
论文题目:Temporal Action Detection Model Compression by Progressive Block Drop
论文地址:https://arxiv.org/pdf/2503.16916

创新点
与传统的通道剪枝方法不同,该方法从模型深度角度出发,通过迭代去除冗余块来减少模型深度,同时保留层宽度,使模型更适合GPU并行计算,提高推理速度。
在每次迭代中,先评估每个块的重要性并去除最不重要的块,然后采用参数高效的跨深度对齐策略进行微调以恢复模型性能。这种渐进式方法能够有效避免一次性去除多个块导致的性能大幅下降问题。
方法
本文提出了一种新的时序动作检测(TAD)模型压缩方法,名为渐进式块丢弃(Progressive Block Drop)。该方法主要从模型深度角度出发,通过迭代去除冗余块来减少模型深度,同时保留层宽度,从而减少计算量并提高推理速度。方法的核心在于两个阶段:块选择和性能恢复。在块选择阶段,通过评估每个块对模型性能的影响,自动选择并去除最不重要的块。在性能恢复阶段,采用参数高效的跨深度对齐策略,结合低秩适应(LoRA)技术对剩余块进行微调,以恢复模型性能。跨深度对齐策略通过特征级和预测级对齐,使剪枝后的模型能够学习到与未压缩模型相似的特征和预测。
模型压缩方法比较

本图展示了渐进式块丢弃方法与其他模型压缩方法的对比。图中展示了特征提取器和检测头在模型计算开销中的占比,特征提取器占总模型计算开销的 95%。渐进式块丢弃方法通过减少网络深度而非宽度来压缩模型,保留了层宽度,从而能够利用大矩阵进行高效计算。相比之下,传统通道剪枝方法通过减少每个层的通道数来压缩模型,但在处理小矩阵时会导致 GPU 的并行化效率降低。渐进式块丢弃方法在相同计算成本下,模型推理速度提升了 1.19 倍,展示了该方法在硬件效率上的优势。
TAD 模型块级分析
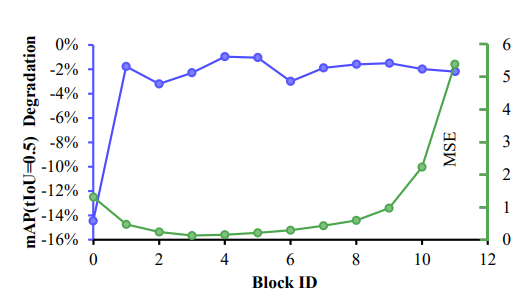
本图对 TAD(时序动作检测)模型进行了块级分析,旨在探索模型深度缩减的可行性。图中展示了两个关键指标:一是模型中每个块的输入和输出特征之间的差异,通过均方误差(MSE)来衡量;二是移除某个特定块后模型性能的下降幅度,以平均精度(mAP)为评估标准。
渐进式块丢弃方法流程图
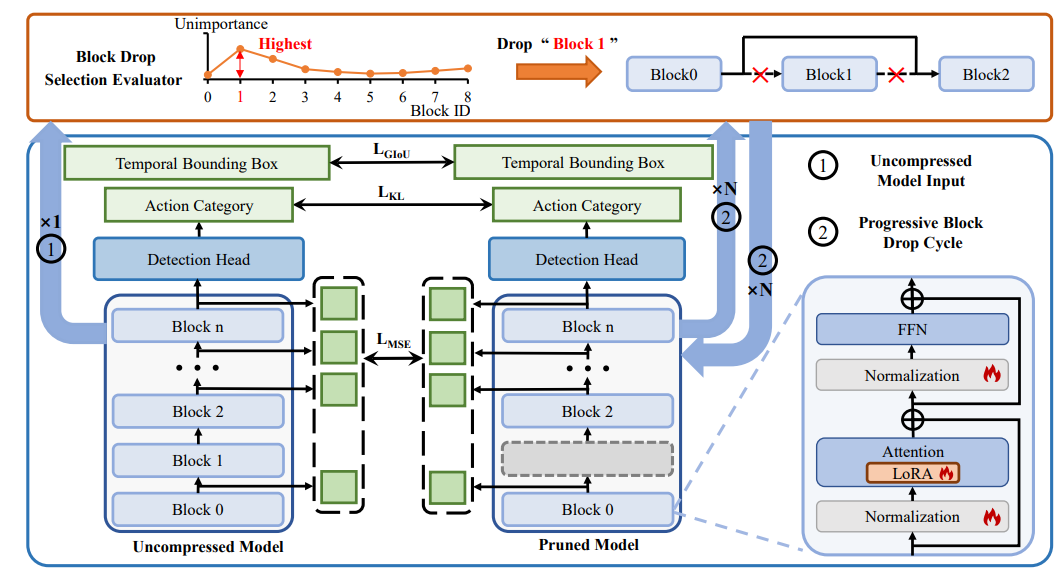
本图展示了渐进式块丢弃方法的完整流程。该方法的核心在于通过多轮迭代逐步压缩模型,每轮迭代包括两个主要阶段。首先,在块选择阶段,利用块选择评估器依据特定指标(如训练损失或平均精度均值mAP)自动确定并移除对模型性能影响最小的块。接着,在性能恢复阶段,采用参数高效的训练技术,包括低秩适应(LoRA)和跨深度对齐策略,对剪枝后的模型进行微调,使其性能恢复甚至超过原始模型。
实验结果

本表中列出了不同丢弃块数量下的模型性能指标,包括计算复杂度(MACs)、本表还评估了渐进式块丢弃方法在 THUMOS14 和 ActivityNet-1.3 数据集上的效果。表格展示了不同丢弃块数量下的模型性能,包括计算复杂度(MACs)、推理时间和平均精度均值(mAP)。这表明渐进式块丢弃方法在降低模型计算开销的同时,保持了模型的性能,甚至在某些情况下还能提升性能。
-- END --

关注“学姐带你玩AI”公众号,回复“2025大模型”
领取2025大模型创新方案合集+开源代码
