当你与AI大模型进行长对话、请它总结一本书或分析长文档时,可曾好奇它为何能如此“聪明”地记住上下文?其实,模型并非每次思考都“从零开始”。它拥有一个关键的“短期记忆库”——KV Cache。它就像模型的“智能笔记本”,记录下已处理过的关键信息,让模型在生成后续内容时能快速调用,避免重复,从而着重在必要的增量计算。
这不仅让对话响应更迅捷,也显著降低了计算开销,是支撑长文本生成的核心技术。 然而,一个现实的挑战随之而来:对话越长,模型处理的信息越多,这个“记忆库”的规模就越大,占用的内存也急剧增长。这成为制约大模型效能的主要瓶颈,限制了其同时服务的用户数量以及处理复杂任务的能力。
此前,研究人员尝试压缩这块内存,但往往难以避免模型准确性的下降。 针对这一挑战,英特尔的研究人员提出了KVCrush技术。它旨在显著减小KV Cache的内存占用,根据测试数据,最高可实现4倍的压缩,并将精度损失控制在1%以内,从而帮助提升推理速度,让大模型更易用。

创新的Token表示法:
从高维向量到精简“二进制指纹”
传统方法使用高维浮点向量(例如,拥有4096个维度)来表示每个Token(词元),这在推理期可能并非最优。KVCrush的核心创新在于,它为每个Token生成一个极其紧凑的二进制特征向量作为替代。这个新“指纹”的长度仅与模型的注意力头 (attention head) 数量相等(例如128维),体积大幅减小。 其生成过程高效且巧妙:
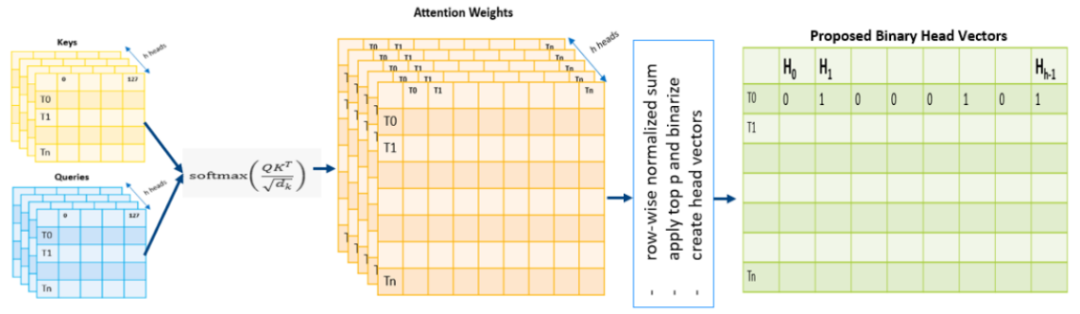
1. 复用计算,无额外开销:KVCrush直接利用模型推理过程中自然计算出的注意力权重矩阵,无需额外计算。
2. 化关注度为二进制决策:对于每个注意力头,根据其注意力分数设定一个阈值,判断一个Token是应被“保留”(记为1)还是“驱逐”(记为0)。这捕捉了每个注意力头对Token的“专业判断”。
3. 合成独特“数字签名”:汇集所有注意力头的二进制决策(0或1),形成一个紧凑的、富含语义信息的二进制向量,作为该Token的唯一签名。
这种方法不仅极大压缩了存储,其二进制特性也使得后续的相似度比较速度加快。

智能内存管理:低开销分组,保留上下文精髓
拥有精简的“指纹”后,KVCrush利用它来智能地决定哪些Token应该保留在有限的内存中,而不是简单地丢弃旧数据,是一种混合保留策略:
● 一部分内存分配给由传统压缩方法(如H2O、SnapKV)识别出的最重要Token。
● 另一部分则交由KVCrush的低开销分组算法管理,用于保留代表性Token,确保上下文的完整性。
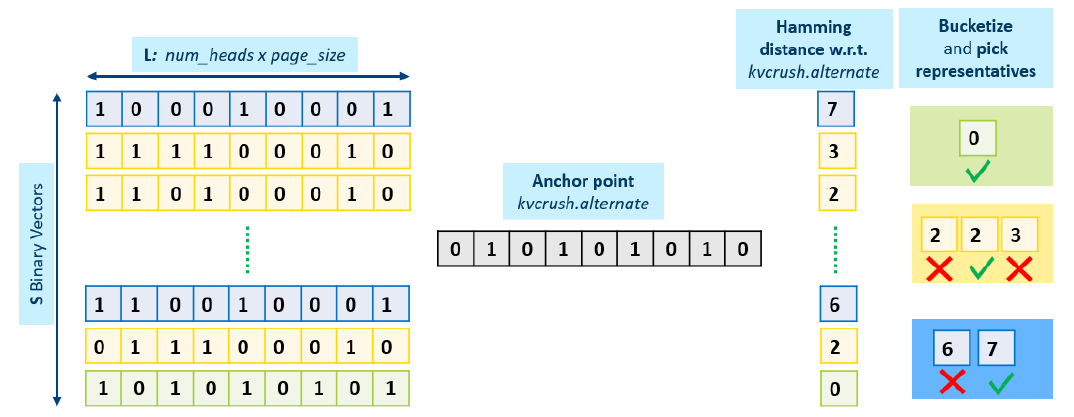
其分组流程大致是:
1. 快速比对:算法会选取”锚点”,利用二进制向量计算速度快的优势,快速计算Token“指纹”之间的相似度。
2. 智能归组:将语义特征相似的Token归入同一组。
3. 择优留存:从每组中选出一个代表性Token保留在缓存中。
这确保了压缩后的缓存仍能保留丰富的上下文信息,有助于维持模型的上下文理解能力。整个分组过程计算开销极低,研究数据显示其对总推理延迟的影响小于0.5%。

KVCrush的应用和未来计划
KVCrush的设计注重兼容性,能够与现有的多种KV Cache优化技术(如混合精度量化、分页缓存机制)协同工作,便于集成到实际的推理流水线中。 根据计划,从OpenVINO™ GenAI库的2025.3版本开始,KVCrush技术被集成其中,助力开发者在英特尔® 平台上部署更高效的LLM应用。
英特尔的研究团队仍在持续探索,例如研究动态的缓存预算分配策略和通过更先进的多锚点技术来改进令牌分组。
了解更多,欢迎访问:https://community.intel.com/t5/Blogs/Tech-Innovation/Artificial-Intelligence-AI/KVCrush-Rethinking-KV-Cache-Alternative-Representation-for/post/1716243
©英特尔公司,英特尔、英特尔logo及其它英特尔标识,是英特尔公司或其分支机构的商标。文中涉及的其它名称及品牌属于各自所有者资产。







![2026年全球及中国AI加速芯片行业发展历程、发展现状及发展趋势研判:云端主导推理突围,细分赛道释放巨大市场空间[图]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2026-03-20/69bc9c95abf69.jpeg)