音频
4步出声,单卡0.24秒!Noiz AI联合港科大清华,开源音频生成大模型
量子位
5天前
通向AGI的关键拼图!首篇多模态大模型「音频推理」综述出炉,万字拆解四大前沿路径
机器之心
1周前
音频编辑的“高考”来了:首个大规模多任务评测基准MMAE发布,现有模型几乎“全军覆没”
机智流
1周前
首个实时交互音频大模型Audio-Interaction问世!南洋理工等团队开启实时“感知-决策-响应”的音频交互新范式
机智流
1周前
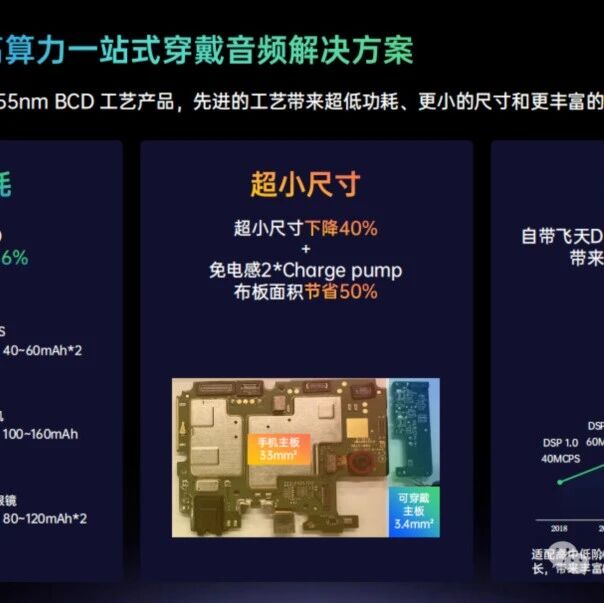
AWA88188:把“功放”做成AI入口——艾为电子重写AI眼镜的音频底层逻辑
EDA 星球
2周前
腾讯音乐官宣放弃音频版权独家授权;中国汽车史首家,上汽将迎全球第一亿位用户;DeepSeek官宣永久降价;微信解释消息撤回时限2分钟...
IT之家
4周前
谷歌重返智能眼镜战场:联手三星与时尚巨头,今秋推出AI音频眼镜
科技区角
1个月前
绝杀!OpenAI正式接管人类耳朵,首个GPT-5级推理音频模型来了
新智元
1个月前
2秒钟转写5分钟音频!国产新语音模型拿下多项SOTA,定价骤减90%
智东西
1个月前
AI 技术大爆炸时代,一颗小小的 TI 音频芯片藏着“改变世界”的潜力
智东西
1个月前
加载中...
Copyright © 2025 成都区角科技有限公司
蜀ICP备2025143415号-1
川公网安备51015602001305号