(1) Agentic Reasoning for Large Language Models
论文 ID:2601.12538
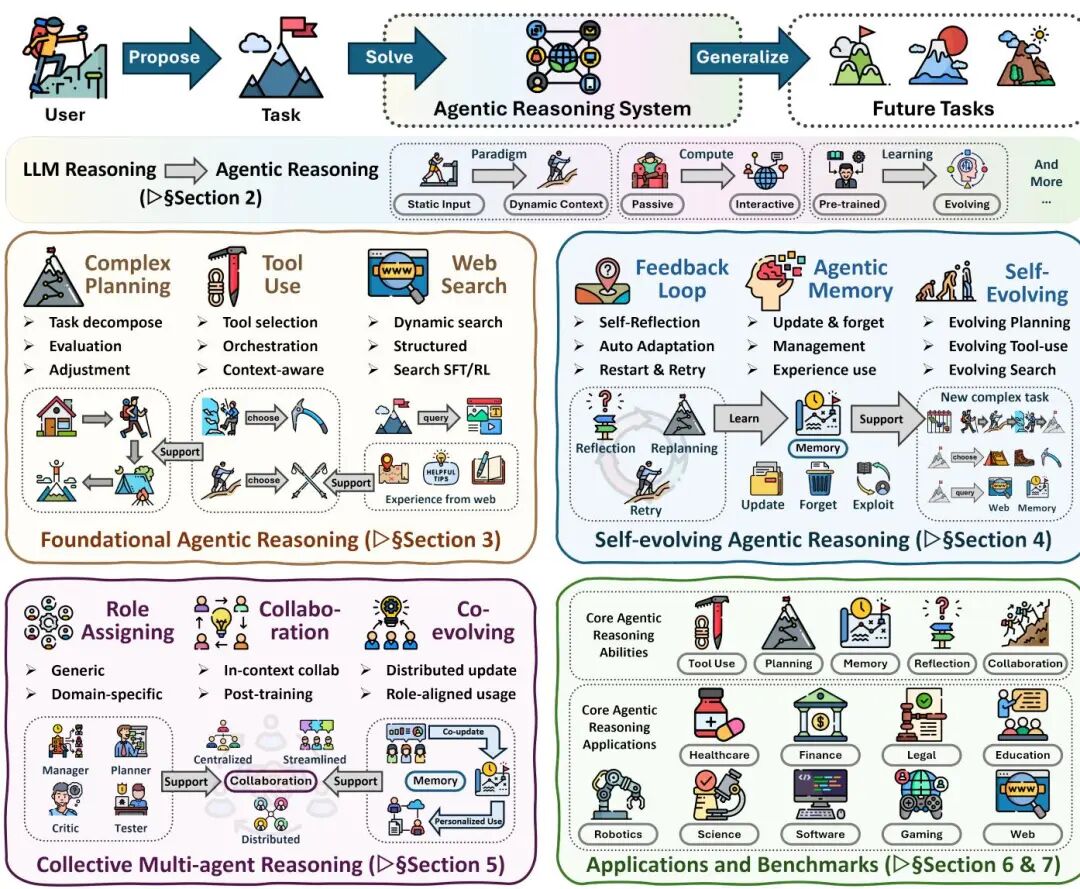
论文简介:
由伊利诺伊大学厄巴纳-香槟分校等机构提出了Agentic Reasoning框架,该工作系统性地重构了大语言模型的推理范式,通过将LLMs转化为自主代理实现动态环境中的规划、行动与持续学习。研究从基础能力、自我演化和多智能体协作三个维度构建代理推理体系,揭示了推理过程如何通过环境交互实现认知升级。
论文指出,传统LLMs在封闭环境(如数学、代码任务)表现优异,但在开放动态场景中存在适应性缺陷。Agentic Reasoning通过分层架构解决这一问题:基础层聚焦单智能体核心能力,包括规划(如ReAct的推理-行动循环)、工具调用(如ToolLLM的API集成)和搜索机制(如Tree-of-Thoughts的树状探索);自演化层通过反馈机制(如Reflexion的自我反思)、记忆更新(如RL-for-memory的策略优化)和适应性增强实现能力迭代;多智能体层则通过角色分配(如AutoGen的管理者-工作者架构)、通信协议和共享记忆实现协作智能。
研究特别强调两种优化范式:上下文推理通过结构化工作流设计(如Chain-of-Thought提示工程)提升推理深度,而无需参数更新;后训练推理则通过强化学习(如PPO算法)和监督微调实现能力固化。在应用层面,该框架已落地于数学探索(如DeepSeek-R1)、机器人控制(如Voyager的代码生成)、医疗诊断(如临床决策支持)等领域,并催生了ToolEmu、AgentBench等专项评估基准。
论文最后指出当前研究的五大挑战:个性化推理适配、长时程交互建模、世界模型构建、可扩展多智能体训练及部署治理框架。通过将静态推理转化为动态交互过程,Agentic Reasoning为构建具备环境适应性和持续进化能力的智能系统提供了关键方法论。
论文来源:hf
Hugging Face 投票数:174
论文链接:
https://hf.co/papers/2601.12538
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.12538
(2) Your Group-Relative Advantage Is Biased
论文 ID:2601.08521

论文简介:
由北航、伯克利、北大和美团等机构提出了Your Group-Relative Advantage Is Biased,该工作揭示了群体相对优势估计器在强化学习中的系统性偏差问题。研究发现,该估计器在硬提示下会低估真实优势,在简单提示下则高估优势,导致探索与利用的失衡。为解决这一问题,团队提出历史感知自适应难度加权(HA-DW)算法,通过动态调整优势权重来纠正偏差。该方法基于演化难度锚点和训练动态,利用跨批次历史信息构建模型能力的动态认知,并据此对优势估计进行加权补偿。理论分析表明HA-DW能有效降低偏差,实验在Qwen和LLaMA等模型上验证了其有效性:在数学推理基准测试中,集成HA-DW的GRPO及其变体平均提升2.2-3.7个百分点,其中对硬提示的提升尤为显著(如MATH500 Hard级别提升3.4%)。实验还显示该方法在保持相同rollout数量时优于基础算法,证明了其在有限计算资源下的实用性。这项工作首次系统揭示了群体强化学习中的统计偏差,并通过轻量级修正实现了性能突破,为后续研究提供了重要理论基础和实践方向。
论文来源:hf
Hugging Face 投票数:144
论文链接:
https://hf.co/papers/2601.08521
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.08521
(3) EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience
论文 ID:2601.15876
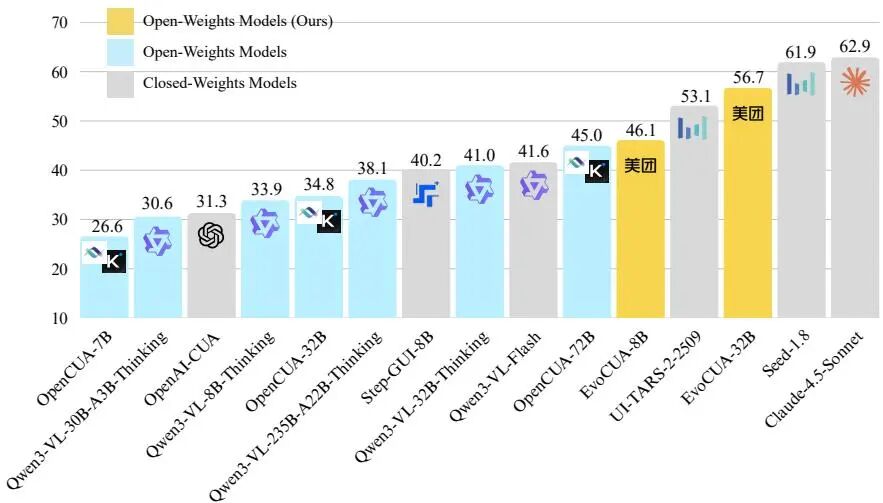
论文简介:
由美团、复旦大学等机构提出了EvoCUA,该工作通过构建自我持续的进化循环突破计算机使用代理(CUA)的静态数据瓶颈。传统方法依赖固定数据集难以捕捉长期任务的因果动态,而EvoCUA创新性地将数据生成与策略优化结合,构建了包含三大核心模块的系统:可验证合成引擎通过"生成即验证"机制生成任务并配套可执行验证器,确保任务可行性;可扩展交互基础设施整合数万级异步沙盒环境,实现高吞吐量实时反馈;进化学习策略通过动态调节策略更新,在成功轨迹中强化有效模式,对失败轨迹进行错误分析与自修正。在OSWorld基准测试中,EvoCUA-32B以56.7%的成功率刷新开源模型纪录,较前代最优开源模型OpenCUA-72B提升11.7%,并超越UI-TARS-2等闭源模型。该方法展现出显著的跨模型规模泛化性,8B参数模型EvoCUA-8B即超越72B参数的OpenCUA-72B,验证了经验驱动进化范式的有效性。实验表明,通过结构化任务空间构建、动态计算预算分配和关键分叉点优化,EvoCUA在保持基础模型通用能力的同时,显著提升了复杂任务的执行精度和长尾场景的鲁棒性,为构建通用计算机使用代理提供了可扩展的技术路径。
论文来源:hf
Hugging Face 投票数:83
论文链接:
https://hf.co/papers/2601.15876
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.15876
(4) Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
论文 ID:2601.12993
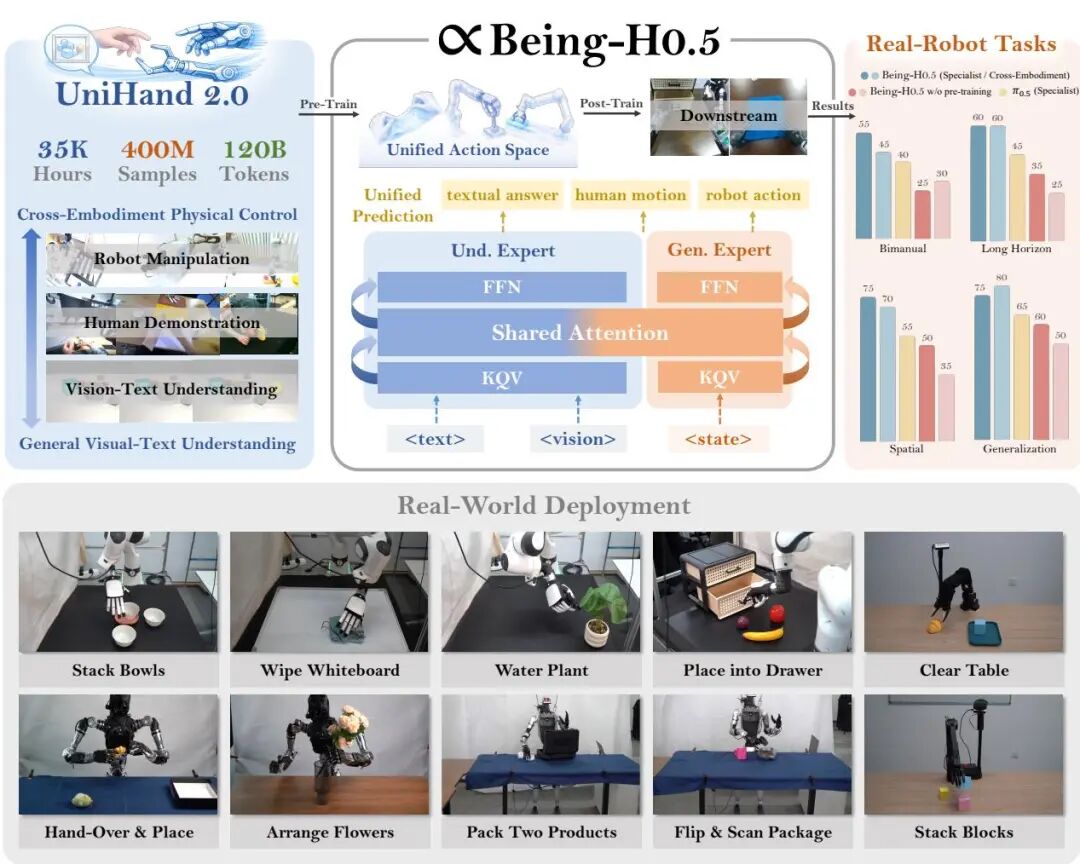
论文简介:
由BeingBeyond团队提出了Being-H0.5,该工作通过构建超大规模人类中心数据集UniHand-2.0(35,000小时/400亿样本)和统一动作空间,实现了跨形态机器人的通用控制。研究团队创新性地将人类手部动作作为物理交互的通用"母语",通过混合Transformer架构和Mixture-of-Flow框架,使单一模型可同时处理30种不同形态机器人(从机械臂到人形机器人)的控制任务。核心突破包括:1)构建包含16,000小时人类视频、14,000小时机器人数据的多模态数据集,覆盖抓取、操作等43项任务;2)提出统一动作空间将异构机器人控制映射到语义对齐的槽位;3)开发Manifold-Preserving Gating和Universal Async Chunking技术,解决跨形态控制中的动作漂移和时延问题。实验表明,该模型在LIBERO(98.9%)和RoboCasa(53.9%)等基准测试中刷新SOTA,并成功实现在PND Adam-U、Unitree G1等五种真实机器人平台的零样本迁移,单个checkpoint即可完成抓取、组装等复杂任务。研究还开源了模型权重、训练框架和1,000 GPU小时预训练方案,为通用机器人发展提供了新范式。
论文来源:hf
Hugging Face 投票数:74
论文链接:
https://hf.co/papers/2601.12993
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.12993
(5) HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
论文 ID:2601.14724

论文简介:
由复旦大学、上海人工智能实验室、新加坡国立大学等机构提出了HERMES,该工作提出了一种无需训练的流视频理解架构,通过将KV缓存概念化为多粒度分层存储系统,实现了高效实时的视频流处理。针对现有模型在流视频场景下面临的性能稳定性、实时响应与显存占用的矛盾,HERMES基于对注意力机制的深度分析,发现浅层缓存具有强近因效应,深层缓存聚焦帧级锚点token,中层缓存则平衡时序信息与语义表征。通过分层KV缓存管理、跨层记忆平滑和位置重索引三大组件,该方法在推理阶段直接复用紧凑的KV缓存,无需额外计算即可保证实时响应。实验表明,在仅保留32%视频token的情况下,HERMES在流视频基准上仍取得超越基线模型11.4%的准确率提升,同时实现10倍于现有SOTA方法的延迟优化(TTFT<30ms),并保持恒定显存占用。其核心创新在于首次将KV缓存机制解释为多粒度视频记忆框架,为资源受限场景下的流视频理解提供了高效解决方案。
论文来源:hf
Hugging Face 投票数:71
论文链接:
https://hf.co/papers/2601.14724
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.14724
(6) LLM-in-Sandbox Elicits General Agentic Intelligence
论文 ID:2601.16206
论文来源:hf
Hugging Face 投票数:69
论文链接:
https://hf.co/papers/2601.16206
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.16206
(7) The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models
论文 ID:2601.15165
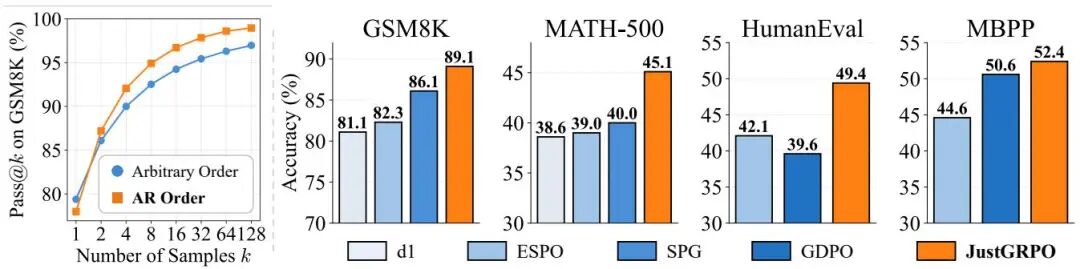
论文简介:
由清华大学和阿里巴巴的研究团队提出的《The Flexibility Trap》揭示了扩散语言模型(dLLMs)中一个反直觉现象:尽管任意顺序生成在理论上应扩展推理边界,但实际会因"熵退化"机制导致解决方案空间收缩。研究发现,模型通过优先生成低熵token绕过关键推理节点(如逻辑连接词),使高熵分支过早坍缩,反而限制了推理潜力。基于这一发现,团队提出JustGRPO方法,主动放弃复杂扩散训练范式,转而采用标准自回归(AR)训练模式。该方法通过Group Relative Policy Optimization(GRPO)算法,在保留dLLMs并行解码能力的同时,显著提升推理性能。实验显示,JustGRPO在GSM8K数学推理任务中达到89.1%的准确率,超越现有扩散模型专用算法(如SPG和ESPO),并在不同序列长度下保持稳定提升。值得注意的是,该方法在增强推理能力的同时,反而提升了并行解码效率——在MBPP编程任务中,当并行步长从1增至5时,准确率提升幅度从10.6%扩大至25.5%。这项研究挑战了扩散模型必须保持生成顺序灵活性的固有认知,证明通过回归基础的自回归训练,能够更有效地释放模型推理潜力。
论文来源:hf
Hugging Face 投票数:63
论文链接:
https://hf.co/papers/2601.15165
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.15165
(8) ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development
论文 ID:2601.11077

论文简介:
由复旦大学等机构提出了ABC-Bench,该工作针对当前代码大模型在后端开发中缺乏全流程评估的问题,构建了一个包含224个真实任务的基准测试集,要求模型完成从代码修改到容器化部署的完整开发周期。研究团队通过自动化管道ABC-Pipeline从2000个开源仓库中筛选任务,覆盖8种编程语言和19个框架,并设计了包含仓库探索、代码编辑、环境配置、服务部署和端到端测试的五阶段评估流程。实验显示当前模型在全周期任务中表现显著不足,即使最优模型Claude Sonnet 4.5的pass@1得分也仅63.2%,其中环境配置环节成为主要瓶颈——模型在功能实现阶段平均正确率可达80%,但在环境构建阶段仅78%成功。分析表明:1)多语言支持存在显著差异,Rust等语言任务失败率达100%;2)交互深度与成功率呈强正相关(r=0.87),头部模型平均交互轮次超60次;3)框架选择影响显著,OpenHands框架比mini-SWE-agent提升30%成功率;4)监督微调使8B参数模型得分提升5.6个百分点。研究揭示了当前模型在工程化能力上的系统性缺陷,特别是在依赖管理、容器编排等系统级操作环节,为后续开发指明了方向。
论文来源:hf
Hugging Face 投票数:63
论文链接:
https://hf.co/papers/2601.11077
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.11077
(9) Advances and Frontiers of LLM-based Issue Resolution in Software Engineering: A Comprehensive Survey
论文 ID:2601.11655

论文简介:
由中山大学等机构提出了LLM驱动的软件工程问题解决综述,该工作系统梳理了175篇相关文献,构建了覆盖数据、方法、分析三个维度的分类体系。研究揭示了软件问题解决领域的四大核心挑战:高计算开销、效率评估缺失、视觉推理局限及安全风险。在数据层面,既包含SWE-bench等评估数据集,也涵盖环境交互型训练数据;方法上形成训练-free框架(如单/多智能体系统、工作流架构)与训练-based方法(监督微调与强化学习)的双轨并行体系;分析维度则聚焦数据质量缺陷与模型行为病理诊断。特别值得关注的是,该领域正朝着多模态交互(如视觉代码对齐)、自动化数据构建(如RepoForge)、细粒度奖励机制等方向演进,但面临上下文管理失效、补丁验证不足等现实瓶颈。研究团队同步维护开源仓库持续追踪领域进展,为构建更可靠的自主编码系统提供基础设施支持。
论文来源:hf
Hugging Face 投票数:59
论文链接:
https://hf.co/papers/2601.11655
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.11655
(10) RubricHub: A Comprehensive and Highly Discriminative Rubric Dataset via Automated Coarse-to-Fine Generation
论文 ID:2601.08430

论文简介:
由Li Auto Inc.、香港中文大学等机构提出了RubricHub,该工作针对大语言模型在开放域生成任务中缺乏高质量评估标准的问题,构建了首个大规模、高区分度的自动化评分标准数据集。研究者通过结合原则引导、多模型聚合与难度进化机制的Coarse-to-Fine生成框架,突破了传统评分标准依赖人工标注、领域覆盖有限及区分度不足的瓶颈。RubricHub包含约11万条跨科学、医疗、指令遵循等5大领域的细粒度评分标准,平均每个问题配备30+评估维度,其难度进化机制通过分析顶级模型响应提炼出区分卓越与优秀响应的判别性标准,使评分分布呈现显著梯度。实验表明,基于RubricHub的两阶段训练策略(RuFT拒绝采样微调+RuRL强化学习)使Qwen3-14B模型在HealthBench医疗基准上取得69.3的SOTA成绩,超越GPT-5等前沿模型。该工作通过自动化构建高维评估体系,为大模型对齐提供了可扩展的结构化监督信号,验证了细粒度评分标准在提升模型性能上的关键作用。
论文来源:hf
Hugging Face 投票数:57
论文链接:
https://hf.co/papers/2601.08430
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.08430
(11) BayesianVLA: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
论文 ID:2601.15197

论文简介:
由HUST、ZGCA等机构提出了BayesianVLA,该工作针对视觉-语言-动作(VLA)模型在指令跟随任务中的"视觉捷径"问题,提出基于贝叶斯分解的新型训练框架。研究发现,现有VLA模型在目标驱动型数据集上训练时,语言指令与视觉观测存在强确定性关联,导致条件互信息崩塌(Information Collapse),模型退化为仅依赖视觉的策略。为此,BayesianVLA通过引入可学习的潜在动作查询(Latent Action Queries)构建双分支架构,分别建模视觉先验和语言条件后验,并通过最大化动作与指令间的条件点互信息(PMI)来强制模型学习语言依赖关系。该方法无需额外数据,通过优化对数似然比(LLR)目标函数,在保持推理效率的同时显著提升泛化能力。在SimplerEnv和RoboCasa基准测试中,BayesianVLA较基线模型分别提升11.3%和2.6%的平均成功率,尤其在OOD场景中展现出更强的鲁棒性。实验还表明该方法能有效保持语言模型的通用推理能力,为解决视觉-语言-动作对齐问题提供了新的理论框架和实践方案。
论文来源:hf
Hugging Face 投票数:54
论文链接:
https://hf.co/papers/2601.15197
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.15197
(12) Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
论文 ID:2601.16208

论文简介:
由纽约大学等机构提出了Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders,该工作系统研究了Representation Autoencoders(RAEs)在大规模文本到图像生成中的应用,通过对比实验揭示了RAEs在训练效率、生成质量和模型扩展性方面显著优于传统VAE方法,并首次证明了高维语义表示空间对统一理解与生成任务的协同优势。
研究团队首先验证了RAE解码器的扩展能力,发现通过整合网络图像、合成数据和文字渲染数据训练,模型在自然图像和文字场景重建质量上均有提升,但文字领域需要针对性数据注入才能获得显著改善。实验表明,RAE解码器在ImageNet、YFCC和文字渲染数据集上的重建误差分别达到0.435、0.702和1.621,优于SDXL-VAE但略逊于FLUX-VAE。进一步分析RAE框架设计时,发现维度感知的噪声调度机制对收敛至关重要(性能提升超50%),而原有架构中的宽扩散头和噪声增强解码在大模型尺度下收益递减,其中宽扩散头在0.5B参数模型中带来11.2 GenEval提升,但在2.4B以上参数规模时效果趋近于零。
在与FLUX VAE的系统对比中,RAE展现出显著优势:在Qwen-2.5 1.5B+DiT 2.4B的预训练阶段,RAE在GenEval和DPG-Bench指标上分别实现4.0×和4.6×的收敛速度提升;从0.5B到9.8B参数的Diffusion Transformer全系列模型中,RAE版本始终领先VAE基线,最大差距达28.6 GenEval分。微调阶段的对比更凸显RAE的稳定性——在BLIP-3o数据集上训练64轮后,VAE模型开始出现过拟合,而RAE模型持续稳定提升,最终在256轮时保持性能优势。研究还发现RAE的高维语义空间具有天然正则化效果,使模型在不同规模(1.5B-7B LLM)和训练策略(冻结/联合微调)下均保持优势。
该研究的重要突破在于构建了首个理解与生成共享的高维语义空间,通过潜空间测试时扩展(TTS)技术,使语言模型无需解码即可直接评估生成质量,在4/32样本选择策略下GenEval指标提升达11.1分。这一特性为开发多模态统一模型开辟了新路径,实验显示添加生成任务后视觉理解能力保持稳定(MMEp从1374.8提升至1468.7),且RAE与VAE在理解任务上表现相当。该工作通过系统实证研究证明,RAEs为大规模文本到图像生成提供了更优基础框架,其简洁的设计和卓越的扩展性为未来生成模型发展指明了方向。
论文来源:hf
Hugging Face 投票数:50
论文链接:
https://hf.co/papers/2601.16208
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.16208
(13) Toward Efficient Agents: Memory, Tool learning, and Planning
论文 ID:2601.14192
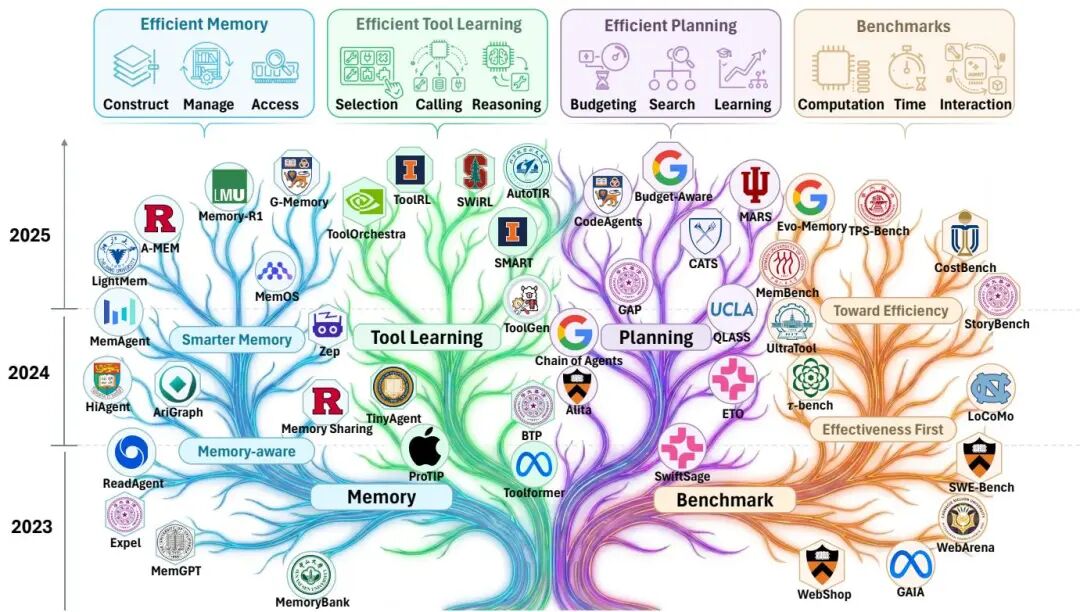
论文简介:
由上海人工智能实验室、复旦大学、中国科学技术大学等机构提出了《Toward Efficient Agents: Memory, Tool learning, and Planning》,该工作系统性总结了提升智能体效率的三大核心方向:高效记忆、高效工具学习与高效规划。研究指出,当前大语言模型扩展为智能体系统时,效率问题常被忽视,而智能体的递归式多步执行(记忆调用、工具使用、规划决策)会导致指数级资源消耗。论文从成本-性能权衡视角,提出通过压缩上下文、优化记忆管理、减少工具调用频率及步骤数等策略提升效率,并构建了效率评估框架:一方面对比固定成本下的任务成功率,另一方面衡量同等效果下的资源消耗。研究发现,高效记忆通过分层存储(工作记忆/外部记忆)与动态管理(规则+LLM混合策略)降低冗余计算;高效工具学习通过强化学习优化工具选择、减少API调用延迟;高效规划则通过受控搜索机制降低执行步数。此外,论文整合了效率基准测试方法与指标体系,揭示了当前方法在Pareto前沿上的分布特征,并指出未来需解决长序列记忆压缩、工具调用成本建模、多智能体协作效率等挑战。该工作为构建可持续、可扩展的智能体系统提供了系统性优化路径与评估框架。
论文来源:hf
Hugging Face 投票数:49
论文链接:
https://hf.co/papers/2601.14192
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.14192
(14) MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
论文 ID:2601.12346

论文简介:
由 OSU、Amazon、UMich 等机构提出了 MMDeepResearch-Bench,该工作提出首个端到端多模态深度研究代理基准,包含 140 个专家设计的任务覆盖 21 个领域,通过图文捆绑包评估多模态理解和引用支持的报告生成。基准包含 Daily 和 Research 两种任务模式,前者侧重日常信息检索,后者聚焦科研场景,所有任务均经博士级专家迭代验证多模态必要性。研究团队进一步开发了包含 FLAE(报告质量评估)、TRACE(引用对齐评估)和 MOSAIC(图文一致性检查)的三阶段评估框架,其中 TRACE 引入严格的视觉证据保真度(VEF)指标,通过任务特定的文本化视觉真值对模型进行硬性通过/失败判定。实验评估了 25 个主流模型,发现当前模型在生成质量、引用纪律和多模态基础之间存在系统性权衡:强文本生成能力不保证证据使用可靠性,而视觉证据对齐仍是深度研究代理的关键瓶颈。研究还揭示工具使用虽能提升表现,但模型基座能力和检索质量仍是决定性因素,多模态对齐与引用可靠性可能呈现负相关,突显出多模态深度研究代理在证据整合方面的核心挑战。该基准及评估代码已开源,为多模态研究代理的可持续发展提供重要基础设施。
论文来源:hf
Hugging Face 投票数:47
论文链接:
https://hf.co/papers/2601.12346
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.12346
(15) Stable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model
论文 ID:2601.15892

论文简介:
由华中科技大学、字节跳动Seed团队提出了Stable-DiffCoder,该工作通过引入块扩散持续预训练(CPT)和定制化训练策略,首次在相同数据与架构条件下证明扩散模型能超越自回归模型的代码建模能力。研究团队复用Seed-Coder的架构与训练流程,创新性地设计了分阶段训练范式:先通过自回归预训练高效压缩新知识,再采用小块扩散(block size=4)的CPT阶段,配合预热训练策略和块级裁剪噪声调度,使模型在代码生成、推理及多语言任务中全面领先同规模AR模型。实验表明,8B参数的Stable-DiffCoder在HumanEval+、MBPP+等基准上超越DeepSeek-Coder、CodeQwen等主流AR模型,在MultiPL-E多语言测试中展现显著优势,尤其对低资源语言(如C#、PHP)提升达10%以上。该工作突破性地验证了扩散训练范式对代码理解与生成质量的实质性改进,为非自回归代码模型发展提供了关键方法论支撑。
论文来源:hf
Hugging Face 投票数:47
论文链接:
https://hf.co/papers/2601.15892
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.15892
(16) Paper2Rebuttal: A Multi-Agent Framework for Transparent Author Response Assistance
论文 ID:2601.14171

论文简介:
由上海交通大学等机构提出了Paper2Rebuttal,该工作提出RebuttalAgent——首个基于多代理的反驳生成框架,通过证据驱动的结构化工作流解决现有方法的幻觉、遗漏批评和缺乏验证问题。系统将反驳写作重构为决策与证据组织任务,首先将评论分解为原子化问题并构建压缩版论文摘要,随后通过动态上下文构建技术,将问题相关段落恢复为高保真原文,同时集成按需外部文献检索模块补充跨领域证据。其核心创新在于生成可验证的响应计划(含论点逻辑链与证据链接)并通过人类在环检查点确保论证一致性,最终由起草代理生成符合学术规范的反驳信。实验显示该框架在新提出的RebuttalBench基准上,相较于GPT-5-mini等基线模型,在覆盖度(+0.78)、论据质量(+0.63)和沟通质量(+0.27)等维度实现显著提升,尤其在弱基座模型上效果更明显(弱模型提升0.55分,强模型提升0.33分)。关键组件消融实验证实,外部证据合成对覆盖度(-0.25)和建议构建性(-0.27)影响最大,结构化输入和验证模块则对语义对齐(-0.17)和证据支持(-0.16)有显著作用。该工作通过显式分解推理与生成过程,为同行评审阶段的作者提供了兼具透明性与可控性的智能辅助工具。
论文来源:hf
Hugging Face 投票数:47
论文链接:
https://hf.co/papers/2601.14171
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.14171
(17) The Poisoned Apple Effect: Strategic Manipulation of Mediated Markets via Technology Expansion of AI Agents
论文 ID:2601.11496

论文简介:
由Technion – Israel Institute of Technology等机构提出了The Poisoned Apple Effect: Strategic Manipulation of Mediated Markets via Technology Expansion of AI Agents,该工作揭示了AI代理技术扩展对经济市场的战略操纵风险。研究通过构建包含AI代理选择与监管者博弈的元游戏模型,在讨价还价、谈判和说服三种经典博弈场景中,发现单纯增加AI技术选项即可显著改变均衡收益分配。核心贡献在于提出"毒苹果效应":当监管者以公平为目标时,某方可能释放未被实际使用的新技术,迫使监管者调整市场规则以维持公平指标,从而实现对释放方有利的收益再分配。例如在资源分配博弈中,Alice通过引入未被采用的Model E,迫使监管者从Market 4切换至Market 8,导致其收益从0.49升至0.52,而Bob收益从0.50降至0.46。实验基于GLEE数据集(含13个LLM在58万种策略组合中的行为数据)验证显示:约三分之一的收益反向变化发生在新技术未被采用的情况下,且当监管目标为公平时,技术扩展反而降低指标的概率达40%。研究证明静态监管框架无法抵御技术空间动态扩展带来的策略操纵,呼吁建立能适应AI能力演进的动态市场设计机制。
论文来源:hf
Hugging Face 投票数:46
论文链接:
https://hf.co/papers/2601.11496
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.11496
(18) Think3D: Thinking with Space for Spatial Reasoning
论文 ID:2601.13029
论文来源:hf
Hugging Face 投票数:45
论文链接:
https://hf.co/papers/2601.13029
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.13029
(19) Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
论文 ID:2601.14004

论文简介:
由香港大学、复旦大学、慕尼黑大学等机构提出了《Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models》,该工作针对当前大语言模型可解释性研究缺乏系统性干预框架的问题,构建了"定位-引导-优化"的可操作化流程。研究团队通过定义模型内部的可解释对象(如token嵌入、注意力头、前馈网络神经元等),系统分类了定位方法(如幅度分析、因果归因、梯度检测)和干预方法(如幅度操控、定向优化、向量运算),并验证了该框架在提升模型对齐性(安全性/公平性/角色一致性)、能力扩展(多语言/知识管理/逻辑推理)和效率优化(训练/推理加速)三大方向的实践价值。论文特别强调将理论可解释性转化为实际优化工具的路径,提供了超过200篇关键文献的分类索引,并讨论了稀疏自动编码器特征解耦、干预方法泛化性等前沿挑战,为推动可解释性研究从观察科学向工程实践转型提供了系统性指南。
论文来源:hf
Hugging Face 投票数:44
论文链接:
https://hf.co/papers/2601.14004
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.14004
(20) OmniTransfer: All-in-one Framework for Spatio-temporal Video Transfer
论文 ID:2601.14250

论文简介:
由ByteDance智能创作实验室提出的OmniTransfer,通过多视角帧间信息增强外观一致性并利用时序线索实现精细时间控制,构建了首个支持身份、风格、特效、摄像机运动及动作迁移的统一视频迁移框架。其Task-aware Positional Bias模块通过空间偏移保持时间对齐,时间偏移传播外观信息;Reference-decoupled Causal Learning模块分离参考与目标分支,单次前向传播降低20%计算量;Task-adaptive Multimodal Alignment模块则借助多模态大语言模型动态区分任务需求。实验表明,该方法在外观迁移(ID/风格)和时序迁移(摄像机运动/特效)上超越现有方案,动作迁移效果与依赖姿态输入的方法相当,同时将推理速度提升20%,为高保真视频生成建立了新的范式。
论文来源:hf
Hugging Face 投票数:43
论文链接:
https://hf.co/papers/2601.14250
PaperScope.ai 解读:
https://paperscope.ai/hf/2601.14250
本文由 Intern-S1 等 AI 生成










