
1. 引言
2024 年至2025 年,全球机器人产业正经历一场深刻的范式转移:机器人正从执行预编程指令的“冷冰冰机器”,进化为具备感知、理解与物理交互能力的“具身智能体”。在这场技术革命中,边缘AI 芯片已超越了单纯的半导体组件范畴,成为决定机器人性能上限的“数字神经中枢”。
当全球目光聚焦于英伟达(NVIDIA)的GPU 帝国时,中国本土芯片厂商正凭借深厚的工业积淀与对具身智能底层需求的精准捕捉,悄然构建起庞大的机器人算力版图。
2. 真相一:“降维打击”,自动驾驶芯片的跨界接管
目前,中国机器人市场呈现出显著的“车芯外溢”效应。地平线(Horizon Robotics)、黑芝麻智能(Black Sesame Technologies)等厂商,正将其在L2+ 级自动驾驶领域锤炼的SoC 技术,直接用于具身智能设备。
这种“降维打击”的核心在于感知算法的同源性。自动驾驶所需的“动态避障”与“路径重规划”,与机器人在复杂室内环境中导航的逻辑高度契合。
•架构优势:地平线的BPU 架构从“Bernoulli(伯努利)”演进至“Bayesian(贝叶斯)”,专门针对Transformer 和BEVFormer 等先进算法优化。这种架构在处理大规模并行注意力机制时,拥有比传统通用GPU 更高的帧率/瓦特能效比。
•功能安全:黑芝麻华山系列芯片内置了由Cortex-R5 核心构成的“安全岛(Safety Island)”。在具身智能场景中,该设计能确保系统在主CPU 故障时,依然能执行“紧急制动”等涉及物理安全的关键任务。
机器人芯片必须在极受限的功耗(通常小于30W)与散热条件下,实现多模态数据的并发吞吐。这不仅是算力的堆砌,更是对车规级可靠性(ASIL-B)与实时控制性能的极致挑战。
3. 真相二:瑞芯微 RK3588,国产机器人的“基石标准”
在非汽车类的泛机器人领域,瑞芯微(Rockchip)的RK3588 已确立了无可争议的“基石”地位。从宇树科技(Unitree)的Go2 四足机器人到云深处(DeepRobotics)的绝影系列,RK3588的身影无处不在。
我们看重RK3588 的原因并非其NPU 算力冠绝群雄,而在于其作为“全能基石”的BOM 优化能力。它极其丰富的接口配置(PCIe 3.0、MIPI-CSI、CAN 总线)消除了外挂昂贵FPGA 桥接芯片的需求。
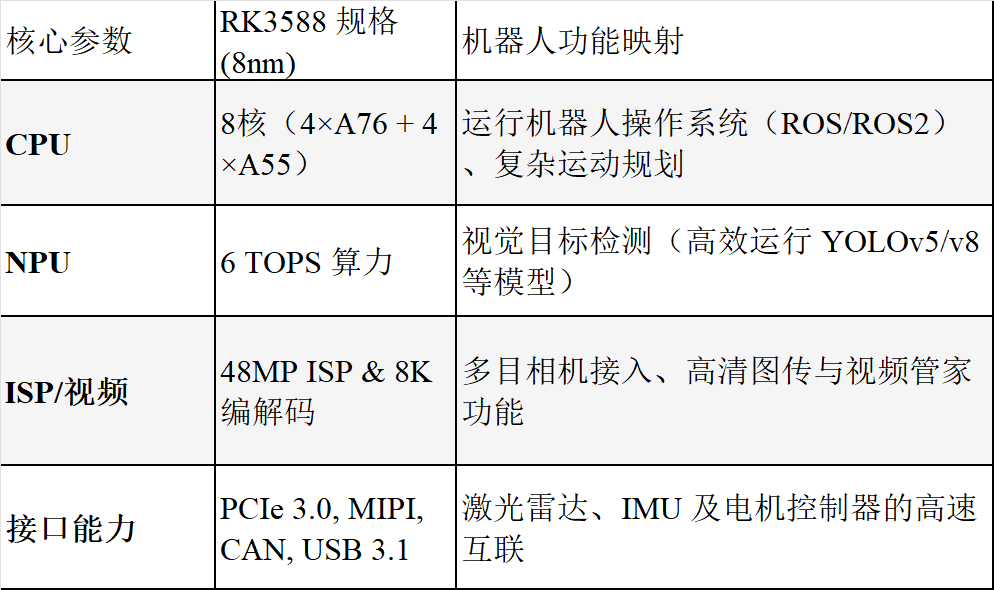
解析:机器人厂商偏爱这种“多面手”,是因为它解决了“存储墙”与接口瓶颈,使得单颗SoC 即可兼顾视觉感知、环境建图(SLAM)与实时动作规划,显著降低了量产成本。
4. 真相三:异构双脑架构,实时性与复杂决策的平衡
高端人形机器人(如优必选Walker S 或普渡 D5)普遍采用异构计算策略,即“双脑架构”。这种设计旨在解决端侧设备在执行大模型推理时,如何兼顾物理运动的毫秒级响应。
•“小脑” (运动控制层):由瑞芯微RK3588 或实时MCU 承担。负责高频步态控制、动态平衡(MPC 算法)以及传感器数据的初步预处理。
•“大脑” (感知决策层):引入NVIDIA Orin 或华为昇腾(Ascend)系列。昇腾芯片采用自研“达芬奇(Da Vinci)”架构,擅长矩阵乘法,用于处理3D 语义重构、复杂任务规划以及端侧大模型的本地推理。
普渡 D5 正是这一模式的典范,利用 Orin 处理重负载VSLAM,而由RK3588 负责交互系统与电机通信,实现了性能与成本的最佳配比。
5. 真相四:RISC-V 与存算一体,打破瓶颈的未来变量
当传统架构面临“存储墙”与“功耗墙”时,中国芯的两支奇兵正在突围:
1.RISC-V 架构的自主化:进迭时空(SpacemiT)的K1 芯片引入了IME(智能矩阵扩展)指令集。这种定制化的指令扩展让RISC-V 在处理AI 推理时,能效超越同类ARM 芯片。智元机器人(Agibot)等独角兽正通过RISC-V 实现底层的软硬解耦与指令集自主。
2.存算一体(PIM) 的革命:后摩智能推出的M50 芯片挑战了传统的冯·诺依曼架构。它将计算单元直接融入内存阵列,提供160 TOPS 算力的同时,典型功耗仅10W,能效比高达20 TOPS/W。对于依赖续航的移动机器人,这意味着更长的作业时间与被动散热的可能性。
6. 真相五:软件生态,国产芯片的“隐形护城河”
硬件参数只是入场券,真正的护城河在于工具链的厚度。国产厂商正通过“保姆式”服务,帮助开发者跨越CUDA 建立的高墙。
•地平线NodeHub:提供了大量如乐高积木般的开源算法节点,支持Sim2Real(仿真到现实)的高效迁移。
•瑞芯微RKNN:历经数年迭代,支持模型一键转换,对主流算子提供了极佳的兼容性。
•华为MindSpore 与CANN:为工业级具身智能提供高精度模型库,实现端云协同的任务规划。
核芯洞察:国产芯片厂商提供的不仅是硅片,而是包含视觉、规划、控制全栈算法的预训练模型库。这种软硬一体的标准化生态,正加速中国机器人厂商从Demo 到量产的开发迭代周期。

厂商评估
•瑞芯微(Rockchip) —— 泛机器人“BOM削减专家”:旗舰RK3588已成为行业标准。其核心竞争力在于极致的接口丰富度(PCIe 3.0, CAN, 多路MIPI),使厂商无需外挂昂贵的FPGA或桥接芯片即可完成系统集成,直接降低整体硬件BOM成本。
•华为海思(HiSilicon) —— 工业级全栈标杆:昇腾310P提供高达176 TOPS的推理算力。华为的优势在于“端云协同”及CANN/MindSpore提供的“重度服务支持”,这使其在对安全性要求极高的工业人形机器人领域具有不可替代性。
•地平线(Horizon) —— 自动驾驶降维打击者:旭日系列对Transformer模型加速效果卓越。其NodeHub生态提供了大量可复用的算法“积木”,极大降低了避障算法的开发门槛。
•黑芝麻智能(Black Sesame) —— 跨域计算先锋:华山A2000强调“双脑合一”,即在一颗SoC上通过硬件隔离同时处理机器人“大脑”逻辑与“小脑”控制,原生支持边缘大模型(LLM)部署。
•进迭时空(SpacemiT) —— RISC-V挑战者:其K1/M1芯片通过自定义IME(智能矩阵扩展)指令集,在执行AI推理任务时能效显著优于同级ARM架构,吸引了智元机器人等追求底层深度定制的厂商。
•爱芯元智(Axera) —— 视觉感知尖兵:凭借AI-ISP在极暗环境下的卓越表现,在安防、巡检类机器人市场占据领先地位。
8. 总结:迎接具身智能的爆发
2024-2025 年,国产机器人芯片已完成从“可用”到“好用”的跨越。随着端侧大模型(VLA 模型)成为标配,下一代机器人芯片将迎来终极形态:集成高带宽内存(HBM)、专门优化Prefill 阶段、并专为触觉/力觉/视觉融合设计的“具身智能专用SoC”。











