作者丨Boseong Jeon等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
一、核心背景与问题痛点
随着机器人实时部署需求的增长,视觉-语言-动作(VLA)模型亟需实现边缘设备上的快速推理。在众多VLA架构中,基于流的模型(如系列、GR00T、CogACT)凭借扩散Transformer(DiT)作为动作头,兼具强生成能力与扩散引导特性,但也面临显著的计算成本挑战:这类模型融合了大型视觉-语言(VLM)backbone与包含数十层Transformer的扩散型动作头,且推理时需迭代执行扩散步骤,导致边缘部署的实时性难以保障。
现有效率优化方案存在明显局限:
-
层跳越方法:通过动态检测层间特征相似度或路由机制跳过冗余层,但需保留完整模型在GPU内存中,且仅针对VLMbackbone优化,未考虑流基VLA模型中动作头与backbone深度对齐以接收中间层特征的架构特点;同时,层相似度随扩散步骤的噪声水平变化剧烈(figure3),固定阈值或路由规则难以适配,且相似度无法准确反映层的功能重要性——跳过相似度高的早期层可能导致成功率大幅下降(figure3底部)。
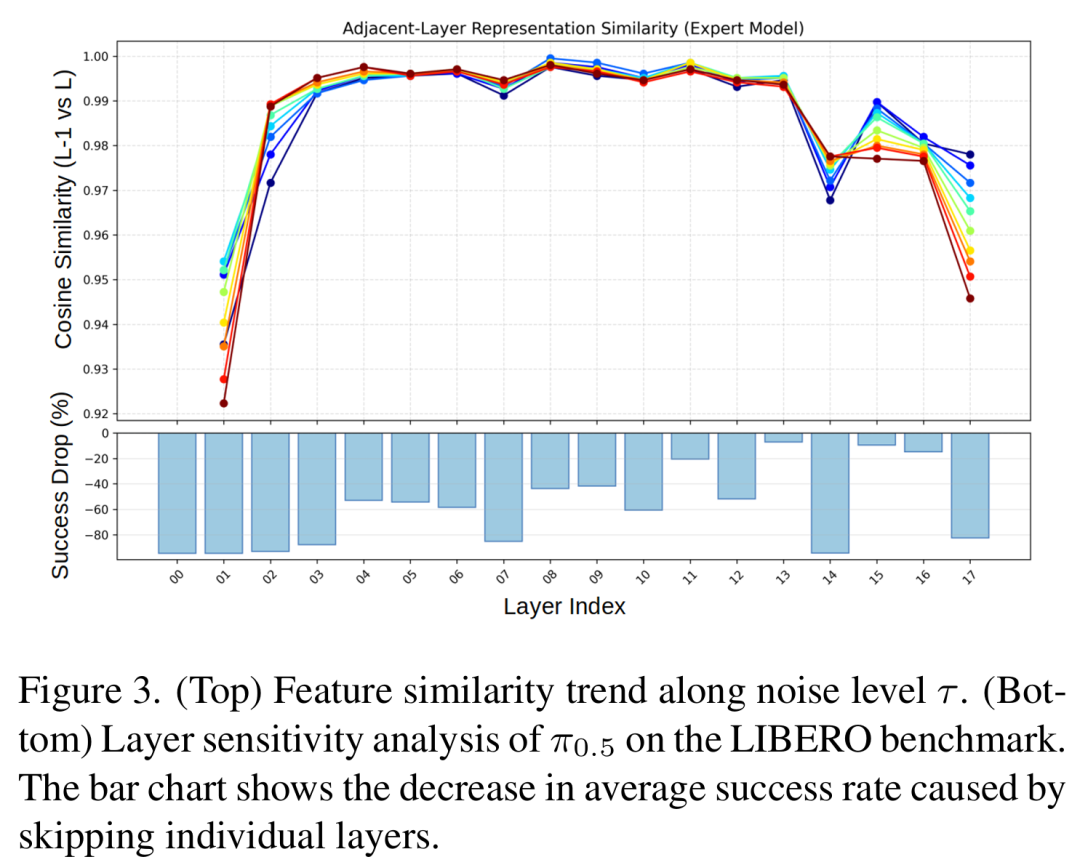
-
小型backbone方案:通过减少隐藏维度或早退机制构建小型VLM,但需从头训练,难以兼容预训练模型的泛化能力,且未优化动作头深度,而动作头的重复去噪计算正是流基模型的主要开销来源。 -
视觉token剪枝:通过减少视觉token数量降低计算量,但现代加速器对token级计算的并行化支持成熟,这类优化带来的延迟提升有限(figure2);而Transformer层的串行执行特性,使得层深度成为影响推理速度的关键因素。

-
论文标题:Shallow-π: Knowledge Distillation for Flow-based VLAs -
论文链接:https://arxiv.org/pdf/2601.20262 -
项目主页:https://icsl-jeon.github.io/shallow-pi/
二、核心方法:Shallow- 蒸馏框架
该框架的核心目标是通过知识蒸馏,同时压缩VLMbackbone与动作头的Transformer深度,在保持模型性能的前提下实现极致推理加速。其关键设计围绕“联合压缩”与“定制化蒸馏目标”展开。
1. 模型结构压缩
采用均匀子采样策略初始化浅层学生模型,将VLM backbone与动作头的Transformer层数从18层大幅削减至6层(部分实验中测试9层、4层)。这一初始化方式借鉴了TinyBERT的层选择逻辑,无需依赖复杂的层敏感性分析(实验验证,足够训练步数下,随机子采样与敏感性导向选择效果一致)。
2. 三重蒸馏目标设计
为实现学生模型对教师模型(预训练流基VLA)的行为对齐,设计了互补的三重损失函数:
-
任务损失():遵循标准流匹配范式,监督学生模型预测真实速度场,确保基础任务能力:
其中,为真实动作轨迹,为噪声向量。
-
知识蒸馏损失():引导学生模型匹配教师模型的预测速度场,利用教师的泛化能力提供额外监督:
其中为教师模型,为学生模型。
-
注意力蒸馏损失():针对流基VLA的架构特点定制——仅对齐动作token(a)与视觉-语言token(vl)的交叉注意力分布,而非所有token的注意力:
其中,KL为KL散度。
3. 注意力蒸馏的关键优化
-
token范围限制:流基VLA中,视觉-语言token仅作为条件上下文,动作token才是生成核心。若蒸馏所有token的注意力(包括视觉-语言token间的自注意力),会过度约束学生模型,干扰预训练表征,导致训练不稳定(table1(c))。

-
层位置选择:仅在中间层应用注意力蒸馏。早期层因初始化时直接复制教师底层,表征已对齐;顶层则通过任务损失与蒸馏损失实现输出对齐,无需额外约束。table1(b)显示,中间层应用时,6层模型的成功率达94.6%,显著高于早期层(93.9%)与后期层(94.1%)。
三、实验验证:性能与效率的双重突破
1. 模拟基准实验(LIBERO)
实验以和为教师模型,验证不同层数学生模型的性能。核心结果如下:
-
性能保留:蒸馏后的6层模型(-L6、-L6)平均成功率仅下降1%以内,其中-L6的平均成功率达95%,与教师模型(96%)几乎持平(table2)。
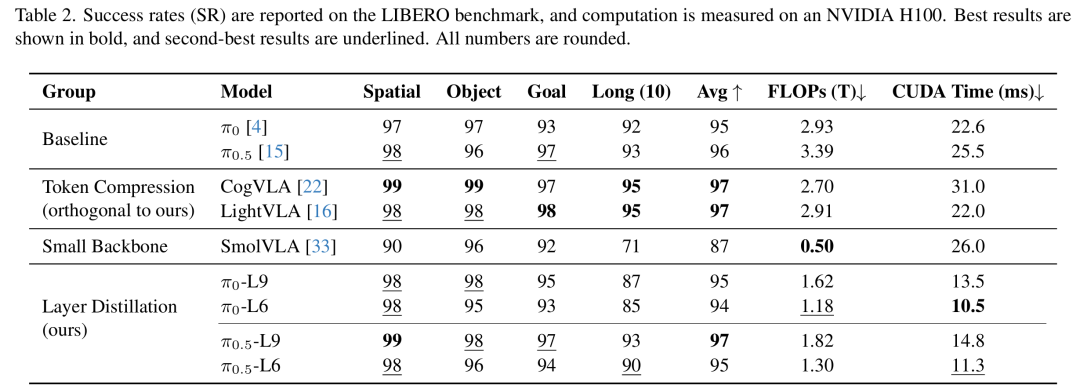
-
效率提升:FLOPs与CUDA推理时间均减少超过50%,-L6的推理时间仅10.5ms,较教师模型(22.6ms)提速2.15倍。 -
方案优越性:相较于从头训练的小型backbone模型(如SmolVLA),蒸馏模型在成功率(95% vs 87%)与推理延迟(10.5ms vs 26.0ms)上均占优,验证了蒸馏优于“从头训练小模型”的核心假设。
2. 真实世界实验(边缘设备部署)
在Jetson Orin(ALOHA机器人)与Jetson Thor(RB-Y1人形机器人)上,针对动态场景、复杂操纵任务与未见过的环境进行测试:
-
动态任务表现:在转盘(15deg/s)上的插销、泡沫插入等任务中,6层模型的成功率显著超越教师模型与SmolVLA。例如插销任务中,蒸馏模型实现10/10成功,教师模型为7/10,而SmolVLA完全失败(0/10);同时推理延迟降至110ms,较教师模型(364ms)减少254ms(table3)。

-
复杂任务适配:在需要手-躯干协同的回收、开盖插销任务中,的蒸馏模型成功率达85%(17/20),较教师模型(12/20)提升明显,推理时间从130ms降至78ms(table3)。 -
泛化能力:面对未见过的环境扰动(如插销初始位置偏移3cm、垃圾桶位移10cm),蒸馏模型仍保持良好性能(插销任务3/5成功,回收任务15/20成功),这得益于低延迟带来的更快观测更新,减少了开环执行导致的失败(figure11)。
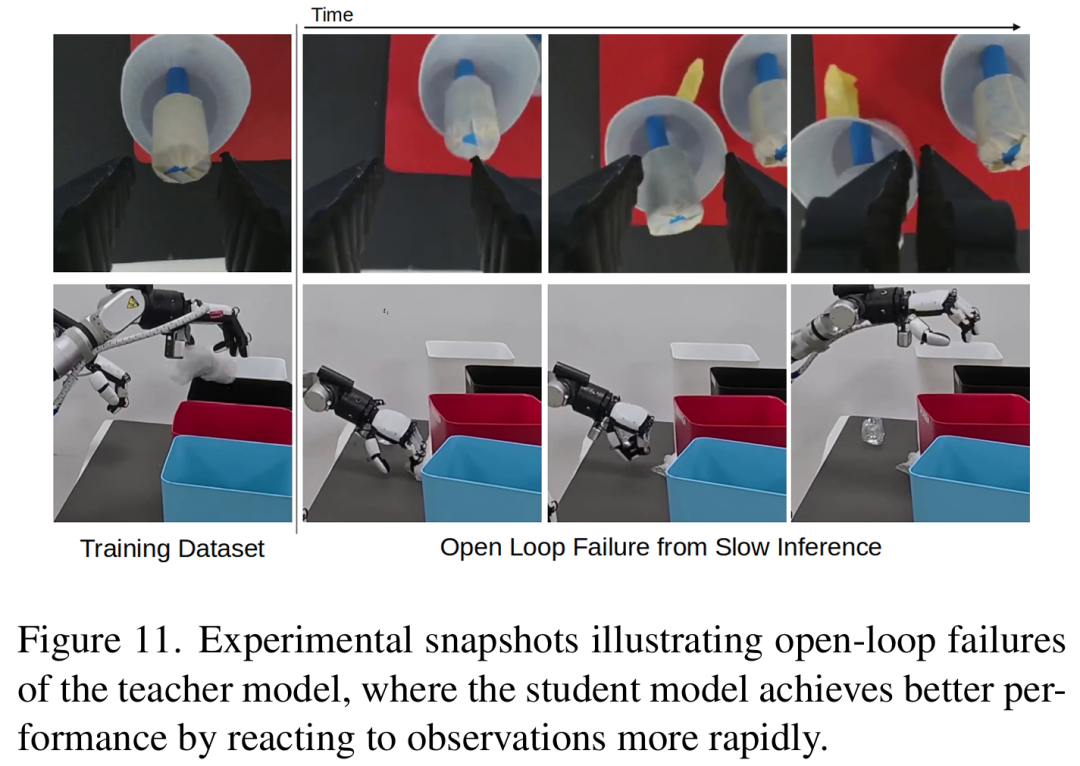
3. 关键现象验证
-
层减少 vs token减少:figure2清晰展示,减少Transformer层数对延迟的降低效果远优于减少视觉token。在H100 GPU上,层数从18减至4层,延迟下降3.3倍;而token从256减至64,延迟仅下降1.1倍。这是因为Transformer层串行执行,延迟直接累积;而token计算可并行化,现代GPU能高效处理。
-
跳层方法的局限性:figure4显示,当跳层数量超过3层,模型成功率骤降,即使基于敏感性排序选择跳层,也无法避免性能崩溃——这证明流基VLA的层功能与去噪动态深度耦合,单纯依赖相似度或敏感性的跳层策略难以替代结构化的蒸馏压缩。

四、结论与未来方向
核心贡献
-
提出首个针对流基VLA的联合蒸馏框架,实现VLM backbone与动作头的层数大幅削减(最高70%),同时保留层间特征传递的架构需求。 -
定制化设计三重蒸馏目标,尤其是中间层交叉注意力蒸馏,解决了流基模型中动作生成与条件上下文的对齐问题。 -
通过工业级边缘部署验证,在复杂动态场景中实现近10Hz的端到端推理,为实时机器人操纵提供了高效解决方案。
局限与未来
当前框架的主要局限是训练阶段需同时加载教师与学生模型,计算成本较高。未来可通过以下方向优化:
-
选择性冻结模型组件,降低蒸馏过程中的显存消耗; -
筛选高信息价值的训练样本,提升蒸馏效率; -
结合视觉token剪枝、扩散步数减少等互补优化方向,进一步提升推理吞吐量。










