

「时间连贯性」与「跨视角几何一致性」兼顾
在机器人操作任务中,生成具有时空一致性的视频对机器人理解环境动态至关重要。现有模型要么生成的视频画面闪烁、物体形变,要么不同视角下的空间位置错乱,严重制约了机器人在复杂场景中的规划与交互能力。
为此,斯坦福大学&丰田研究院团队提出的几何感知4D视频生成模型,通过融合时间连贯性与3D几何一致性,实现了跨视图的精准视频预测。
该方法的核心在于利用跨视图点图对齐的几何监督机制,结合预训练的视频扩散模型,使生成的视频既能保持时间序列上的平滑过渡,又能在不同相机视角下维持物体的几何结构一致性。

流程说明
基于扩散的视频生成框架
目标:从短暂的历史视频帧中预测未来短暂的视频帧,从而得到连贯的视频预测生成能力。
该方案采用的方法是利用视频扩散框架模型——Stable Video Diffusion(SVD)框架,通过变分自编码器(VAE)将历史RGB视频帧投影到潜在空间,再利用 U-Net网络的扩散能力来预测未来潜在图像序列的特征表示,最终将这些特征表示解码为RGB序列帧。
基于扩散的视频生成框架微调过程:就是通过最小化扩散损失函数,使模型能够从含噪的输入中恢复出干净的潜在表示,从而实现时间序列上的连贯预测。
几何一致性监督
如图所示,该方案的使用2个不同视角的 RGB-D相机 和来实现几何一致性监督。
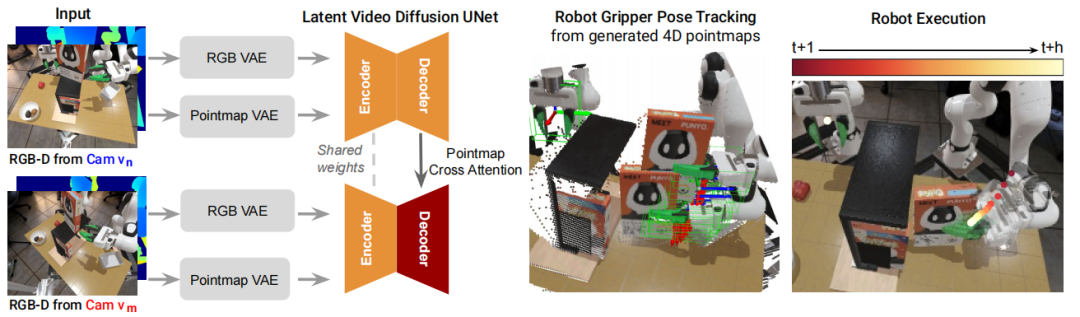
▲4D视频生成并用于机械臂操作的流程©️【深蓝具身智能】编译
先对参考视角的历史点图用点图 VAE 进行编码,经潜扩散和Decoder 后生成未来点图;
同时,将第二视角的未来点图投影到 坐标系下,生成投影点图序列,这些投影点图序列将被点图 VAE 编码成与 对齐的潜在表示。
在训练时,对 视角和投影视角的点图进行扩散,以求得最小化含噪的潜在表示和预测结果的差异。
该模型采用两个独立解码器,通过交叉注意力机制让的解码器通过提供的的几何线索来实现跨视角一致性,并且保障在推理过程中,无需输入相机位姿便可以从新视角预测出参考视角坐标系下的点图。
联合优化策略
预训练的视频扩散模型为预测动态场景提供了时间先验,而3D点图监督则强制跨视角图像之间保持几何一致性。
因此,利用预训练的视频模型,结合基于RGB的视频扩散损失和基于点图的3D一致性损失进行联合优化,便可以达到时空一致性的视频预测效果,其整体的损失函数可以表示成:
核心代码
接下来,让我们看看该方案的核心代码。
变分自编码器VAE的核心代码在sgm/models/autoencoder.py中的AutoencodingEngine。
编码器对应于sgm/modules/diffusionmodules/model.py 的Encoder。
编码器推理执行代码片段如下:
解码器对应于sgm/modules/autoencoding/temporal_ae.py的VideoDecoder。
解码器推理执行代码片段如下:
4D生成模型的核心代码在sgm/models/diffusion.py中的DiffusionEngine。
其中backbone采用U-Net模型,其核心代码在sgm\modules\diffusionmodules\video_model.py中的VideoUNet;
损失函数核心代码在sgm\modules\diffusionmodules\loss.py中的StandardDiffusionLoss
训练过程中重要的函数调用过程如下:
相关核心代码如下:
4D视频用于机械臂操作任务
1. 利用FoundationPose等现成的位姿跟踪模型,从预测的4D视频中提取出机器人末端执行器的6自由度位姿。
2. 通过分割机械臂手指点云并计算质心距离,判断gripper的开合状态,从而实现对下游操作任务的支持。


实验
实验任务设置
1. 模拟任务:
任务1-StoreCerealBoxUnderShelf:机械臂将麦片盒插入货架,涉及遮挡与精准定位。
任务2-PutSpatulaOnTable:抓取锅铲并放置在桌面上,考验对细长物体的操作能力。
任务3-PlaceAppleFromBowlIntoBin:双臂协作将苹果从碗中转移至bins,测试长时程多物体交互预测。

▲仿真中的机械臂操作任务©️【深蓝具身智能】编译
2. 真实任务:
复刻模拟中的PutSpatulaOnTable任务,使用两台FRAMOS D415e相机采集 RGB-D数据。

▲真实任务结果示例©️【深蓝具身智能】编译
评估指标
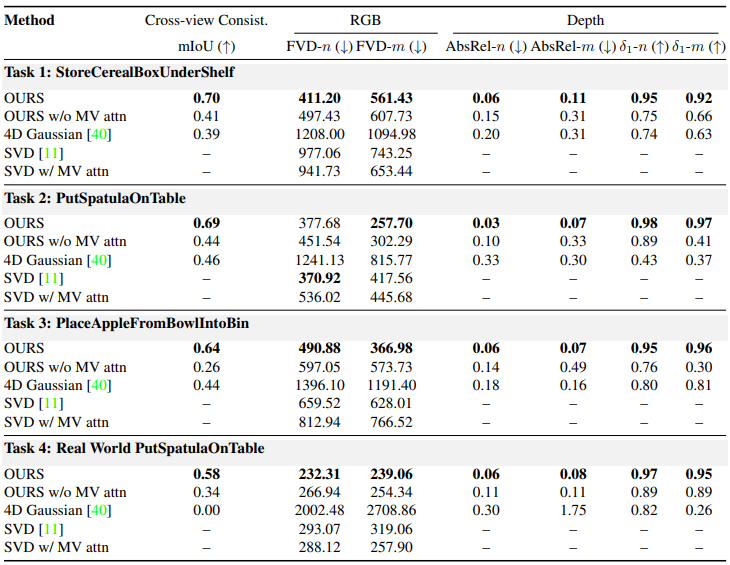
RGB视频质量:Fréchet Video Distance(FVD),数值越低表示生成的视频与真实视频的视觉差异越小。
深度预测精度:绝对相对误差(AbsRel):,衡量预测深度与真实深度的相对偏差。
阈值准确率(δ1):,反映深度预测的整体准确性。
跨视图3D一致性:平均交并比(mIoU),通过将一个视图的机械臂掩膜投影到另一个视图并计算IoU,评估几何对齐程度。
基线方法
OURS w/o MV attn:移除多视图交叉注意力的模型变体。
4D Gaussian:基于单视图RGB视频重建4D场景的方法。
SVD:原始Stable Video Diffusion模型,仅预测RGB视频。
SVD w/ MV attn:在SVD中添加多视图交叉注意力,但不使用点图监督。
▲在新型摄像机视图下生成的多视角4D视频结果©️【深蓝具身智能】编译
结果分析
几何一致性优势:OURS在所有任务中均表现出最高的mIoU值,证明几何监督有效促进了跨视图的3D结构对齐。移除交叉注意力后,mIoU显著下降,表明多视图信息交互的重要性。
视频与深度生成质量:OURS的FVD值显著低于基线,且深度预测的AbsRel更小、δ1更高,说明模型在视觉保真度和深度准确性上均有优势。
机器人策略效果:在操作任务中,OURS的平均成功率达0.64,远高于 Dreamitate(0.09)和Diffusion Policy(0.12),验证了生成视频对机器人控制的实际价值。
真实场景验证
在真实世界的PutSpatulaOnTable任务中,OURS生成的RGB-D序列能够准确捕捉机械臂的抓取动作,深度预测与实际场景吻合,且跨视图一致性的mIoU达0.58,证明了模型在真实环境中的泛化能力。

▲在“PutspatulaOnTable”任务上生成的真实世界4D视频结果©️【深蓝具身智能】编译

总结
本文提出的几何感知4D视频生成方法主要结合跨视图点图对齐监督和多视图交叉注意力机制,成功实现了时间连贯性与3D几何一致性的统一。
在模拟和真实场景中均能生成高质量的跨视图RGB-D视频,且可直接用于机器人末端执行器的位姿估计,为机器人操作任务提供可靠的视觉预测基础。
在未来工作中,可以进一步优化模型推理速度,并探索其在更复杂真实场景中的应用。
编译|木木伞
审编|具身君
标题:Geometry-aware 4D Video Generation for Robot Manipulation
作者:Zeyi Liu, Shuang Li, Eric Cousineau, Siyuan Feng, Benjamin Burchfiel, Shuran Song
项目地址:https://robot4dgen.github.io/
论文地址:https://arxiv.org/pdf/2507.01099
 【深蓝具身智能读者群】-参观机器人:
【深蓝具身智能读者群】-参观机器人:
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇



点击❤收藏并推荐本文










