
本文第一作者为清华大学计算机系的硕士二年级研究生葛晨笛,研究方向为多模态大语言模型、自动机器学习和图机器学习。主要合作者为来自阿里巴巴集团安全部的樊珈珮、黄龙涛和薛晖。通讯作者为清华大学的朱文武教授、王鑫副研究员。
近日,阿里巴巴集团安全部-交互内容安全团队与清华大学针对持续多模态指令微调的联合研究成果被机器学习顶级会议 ICML 2025 收录。本届 ICML 共收到 12,107 篇投稿,录用率为 26.9%。

论文标题:Dynamic Mixture of Curriculum LoRA Experts for Continual Multimodal Instruction Tuning
论文地址:https://arxiv.org/abs/2506.11672
代码链接:https://github.com/gcd19/D-MoLE
一、研究背景
多模态大语言模型(Multimodal Large Language Models, MLLMs) 通过结合视觉、语音等模态编码器与文本生成模型,展现出处理多模态数据的强大能力。然而,在实际应用中,预训练的 MLLM 会随着用户需求和任务类型的变化,不断面临新的适配要求。如果直接针对新任务进行微调,模型往往会出现灾难性遗忘(Catastrophic Forgetting),即丢失之前掌握的能力。
因此,如何让 MLLM 持续地适应新任务,同时保留过去的知识,成为一个核心挑战,这一问题被称为「持续多模态指令微调」(Continual Multimodal Instruction Tuning, CMIT)。
目前有关CMIT 的研究刚刚起步。常用的持续学习策略包括基于经验回放(replay) 和参数正则化的方法,但这些方法最初设计是针对较小规模、单模态模型的。在多模态大模型的场景下,这些固定架构的策略面临着两个新出现的挑战:
任务架构冲突:不同任务对模型不同层次有不同的依赖程度,统一固定的结构难以实现理想的适配效果。
为此,我们在 preliminary study 中具体量化了这一现象,发现在多模态任务的持续学习中,不同任务在模型的 Transformer 层具有明显不同的敏感程度。以视觉任务为例,部分任务对视觉编码器的较浅层依赖更多,而另一些任务则明显依赖语言模型的更深层。这表明简单的统一架构适配策略很难同时满足所有任务的需求,易导致部分层的参数冗余而另一部分层的参数更新不足。
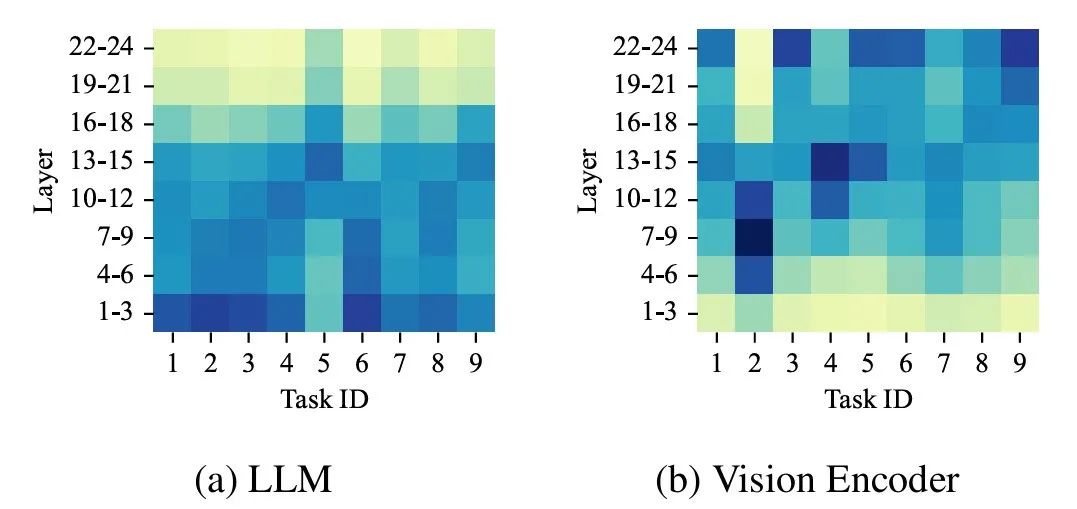
模态不均衡:不同任务对图像、文本等不同模态的依赖程度差别较大,容易导致训练过程中各模态更新程度的不平衡。
同样在 preliminary study 中,我们跟踪分析了模型在训练不同任务时,视觉和文本模态的参数更新幅度变化,结果清晰显示,有些任务以文本模态更新为主,而另一些则明显偏重视觉模态更新。这种模态依赖的不均衡性导致部分模态模块的优化不足,整体性能受到影响。

为了应对这些挑战,本研究团队提出了一种新的持续多模态指令微调框架D-MoLE,打破了传统模型结构固定的思路,允许模型在参数预算受控的条件下,根据任务需求动态地调整模型架构。具体而言,D-MoLE 能够按需在关键层引入额外的参数模块(LoRA 专家),精准地缓解任务架构冲突;同时,通过引入基于梯度的持续学习课程策略,自动平衡不同模态模块的更新比例,使得各模态能够获得更加均衡的优化。
二、论文摘要
持续的多模态指令微调(Continual Multimodal Instruction Tuning, CMIT) 对于多模态大语言模型(MLLM) 适应不断变化的任务需求至关重要。然而,目前主流方法大多依赖固定的模型架构,难以灵活应对新任务,因为它们的模型容量在设计之初就被限定住了。
我们提出一种在参数预算受限条件下进行架构动态调整的方法,用于提升模型在持续学习过程中的适应能力。这个方向此前几乎没有被探索,但它同时带来了两个关键挑战:其一,不同任务对模型的层级结构有不同的依赖,容易引发「架构冲突」;其二,不同任务对视觉和文本等模态的依赖强度不一,可能导致训练过程中的「模态不均衡」。
为此,我们提出了D-MoLE(Dynamic Mixture of Curriculum LoRA Experts) 方法,在有限参数预算下实现模型架构的按需演化,从而持续适配新任务,同时保留已有知识。
具体来说,D-MoLE 包含两个核心模块:一个是动态按层专家分配器,用于识别当前任务最需要适配的关键层并分配 LoRA 专家;另一个是基于梯度的跨模态课程机制,根据当前任务对不同模态的学习难度,动态调整语言模型与模态编码器的更新比例,从而缓解模态不均衡问题。
实验结果表明,D-MoLE 在多个任务的持续学习评估中表现优异,在平均指标(AVG) 上相较当前最强基线提升约 15%。据我们了解,这是首个从模型架构演化的角度系统研究 MLLM 持续学习问题的工作。
三、方法解读
D-MoLE 框架的核心思想在于通过动态调整模型结构和学习策略,以应对持续学习中的任务架构冲突和模态不平衡问题。整体框架如论文图 3(下图) 所示,主要包含动态分层专家分配器和基于梯度的跨模态持续课程两大核心组件。

动态分层专家分配器(Dynamic Layer-Wise Expert Allocator) 与常规 MoLE 的区别
常规的LoRA 专家混合(Mixture of LoRA Experts, MoLE) 方法通常是将多个 LoRA 模块(视为「专家」) 集成到模型中,并使用一个路由机制来为不同的输入选择性地激活部分专家。D-MoLE 在此基础上,针对持续学习的特性进行了关键创新。我们可以从其核心运作公式(即论文中的公式 2)来理解其独特性:
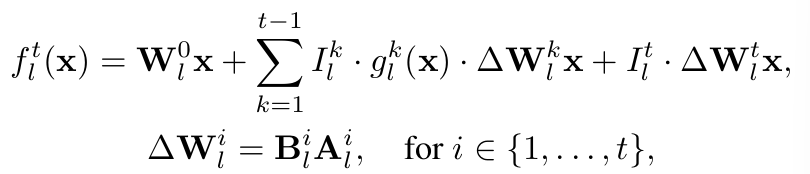
该公式描述了在学习第 t 个新任务时,模型第 1 层的输出是如何构成的。它主要包含三部分:
基础知识(
 ):这是模型第
):这是模型第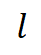 层原始预训练权重
层原始预训练权重  对输入
对输入 的处理结果。它代表模型的通用能力,在持续学习中保持不变。
的处理结果。它代表模型的通用能力,在持续学习中保持不变。
历史经验的动态调用(
 ):这代表模型从过去已学习的任务(任务 1 到 t−1) 中提取的相关知识。
):这代表模型从过去已学习的任务(任务 1 到 t−1) 中提取的相关知识。
 是过去第
是过去第 个任务的 LoRA 专家(一种小型的、可训练的适配器模块) 在第
个任务的 LoRA 专家(一种小型的、可训练的适配器模块) 在第 层的输出。
层的输出。
 标记了过去任务
标记了过去任务 时第
时第 层是否真的分配了这样一个 LoRA 专家。
层是否真的分配了这样一个 LoRA 专家。
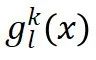 是一个门控函数,它会判断当前输入
是一个门控函数,它会判断当前输入 与历史任务
与历史任务 的相关性,从而决定该历史专家的激活程度。这意味着模型能智能地、有选择地重用最相关的历史经验。
的相关性,从而决定该历史专家的激活程度。这意味着模型能智能地、有选择地重用最相关的历史经验。
新知识的学习
 :这部分是专门为当前新任务
:这部分是专门为当前新任务 学习的内容。
学习的内容。
 是为当前任务
是为当前任务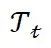 在第
在第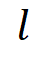 层新分配并训练的 LoRA 专家的输出。
层新分配并训练的 LoRA 专家的输出。
 标记了当前新任务
标记了当前新任务 是否在第
是否在第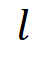 层分配了新的 LoRA 专家。这个决策是动态的,基于对新任务的分析,而非预设。
层分配了新的 LoRA 专家。这个决策是动态的,基于对新任务的分析,而非预设。
核心思想:这种设计的核心在于动态和选择性。模型不是简单地累积所有知识,也不是为每个新任务都重新调整所有层。而是:
保留通用基础:冻结大部分预训练参数。
按需适配新任务:通过「零成本代理评估」(快速分析任务对各层的影响),D-MoLE 仅在对新任务最关键的层 (即
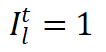 的层) 动态引入新的、轻量化的 LoRA 专家进行针对性学习。
的层) 动态引入新的、轻量化的 LoRA 专家进行针对性学习。
情境化利用旧经验:通过门控机制,模型可以根据当前输入数据的特性,智能地激活那些最相关的历史 LoRA 专家,实现有效知识迁移,同时避免不相关历史经验的干扰。
这种策略使得模型能够在参数预算受控的情况下,高效地适应新任务,同时最大限度地保留和利用过往的知识。
基于梯度的跨模态持续课程(Gradient-Based Inter-Modal Continual Curriculum)
该模块用于解决「模态不平衡」问题。在多模态学习中,不同任务对图像、文本等不同模态的依赖程度各异。
核心思想:D-MoLE 不再对所有模态一视同仁。它首先通过「零成本代理评估」分别判断整个视觉编码器和整个语言模型对当前新任务的整体「敏感度」或「学习难度」。
预算动态分配:基于评估出的各模态「学习难度」,此模块会动态地调整分配给视觉和语言部分的参数预算(即允许放置多少新的 LoRA 专家)。「学习难度」更大(即对任务更敏感、更需要调整) 的模态会获得更多的参数预算。
协同工作:这个分配好的、针对不同模态的预算,会进一步指导「动态分层专家分配器」具体在哪些层、为哪个模态放置 LoRA 专家。
当一个新任务到来时,D-MoLE 的工作流程大致如下:
快速评估:首先,模型用少量新任务的数据样本进行一次「演练」(即零成本代理评估),快速了解这个新任务对模型哪些层、哪些模态(视觉/语言) 的挑战比较大。
动态预算:基于上述评估结果,「跨模态持续课程」模块会决定在这个新任务上,应该给视觉部分多一点「学习资源」(参数预算),还是给语言部分多一点。挑战大的模态会分到更多预算。
精准部署新专家:「动态分层专家分配器」拿着各个模态分到的预算,在各自模态内部,把新的 LoRA 专家模块(可训练的小型网络结构) 安装到那些在步骤 1 中被识别为对新任务「最敏感」或「最关键」的层上。
旧知识导航:训练一个轻量级的「导航员」(自编码器路由),它能判断当前新任务的输入数据和以前哪个老任务最像。
针对性训练:开始正式学习新任务。此时,模型的绝大部分原始参数和为老任务安装的 LoRA 专家都保持「冻结」状态,只有刚刚为新任务精准部署上的那些新 LoRA 专家才参与训练。在训练时,步骤 4 的「导航员」会唤醒与当前输入最匹配的那些「旧专家」,让它们也贡献一部分智慧,帮助新专家学得更好更快。
推理应用:学习完毕后,当模型处理新的多模态输入时,「导航员」会再次判断输入数据和哪个(或哪些) 任务最相关,然后激活相应的 LoRA 专家(可能是新任务的,也可能是相关的旧任务的) 来共同完成任务。
通过这一系列动态和自适应的策略,D-MoLE 旨在让多模态大模型在持续学习新知识时,既能学得好、学得快,又能有效减少对旧知识的遗忘。
四、实验结果
研究团队构建了一个包含视觉问答(VQA)、图像描述(Image Captioning) 和视觉定位(Visual Grounding) 三大类共 9 个数据集的持续多模态指令微调(CMIT) 基准。实验采用的预训练 MLLM 是 InternVL2-2B。评估指标主要包括:
AVG:模型在所有任务上,在整个持续学习过程中的平均性能。
Last:模型在学完所有任务后,在各个任务上的最终性能。
BWT(Backward Transfer):向后迁移,衡量学习新任务后,旧任务性能的下降程度(越接近 0 越好,负值越大表示遗忘越严重)。

主要结果对比
如上表所示,D-MoLE 在 AVG、Last 和 BWT 三个关键指标上均显著优于所有对比的基线方法。与表现次优的 O-LORA 方法相比,D-MoLE 在 AVG 指标上平均提升了约 15.08%,在 Last 指标上提升了约 20.14%,在 BWT 指标上更是将平均遗忘从 -21.31% 大幅改善至 -1.49%。这充分证明了 D-MoLE 在持续学习过程中的任务适应能力和抗遗忘能力。传统的持续学习方法如 LwF-LORA 和 EWC-LORA,即使结合了参数高效微调技术 LoRA,在 CMIT 场景下表现不佳,遗忘严重。而一些基于 LoRA 专家混合(MoLE-based) 的方法(如 Dense MoLE, Sparse MoLE, MoLA) 虽有改进,但效果仍不如 D-MoLE,这凸显了 D-MoLE 动态架构调整和课程学习策略的优越性。
通用能力评估
为了检验模型在持续学习后是否保持了通用多模态能力,研究团队在三个通用的MLLM 评测基准 MME、MMMU 和 POPE 上对学完所有 9 个任务后的模型进行了评估。

结果如上表所示,与直接对每个任务进行顺序微调(Seq-FT) 和 O-LORA 相比,D-MoLE 在这些通用能力测试中表现更好,更接近原始预训练模型(Zero-Shot) 的水平。这表明 D-MoLE 在适应新任务的同时,能更好地保持模型原有的基础能力。
消融实验

为了验证D-MoLE 中各个组件的有效性,研究团队进行了一系列消融实验:
v1(仅微调 LLM) 和 v2(仅微调视觉编码器):结果显示,单单更新一个模态效果很差,说明多模态协同适应的重要性。
v3(移除跨模态课程):性能有所下降,表明基于梯度的模态难度评估和预算动态分配是有效的。
v4(移除动态分层专家分配器,均匀分配 LoRA):性能大幅下降,证明了根据任务敏感度动态分配 LoRA 专家到关键层对于缓解架构冲突和提升性能至关重要。
这些结果清晰地表明 D-MoLE 的每个精心设计的组件都对其优越性能做出了贡献。
训练效率

尽管D-MoLE 引入了零成本代理评估和动态分配机制,但其总训练时间(12.40 小时) 与 vanilla LoRA 微调(Seq-FT, 13.15 小时) 相当,甚至略优,并快于其他一些复杂的持续学习方法(如 MOLA, 23.03 小时)。这是因为 D-MoLE 通过选择性地在关键层插入 LoRA 模块,而不是在所有层都插入,从而减少了实际参与训练的参数量和反向传播的计算量。零成本代理评估本身计算开销很小(约占总训练时间的 1.45%)。
五、业务应用
D-MoLE 可以用于提升阿里安全多模态审核大模型在交互内容安全场景下的持续适应能力。具体而言,模型需要同时支持多个平台的图文审核,而不同平台的审核规则存在差异,且会随着时间不断变化。
借助 D-MoLE,模型能够在不影响原有能力的前提下,快速适配新的平台或规则,只需引入少量参数即可完成扩展,无需重复训练整个模型。这有助于降低运维成本,提升模型在多任务、多平台环境中的灵活性与长期可用性。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










