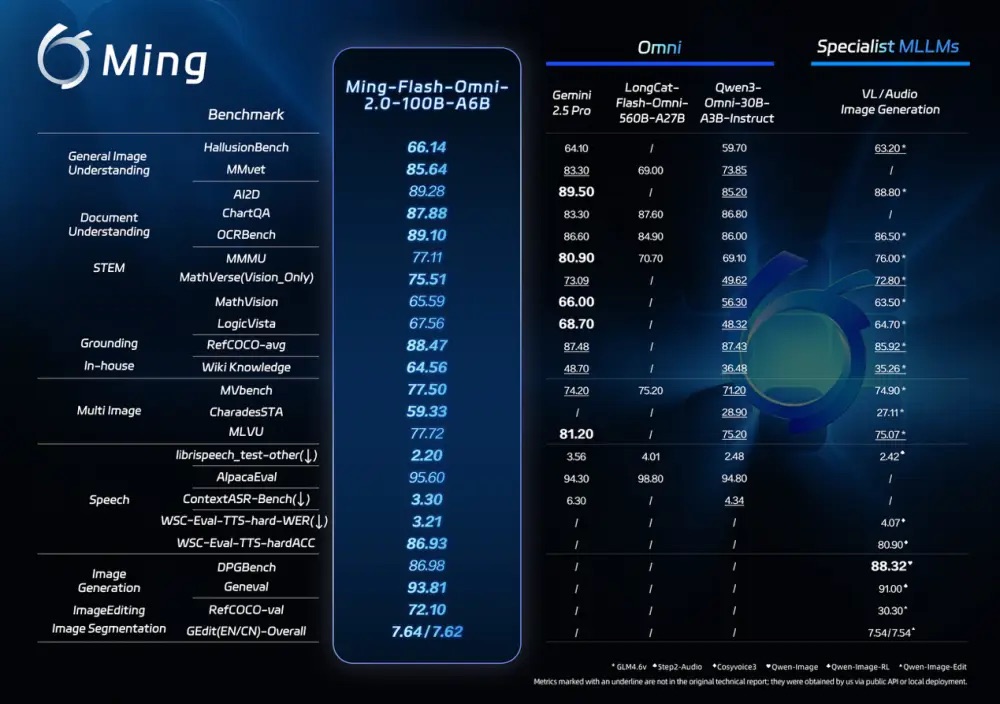
【区角快讯】2026年2月11日,蚂蚁集团正式对外开源其最新一代全模态大模型Ming-Flash-Omni 2.0。该模型在多项公开基准测试中展现出卓越性能,尤其在视觉语言理解、语音可控生成以及图像生成与编辑等核心能力上表现突出,部分指标已超越Gemini 2.5 Pro,被业界视为当前开源全模态大模型的性能新标杆。
Ming-Flash-Omni 2.0同时也是业内首个支持全场景音频统一生成的模型,能够在单一音轨内同步合成语音、环境音效与背景音乐。用户仅需通过自然语言指令,即可对音色、语速、语调、音量、情绪乃至方言等参数实施精细化调控。
在推理效率方面,该模型实现了3.1Hz的极低推理帧率,能够实时生成高保真度的分钟级长音频,在兼顾生成质量的同时显著优化了计算成本与响应速度,处于行业领先水平。
蚂蚁集团在全模态技术领域已深耕多年,Ming-Omni系列历经三次迭代,此次开源Ming-Flash-Omni 2.0标志着其将核心能力以“可复用底座”形式开放,旨在为开发者提供端到端的多模态应用统一入口。
据披露,该模型基于Ling-2.0架构(MoE,100B-A6B)训练,围绕“看得更准、听得更细、生成更稳”三大目标进行系统性优化。在视觉任务中,融合亿级细粒度数据与难例训练策略,显著提升了对近缘动植物、工艺细节及稀有文物等复杂对象的识别精度;音频模块支持语音、音效与音乐同轨生成,并具备零样本音色克隆与定制能力;图像生成方面则强化了复杂编辑的稳定性,涵盖光影调整、场景替换、人物姿态优化及一键修图等功能,即便在动态场景下也能维持画面连贯性与细节真实性。
目前,Ming-Flash-Omni 2.0的模型权重与推理代码已在Hugging Face等主流开源平台发布,用户亦可通过蚂蚁百灵官方平台Ling Studio在线体验和调用相关功能。
随着多模态AI逐步迈向统一架构时代,此类开源底座的推出有望加速跨模态应用的开发效率与落地进程。