RAM团队 投稿
量子位 | 公众号 QbitAI
让大模型像人类一样阅读!通过精读略读实现性能与效率的双重飞跃。
在长上下文场景中,Transformer架构的二次计算复杂度让推理速度急剧下降,而人类面对长文档时却能游刃有余——我们不会逐字阅读整本小说,而是对关键情节精读,对背景描述略读。

来自清华大学、鹏城实验室与阿里巴巴未来生活实验室的联合研究团队发现:现有任务相关的压缩方法不仅陷入效率瓶颈——要么一次性加载全文(效率低),要么自回归逐步压缩(速度慢),更难以兼顾“保留关键信息”与“保持自然语言可解释性”。
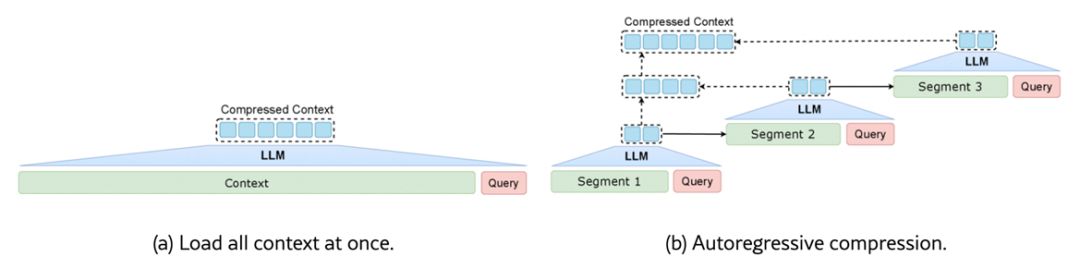
受人类阅读认知启发,他们提出全新框架RAM(Read As HuMan),首次将“精读+略读”的混合策略引入上下文压缩,不仅在多个长文本基准上取得卓越表现,更在平均1.6万token的输入上实现12倍端到端加速。
像人类一样阅读:精读重要内容,略读背景内容
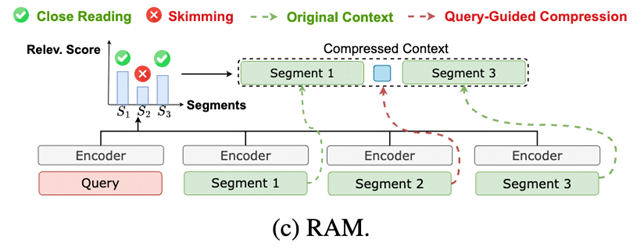
研究团队从认知科学中汲取灵感:人类阅读时会动态分配注意力——对与目标高度相关的内容进行精读(close reading),保留全部语义细节;对次要背景信息采用略读(skimming),快速提取核心语义。
RAM将这一行为转化为可计算的自适应压缩策略:
精读区:高相关片段完整保留原始文本,确保关键信息零损失,维持自然语言可解释性
略读区:低相关片段通过查询引导压缩为单个语义向量,极致削减冗余内容
混合表示:精读文本与略读向量按原顺序拼接,形成“显式+隐式”混合上下文,既保留关键细节又大幅缩短长度
更关键的是,RAM突破了现有方法的效率瓶颈:所有片段与查询并行编码,彻底规避了全文一次性加载的二次复杂度,也摆脱了自回归压缩的串行等待,真正实现“压缩即推理”的高效流水线。
授人以渔:让模型学会“何时精读、何时略读”
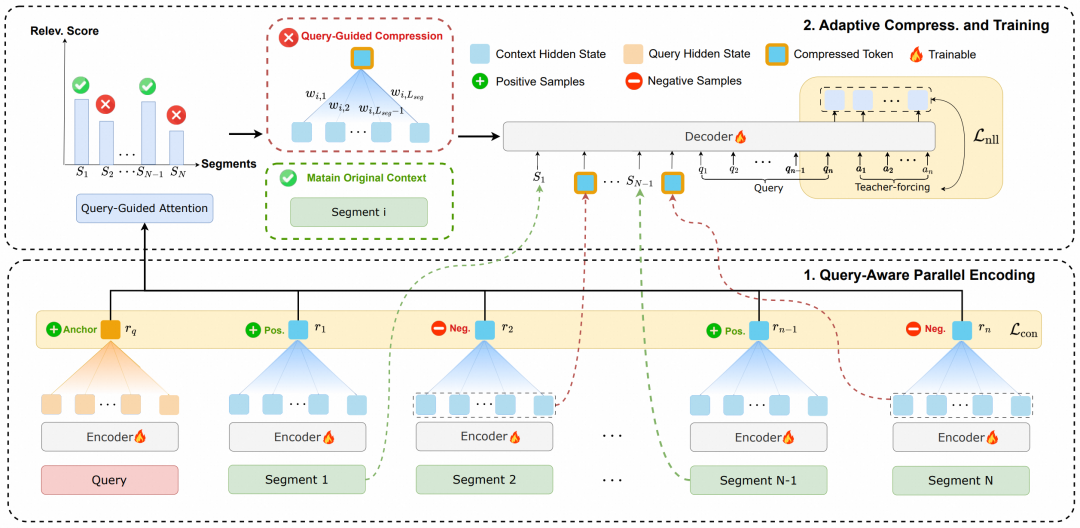
仅有策略不够,如何让模型精准判断“哪些内容值得精读”?RAM引入对比学习优化决策边界:
利用正负样本对(含答案片段/无关片段)训练查询-片段相关性判别器
通查询引导的注意力计算计算片段重要性,动态决定段落的保留(精读)和压缩(略读)
略读过程采用查询引导加权平均:对每个token计算与查询的相似度,聚焦提取与任务相关的语义“精华”
这种设计使RAM在训练阶段仅需单次训练,即可泛化至多种任务(问答、摘要)与任意压缩比例(2x–32x)。更令人惊喜的是,尽管训练时最大长度仅2万token,RAM在3.2万tokens的NarrativeQA测试中性能反超未压缩原文,展现出强大的长度外推能力——它学会的不是记忆固定模式,而是组合式语义表征。
实践出真知:效率与性能的双重飞跃
多种任务上表现出色
在NaturalQuestions、HotpotQA等四大问答基准与MultiNews摘要任务上,RAM以LLaMA-3.1-8B和Qwen3-4B为基座,在4x/8x压缩下均展现出优越性能。以Qwen3-4B为例,4x压缩时EM分数达66.59(输入原文时32.77),证明压缩非但未损伤性能,反而通过去噪提升了推理质量。
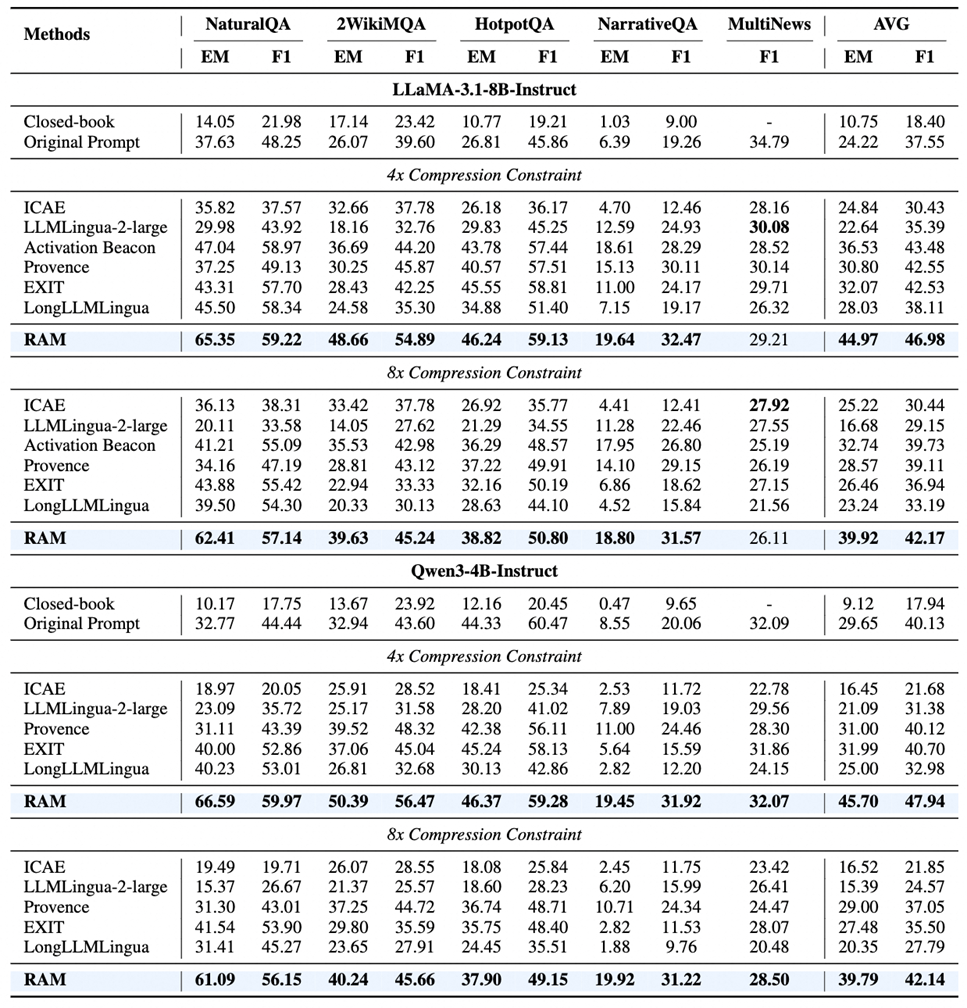
12倍加速,长文秒级响应
在平均1.6万token、最长3.2万token设置的NarrativeQA数据集上,RAM端到端延迟仅0.20秒(32x压缩),相比于输入原始提示词(端到端时延1.23秒)——提速约6倍。压缩阶段耗时仅0.08秒,真正实现“压缩成本可忽略”。
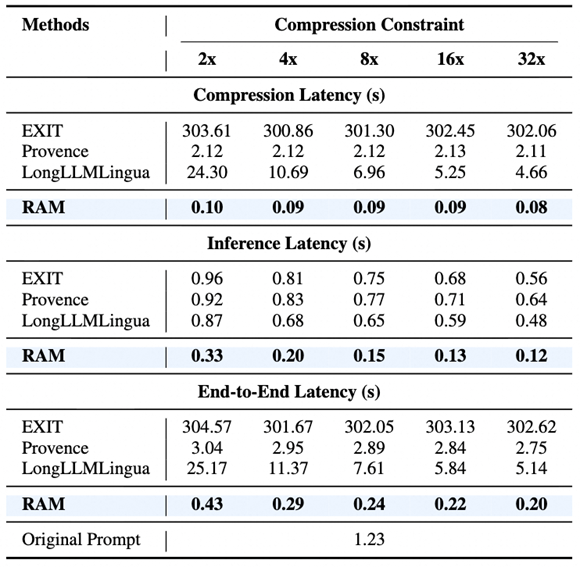
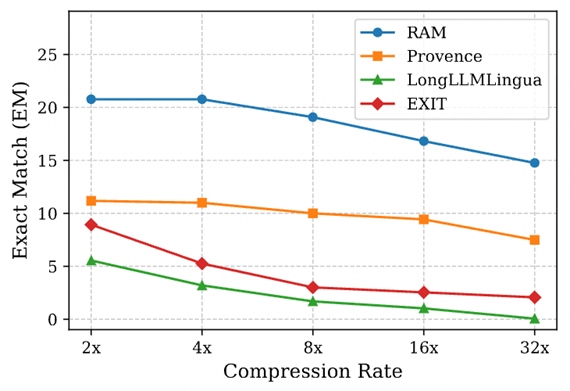
压缩鲁棒性:从2x到32x稳如磐石
当压缩率从2x提升至32x,RAM的EM分数仍稳定高于基线。这证明RAM在各种压缩率下的表现具有鲁棒性,从2倍压缩率到32倍压缩率稳如磐石。
总结
RAM的工作为长上下文LLM部署提供了新范式:它不再将压缩视为“不得已的妥协”,而是通过模拟人类认知策略,将效率与性能转化为协同增益。
方法论创新:首次将“精读+略读”混合策略算法化,打破效率-保真度权衡
工程突破:并行化设计使压缩成本趋近于零,真正满足工业级实时需求
认知启示:证明借鉴人类信息处理机制,可为AI系统设计提供强大灵感
当大模型学会像人类一样“有重点地阅读”,长文本不再是负担,而是可高效驾驭的知识海洋。RAM不仅压缩了上下文长度,更压缩了AI与人类认知之间的距离。
论文标题:
Read As Human: Compressing Context via Parallelizable Close Reading and Skimming
论文链接:
https://arxiv.org/abs/2602.01840
代码链接:
https://github.com/Twilightaaa/RAM
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟










