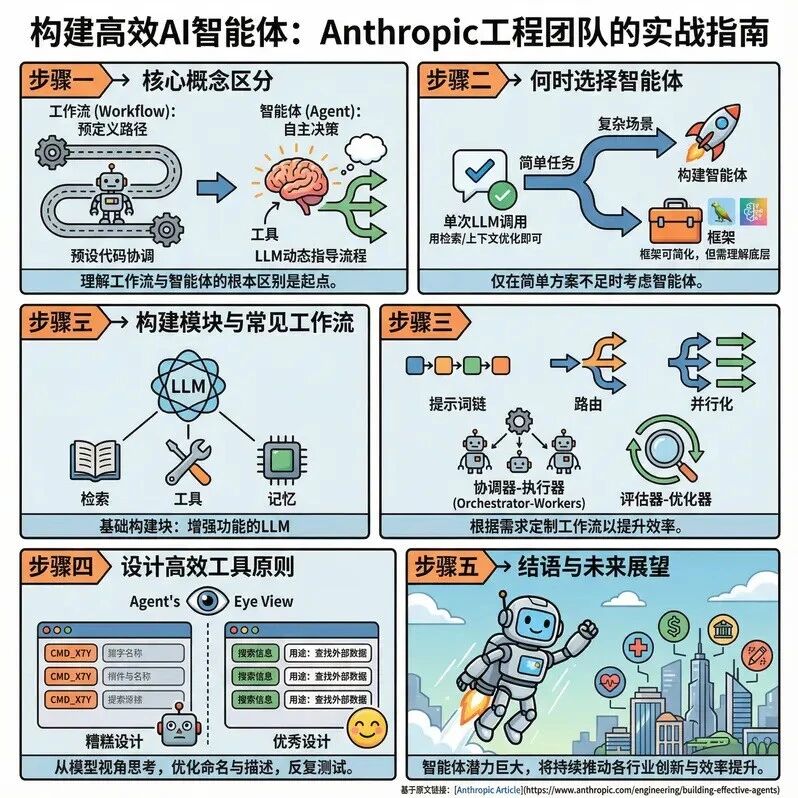
本文来自香港浸会大学和上海交通大学的可信机器学习和推理组,已被 ICLR 2026 接收。
目前,RLVR(Reinforcement Learning with Verifiable Rewards)已成为诱导大语言模型推理能力的主流技术路线。然而,RLVR 需要高质量标注数据来监督奖励获取,这一点是其可扩展性上的主要瓶颈。
一旦走向不需要标注数据的 “自奖励(Self-rewarding)” 强化学习训练,模型往往会迅速陷入训练崩溃(Training Collapse),看似获取的奖励(Reward)越来越高,实际上却是在利用自我奖励规则中的漏洞进行奖励投机(Reward Hacking),而非真正答对问题获取奖励。
究竟什么样的强化学习(Reinforcement Learning,RL)训练范式,才能在无需真实(Ground-truth)答案标注的情况下,实现稳定的 RL 训练,诱导出模型的推理能力?
针对这一挑战,来自香港浸会大学和上海交通大学的可信机器学习和推理组提出了一个全新的自监督 RL 框架 ——Co-rewarding。该框架通过在数据端或模型端引入互补视角的自监督信号,稳定奖励获取,提升 RL 过程中模型奖励投机的难度,从而有效避免 RL 训练崩溃,实现稳定训练和模型推理能力的诱导。

论文标题:Co-rewarding: Stable Self-supervised RL for Eliciting Reasoning in Large Language Models
论文链接:
代码链接:
Huggingface 链接:
自我奖励策略训练模型为什么会导致训练崩溃?
在缺乏标注数据的场景下,目前的自我奖励策略均是通过强化模型的自信心来进行训练,主要分为两个类别:(1)基于熵(Entropy)的方法:通过最小化模型输出内容的熵(Entropy),或最大化自我确定性(Self-certainty)等指标来强化模型的信心;(2)基于一致的方法:让模型针对同一个问题多次输出后,进行多数投票(Majority-voting)得到伪标签(Pseudo label)来监督 RL 训练。

图 1:左边 4 个图为训练过程中验证集上的性能曲线。右边 2 个图为训练过程中的奖励(Reward)曲线。
无论是哪一类方法,它们都是让当前模型从单一视角产生信号监督自己。这极易让模型进行奖励投机,以一种最容易方式拿到奖励,而不是产生正确的推理路径。这就像让学生自己监督自己学习时,学生会自己 “开小差” 一样。如图 1 所示,模型会发现重复输出部分 token 可以使得熵最小;模型输出一个一致但错误的答案,也可以拿到奖励。这就模型在 RL 的自我奖励机制中以投机的方式获取到最高奖励,奖励获取与推理正确性逐步脱钩,进而导致训练崩溃。

图 2:Co-rewarding 框架示意图。不同于单视角自我监督的方法,(a) Co-rewarding 引入其他视角互补的监督信号;(b) 从数据视角,Co-rewarding-I 使用原题和改写题进行相互监督;(c) 从模型视角,Co-rewarding-II 使用一个教师参考模型产生伪标签监督当前模型。
Co-rewarding 提出关键转变:互补视角进行监督和奖励
针对这一挑战,Co-rewarding 提出避免训练崩溃的关键转变:不再相信单一视角的监督信号,而是主动引入 “互补视角的监督”,进而增加模型奖励投机的难度。具体来看,Co-rewarding 分别从数据视角和模型视角给出两种实现。
方法一:Co-rewarding-I(数据视角)
如图 2 (b) 所示,Co-rewarding-I 从数据层面引入互补监督信号,对原问题构建语义等价但表述不同的改写问题(Rephrased Questions),利用原问题与改写问题之间的 “类比一致性” 进行相互监督:
对原题与改写题分别进行多次采样,生成回答。
用原题回答进行多数投票得到的伪标签去监督改写题,用改写题回答多数投票得到的伪标签监督原题。
这种设计的关键在于:模型必须在不同表述下保持推理结果的一致性,才能持续获得奖励。相比单一视角下的一致性自洽,跨问题的一致性显著提高了奖励投机的难度,从而有效缓解训练崩溃问题。
方法二:Co-rewarding-II(模型视角)
如图 2 (c) 所示,Co-rewarding-II 从模型层面解开监督信号与当前 Policy 模型训练之间的耦合,即监督信号所需要的伪标签不是从当前 Policy 模型得到,而是一个另外的教师模型,这进一步降低了当前 Policy 模型对于奖励信号的控制,增强了奖励投机的难度:
教师模型针对一个问题,生成多次推理回答,并多数投票产生伪标签。
学生 Policy 模型基于教师提供的伪标签进行奖励获取和 RL 训练。
教师模型无需引入一个额外的模型,而是由学生模型通过 EMA(指数滑动平均) 更新参考模型(Reference Model)得到。
这种 “慢更新教师 + 快更新学生” 的结构,本质上是一种时间解耦的自蒸馏(Self-distillation)机制,能够有效避免当前 Policy 模型对于奖励信号的操纵,从而显著降低训练崩溃风险。
实验结果:不仅更加稳定,而且性能更强
在多个训练集(MATH、DAPO-14k)、模型系列(Qwen2.5/3、Llama)上进行实验。并在多个数学推理、代码生成和通用领域基准数据集上进行评估,Co-rewarding 均展现出相比于现有自我奖励方法的优势:

表 1:在 MATH 训练集上的性能对比,颜色越深表示相同组内性能越好。Co-rewarding-I 相比于最好的自我奖励的基线方法在 4 个数学相关的基准上的平均性能提升达到 + 4.42%
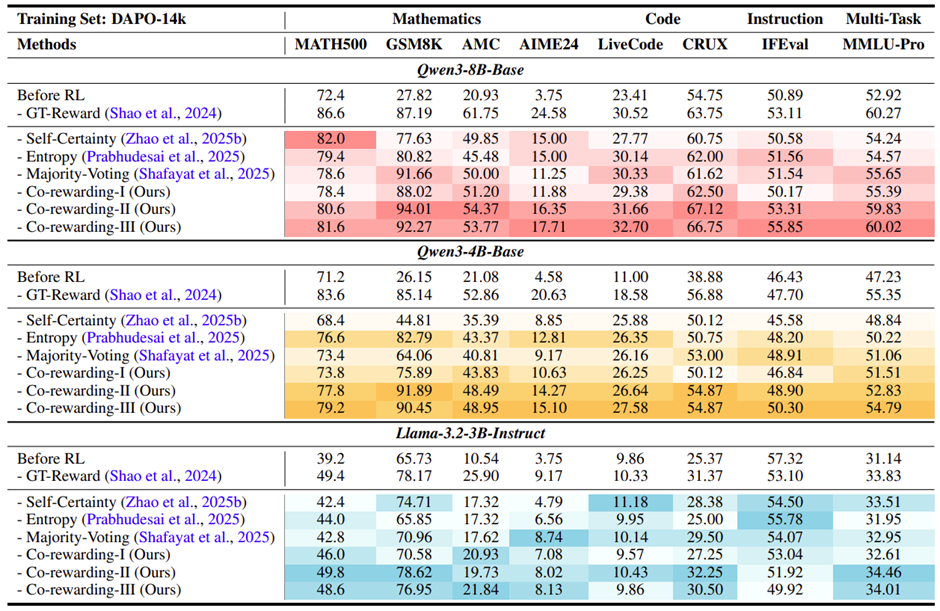
表 2:在 DAPO-14K 训练集上的性能对比,颜色越深表示相同组内性能越好。Co-rewarding-II 相比于最好的自我奖励基线方法在 4 个数学相关的基准上的平均提升达到 + 12.90%
从表 1 中得到,在 4 个数学推理基准上,相比于最好的自奖励方法,Co-rewarding-I 平均性能提升达到 + 4.42%。从表 2 中得到,Co-rewarding-II 平均性能提升达到 + 12.90%。
在一些情况下,Co-rewarding 甚至超越了真实答案进行监督的 RL 训练得到模型,例如 Qwen3-8B-Base 基于 Co-rewarding-II 在 GSM8K 上达到了 Pass@1 为 94.01%。
从图 1 中观察得到,Co-rewarding 在训练过程中,验证集上的性能曲线持续提升,奖励持续获取,无训练崩溃和奖励劫持现象发生。
Co-rewarding 在数学相关的训练集上进行训练,在代码生成的基准上依旧取得性能提升。
Co-rewarding 在 MMLU-Pro 和 IFEval 等多任务和通用领域基准上性能保持稳定,未牺牲模型通用领域的性能。
Co-rewarding 带来的启发
自监督强化学习的关键,在于构造更 “可靠” 的监督信号来维持稳定和持续的学习。通过引入互补视角的奖励监督机制,Co-rewarding 证明了:即便没有人工标注,通过合理可靠的自我奖励机制,大模型也可以稳定、持续地诱导出推理能力。这反应了自监督强化学习的潜力,在摆脱对于标注数据依赖的同时,更加符合 Scaling Law 的精神,能够更加容易的获取到更多的数据用于模型训练。
作者介绍
张子卓、朱嘉宁(现 UT Austin 博后)、周展科、李烜、冯啸来自香港浸会大学计算机系可信机器学习和推理组,葛馨木和赵孜铧来自上海交通大学,团队导师为韩波教授和姚江超教授。本研究工作的作者均在 NeurIPS、ICML、ICLR 等机器学习和人工智能顶会上发表多篇论文,主要研究方向为大语言模型推理。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com