“所以产业都值得用AI重新做一遍。”这是行业的普遍共识。
对于汽车处理器来说也不例外。当下,厂商都在接连拥抱边缘AI,并在处理器中放入NPU。那么,这些厂商布局NPU,都面向哪些应用?为什么汽车处理器已经离不开NPU了?

ST:给汽车MCU里放进NPU
2月10日,ST发布首款内置自研Neural-ART NPU的汽车边缘智能微控制器(MCU)Stellar P3E。NPU为Neural ART Accelerator 11,这款NPU与2024年12月发布的STM32N6的引擎相同,但配置不同。此外,P3E 延续了该系列一贯的 28nm FD-SOI工艺。
P3E还拥有足足19.5MB的相变存储(PCM)技术的可扩展 xMemory。以往Stellar设备采用ePCM的两位每单元结构以确保可靠性,而ST改进技术,实现汽车级鲁棒性,仅用一个单元,整体密度翻倍于嵌入式闪存、MRAM或RRAM。19.5MB的嵌入式内存专门用于代码,通过存储两个独立的代码镜像实现空中(OTA)更新,以便在出现问题时恢复到之前的版本。ST还在制造过程中使用独特的算法,使其PCM达到汽车级水平,无论是存储关键代码还是长期数据。简单来说,Stellar P3E 的 xMemory 为客户提供了庞大且强大的存储池,以应对多个不同内存需求的项目。
其他配置上来看,P3E包括6个500MHz的Cortex-R52+,CoreMark分数达到了最高的8000分;1个200MHz的Cortex-M4、4个eDMA engines。提供98个SAR/SD模数转换器通道、8个低功耗ADC、高分辨率定时器和冗余传感,为双电机控制等先进应用提供所需的稳健控制。配备了可扩展的千兆以太网接口,方便连接短距离,同时屏蔽连接免受非常嘈杂的环境影响。

那么,为什么ST要把这款MCU中放入一个NPU?一是为未来的软件定义车辆设计,二是简化了X合1电子控制单元(ECU)的多功能集成,降低了系统成本、重量和复杂度。
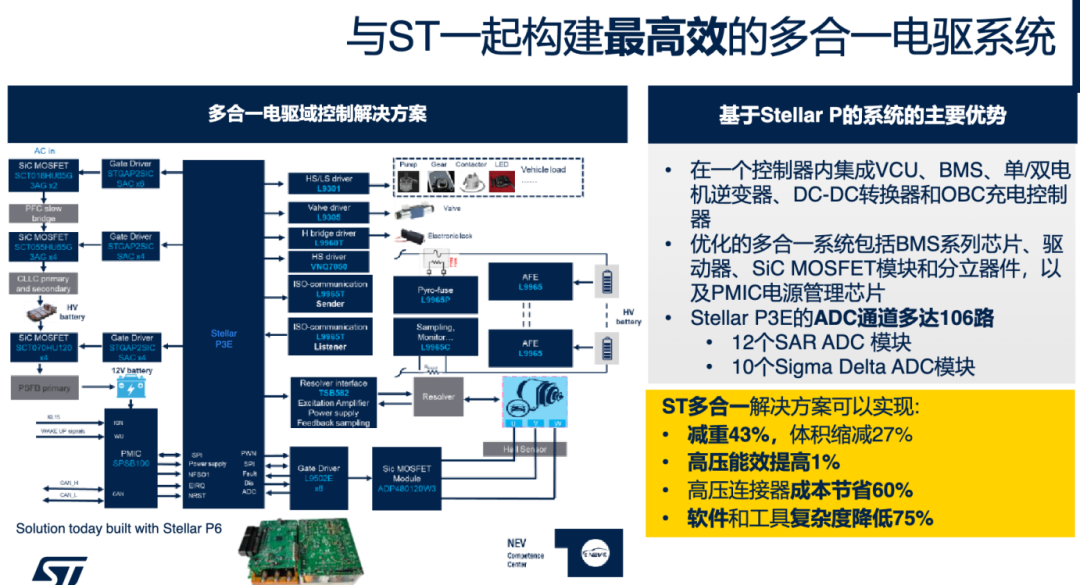
根据ST的介绍,这款MCU可以实现微秒级推理处理,效率高出传统MCU核心处理器的30倍。使得能够实现始终在线、低功耗的AI,支持包括预测性维护和智能传感在内的实时功能,在广泛的应用中带来显著益处。
例如,这些功能可以提升电动汽车的充电速度和效率,并实现新功能的快速部署,无论是工厂还是现场。原始设备制造商(OEM)可以通过不同的AI模型引入新功能和更直观的行为,减少对额外传感器、模块、布线和集成工作的需求。
ST也在具体应用测试中,给出了直观的对比:以车窗防夹手功能为例,NPU 处理障碍物检测的速度是纯CPU计算的69倍,确认车窗关闭的速度则提升了16倍。

当前,P3E样品限量供应,预计2026年底全面生产,软件开发解决方案包括AI工具现已上市。
总得来说,P3E的面世意味着ST已经能够根据应用,提供整套的解决方案。


NXP:推出带NPU的S32N7系列
恩智浦也在积极布局边缘AI上车,并发布了带有NPU的车规处理器。
CES 2026上,恩智浦(NXP)发布了5nm的S32N7系列超级集成处理器,全面释放人工智能(AI)在汽车领域的潜能,推动汽车向“软件定义”时代加速演进。博世(Bosch)为首家采用该技术的合作伙伴。
AI方面,S32N7支持最高可达L2级的自动驾驶功能,融入创新的“智能体AI”,让车辆具备更强的感知、决策和交互能力,具备强大的车端边缘计算能力,可高效处理传感器数据,为实时决策提供支撑,支持始终在线、超低功耗以及基于AI的低功耗运行能力。
应用方面,可将多达8个独立的车辆功能域(如车身、运动控制、底盘、网关等)整合至统一平台。通过完全片上硬件隔离与虚拟化、内核到引脚的虚拟硬件隔离技术,免除各子系统间的干扰,形成精简而强大的中央计算架构。
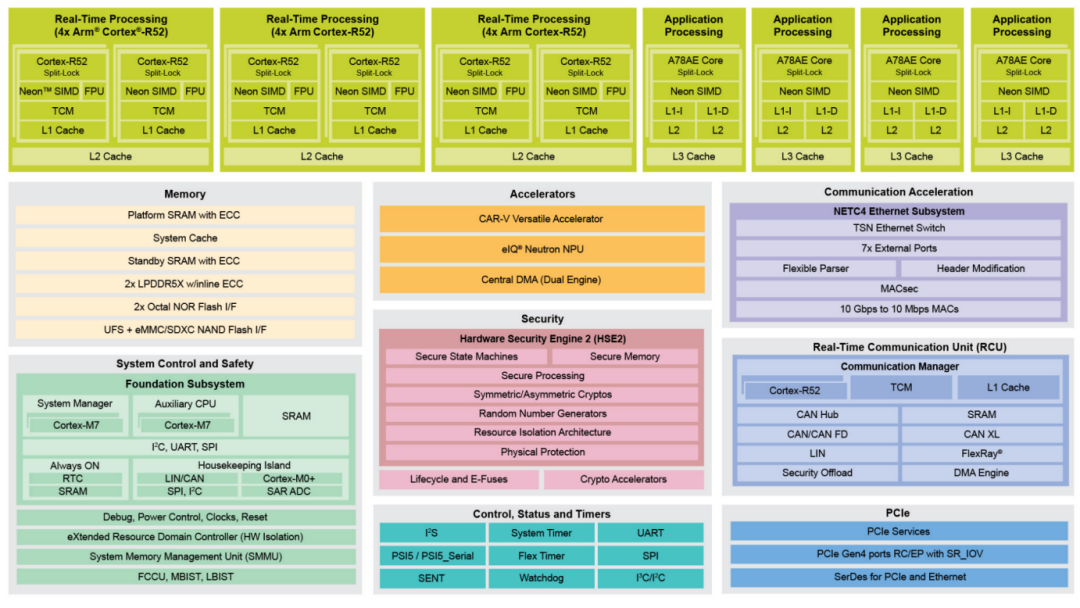
从配置来看,S32N7最大的亮点是搭载了eIQ Neutron神经处理单元(NPU),用于车辆核心的NeuroNetwork加速,搭载了基于RISC-V的加速器,适用于网络、数学及数据密集型工作负载。此外,核心上还搭载了8个1.8GHz的Cortex-A78E、12个1.4GHz的Cortex-R52、独立的安全系统管理器、独立的安全通信管理器、独立后台管理控制器。
存储方面,包括2个LPDDR4X/5/5X DRAM接口、36MB平台SRAM、两通道NVM接口、支持串行、四线和八线NOR存储器、1个UFS 3.1接口、支持eMMC 5.1 NAND闪存和SD卡/SDIO闪存。

Infineon:在TC4x中放进PPU
28nm的AURIX TC4x是英飞凌未来数年的重点产品,这款产品其中也搭载了并行处理单元(PPU),为AI加速。
PPU是集成在英飞凌AURIX TC4x微控制器系列中的协处理器。PPU旨在卸载主CPU的信号处理、滤波和其他数学运算,从而为要求严格的应用程序(例如实时控制、传感器信号处理和轨迹规划等)提供高计算能力和缩短执行时间,并且能支持实现简单的神经网络算法。PPU内包含:
-
标量核(Scalar Core):用于执行大量的标量运算,以及任务调度,支持多种算术运算和逻辑运算,支持硬件浮点运算,提供丰富的硬件功能安全机制;
-
向量核(Vector core/SIMD Core):专门用于执行向量运算,支持多种向量算术运算、逻辑运算和专用信号处理,支持整型数和浮点运算,支持多级流水线和SIMD指令;
-
一级缓存:用于保存计算输入和输出数据的存储空间,由于结构上和运算核紧密耦合,该缓存可以在PPU的执行过程中对状态进行快速读写,并且有EDC/ECC保护,从而实现更高的执行效率和更高的可靠性;
-
其它系统资源:包括用于快速数据搬运的DMA,共享内存区等等。

TC4x可在多方面对AI进行支持。首先,TC4x满足ASIL-D功能安全,可与大算力SoC配合,在路线规划完成后对系统进行安全控制和执行。另外,PPU的矢量计算可以实现轻量化的AI加速,英飞凌也在同客户共同探讨AI的可能应用,从而增强系统性能,或完全创新的算法,比如通过AI模型实现虚拟传感器,从而降本增效。另外,则是随着明年电池管理新国标的实施,PPU也可以利用AI技术,加速数据网络模型,让电池包测试更准确,更可预判。


TI:在C2000中放NPU
TI在C2000中也放入了NPU,来部署边缘AI。
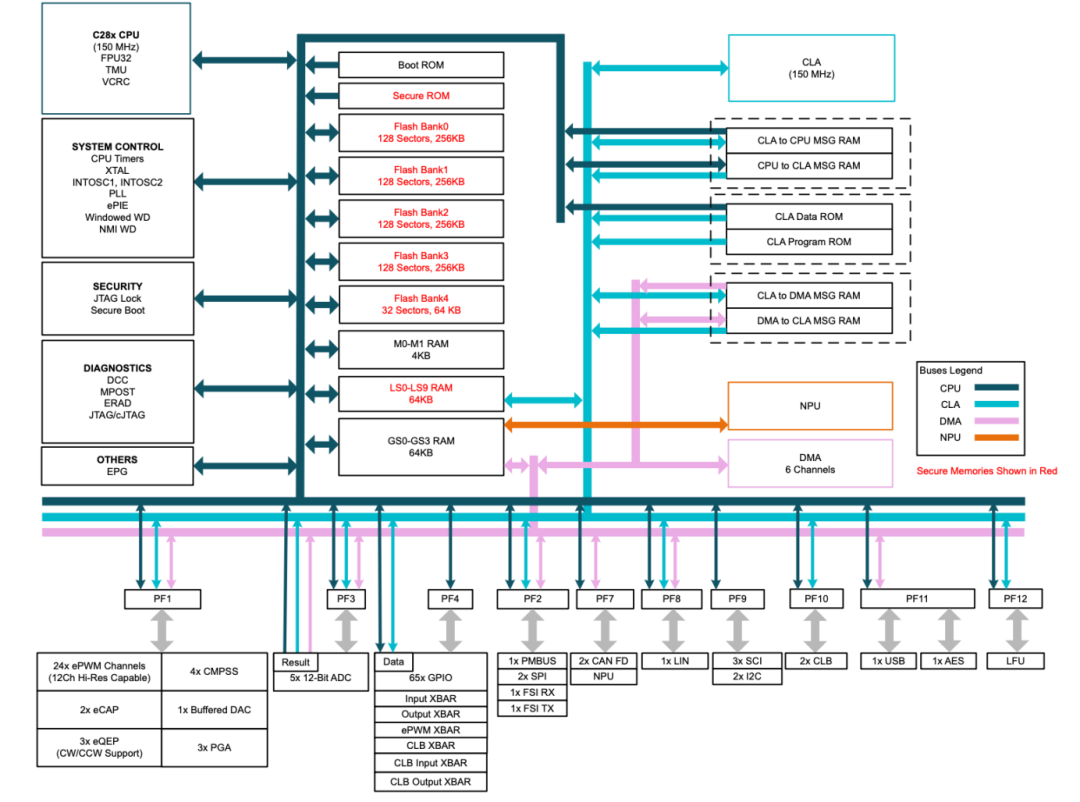
TMS320F28P559SG-Q1的NPU支持基于预训练模型的机器学习推理,运算能力达600~1200MOPS,可部署于电弧故障检测、电机故障检测等场景。相比纯软件实现方案,其神经网络推理周期最多可缩短至原来的十分之一,性能提升高达10倍。
开发者可通过TI Edge AI Studio中的Model Composer或Tiny ML Modelmaker工具加载预训练模型,快速获取高级功能集,并自动生成C28x源代码,无需手动编码。对于采用自有AI训练框架的用户,TI神经网络编译器可将AI模型无缝移植至多款基于C28x的MCU,确保兼容性与部署效率。
这款产品在汽车上的可以有很多应用:混合动力、电动和动力总成系统包括直流/直流转换器、逆变器和电机控制、车载充电器(OBC)和无线充电器、虚拟引擎声浪系统(VESS)、发动机风扇、电子涡轮/增压器泵、电动助力转向(EPS);信息娱乐系统与仪表组包括抬头显示、汽车音响主机、汽车外部放大器;车身电子装置与照明包括汽车HVAC压缩机模块、直流/交流逆变器、前灯;ADAS包括机械扫描激光雷达-电动汽车充电基础设施、交流充电(桩)站、直流充电(桩)站。
配置上,TMS320F28P559SG-Q1搭载150MHz C28x 32位DSP CPU、IEEE 754 单精度浮点单元(FPU32)、三角函数单元加速器(TMU)、支持非线性比例积分微分(NLPID) 控制、CRC引擎和指令(VCRC)、150MHz可编程控制律加速器(CLA)、24个ePWM通道、2个增强型捕获(eCAP)模块、嵌入式图形发生器(EPG)、可配置逻辑块(CLB)等。

总 结
随着整车AI量不断攀升,不光是智驾芯片和座舱芯片,汽车处理器放入NPU也正在成为标配,车窗防夹、虚拟传感器这类应用正在不断催生市场需求。随着“软件定义汽车”革命的继续深入,相信未来整车的边缘AI含量还会增加。










