

大模型终于走下神坛,实用才是AI最好的归宿。

阿里又发模型了。
昨晚,通义千问团队在X上公布了Qwen3.5小模型系列,一共四个尺寸:0.8B、2B、4B、9B。

图源:X
消息传回国内,很快就有了“马斯克点赞中国AI”的话题。
可以理解。毕竟马斯克这个名字,自带流量。但说实话,如果把注意力全放在“马斯克点赞”这件事上,反而可能错过真正有意思的东西。

阿里掀桌,终结参数内卷游戏
先看一个数字。
Qwen3.5-9B,参数量90亿,它在GPQA Diamond上的得分是81.7。作为对比,ChatGPT有一个开源模型,参数量1200亿,得分差不多。

图源:X
也就是说,90亿参数的模型,和1200亿参数的模型,在同一个测试里打成了平手。
十三分之一的体积,差不多的本事。这背后是这两年AI圈一直在琢磨的一件事:参数规模,到底是不是越大越好?
过去两年的逻辑很简单粗暴——谁参数多谁厉害。万亿参数的模型一个接一个往外冒,像重型卡车,马力确实足,但油耗也惊人。
训练一次的成本动辄上千万美元,推理一次的电费都能让中小公司肉疼。最后变成只有巨头玩得起的游戏,但这显然违背了科技发展的初衷。
因此,Qwen3.5走了另一条路。
它在架构上做了个改动:把“门控增量网络”和“稀疏混合专家”结合起来,前向传播的时候只激活当前任务需要的部分,不是所有神经元都扑上去。
听起来有点绕,那我们换一种说法:假设你有一个4000万册的图书馆,以前每次查资料,得把整个馆翻一遍。但现在有个聪明的检索系统,只需要调那170万册核心藏书,就能答出差不多的答案。
这就是马斯克说的“智能密度”——不在参数规模上堆料,在有限资源里压榨出尽可能多的智能。
而这还不是全部。多模态能力的整合方式,藏着另一层门道。
Qwen3.5用的是“早期融合”——文本、图像、视频在底层就一起处理了,不像很多模型那样,先有个文本模型,再在外面挂个视觉编码器当附件。
这种差别,直接让0.8B这种迷你模型的表现同样征服了一众开发者——它在语言基准MMLU-Pro上只拿到了29.7分,但在视觉任务MathVista上冲到了62.2,OCRBench拿了74.5。

图源:X

跑分是起点,场景才是终局
跑分归跑分。真正让开发者兴奋的,是另一件事。
有人算了一笔账:现在3万美元的硬件,就能跑出去年需要20万美元GPU才有的推理能力。

还有人直接上手演示——在iPhone 17 Pro上,用针对Apple Silicon优化的MLX框架,本地跑Qwen3.5-2B的6-bit版本,实时视觉理解、实时问答,全都跑得动。
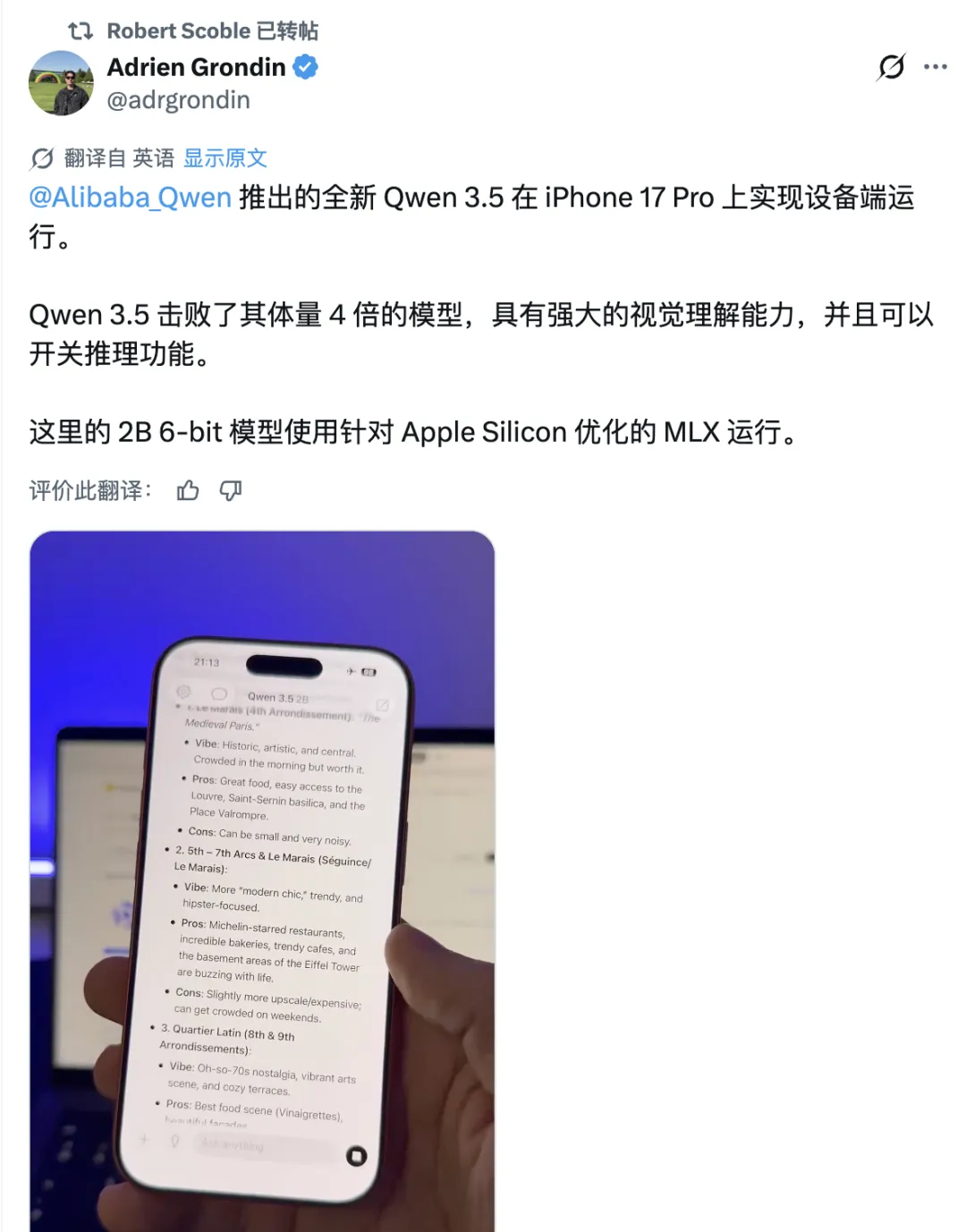
这意味着什么?意味着普通人终于能用得起AI了!
意味着你可以不用联网,不用把需求上传到谁的云端,就能在自己手机里,有一个能看、能听、能琢磨事儿的AI。
这背后其实是一个正在发生的转变。
智能手机时代本质上是“单向输入”的范式——你对着屏幕戳戳点点,手机给你反馈。
但即将到来的AI硬件浪潮,路子不一样了。AI厂商们想干的事,是用更碎、更粘的方式,渗透进你的记忆和生活。
比如你戴着一副AI眼镜走在路上,随口问一句前面有没有障碍物。这时候如果AI延迟了五秒才回答,那这功能几乎就废了。
而这恰恰是云端大模型绕不过去的物理瓶颈——上传、计算、返回,再快的网络也有那点延迟。
端侧小模型的价值就在这儿。遇到真需要深度推理的复杂问题,可以扔给云端;但日常的、实时的、隐私敏感的,本地搞定。
阿里已经把Qwen小模型塞进了AI眼镜这类可穿戴设备里,能做到毫秒级的端侧视觉解析。
听说苹果那边也在捣鼓带摄像头的AirPods和新一代VR智能眼镜——这些玩意儿,将来可能就是你的“第二双眼睛和耳朵”。

阿里野心勃勃,模型与硬件并发
事实上,阿里的这一步,迈得比大多数人想象的要大。
3月2日,千问AI眼镜开启“0元预约”,G1系列叠加补贴后最低1997元,3月8日现货发售。
同一天,巴塞罗那MWC展台上,五米高的“Qwen”标志下,海外观众排着队等试戴。

据媒体爆料,有美国用户试完后给出高度评价——换电设计“太妙了”,续航焦虑明显降低,“基本可以全天开机使用智能服务”。
而这只是开始。内部人士透露,今年年内,AI指环、AI耳机也会陆续落地,面向全球发售。
你可能想问:阿里做硬件,图什么?
表面看是跟风——Meta的Ray-Ban眼镜吃掉了七成市场份额,OpenAI组了两千人的硬件团队,字节的眼镜耳机也在路上。巨头们都在抢同一个东西:下一个AI入口。
但阿里的打法,跟别人不太一样。
1月底,平头哥官网上线了一款叫“真武810E”的AI芯片。
参数上看,性能对标英伟达H20,已经在阿里云部署了多个万卡集群,服务了国家电网、中科院、小鹏汽车等400多家客户。更重要的是,它被大规模用于千问大模型的训练和推理。
芯片亮相的同时,一个叫“通云哥”的黄金三角浮出水面——通义实验室做模型,阿里云做算力,平头哥做芯片。
三个东西捏在一起,意味着什么?意味着阿里可以在芯片架构、云平台架构、模型架构三个层面协同优化,而不是像大多数玩家那样,拿着英伟达的卡、跑别人的框架、调第三方的模型。
业内有一种说法:全球能做到“大模型+云+芯片”全栈自研的公司,目前只有两家,一家是谷歌,另一家是阿里。
这个说法含金量高不高另说,但逻辑是通的——端侧硬件对成本和功耗极其敏感,如果芯片、模型、云不能深度耦合,体验上就永远差一口气。
千问3.5能把部署显存占用降低60%、推理吞吐量提升19倍,靠的不只是算法,还有底层硬件的配合。
所以硬件本身,从来不是阿里的目的。
春节期间,用户在千问APP上“一句话下单”接近2亿次,Questmobile数据显示,千问在春节期间日活冲到7352万,以940%增幅居国内AI应用首位。
这说明:千问已经从一个聊天机器人,变成了一个能点外卖、订酒店、打车的国民级AI助手。
现在的问题是,这个助手能不能走出手机屏幕?
当你戴着AI眼镜路过一家餐厅,扫一眼招牌,说一句“这家评价怎么样,帮我订个位”,随即眼镜开始识别画面,调高德的数据,用支付宝完成支付——全程不用掏手机;你在异国街头看不懂菜单,眼镜直接在你视野里叠上翻译;你骑车想记录路线,对着指环说句话就搞定。
这就是阿里想要的“所见即所得”。它依赖的不只是模型聪明,更是背后那个能触达数百万商家、打通支付和出行、覆盖生活服务全场景的生态。
阿里集团CEO吴泳铭有句话说的很好:AI最大的想象力,不在手机屏幕,而在于如何接管数字世界。
从这个角度看,千问做硬件的逻辑就清晰了——它想做的,是用硬件把阿里的服务网络,编织到现实世界的每一个节点上。
而让这一切能够成为可能的,正是Qwen3.5这批被马斯克大赞的、几十亿参数的“小东西”。










