
如今,Test-Time Scaling(测试时扩展)已成为提升模型推理能力的关键路径。而在这一浪潮中,块扩散语言模型(Block Diffusion Language Models, BDLMs) 凭借其独特的并行解码能力,被视为超越传统自回归(AR)模型推理效率的有力竞争者。
然而,现有的 BDLMs 在面对长链推理时,陷入了一个两难的效率 - 效果博弈:大块(Large Block)解码速度极快,但在复杂推理中容易出错,导致性能大幅下降;而小块(Small Block)虽然推理准确,但退化为接近自回归的速度,失去了扩散模型的并行优势。同时,现有的解码策略(如固定置信度)无法适应长推理链中 “难易交替” 的动态特性。这引出了一个核心问题:如何在保持 Block Diffusion 高效并行优势的同时,解锁其在复杂推理任务上的 Test-Time Scaling 潜力?
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码 (Bounded Adaptive Confidence Decoding, BACD),成功打破了速度与精度的零和博弈。

论文标题:Advancing Block Diffusion Language Models for Test-Time Scaling
论文链接:https://arxiv.org/abs/2602.09555
代码链接:https://github.com/LuLuLuyi/TDAR
模型链接: https://huggingface.co/lulululuyi/TDAR-8B-Thinking

TDAR-8B-Thinking 在 AIME24 上的性能与速度对比图。TDAR 位于右上角,展示了在保持高推理速度的同时实现了 SOTA 的准确率。
核心创新:双重自适应机制
为了解决上述痛点,研究团队提出了一套统一的测试时扩展框架 TDAR,如下图所示,该框架包含两个核心设计:有界自适应置信度解码(BACD)与 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式。
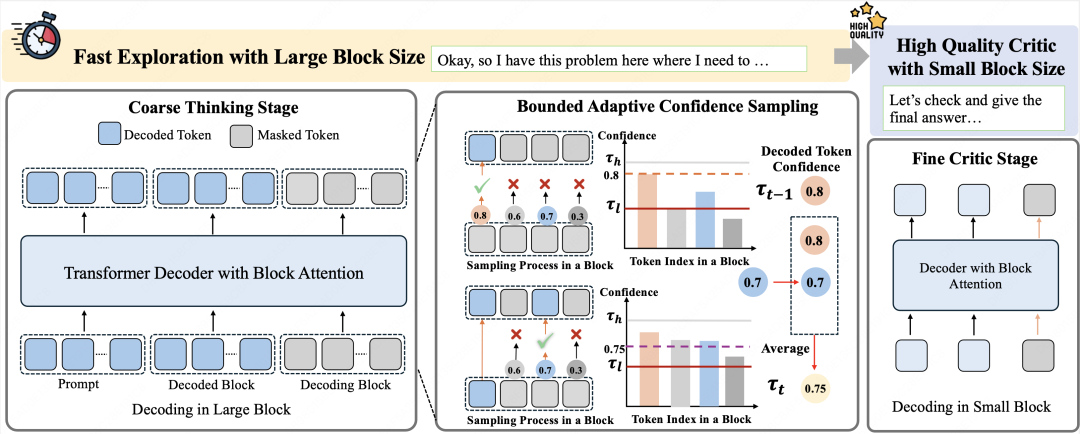
TDAR 方法概览。展示了 TCCF 流程(Coarse Thinking -> Fine Critic)以及 BACD 的动态阈值机制。
1. 解码层:BACD (Bounded Adaptive Confidence Decoding)
传统的动态解码往往依赖固定的置信度阈值,这在长链推理中极易导致 “一步错,步步错”。研究团队提出了有界自适应置信度解码(BACD)算法,该算法利用已生成 token 的平均置信度作为信号,动态调整当前的去噪阈值。同时,为了实现效率和效果的兼顾,增加了双重边界保护机制:上限(Upper Bound)负责在模型自信时激进加速,下限(Lower Bound)负责在模型不确定时强制保守,防止错误累积。这使得模型能够像人类一样,简单步骤快思考,困难步骤慢推敲。

2. 范式层:TCCF (Think Coarse, Critic Fine)
长链推理并非均匀的过程,而是由 “探索” 和 “验证” 组成的异质序列。在探索阶段,思维发散但推理内容较为粗糙,而在验证阶段,需要更加精细的验证和总结。研究团队提出了 TCCF 范式,根据推理阶段的功能分配不同的计算粒度:
Think Coarse(粗思考):使用 大 Block Size (block_size=16) 进行快速的探索性推理,迅速铺开思维路径。
Critic Fine(细求证):使用 小 Block Size (block_size=1) 进行精细的验证、纠错和总结,确保最终答案的正确性。
此外,为了支持大 Block 的高效训练,研究团队引入了 Progressive Block Size Extension(渐进式块大小扩展) 策略,有效缓解了 Block Size 增大带来的性能衰退。
实验结果:速度与精度的双重飞跃
研究团队在 Math500、AIME24、AIME25、AMC23、GPQA、LiveCodeBench 共6个主流推理基准上评估了 TDAR-8B-Thinking。
实验结果表明,TDAR-8B-Thinking 在 8B 规模的 Block Diffusion 模型中取得了最佳性能,平均性能超越前 SOTA 模型 TraDo-8B 3.4 个百分点,解码速度从 1.27 TPF 飙升至 2.97 TPF。
结合 BACD 算法后,速度进一步提升至 3.37 TPF 且性能再涨 1.6 个百分点;叠加 TCCF 范式后,在 AIME24 复杂数学任务上准确率从 36.3% 提升至 42.9%,同时维持 3.04 TPF 的高速度,实现了速度与性能的完美平衡。
Method | AIME24 TPF | AIME24 AVG@8 |
Fast-dLLM-v2 | 2.58 | 0.0 |
SDAR-8B-Chat | 2.96 | 5.0 |
DiRL-8B-Instruct | 1.96 | 18.8 |
TraDo-8B-Instruct | 2.13 | 13.3 |
TraDo-8B-Thinking | 1.35 | 31.3 |
+ BACD | 1.44 | 32.9 |
+ BACD +TCCF | 1.36 | 35.8 |
TDAR-8B-thinking (ours) | 4.47 | 34.6 |
+ BACD | 5.07 | 36.3 |
+ BACD +TCCF | 3.04 | 42.9 |
实验结果表格。TDAR-8B 及其变体在各项指标上均优于现有的自回归和扩散模型基线。
深度分析:解构 TDAR 的性能来源
为了探究 TDAR 高效背后的机制,研究团队对 Block Size、解码策略及 TCCF 范式进行了多维度的量化分析。
1. 突破效率瓶颈:BACD 解锁高能效区间
研究团队将 BACD 与 BDLMs 中主流的采样算法进行了对比,包括 Static Confidence Decoding(固定步数,性能上限但效率低)和 Dynamic Confidence Decoding(动态阈值)。
首先,研究团队比较了在不同阈值下的性能与速度权衡。如下图所示,对于 Dynamic Confidence Decoding,随着置信度阈值(Threshold)的降低,模型的性能会出现肉眼可见的衰退。相比之下,BACD 在获得持续效率增益的同时,依然维持了稳定的性能表现。

BACD 与 Dynamic Confidence 等方法的效率 - 准确率在不同 threshold 对比
研究团队对 BACD 在不同阈值下,模型输出的行为进行了分析,相比于标准的动态置信度解码,BACD 在不同阈值下表现出极高的稳定性。分析显示,BACD 有效避免了低阈值下的 “模型崩溃” 和 “重复生成” 问题,证明了 BACD 在动态调整去噪步数时具有显著的优越性。

BACD 在不同阈值下的性能稳定性分析。
2. Block Size 的权衡
Block Size 是影响 BDLMs 性能与效率的关键变量。研究团队深入探究了其非线性影响:
如下图所示,随着 Block Size 增大,推理速度呈线性增长,但生成质量会出现显著衰退。通过权衡分析,研究团队锁定 B=16 为 8B 模型的最佳平衡点(Sweet Spot)。TDAR 在此设置下,既保留了并行解码的速度优势,又通过渐进式训练(Progressive Extension)维持了强大的推理能力。

不同 Block Size 下模型性能与效率的 Trade-off 分析。
3. TCCF 的普适性增益
在不同的解码算法下应用 TCCF 机制,比较其在 AIME24 上的表现,如下图所示。结果表明,无论是在 Dynamic Confidence 还是 BACD 算法下,引入 TCCF(即从 Coarse 到 Fine 的转换)都能带来一致且显著的性能提升。
特别是在 BACD 算法中,TCCF 有效提升了不同阈值下的性能下限。这证明了 “粗思考,细求证” 机制能有效弥补单一解码策略在细节处理上的不足,实现了 1+1>2 的效果。

TCCF 策略在不同解码算法及阈值下的性能增益分析。
结论与展望:释放 BDLMs 的推理潜力
TDAR 的提出,标志着 Block Diffusion 语言模型在复杂推理任务上迈出了重要一步。从此以后,大 Block Size 不再是禁区,通过渐进式训练和 BACD 解码,大 Block 也可以兼顾质量与速度。而 TCCF 范式的提出,证明了针对推理阶段动态分配计算粒度的必要性。
TDAR 不仅为 BDLMs 的 Test-Time Scaling 提供了一套高效的解决方案,也为未来并行推理模型的设计提供了新的思路。
团队成员均来自美团LongCat后训练团队:
陆毅,复旦大学自然语言处理实验室硕士在读,研究方向为大语言模型,复杂推理,导师为桂韬老师。
孔德阳,北京大学软件工程国家研究中心硕士在读,研究方向为大语言模型,复杂推理,导师为叶蔚副研究员。
王嘉宁,获得华东师范大学博士学位,曾前往UCSD访问学习,在ACL、EMNLP、AAAI、ICLR等顶会发表论文数十篇,目前就职于美团,LongCat-Flash-Thinking核心作者之一,研究方向为大模型训练与复杂推理。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com









