离线强化学习(Offline RL)的一大难点是:训练数据固定、质量参差不齐。近两年,Decision Transformer(DT)等基于 Transformer 的方法因为把决策建模成条件序列生成而受到关注,但它们往往把「整条轨迹」作为学习单位:如果一条轨迹的最终回报不高,轨迹中间即便出现过有效动作与局部成功,也容易被整体低回报「稀释」。
针对这一痛点,山东大学、中科院、理想汽车与清华大学的研究团队联合提出了一种名为 PRGS(Peak-Return Greedy Slicing)的新框架。
PRGS 的目标是在不改变离线数据来源的前提下,从原始轨迹中自动筛选出更有学习价值的子轨迹(sub-trajectories),用于训练 Transformer 型离线 RL 方法,并在推理阶段进一步避免「糟糕历史」对当前决策的干扰。
在 D4RL、BabyAI 等主流榜单上,PRGS 不仅超越各种基线方法,更让 Transformer 类方法的平均性能提升了 15.8%!
本论文的第一作者徐志伟,山东大学通用智能实验室助理教授。于 2024 年在中国科学院自动化研究所获博士学位,研究内容主要为强化学习、多智能体系统与基于大语言模型的 AI Agent。曾获得 2025 年度中国智能体与多智能体系统优秀博士论文提名等荣誉。
目前,该论文已接收于国际计算机顶级会议 ICLR 2026。ICLR(International Conference on Learning Representations)是机器学习与表示学习领域的国际顶级会议之一,与 NeurIPS、ICML 并列为人工智能方向最具影响力的学术会议。本次 ICLR 2026 共有接近 19000 篇有效投稿,接收率约为 28%。

论文标题:Peak-Return Greedy Slicing: Subtrajectory Selection for Transformer-Based Offline RL
论文链接:
https://openreview.net/pdf?id=7vpehpWnnY
01 痛点:按「整条轨迹」学习,粒度不够细
在离线 RL 中,数据是固定的,不能像在线 RL 那样去不断试错。现有的 Transformer-based 方法(如 DT),本质上是在做条件序列建模。它们通常以「最终回报(Final Return)」为条件来生成动作。
这带来的问题是显而易见的:
粒度偏粗: 模型只能看到一条轨迹的整体回报信号,难以区分轨迹内部不同时间段的质量差异。
缝合能力缺失: 由于缺乏局部优化目标,模型很难从多个平庸策略中提取出最优片段并组合成新的完美策略。
虽然也有研究试图通过重采样或加权来缓解,但大多治标不治本,没有深入到时间步(Timestep)级别去精细化操作。而 PRGS 的出现,正是为了打破这一僵局。
02 核心解法:从全局建模到精细化切片
PRGS(Peak-Return Greedy Slicing)可以理解为一个面向 Transformer 离线 RL 的数据处理与推理增强框架,包含三部分:回报估计、贪心切片、推理时自适应截断。

它的核心逻辑非常像人类的学习过程:回顾过去的经历,哪怕结局是失败的,也要找出其中做得最好的那一段,刻在脑子里。
PRGS 包含三个环环相扣的模块:
第一步:MMD-based Return Estimator:用分布视角做更「乐观」的回报估计
PRGS 首先需要回答:在轨迹内部,哪些时间段更可能带来高回报?为此作者引入基于最大均值差异(MMD)的回报估计器,用来刻画状态-动作对的潜在回报分布。
不同于传统的均值预测,MMD 估计器能预测状态-动作对的潜在回报分布。通过对分布采样并取 Top-n 均值,PRGS 获得了一个乐观的回报估计值。简单来说就是:它能挖掘出当前状态下可能达到的最好结果,而不是平均结果。
第二步:Greedy Subtrajectory Slicing:围绕峰值回报做递归切片
在得到每个时间步的「乐观回报」后,PRGS 对单条轨迹执行贪心切片:PRGS 会扫描整条轨迹,计算每个时间步的「乐观回报」。然后,它会找到那个回报最高的点——峰值点(Peak Point)。
切。 以这个峰值点为界,从起点到峰值点的这一段,被认定为「高质量子轨迹」,直接拿去训练 Transformer。
再切。 剩下的部分,再重新找峰值,继续切,直到切完为止。
这种递归式的贪心策略,把长轨迹拆成一组更短、质量更聚焦的子轨迹,从而让 Transformer 在训练中更频繁地接触到「相对高回报」的决策片段。
第三步:Adaptive History Truncation:推理阶段的自适应截断
PRGS 还考虑了一个实际问题:模型训练时看到的是「从轨迹中段截取出来的子轨迹」,推理时如果始终把所有历史上下文都喂给模型,早期的低质量动作可能会干扰后续决策。
PRGS 引入了一种自适应历史截断机制(AHT):每走一步,模型都会评估当前状态的价值。如果发现现在的处境比历史记录显示的更有前途,说明之前的历史已经不仅没用,反而成了累赘。这时候,模型会果断失忆,丢掉历史上下文,轻装上阵。
03 实验:多场景达到 SOTA 表现,复杂场景更强
研究团队在 D4RL(连续控制)、BabyAI(自然语言指令跟随)以及 AuctionNet(大规模广告竞价)三个截然不同的基准上进行了测试。
D4RL 场景中表现惊艳
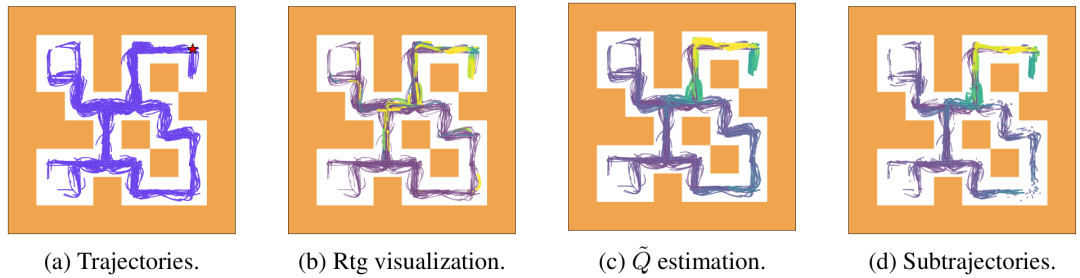
在经典的 MuJoCo 和 AntMaze 任务中,PRGS 的表现堪称惊艳。特别是在需要极强「缝合能力」的 Maze2D-Large 迷宫任务中,DT-PRGS 的得分高达 127.5,而原始 DT 只有不到 30 分。

在迷宫任务中的可视化结果也显示,通过 PRGS 提取出的子轨迹,精准地覆盖了通往目标的「黄金路径」,几乎剔除了所有绕弯路的无效探索。
真实业务场景的潜力
除了学术榜单,PRGS 在 AuctionNet(阿里妈妈开源的广告竞价数据集)上也表现出色。相比于 BC(行为克隆),加持了 PRGS 后的 BC 算法在多个周期内实现了显著的利润提升。

04 总结与展望
PRGS 的成功证明了一件事:在离线强化学习中,数据不仅要「多」,更要「精」。
通过 MMD 估计器、贪心切片和自适应截断这套组合拳,PRGS 成功地让 Transformer 具备了「取其精华,去其糟粕」的能力。这一成果也为自动驾驶、机器人控制等工业级应用提供了极具价值的技术参考。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com