 芝能智芯出品
芝能智芯出品在 NVIDIA GTC 2026 上,理想汽车发布了新一代自动驾驶基座模型 MindVLA-o1。官方的描述是"自动驾驶进入物理智能体时代"。
这类表述在发布会上出现太多次,很容易被当成话术略过。
这意味在工程层面做了什么?自动驾驶这件事本身的问题定义正在被重写。

Part 1
三次跃迁之后,卡在哪里了
过去十年,自动驾驶的技术路径经历了三次迭代。
◎ 第一代是规则驱动:工程师手写规则,告诉系统什么情况下刹车、什么情况下变道。这套方法在结构化道路上能用,但规则写不完,现实比规则复杂得多。
◎ 第二代是端到端:不再手写规则,而是喂给模型海量数据,让它自己学出驾驶策略。这解决了规则无法穷举的问题,但新的问题出现了——模型学会的是数据里的模式,遇到训练数据覆盖不到的情况就容易崩。
◎ 第三代是 VLA,也就是把视觉、语言、行动整合进一个架构,让系统具备跨任务的理解和泛化能力,不再只是一个驾驶专用的预测机器。
但 VLA 也有它自己的天花板。它能理解场景,能做出决策,但它对世界的理解是静态的——它知道现在是什么状态,但不能很好地推演这个状态接下来会怎么变。
一个行人正在路边站着,VLA 能识别他,但很难预判他下一秒会不会突然走出来。这不是感知精度的问题,而是对物理世界的因果结构缺乏理解。
◎ 第四次跃迁:从"开车"到"理解世界"

MindVLA-o1 想解决的正是这个缺口。
它的核心主张是:自动驾驶系统不应该只是一个驾驶任务执行器,而应该是一个能在物理世界中持续认知、预测和行动的智能体。
这个表述听起来抽象,但落到工程上有一个很具体的含义:系统需要在内部建立一个关于世界"接下来会发生什么"的模型,而不只是对当前状态做出反应。这就是"世界模型"(World Model)的意义所在。

过去一年,自动驾驶行业在 VLA 和世界模型之间存在一个技术路线的争论,有人认为应该押注 VLA,有人认为世界模型才是未来。
理想给出的答案是:这两件事不是竞争关系,而是分工关系:
◎ VLA 负责决策闭环,在车上实时运行;
◎ 世界模型负责认知和训练,在云端生成数据、模拟场景、优化策略。
车端要的是快,云端要的是深,两者承担不同的职责,在不同的地方发挥价值。
这个分工听起来合理,但把它真正做通,需要解决几个过去没有人彻底解决的工程问题。
Part 2
理想怎么做——
三个关键的工程选择
让模型学会"世界如何变化",而不是"当前是什么样"
传统自动驾驶的感知系统,处理的是空间问题:这里有什么,那里有什么,彼此的位置关系是什么。
这个问题被描述成一张鸟瞰图——把三维世界压平成二维平面,标注出障碍物和车道线。这套方法在很长时间里够用,但它有一个根本性的局限:它丢失了时间。

MindVLA-o1 的第一个关键选择,是从空间表示转向时空表示,引入了一种叫做"下一帧预测"的训练方式:模型不只是学习"当前世界是什么状态",而是学习"这个状态接下来会怎么变"。
同时,感知编码器升级到了三维结构,融合了摄像头和激光雷达的信息,保留了高度和动态关系——这些在鸟瞰图里会被压平的信息。
这个改变的意义在于:模型开始理解物理因果关系,而不只是识别静态模式。
一辆车正在加速,下一帧它会在哪里;一个行人正在转身,下一步他最可能走向哪个方向——这类判断需要对世界的动态结构有理解,光靠感知精度是不够的。
把"想象未来"的成本压下来

有了对世界动态的理解,如何在车上实时使用这种理解。世界模型的计算代价很高,直接在车端运行几乎不可能。
理想的解法是把预测过程压缩到"隐空间"里进行。所谓隐空间,是模型内部的一种压缩表示——不是真实世界的图像或点云,而是经过编码之后的抽象向量。
在隐空间里推演未来,比在原始感知数据层面推演要快得多、省得多。训练的时候先用视频数据学会如何压缩和解压缩这种表示,然后在隐空间里建立预测未来的能力,最后再把这种预测能力和驾驶决策联合训练。
结果是:系统获得了"想象未来"的能力,但把这种能力的计算成本压缩到了可以在车端实时使用的级别。
从预测轨迹到生成轨迹
传统的自动驾驶规划,做的是一个预测问题:给定当前状态,预测出未来最可能的路径点序列。MindVLA-o1 把这件事改造成了一个生成问题:用类似大语言模型生成文字的方式,生成驾驶轨迹。

这个转变听起来像换了个说法,但工程含义很不同。
◎ 生成模型可以同时考虑多种可能性,然后通过多轮迭代优化收敛到最好的解;
◎ 而传统预测模型更像是沿着一条确定的路径走下去。
具体实现上,理想用了三项技术的组合:混合专家模型(不同驾驶场景交给不同专家模块处理)、并行解码(所有轨迹点同时生成,避免顺序生成带来的延迟积累)、扩散优化(多轮迭代让轨迹越来越平滑稳定)。
这三件事加在一起解决的是一个实际问题:在复杂场景里,轨迹生成既要快,又要稳,还要能覆盖多种不同的处置策略。以前这三个要求很难同时满足,现在有了一套组合解法。

模型结构之外,还有一个更根本的问题:数据从哪里来。
自动驾驶最难搞定的不是常见场景,而是长尾场景——那些在真实道路上出现概率很低、但一旦出现就很危险的情况。靠真实采集数据来覆盖这些场景,成本极高,而且有些极端情况根本不可能在真实路测中主动制造。
MindVLA-o1 的解法是用世界模型生成仿真场景,再用强化学习在这些场景里让模型自己探索最优策略。这套流程在效率上有一个关键改进:场景生成从逐步重建改成了前馈生成,速度快了约两倍,训练成本降低了约 75%。
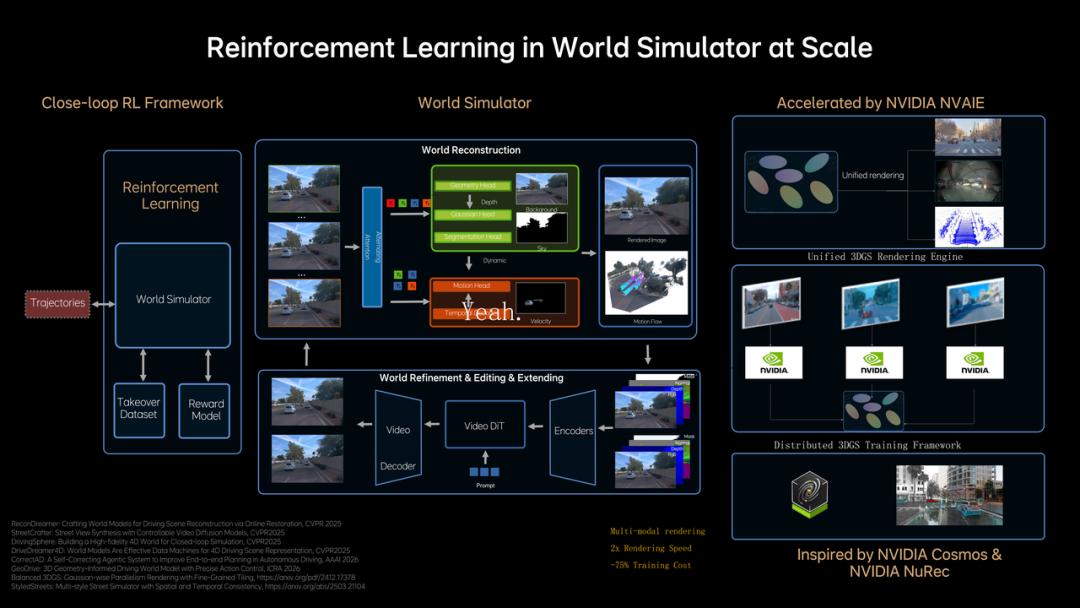
更重要的是这套机制带来的能力:系统不再只是被动地从人类标注数据里学习,而是可以主动生成从未见过的情况,然后在其中试错、优化、迭代。这是一种质的变化——从"被教会"到"自己学会"。
最后一个工程选择是软硬件协同。模型再先进,如果在车端硬件上跑不起来,等于白做。
理想引入了一套叫做 Roofline 的分析框架,用来在模型结构和硬件性能之间建立精确的映射关系,再通过大规模架构搜索——测试了大约 2000 种不同的模型配置——找到在精度和延迟之间的最优平衡点。
一个有意思的发现是:在车端场景里,更"宽但浅"的模型结构优于深层结构。这与大语言模型的经验相反,反映的是车端对实时性的要求比对参数规模更敏感。
这套探索过程,过去需要数月,现在压缩到了数天。

Part 3
车,是目前最好的具身智能载体

MindVLA-o1 最值得关注的方向:自动驾驶正在成为通用物理 AI 的入口。
这件事的逻辑并不复杂。要训练一个能在真实物理世界中行动的 AI,你需要三件东西:完整的感知系统、实时的决策需求、大规模的真实数据。
汽车恰好同时具备这三件东西,而且已经有数百万辆在路上跑,每天产生海量的真实场景数据。
相比之下,机器人虽然是更通用的具身载体,但它的规模化部署还要等很多年。

谁在自动驾驶上建立了强大的感知、预测、决策和学习体系,谁就在通用物理 AI 的竞争中拥有了一个很难被绕过的先发优势。
同一套模型,可以控制机器人

理想已经明确,MindVLA-o1 的架构不只用于驾驶,同一套 VLA 模型可以迁移到机器人控制上。这不是一个遥远的路线图,而是一个工程上已经在验证的方向。
原因在于,驾驶和机器人在底层问题上高度相似:都需要感知三维空间,都需要理解物体的运动和意图,都需要在实时约束下做出行动决策。两者的差异更多在于执行器,一个是方向盘和油门,一个是机械臂和腿。
如果感知和决策的底层模型是通用的,那么迁移的成本会大幅降低。这是一个值得认真看待的技术判断,自动驾驶的边界可能比我们通常想的要宽得多。
过去几年,自动驾驶的军备竞赛主要发生在两个地方:传感器数量和城市覆盖里程。这两件事当然重要,但它们正在快速成为行业基线,不再是真正的差异化来源。
MindVLA-o1 所代表的方向,指向的是另一维度的竞争:数据闭环能力、仿真能力、强化学习基础设施、系统工程整合能力。
这些东西都不是一两年能追上的,它们依赖长期的技术积累和大规模的工程投入,本质上是组织能力,而不只是模型能力。
MindVLA-o1 的意义或许不在于它今天是否已经领先,而在于它标志着竞争维度的一次迁移,从"谁的感知更准"到"谁的系统进化更快"。后一场竞争,才刚刚开始。










