
SMARTFLOW AI DAILY
GTC 万亿美元信号、OpenClaw 全面接管、AI 学会了科研品味
2026-03-17 · 共 21 条资讯 + 10 篇论文解读
📡 AI 资讯速递
21 条来自 X/Twitter 的最新 AI 动态
Google:Gemini Embedding 2 多模态嵌入模型公开预览
Google 发布首个全多模态嵌入模型 Gemini Embedding 2,支持文本、图片、视频和音频的统一映射,已在 Gemini API 和 Vertex AI 上提供公开预览。
🔗 https://x.com/Google/status/2033631279925891078
Replit:Agent 4 发布,支持无限画布自由设计
Replit 发布 Agent 4,支持在 Agent 构建的同时进行设计,可在无限画布上探索多种 UI 方案,并将精确的 UI 编辑直接应用到应用中。

🔗 https://x.com/Replit/status/2033589406112870672
NVIDIA:黄仁勋在 GTC 大会发表主题演讲,分享 AI 未来
NVIDIA CEO 黄仁勋在 SAP Center 的 GTC 大会上进行现场主题演讲,分享 AI 领域的最新进展与未来方向。

🔗 https://x.com/nvidia/status/2033600434858770685
Karpathy:SGD 也是 ResNet,权重就是残差流
Karpathy 发表技术观点,指出 SGD 的前向+反向传播构成类似 ResNet 的残差块,权重即残差流,引发对 Attention is All You Need 的深层思考。
🔗 https://x.com/karpathy/status/2033400893346107835
Cursor:构建安全 Agent 舰队持续监控代码库
Cursor 构建了一组安全代理持续运行在其代码库上,并开源了自动化模板供开发者复用。
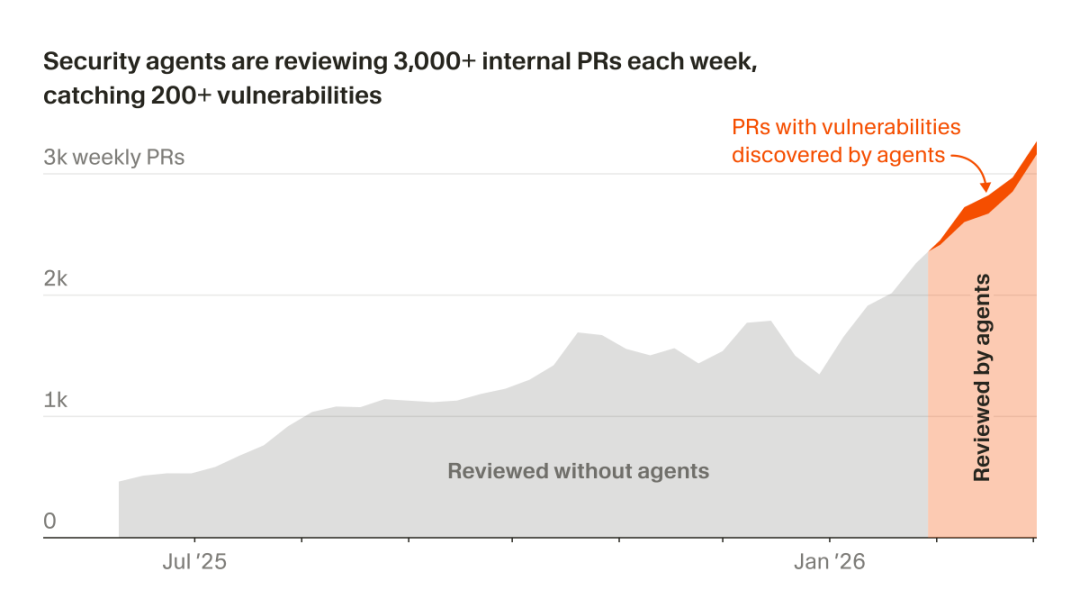
🔗 https://x.com/cursor_ai/status/2033595658951930073
xAI:Grok 文本转语音 API 正式上线
xAI 发布 Grok 的 Text to Speech API,支持自然语音和表达控制,开发者可立即集成到应用中。
🔗 https://x.com/xai/status/2033617157884678507
OpenAI:AI 开始帮助解决医疗领域的实际问题
OpenAI 健康负责人 Nate Gross 博士和健康 AI 研究主管 Karan Singhal 讨论了如何构建新模型和产品以满足全球健康需求。

🔗 https://x.com/OpenAI/status/2033589167905734668
Perplexity:Computer 功能全面接管 Comet,可控制浏览器完成任务
Perplexity 的 Computer 功能现可完全控制 Comet,启动浏览器代理访问任意网站或已登录应用,无需连接器或 MCP,已向所有 Comet 用户开放。
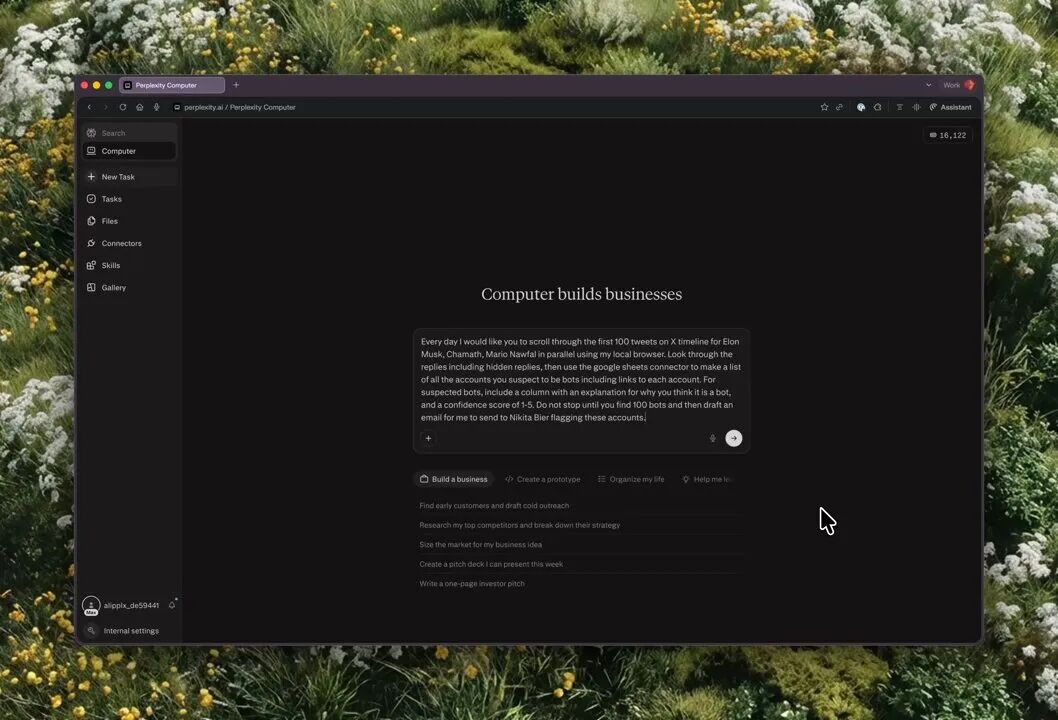
🔗 https://x.com/perplexity_ai/status/2033598416962592813
Sam Altman:Codex 使用量快速增长,硬核开发者纷纷转向 Codex
Sam Altman 表示 Codex 团队是硬核构建者,产品深受硬核开发者青睐,Codex 使用量正在快速增长。

🔗 https://x.com/sama/status/2033599375256207820
新研究:视觉语言模型能否破解「三杯猜球」游戏?
最新论文探讨视觉语言模型在经典 Shell Game 中的推理追踪能力,为评估 VLM 动态视觉理解提供了新颖基准。

🔗 https://x.com/_akhaliq/status/2033556776671396249
Yann LeCun:特斯拉 FSD 远未达到 L5 级自动驾驶
LeCun 以 Model S 车主身份表示,FSD 虽然实用但仍为 L2 级辅助驾驶,远非完全自动驾驶,并分享了相关安全评级数据。
🔗 https://x.com/ylecun/status/2033522056394891342
Kimi:Scaling Law 实验揭示一致的 1.25 倍算力优势
月之暗面最新 Scaling Law 实验表明,在不同模型规模下均存在一致的 1.25 倍算力优势,为大模型训练效率优化提供了新参考。
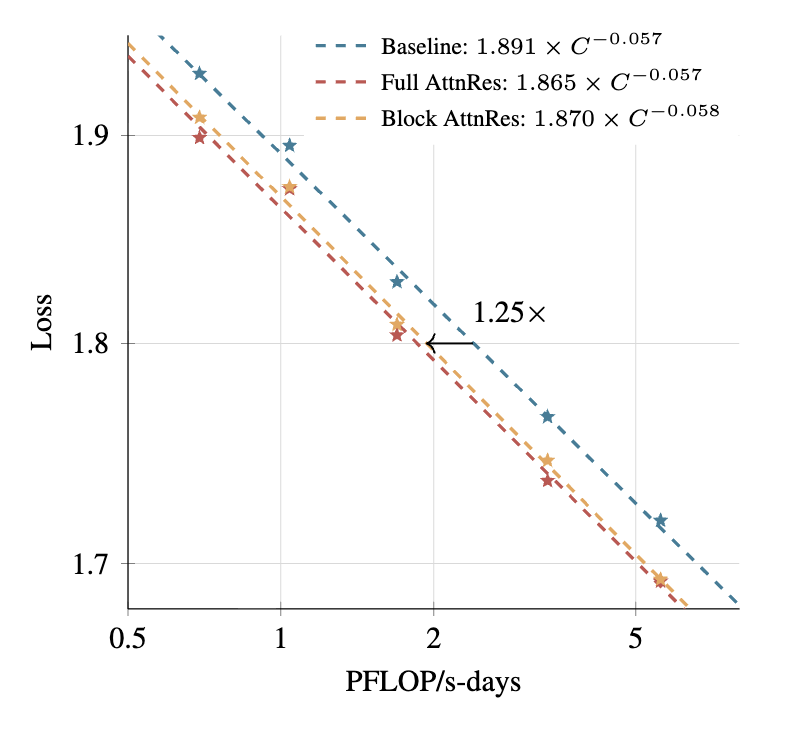
🔗 https://x.com/Kimi_Moonshot/status/2033378592147767483
NVIDIA:GTC 2026 大会开幕,黄仁勋主题演讲汇聚 AI 行业领袖
NVIDIA GTC 2026 大会今日举行,黄仁勋将发表主题演讲。参会企业涵盖 Mistral AI、Cohere、CoreWeave、Perplexity、LangChain 等行业领军者,OpenClaw 也在列。

🔗 https://x.com/nvidia/status/2033551362210865371
新论文:LMEB 长期记忆嵌入基准测试发布
研究者发布 LMEB(Long-horizon Memory Embedding Benchmark)论文,提出评估模型长期记忆嵌入能力的新基准测试框架。

🔗 https://x.com/_akhaliq/status/2033394086778945671
Andrej Karpathy:C 编译器生成 LLM 权重与对数复杂度注意力机制令人振奋
Karpathy 评论了一项将 C 编译器转化为 LLM 权重的研究,以及对数复杂度的 hard-max 注意力机制及其潜在推广方向,称其非常棒且令人振奋。
🔗 https://x.com/karpathy/status/2033383295237734847
宝玉:让 AI Agent 自动从视频中抓取关键幻灯片作为文章配图
宝玉分享了用 Codex App 自动为文章抓取演讲视频关键帧的案例,16 张配图全由 AI 自动选取截图,仅 1 张需微调,大幅替代了以往手动截图的繁琐流程。

🔗 https://x.com/dotey/status/2033439205783634355
LookaheadKV:无需生成即可预见未来的 KV Cache 淘汰策略
LookaheadKV 提出一种快速准确的 KV Cache 淘汰方法,通过瞥见未来机制在不实际生成 token 的情况下判断哪些缓存可安全移除,提升长序列推理效率。

🔗 https://x.com/_akhaliq/status/2033395963423785123
dots.mocr:多模态 OCR 新 SOTA,文档解析仅次于 Gemini 3 Pro
dots.mocr 在 olmOCR Bench 上达到 83.9 分新纪录,超越所有开源文档解析系统。在图表、UI 布局、科学图表等结构化图形解析上,SVG 重建质量甚至超过 Gemini 3 Pro。

🔗 https://x.com/_akhaliq/status/2033386435538022438
宝玉:不给 AI 设限反而能突破预期,使用者心态决定 AI 表现
宝玉分享观察——完全不限制 AI 的可能性、只要求任务必达时,AI 会不断尝试各种途径最终突破预期。有时越懂技术的人反而越给 AI 设限,不敢放手尝试。
🔗 https://x.com/dotey/status/2033361892777832537
Kimi:提出 Attention Residuals 新方法,重新思考深度聚合机制
月之暗面发布 Attention Residuals 研究,用学习型、输入依赖的注意力机制替代传统固定残差连接,能选择性地检索先前层表征,有效缓解信息稀释和隐状态膨胀问题。

🔗 https://x.com/Kimi_Moonshot/status/2033378587878072424
Ollama:正式成为 OpenClaw 官方提供商,所有模型无缝接入
Ollama 宣布成为 OpenClaw 的官方 provider,用户只需执行 onboard 命令即可接入,所有 Ollama 模型均可与 OpenClaw 无缝协作,直接在聊天应用中完成各类任务。

🔗 https://x.com/ollama/status/2033339501872116169
📄 HF Papers 深度解读
今日 46 篇论文,Top 10 深度解读
今日主线一:AI 元研究的突破——复旦团队让 AI 学会判断论文潜在影响力,Scientific Judge 超越 GPT-5.2 和 Gemini 3 Pro,这标志着 AI 从"写论文"进化到"评论文"。主线二:开源 Agent 全面崛起——OpenSeeker 仅用 11,700 条合成数据训练出 30B 搜索 Agent,在 BrowseComp 上以 29.5% 大幅领先第二名(15.3%),全栈开源。主线三:注意力机制的深层革新——Kimi 的 AttnRes 和字节的 MoDA 分别从残差路径和跨层检索两个角度重新设计深层 Transformer。
Insight:当 AI 开始具备"科研品味",下一个被革新的不只是论文写作,而是整个科研评审体系——从同行评议到基金评审都将面临范式转换。
Scientific Taste: 用强化学习让 AI 学会判断论文潜在影响力
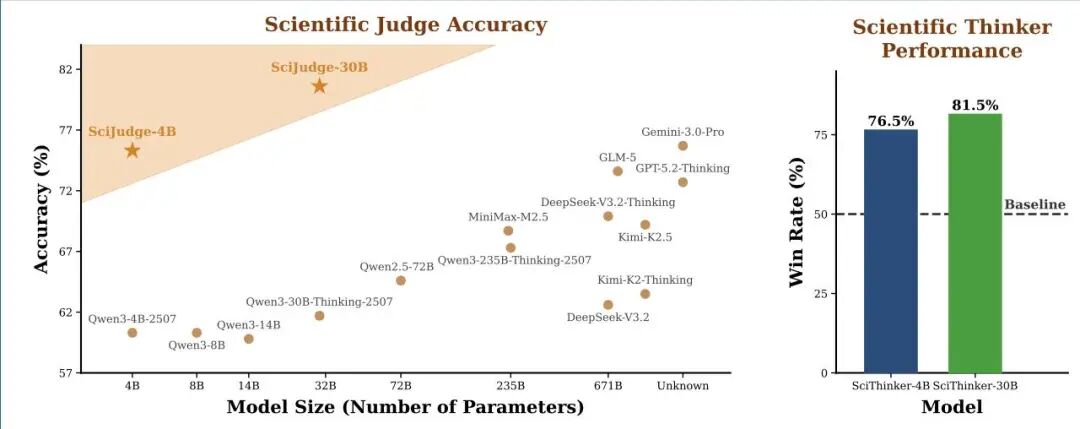
顶尖科学家不只擅长执行研究,更具备一种难以言传的「科学品味」——判断哪个研究方向值得追,哪篇 idea 有真正的影响力。这种能力此前被认为只属于人类专家,而本文来自复旦大学的团队尝试将其系统化、可学习化。
核心动机:现有 AI 科学家研究大多聚焦于「执行能力」(如文献检索、自动实验),对 AI 如何判断研究价值这一上游问题几乎空白。论文指出,引用数是社区对研究价值的长期集体反馈,可以作为偏好信号的代理。
方法框架 RLCF(Reinforcement Learning from Community Feedback):研究分两个模块。首先训练 Scientific Judge,基于 70 万对「高引 vs 低引」论文摘要对(按领域和发表时间严格匹配)进行偏好建模,让模型学会从 abstract 层面判断哪篇论文更有影响力潜力。随后以 Scientific Judge 作为奖励模型,通过强化学习训练 Scientific Thinker,使其提出的 research idea 分布朝高影响力方向对齐。
关键结果:Scientific Judge 在 SciJudgeBench 上超越 GPT-5.2、Gemini 3 Pro 等闭源旗舰模型,且泛化到未见领域、未来年份测试集和同行评审偏好场景。Scientific Thinker 生成的 idea 在集成评估下胜过未对齐基线模型的胜率显著提升。
一句话总结:用 70 万对高低引用论文作偏好数据,通过 RLCF 两阶段训练,首次系统验证了 AI 可以习得「科学品味」并将其迁移到 idea 生成中。
🔗 https://huggingface.co/papers/2603.14473 · https://paperscope.ai/hf/2603.14473
OpenSeeker: 全开源训练数据驱动的前沿级搜索 Agent

深度搜索能力正成为前沿 LLM Agent 的标配,但高性能搜索 Agent 的训练数据长期被工业界垄断,开源社区缺乏完整的可复现路径。上海交通大学团队推出 OpenSeeker,将模型权重、训练数据、合成 pipeline 全部开放,试图打破这一壁垒。
核心动机:BrowseComp 基准上,截至 2025 年 4 月即便最强闭源模型也难超 10 分;到 2026 年 3 月已有超过 10 个 Agent 突破 50 分。然而这些高分 Agent 几乎全部来自有充裕算力的大厂,训练数据从未公开。OpenSeeker 针对这一「数据黑箱」问题切入。
两项核心技术:(1)基于事实的可控 QA 合成:通过拓扑展开(topological expansion)和实体混淆(entity obfuscation)对 Web 图谱进行逆向工程,自动生成复杂度和覆盖度可控的多跳推理问题,从根本上解决数据稀缺问题。(2)去噪轨迹合成:引入回顾式摘要机制(retrospective summarization),对 teacher LLM 生成的搜索轨迹进行噪声过滤,显著提升动作序列质量,使 SFT 训练更有效。
关键结果:OpenSeeker(30B,仅 11,700 条合成样本 + 单次 SFT 训练)在 BrowseComp、BrowseComp-ZH、xbench-DeepSearch、WideSearch 四个基准上均达到 SOTA 开源水平。BrowseComp 上以 29.5% 大幅领先第二名全开源 Agent DeepDive(15.3%),BrowseComp-ZH 上甚至超越经过持续预训练 + SFT + RL 的通义 DeepResearch(48.4% vs 46.7%)。
一句话总结:用不到 1.2 万条合成训练样本 + 单次 SFT,OpenSeeker 实现了对工业界闭源搜索 Agent 的比肩乃至超越,并将完整数据和权重开源,为搜索 Agent 研究提供了可复现的基准起点。
🔗 https://huggingface.co/papers/2603.15594 · https://paperscope.ai/hf/2603.15594
EnterpriseOps-Gym:企业级有状态智能体规划与工具调用基准测试

当前 AI Agent 的企业落地面临一个根本性矛盾:现有评测基准过于简化,根本无法反映真实业务场景的复杂性。EnterpriseOps-Gym 正是为填补这一空白而生。
基准设计:研究团队构建了一个容器化沙盒环境,内含 164 张数据库表和 512 个可调用工具,跨越客服、HR、IT 等 8 大业务领域,共设计 1,150 道专家级任务。与 SWE-bench 等代码基准不同,这里的任务要求 Agent 在有持久状态变更的环境中维持多步骤计划,并严格遵守访问控制策略——这正是企业真实工作流的核心挑战。
核心发现令人警醒:对 14 个前沿模型的测评显示,最强的 Claude Opus 4.5 成功率仅为 37.4%,开源模型普遍低于 20%。更关键的发现是:当提供人工编写的「Oracle 计划」后,成功率提升 14–35 个百分点,这直接指向了模型的战略推理能力是当前瓶颈所在,而非工具调用能力本身。
另一个高风险问题是拒绝不可行任务的能力——最佳模型也只有 53.9% 的正确拒绝率。这意味着近半数情况下,Agent 会在无法完成的任务上执行错误操作,直接修改数据库或触发下游流程,产生难以逆转的副作用。
对企业部署的启示:研究清晰地表明,当前 Agent 尚不具备在企业环境中完全自主运行的能力。性能与成本的 Tradeoff 分析也显示,更贵的闭源模型虽有优势,但提升幅度远不够显著。EnterpriseOps-Gym 为研究界提供了一个可复现的压力测试平台,指引未来工作聚焦于长程规划和策略合规两大方向。
🔗 https://huggingface.co/papers/2603.13594 · https://paperscope.ai/hf/2603.13594
HSImul3R:物理仿真驱动的人-场景交互三维重建框架

从视频或图片重建人与场景的交互过程,是具身机器人训练数据获取的核心难题。现有方法普遍存在「视觉可信、物理失效」的困境:重建结果看起来合理,但一旦导入物理引擎,人物就会穿墙、漂浮或倒塌。HSImul3R 提出了一套以物理仿真器为核心监督信号的双向优化框架,直接攻克这一感知-仿真鸿沟。
核心架构——双向优化:框架分为两个互补方向。正向优化在固定场景几何的前提下,采用「场景靶向强化学习」来精炼人体运动,同时以运动保真度和接触稳定性作为双重奖励信号,确保脚步不悬空、手部真实触碰物体。反向优化则创新性地引入「直接仿真奖励优化(DSRO)」,利用仿真器对重力稳定性和交互成功率的反馈,反过来修正场景几何——物体的形状和位置会被迭代调整,直到满足物理约束。
数据来源灵活:HSImul3R 同时支持稀疏视角图片和单目视频作为输入,借助图像到三维生成模型建立度量一致的初始对齐,降低了数据采集门槛,方便在野外环境中收集真实人类行为。
新基准 HSIBench:研究团队同步发布了涵盖多样物体和交互场景的评测集,填补了该方向缺乏标准化评测的空白。
实验证明,HSImul3R 生成的重建结果可以直接部署到真实人形机器人,完成搬运、坐立等复杂动作,是当前少数能真正打通「感知重建→物理仿真→机器人部署」完整链路的工作之一,对机器人学习和具身 AI 数据构建具有重要参考价值。
🔗 https://huggingface.co/papers/2603.15612 · https://paperscope.ai/hf/2603.15612
将世界仿真模型锚定到真实城市:首尔世界模型

大多数视频世界模型生成的都是"虚构环境"——给定一张起始图,后续所有内容由模型凭空想象。KAIST AI 与 NAVER AI Lab 合作提出的 Seoul World Model(SWM) 反其道而行:让世界模型生成的是真实存在的首尔街道,而非杜撰出来的城市景观。
核心方案是检索增强条件生成(RAG-conditioned generation)。给定 GPS 坐标、摄像机动作和文字提示,SWM 从街景图库中检索附近的参考图,将几何结构与外观信息注入自回归视频生成过程,使每段生成内容都锚定在真实地理位置的布局之上。模型在 44 万张首尔街景图、真实驾驶视频和合成城市数据上微调一个预训练视频世界模型。
引入真实街景带来三个技术难点,论文逐一给出解法:时序错位(检索到的旧图与动态目标场景不一致)→ 跨时间配对训练策略;轨迹多样性不足与数据稀疏(车载采集间隔大)→ 构建大规模合成数据集 + 视角插值流水线;长程生成飘移 → 提出 Virtual Lookahead Sink,每段生成前持续将未来位置的检索图作为锚点重新校准。
在首尔、釜山和 Ann Arbor 三座城市的评测中,SWM 在空间保真度、时序一致性和长程稳定性上均优于现有视频世界模型,可沿数百米轨迹生成与真实城市高度吻合的视频,同时支持多样化摄像机运动和文字驱动的场景变换(如洪水、黄昏光效)。这为自动驾驶场景生成、城市规划可视化和位置感知虚拟探索提供了新路径。
🔗 https://huggingface.co/papers/2603.15583 · https://paperscope.ai/hf/2603.15583
注意力残差:用深度维注意力替代固定残差累加

现代大语言模型中,残差连接(Residual Connection)与 PreNorm 几乎是标配,但它们始终以固定单位权重对所有层的输出做均匀累加。Kimi 团队发现这种均匀聚合会导致隐藏状态随深度以 O(L) 速度增长,越深的层对最终表示的贡献越被稀释,早期层的信息无法被选择性地取用——这正是大量层可以被无损剪枝的根本原因。
论文提出 Attention Residuals(AttnRes),用深度维度上的 softmax 注意力替换固定累加。具体而言,每层用一个可学习的伪查询向量(d 维)对前面所有层的输出计算注意力权重,使当前层能够内容感知地、动态地从历史各层中选择性聚合信息。作者指出这与 RNN 在序列维度遇到问题后引入注意力机制的情形在形式上完全对称。
面向大规模训练的工程挑战,论文进一步提出 Block AttnRes:将层分组为若干 Block,仅在 Block 级表示上做注意力,把内存开销从 O(Ld) 降至 O(Nd),同时结合基于缓存的流水线通信和两阶段计算策略,使其成为标准残差连接的即插即用替代方案,几乎无额外开销。
Kimi 团队将 AttnRes 集成进 Kimi Linear 架构(48B 总参数 / 3B 激活参数),在 1.4T token 上预训练验证:AttnRes 有效缓解了 PreNorm 稀释问题,使各层输出幅度和梯度分布更均匀,所有下游评测任务均有提升。Scaling law 实验也确认改进在不同模型规模下保持一致。
🔗 https://huggingface.co/papers/2603.15031 · https://paperscope.ai/hf/2603.15031
MoDA:混合深度注意力,让大模型深度扩展不再"信息稀释"
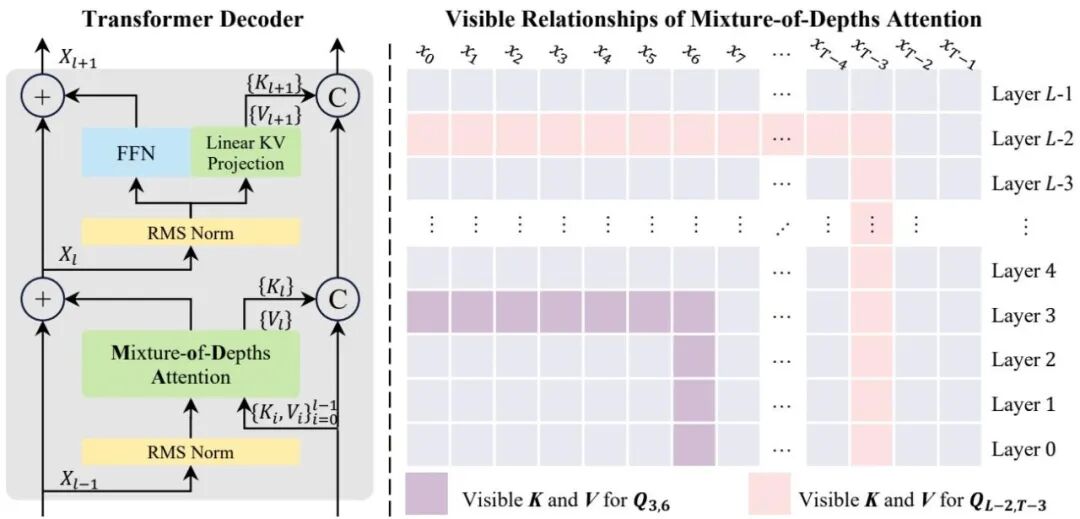
核心问题:深度扩展中的信息稀释
大语言模型扩展深度时存在一个长期困扰:浅层形成的有价值特征,在经过一层又一层的残差更新后会被逐渐"冲淡",到深层时已难以有效恢复。这本质上是残差路径的单轨制缺陷——所有历史信息都被压缩进一条隐状态轨迹,没有任何机制让深层直接"回望"浅层曾经存储的关键信息。
MoDA 的解决思路
来自字节跳动 Seed 与华中科技大学的团队提出了 混合深度注意力(MoDA)。其核心思想是:在标准的序列维度注意力基础上,同时允许每个注意力头跨层访问"深度 KV"——即同一序列位置在所有前驱层产生的 Key-Value 对。
这相当于把注意力机制从"序列内检索"扩展到了"深度维检索":模型不仅能在同一层内关注不同位置的 token,还能在同一位置回溯不同层深度上曾经编码过的特征,实现了 DenseNet 跨层连接的语义,但以注意力的数据驱动方式动态选择,而非固定稠密连接。
硬件效率的关键突破
跨层访问带来非连续内存寻址问题,这是此类方案走向实用的最大障碍。研究团队专门设计了针对 MoDA 的硬件高效算法,在 64K 序列长度下达到 FlashAttention-2 效率的 97.3%,几乎没有系统开销。
实验结果
在 1.5B 参数规模的模型上,MoDA 相比强基线(OLMo2)带来显著提升:
10 个验证集上平均困惑度降低 0.2 10 个下游任务平均性能提升 2.11% 额外计算开销仅 3.7% FLOPs
此外,MoDA 与 post-norm 组合时效果优于 pre-norm,这为架构选型提供了实用指导。
意义
MoDA 以极低的额外代价,让深层模型能够直接检索浅层已编码的关键信息,从根本上解决了深度扩展的效率递减问题,是 Transformer 深度扩展路线上一个值得关注的原语级创新。代码已开源。
🔗 https://huggingface.co/papers/2603.15619 · https://paperscope.ai/hf/2603.15619
xLSTM 蒸馏新突破:Expert 合并让线性架构无损继承 Transformer 能力

背景:线性化蒸馏的老大难问题
将 Transformer LLM 蒸馏成线性复杂度架构,是降低推理成本的重要路线。但长期以来,蒸馏出的学生模型总有一道坎迈不过去:在语言理解和知识类任务上勉强追平教师,一到数学推理、代码生成这类需要强生成能力的任务上就明显掉队。
本文的目标:无损蒸馏
来自 NXAI 和林茨大学(Sepp Hochreiter 团队)的研究者将目标定义为无损蒸馏(Lossless Distillation),并用"容差修正胜平率(Win-and-Tie rate)"作为评估指标:在一组任务上,学生模型与教师模型的表现在允许误差范围内打平甚至超越,才算真正成功。
关键创新:Expert 合并阶段
论文的核心贡献是在蒸馏流程中引入了一个额外的 Expert Merging 阶段:先对各层独立进行线性化专家训练,再将多个专家合并成单一模型。这种分治再合并的策略,让每个专家在局部优化时不受其他层干扰,合并后又能发挥协同效应,显著提升了学生模型在复杂生成任务上的表现。
实验覆盖与结果
团队以 xLSTM 作为学生架构,对 Llama、Qwen、OLMo 系列的 base 模型和指令微调模型进行蒸馏:
xLSTM-Qwen2.5-7B-IT 和 xLSTM-Llama3.1-8B-IT 在数学、代码、STEM、对话等多个生成基准上达到或超越同类线性化方法的最佳基线 部分任务上学生模型甚至超越教师,验证了 xLSTM 线性架构本身的表达潜力
意义
xLSTM 架构具备线性推理复杂度,在长序列上推理成本远低于 Transformer。本文将高性能 Transformer LLM 的知识有效迁移到 xLSTM,向"用更少能耗部署同等能力模型"这一目标迈出了重要一步,对边缘部署和大规模推理场景均有实际价值。
🔗 https://huggingface.co/papers/2603.15590 · https://paperscope.ai/hf/2603.15590
解剖谎言:多阶段诊断框架追踪视觉语言模型幻觉根源

视觉语言模型(VLM)的幻觉问题一直是落地部署的核心障碍:模型会生成听起来合理但事实错误的内容。新加坡国立大学的研究团队提出了一个全新诊断范式,将幻觉从"静态输出错误"重新定义为"动态认知病理"。
核心发现:几何-信息对偶原理
论文最重要的理论贡献是发现了"几何-信息对偶"(geometric-information duality):在认知状态空间(Cognitive State Space)中,模型生成轨迹的几何异常与信息论意义上的高惊讶度(surprisal)在本质上是等价的。这意味着幻觉检测可以被优雅地转化为几何异常检测问题——不需要昂贵的标注数据,只需在低维空间中观察轨迹偏离。
三阶段诊断框架 CAD
研究设计了一套信息论探针,将模型生成过程映射到可解释的低维认知状态空间,并定义三类可测量的病理状态:
- 感知不稳定性
(Perceptual Entropy, H_Evi):模型在证据生成阶段出现幻觉,如"看到"图中并不存在的摩托车 - 逻辑因果失败
(Inferential Conflict, S_Conf):模型结论与自身证据自相矛盾,即"认知失调" - 决策模糊性
(Decision Entropy, H_Ans):最终答案阶段的不确定性过高
为什么这件事重要?
传统评估只看准确率,一个"双重失败巧合答对"的案例(幻觉证据 + 逻辑矛盾 → 碰巧正确答案)在准确率指标下会被算作成功,但模型的推理过程是完全损坏的。CAD 框架能精确捕获这类隐性失败,在 POPE(二元 QA)、MME(综合推理)、MS-COCO(开放字幕)三个基准上均达到最优性能,且在弱监督条件和含噪校准数据下依然鲁棒。
这项工作为构建"推理过程透明可审计"的 AI 系统提供了基础工具,对医疗、法律等高风险 VLM 应用场景意义重大。代码已开源:github.com/Lexiang-Xiong/CAD
🔗 https://huggingface.co/papers/2603.15557 · https://paperscope.ai/hf/2603.15557
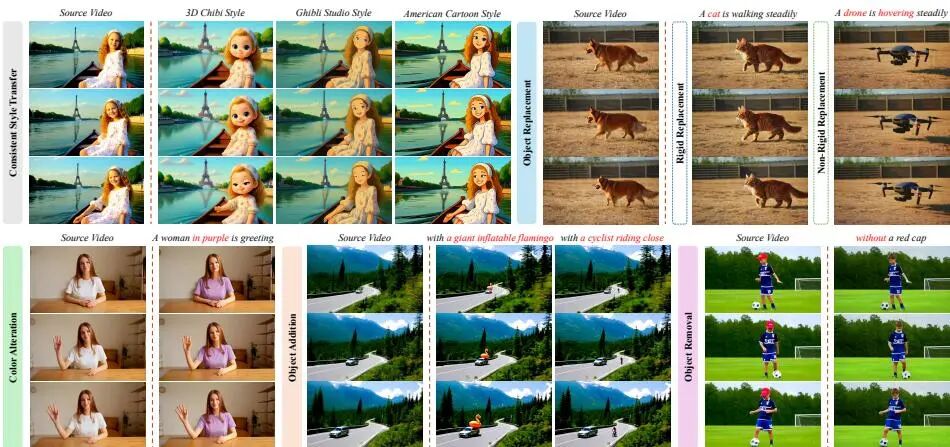
ViFeEdit:无需视频数据,仅用图像微调视频扩散 Transformer
视频编辑模型的训练通常需要海量配对视频数据,构建成本动辄耗费一万 GPU 天以上。新加坡国立大学与上海交通大学的联合团队提出 ViFeEdit,一个无需任何视频训练数据、仅靠 2D 图像就能微调视频扩散 Transformer 的框架。
核心思路:解耦空间与时间建模
现代视频 DiT(如万象 Wan 系列)采用 3D 全注意力机制,同时处理空间和时间维度,导致无法直接用图像数据训练。ViFeEdit 的关键创新是一种架构重参数化(architectural reparameterization):将 3D 注意力中的空间独立性从时间维度中剥离出来,使调优器可以单独在 2D 图像上学习空间编辑行为,而预训练的时间模块保持冻结,继续维持帧间时序一致性。
双路径管线设计
ViFeEdit 采用双路径(dual-path)推理管线,为噪声调度配备独立的时间步嵌入,增强了对多种条件信号的适应性。这使得同一个框架可以支持六类精细化视频编辑任务,而不需要为每类任务单独准备视频数据:
风格迁移(style transfer) 刚体替换(rigid replacement) 非刚体替换(non-rigid replacement) 颜色变换(color alternation) 对象添加(object addition) 对象删除(object removal)
意义与局限
这项工作的实用价值在于大幅降低视频编辑能力的获取门槛——中小团队无需搭建大规模 GPU 集群、无需收集配对视频,只需准备图像数据即可完成微调。实验表明在时序一致性和编辑忠实度上均有竞争力的表现。
当然,纯图像训练在处理复杂运动模式时仍有固有局限,时序模块完全冻结意味着无法学习新的运动风格。但作为一个"以最小代价撬动视频编辑能力"的工程方案,ViFeEdit 提供了一条值得关注的技术路径。代码已开源。
🔗 https://huggingface.co/papers/2603.15478 · https://paperscope.ai/hf/2603.15478
今天值得持续关注的三个趋势:
1. AI 科研元能力:从辅助写作到独立判断论文价值,AI 在科研生态中的角色正在升级
2. 注意力机制的深度革命:AttnRes 和 MoDA 表明,深层 Transformer 的信息流优化仍有巨大空间
3. 全开源 Agent 生态:OpenSeeker 证明开源数据+开源模型可以达到甚至超越闭源水平
感谢读到这里 🙏 觉得今天的论文解读有收获,欢迎 点赞、在看、转发 三连支持~想第一时间看到新推送,记得给公众号加个 星标 ⭐,明天见 👋
© 2026 AI Insight · 机智流 · 本文由 Intern-S1-Pro 等 AI 生成,可能有误










