贾鹏 | 至简动力创始人兼CEO,曾任理想汽车智驾技术研发负责人,主导多项关键技术研发。此前在英伟达、IBM任职,经验深厚。2025年他进入具身智能领域,创立至简动力,提出创新架构,半年获五轮20亿融资。
在近日举办的GTC 上,贾鹏以新身份首次深入剖析了具身智能通用能力与工业高要求之间的矛盾,并重点分享了至简动力在基座模型上的突破性实践——基于「大一统」的基座模型架构,其团队已可实现在短短20 分钟内,实现下游任务100% 的成功率。
骨感现实中的巨大鸿沟
在具身智能实际的落地过程中,存在一个巨大的现实鸿沟:目前具身智能的整体泛化能力比较差,尤其在灵巧操作任务上,几乎没有任何泛化能力可言,大多数场景中都存在落地难题。
为了制作Demo,大家往往会针对单一任务大量采集数据。可即便如此,很多精细操作任务的成功率也难以提高。与此相对的是,在工厂等应用场景中,只有达到100%的成功率,才能真正形成生产力,对用户产生价值。
“通用能力的不足与用户的高要求之间存在着巨大鸿沟,这也是具身智能发展至今仍未大规模落地的真正原因。”
贾鹏介绍称,至简动力(Simplexity Robotics)希望以极简架构破解复杂难题——通过打造简单统一的底层框架,致力于让通用基座模型兼具「高泛化性」与「100%任务成功率」,跨越落地鸿沟,形成真正的工业生产力。
要想达成这一目标,需要在四个方面努力:
1、构建高上限的基础模型;2、更高效的数据采集方式;3、确保模型能快速达到100%的成功率;4、实现端侧的实时推理和训练

他尤其指出,很多工厂对节拍和延时有非常高的要求,系统必须具备实时的推理能力。同时,很多工厂因为保密原因不允许接入外网,因此具身模型必须部署在端侧,这极具挑战。
三大技术流派的利与弊
贾鹏介绍称,目前具身智能模型的技术路线并不收敛,行业内还存在路线之争,主要分为以下三个流派:
1、双系统范式:利用一个较大的VLM进行指令的理解和任务的拆解,再通过一个较小的、端到端的VLA模型做快速的执行。
2、端到端的VLA模型:它将指令理解、任务拆解以及动作生成合为一个整体,端到端地去完成任务。
3、世界模型:这是最近比较热门的路线,它不再以传统的VLM作为基础,而是基于视频生成模型或者是高斯泼溅生成模型,实现对世界的理解、预测以及动作的生成。

这三条路线都有各自的优势和不足。
1、双系统基于VLM对任务的拆解和调度,其优点是可以处理长程任务。但由于双系统是由两个不同的模型构成的,二者运行帧率不同,因此协同与联合训练都非常困难。
“事实上,我们团队是全球最早提出并量产双系统的团队,因此踩过非常多的坑。”
2、端到端VLA模型普遍基于预训练的VLM去做具身的指令微调。在此过程中,大家都发现灾难性遗忘是不可避免的:第一是视觉能力的遗忘,第二是语言的思维链(CoT)能力的遗忘。
“行业已普遍认为视觉是具身智能中最重要的模态,那么一旦视觉识别能力下降,对灵巧操作的影响就非常大。因此,很多VLA模型训练出来之后,泛化能力几乎为零。”
3、世界模型相对于双系统和端到端VLA,是一个巨大的范式变化——它从「以语言为中心」转向「以视觉为中心」、从「以理解为主」转向「以生成为主」。
不过,该方法同样伴随着语言中的幻觉问题。所以目前世界模型在灵巧操作上的性能并没有超过VLA。同时它还有一个劣势,就是对算力的要求非常高。
基座模型的「大一统」设计哲学
在此背景下,至简动力认为,所有的模型设计都应追求结构简单。随着数据的增加,这种没有太多人为先验设计的结构,上限反而会更高。
首先贾鹏认为,具身基础模型需要四种能力:
1、多模态理解与建构:它需要对语言指令、任务逻辑、3D空间及其时序变化以及本体自身的状态进行统一的理解和建构,这意味着模型的输入天生就是多模态的,而且多模态之间必须进行统一的建模和编码,而非简单的跨模态对齐。
2、闭环交互与多模态生成:模型在理解指令和任务的基础之上,需要与世界进行交互,而这个交互一定是闭环的——动作会改变世界,同时世界的变化也会影响动作。这就意味着需要同时对世界的变化和动作进行联合生成和预测,所以模型的输出也是多模态的。
3、快慢思考:模型对实时性的要求非常高,所以其结构必须非常适合端侧的推理。但仅仅是条件反射式的响应还是不够的,它需要具备在关键时刻深入思考的能力,并且能根据工况自适应地调整思考的速度。
4、自我评估与调整:模型还需要具备对自身状态作出评估的能力,并且根据评估的状态调整动作的生成。
综上所述,这样的模型实际上综合了双系统、端到端VLA和世界模型的所有优点。“所以,未来通用的具身基座模型,一定是一个大一统的模型。”所谓「大一统」,是四个方面的一体化:
•多模态理解的一体化、多模态生成的一体化、快慢思考的一体化,以及策略(Policy)和价值(Critic)的一体化。
“我们心目的大一统模型,是只使用单一的Transformer网络,就能实现多模态的理解和生成。但是对于我们至简这样的初创团队来说,从零训练一个原生多模态的模型是非常困难的。”
在此背景下,至简破局的方法是采用MoT (Mixture-of-Transformer)架构。这是一种在已有模型之上实现原生多模态能力的架构,其核心思想是,让不同的模态通过共享的attention层层实现跨模态的信息交互。
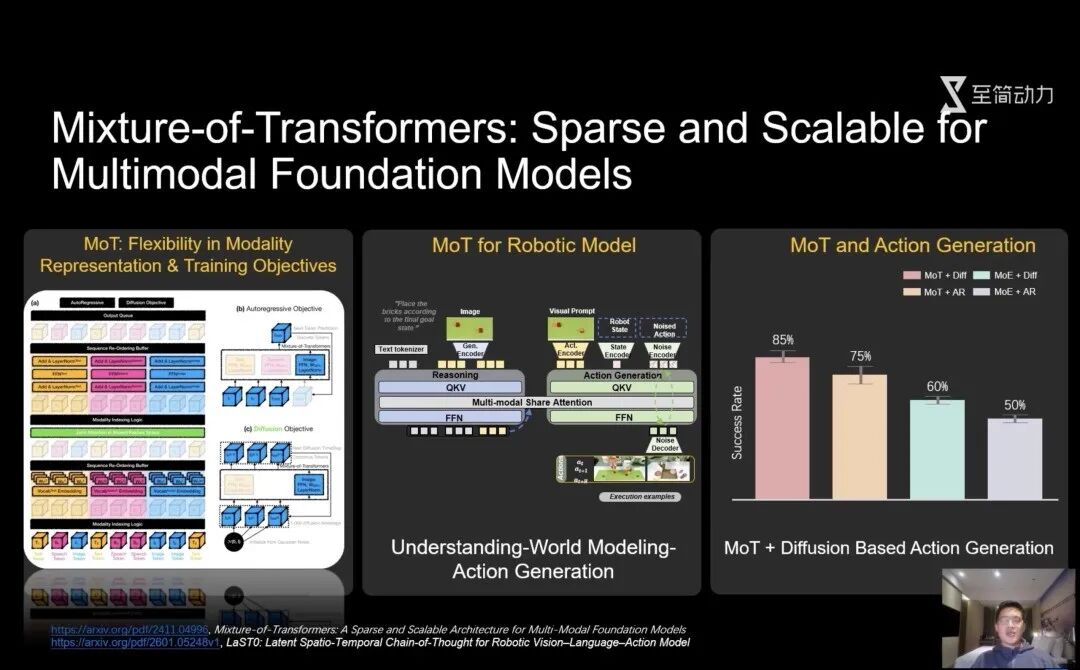
“它的输入被统一为Token序列,不同模态保留独立的QKV和FFN网络,但是通过共享的attention层进行联合建模。”
相比于从零训练原生多模态模型,MoT的优势在于它可以复用已有的单模态预训练模型,成本非常低。此外,它可以灵活扩展新模态,便于灵巧操作的拓展。
同时,通过实践,至简团队发现扩散模型在3D动作生成的效果上明显优于自回归模型。而由于MoT的不同子网络可采用不同的训练目标,所以它天然兼容了自回归和扩散两种生成方式。
至简基座模型LaST₀
贾鹏介绍称,至简动力的具身基座模型LaST₀,将理解和生成合一,引入了高效的时空多模态CoT,将VLA和世界模型的优点结合在一起,在紧凑的隐空间中对物理世界进行建模和预测。
在隐空间(Latent space)中,LaST₀会同时自回归地预测二维图像、三维点云以及本体的感知状态,实现了多模态的思维链,获得优秀的空间推理能力。同时,多模态的时空CoT也被扩展到未来的关键帧上,实现了时序上的预测和生成。
经过大规模的预训练,MoT实现了在快慢系统的统一架构中自主切换,有效地实现了深度思考与快速响应之间的无缝交互,从而实现了更高的推理效率,并保证了高帧率、低延时的要求。

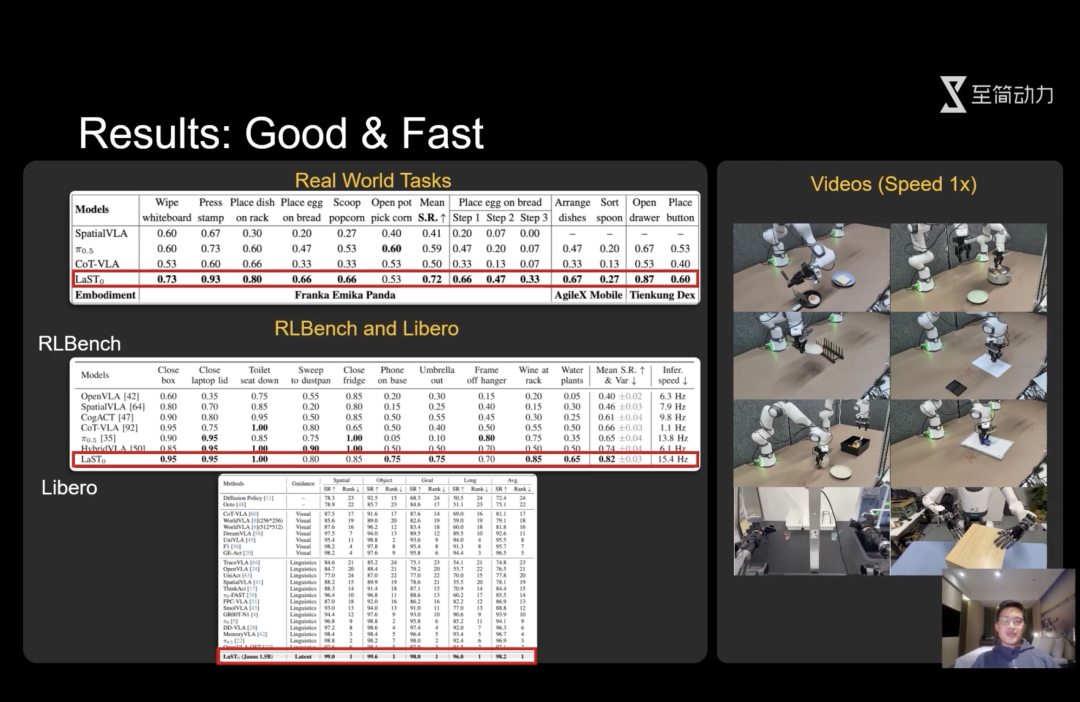
至简团队在仿真任务和真实场景上评估了LaST₀的效率。结果显示,在仿真和真实场景中,LaST₀均实现了SOTA,大幅超越了之前的基座模型,同时比显式的CoT方法实现了约14倍的加速。
在长程任务中,LaST₀也具备很好的容错能力,即使中间被故意打断,它也能从错误中快速恢复。
「每个模态仅需一个Token」
“我们发现,2D视觉语义、3D空间结构以及机器人自身状态都需纳入考量——模态越丰富,精细操作成功率越高。由此,多模态建模产生的大量Token引发业界担忧,因其或许会降低模型推理效率。”
但贾鹏指出,实际上,每个模态仅需一个Token,再增加Token也并不会显著提高成功率。

“我们还发现,持续预测帧数越多,模型效果越好。不过,实际部署中,不同难度任务所需的预测时长不同。通过大规模预训练,模型能自适应调整预测时长,以最佳推理速度完成任务,这实现了另一种形式的快慢系统。”
根据评估结果,LaST₀在真实和仿真场景中均达SOTA水平,远超之前基座模型,且比显式CoT方法加速约14倍。长程任务中,LaST₀容错能力强,即便中间被打断,也能快速从错误中恢复。
如何应对「灾难性遗忘」?
在上文提到的「VLM 具身微调的灾难性遗忘」问题中,影响最大的是视觉能力的遗忘。可以发现,随着VLM模型层数的加深,视觉特征会逐渐减弱甚至消失。
相比之下,MoT是个非常灵活的架构,可以将视觉特征注入到更深层的Transformer层中,大幅提升模型性能。
在评估实验中,LaST₀模型仅通过数十条数据就能实现煎鸡蛋、盛爆米花,甚至使用筷子这样复杂的操作。
其中一个案例展示是「3D乐高积木搭建」——先由人搭建积木,并故意遮挡摄像头,不让模型看到人是拼搭过程。之后模型会根据最终状态和空白时的初始状态,推理出整个搭建过程,并驱动机械臂复刻出相同的形状。

“它有自己的思路,搭建过程可能跟人完全不同。我们通过语言的思维链描述搭建逻辑和过程,并最终通过动作生成实现积木拼搭。”
数据规模化的最佳方案
目前行业获取数据有以下几种方法:
1、合成数据:可以快速实现数据的规模化,但在柔性物体、可变形物体、透明物体和流体的模拟上存在不足,对触觉、力觉的模拟上也有所欠缺,无法满足落地的需求。
2、真机数据采集:真机采集和真实任务的Domain Gap是最小的,但是效率非常低下。
3、遥操作:这种半真机采集效率非常高,但其硬件往往需要末端执行器和真机保持一致,大大地限制了使用范围。
4、Ego-centric数据:基于人类第一视角的视频,数据来源非常广泛。但实践下来,此类数据质量并不高,在需要力、触觉等精细操作的场景下,仅仅依靠视频是不够的。
至简动力选择的是便携式手套进行数据采集。它既能保证数据采集的效率,也能保证数据的质量,同时还能很方便地扩展到更多的模态,比如说触觉、力觉等等。

“我们认为这是目前数据规模化的最佳方案。这些数据不仅可以适配到不同形态的灵巧手上,同时也能适配到二指和三指夹爪上。”
针对垂直领域任务,高质量的SFT数据至关重要。在工厂落地场景中,传统真机采集往往是不可行的。相比之下,便携式数据手套不仅不影响正常作业,还能通过额外收益提升工人配合度。实践证明,这种高精度的人手采集数据完全能满足SFT 对数据质量的严苛要求,显著提升了模型在下游任务中的抓取精度与成功率。
强化学习
从99%到100%的最后一公里
如何让一个通用模型在单一任务上实现100%的成功率?强化学习(RL)已经成为行业共识,但它也存在两大问题:
1、效率极其低下:具身的强化学习监督信号非常稀疏,往往只有动作完成和未完成两种结果。为了增加过程监督信号,大家往往通过人工干预提供稠密的Reward信号,但随之而来的负面问题是效率极其低下。
2、容易过拟合:经过强化学习之后,模型往往失去了泛化性,过拟合到了单一场景,甚至只是小幅度地挪动一下目标物体的位置,模型都会失效。
贾鹏团队发现,强化学习,尤其是RLVR,并不会创造新的知识,它只是重新调整了模型输出的概率分布,强化学习的能力上限仍然是由基座模型的能力决定的。

为解决RL问题,至简动力采取了虚实结合的方法,提出了Twin-RL框架。
“我们通过3D GS(高斯泼溅)把场景重建为虚拟的数字孪生。在虚拟环境中,训练的并非具体操作,而是放大模型的探索空间,并且通过并行训练大幅提升探索的效率。另一方面,我们可以锁定模型更容易出错的位置,来指导真机的强化学习,提升效率。”
同时,当前的强化学习大多数都是针对动作(Action)的强化,但是Action往往只有成功和失败两种状态,监督十分稀疏。而至简动力的基座模型具备了稠密的时空特征,可以针对过程中的特征进行更加稠密和更加高效的强化训练。
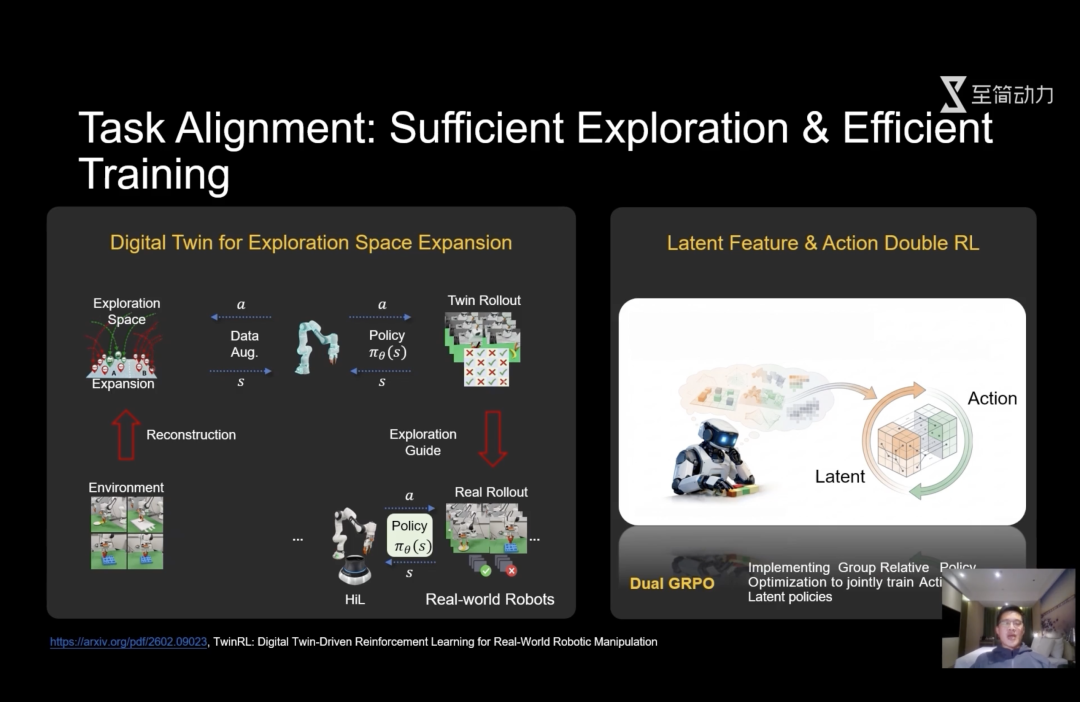
基于此,至简也提出了DoubleRL强化学习框架,在特征生成和动作生成两个层面进行双重的强化学习,效果和效率进一步提升。
“在大多数下游任务中,我们都可以在20分钟内实现100%的成功率,而且这个成功率是具备泛化性的成功率,在任意位置都能达到100%。”

由此看来,至简动力已经形成了一套行之有效的方法论:更高上限的一体化模型、更高效的数据采集方式、更高效的强化学习框架、端侧的推理引擎和训练框架。通过这套方法论,至简可以在保证模型泛化性的同时,在最短的时间内实现单一任务的100%成功率。










