3 月 16 日到 19 日,被誉为“AI 超级碗”的 NVIDIA GTC 2026 即将在硅谷拉开帷幕。说实话,这次大会的关注度比以往任何一届都要高,因为现在整个市场的情绪已经从去年的“疯狂砸钱”转向了“你得证明 ROI”。华尔街的分析师们都把这次大会当成一块试金石——AI 这条赛道到底还能不能继续狂奔下去?
最近关于GTC Preview的分析和研报已经非常多了,这篇文章我们就来盘点一下,花旗、摩根士丹利、瑞银、摩根大通等投行的研报,以及一些其他机构的观点,看一次综合的Preview。
不只是卖芯片,NVIDIA 要做 AI 时代的“水电煤”
这次 GTC 最大的看点,其实不是某一款新芯片,而是 NVIDIA 想要传递的一个战略信号:我们不再只是一家 GPU 公司,而是要做 AI 时代的全栈基础设施供应商。
黄仁勋会之前提到的的五层技术栈——从最底层的能源管理,到芯片设计,再到数据中心基础设施,然后是 AI 模型,最后到应用层。这套组合拳的目的很明确:告诉客户和投资人,NVIDIA 已经不是那个只会卖显卡的公司了,我们现在掌控的是整个 AI 产业的命脉。
更有意思的是,NVIDIA 最近开始推一个新概念叫“AI 工厂”。什么意思呢?就是把数据中心重新定义成一个生产车间,输入是数据和电力,输出是 Token 和洞察。这个叙事方式很聪明,因为它把原本看起来“烧钱”的资本支出,变成了“创造收入”的生产投资。
Rubin 架构:10 倍成本降低的推理革命
Vera Rubin 架构肯定是这次GTC大会上绕不开的一个话题。
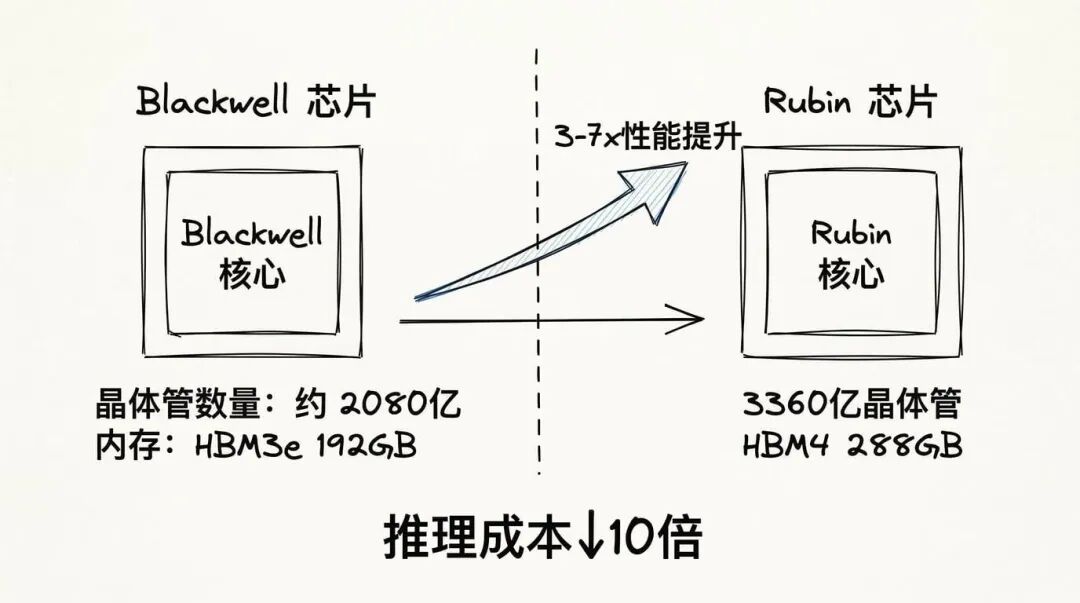
3360 亿个晶体管,288GB 的 HBM4 内存,相比上一代 Blackwell 在某些计算场景下性能提升 3 到 7 倍。但这些都不是最关键的,最关键的是,Rubin 能把 AI 推理的成本降低 10 倍。
为什么推理成本这么重要?因为现在 AI 应用的瓶颈已经不在训练上了,而在推理上。每天有多少人在用 ChatGPT?每天有多少企业在调用 API?这些都是推理任务,而推理的成本直接决定了 AI 能不能真正普及到千家万户。
Rubin 的晶圆生产会在 3-4 月开始加速,预计 2026 年下半年正式投产,第四季度开始大规模出货。不过有个小问题,HBM4 的设计最近做了调整,这可能导致 2026 年全年供应都会比较紧张。所以如果你是云厂商或者大模型公司,现在就得开始排队了。
LPX 机架:Groq 技术加持的推理芯片
第二个重磅是 LPX 推理机架,核心技术来自 NVIDIA 去年底收购的 Groq 公司。
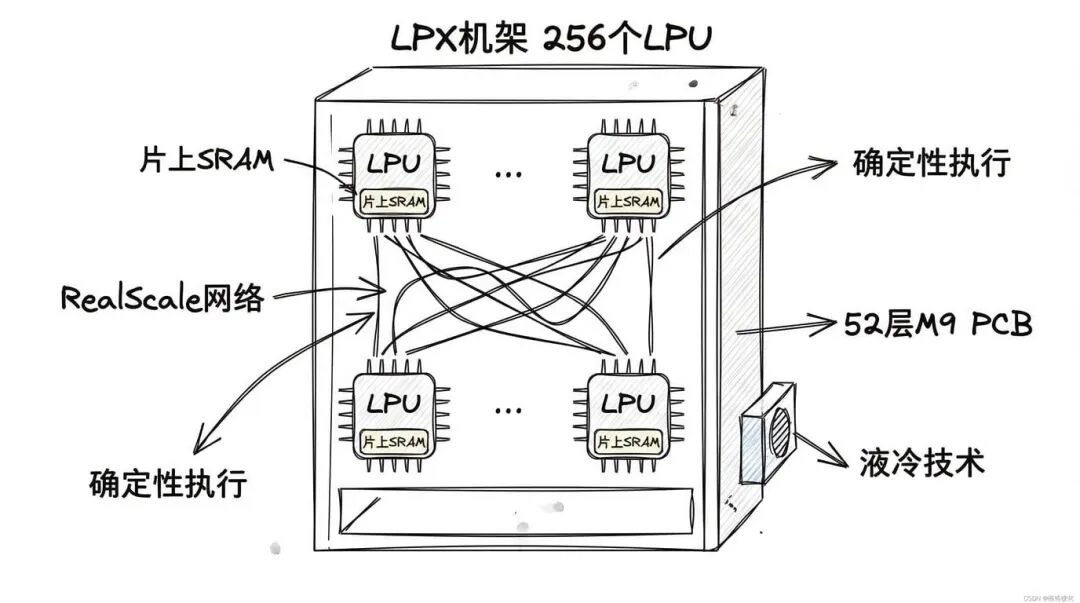
Groq 的 LPU(语言处理单元)跟传统 GPU 有个本质区别:它把大量内存直接塞进芯片里,而不是像 GPU 那样依赖外部的 HBM。这样做的好处是什么?延迟非常低。Groq 之前做过演示,生成 1 万个“思考 token”只需要大约 2 秒钟,这个速度是传统 GPU 架构很难达到的。
NVIDIA 这次要展示的 LPX 机架,预计会塞进 256 个 LPU,是第一代 64 个 LPU 的四倍。整个系统采用 52 层的 M9 Q-glass PCB(这是目前最高端的电路板材料),配合液冷技术,专门用来处理那些对延迟极度敏感的推理任务,比如实时语音对话、长上下文推理、视频生成等等。
LPX 不是来替代 Rubin 的,而是跟 Rubin 形成互补。可以理解为,Rubin 是全能型选手,既能训练又能推理;而 LPX 是推理专家,在特定场景下能把延迟压到极致。
CPO 技术:从铜线到光的物理革命
第三个看点是 CPO(共封装光学)技术。
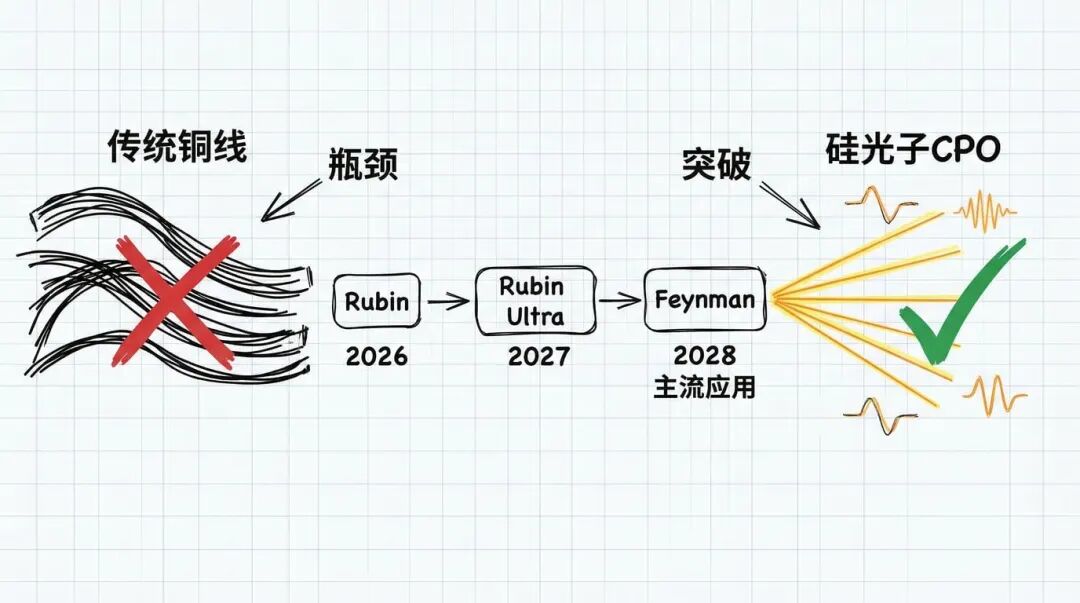
现在的数据中心,GPU 之间的连接主要靠铜线或者可插拔光模块。但随着算力需求越来越大,铜线的带宽瓶颈越来越明显,信号损耗大、功耗高、传输距离受限。CPO 的思路是直接把光引擎集成到交换机芯片上,用光信号代替电信号来传输数据。
这个技术的好处是显而易见的:带宽更高、功耗更低、传输距离更远。但问题是成本和良率。根据投资者调研的结果,大部分人预期 CPO 要到 2028 年的 Feynman 架构才会成为主流。不过 NVIDIA 可能会在这次 GTC 上展示一些早期的 CPO 应用,比如在 Rubin Ultra 的某些高端 SKU 上先试水。
对于供应链来说,CPO 是个巨大的机会。传统的光模块厂商、硅光子公司、先进封装厂都会受益。
Kyber 机架:兆瓦级算力的疯狂构想
如果说前面几个还算“正常”,那 Kyber 机架就真的是在挑战物理极限了。
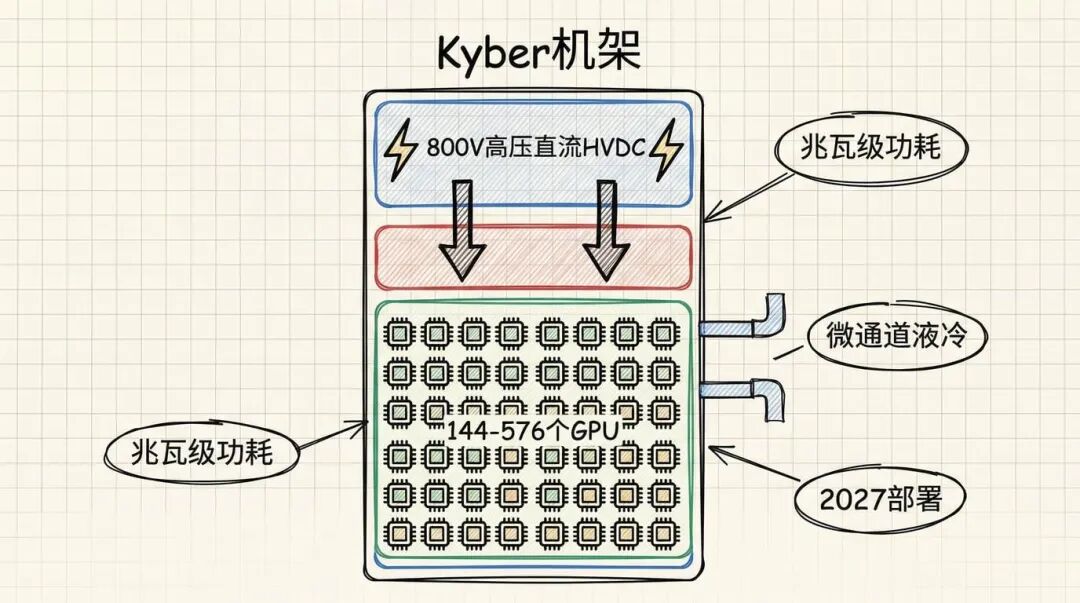
Kyber 是为 Rubin Ultra 设计的下一代机架系统,预计 2027 年下半年部署。单个机架可能塞进 144 个甚至 576 个 GPU,总功耗达到兆瓦级,相当于一个小型发电站的输出功率。
为了支撑这么恐怖的功耗,NVIDIA 会推两项革命性技术。第一个是 800V 高压直流供电(HVDC)。传统数据中心用的是交流电或者低压直流电,但在兆瓦级功耗下,这些方案的效率太低了。800V HVDC 能大幅提升电源转换效率,减少能量损耗。
第二个是微通道液冷技术。空气冷却在这个功耗级别下已经完全不够用了,必须用液体直接接触芯片表面带走热量。NVIDIA 可能会在 GTC 上展示一个 mini 版的 HVDC 系统作为概念验证,让供应链提前准备起来。
说实话,Kyber 这个东西听起来有点科幻,但如果真的能落地,那就意味着单个数据中心的算力密度会再上一个数量级。这对电力基础设施、散热技术、机房设计都是巨大的挑战。
OpenClaw:智能体 AI 的杀手锏
硬件说完了,再聊聊软件。这次 GTC 在软件层面最大的亮点,可能是 OpenClaw 智能体框架的发布。
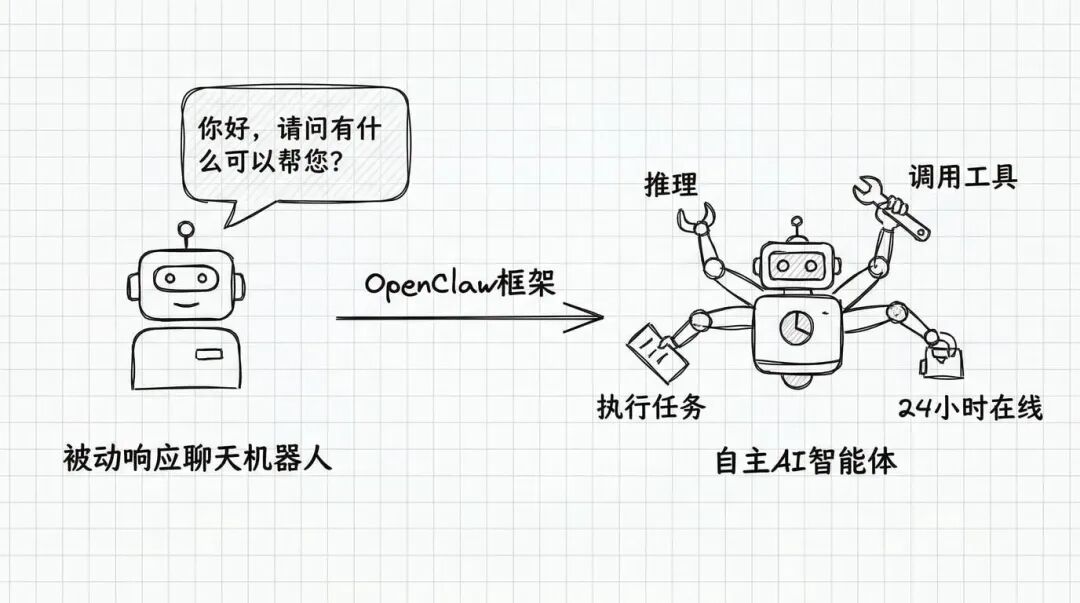
什么是智能体 AI(Agentic AI)?简单说,就是 AI 从“被动回答问题”进化到“主动完成任务”。以前你问 ChatGPT 一个问题,它给你一个答案,就结束了。但智能体 AI 可以自己拆解任务、调用工具、执行多个步骤,最后把结果交给你。
黄仁勋对 OpenClaw 框架给予了极高的评价,甚至有报道称他将其描述为“可能是有史以来最重要的软件发布”。
有资料说在 GTC 现场,参会者可以用 DGX Spark 平台亲自定制一个 24 小时在线的 AI 助手,能直接处理本地文件、执行工作流。尽管 OpenClaw 功能强大,但该开源框架被指出存在一些安全漏洞。因此,英伟达被曝正在开发一个名为 NemoClaw 的平台。NemoClaw 是基于 OpenClaw 的强化、安全版本(NemoClaw Enterprise),专为需要更高审计能力和严苛安全性要求的高机密企业环境而设计。
物理 AI:从虚拟世界走向现实世界
除了数据中心,NVIDIA 还有一个重要布局,物理 AI,也就是机器人和自动驾驶。
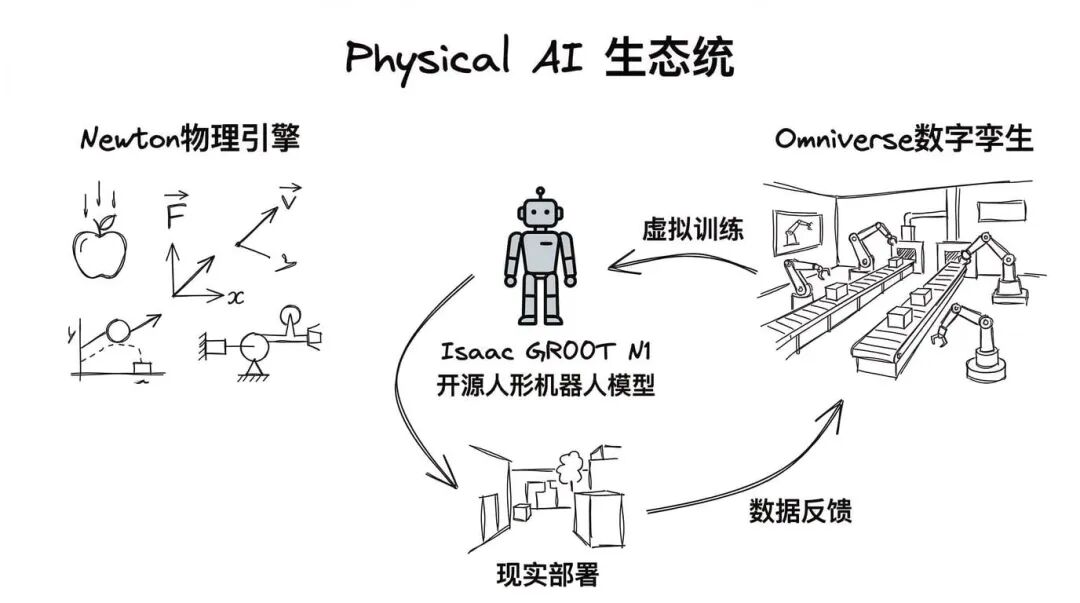
英伟达的Isaac GR00T N1是全球首个开源的人形机器人基础模型。配合新一代 Newton 物理引擎和 Omniverse 数字孪生平台,NVIDIA 想要打造一个完整的“虚拟训练、现实部署”闭环。
具体怎么玩?首先在 Omniverse 里搭建一个虚拟工厂或者虚拟城市,然后让 AI 机器人在虚拟环境里不断训练、试错。等它在虚拟世界里学会了,再把模型部署到真实的机器人上。这样做的好处是训练成本低、速度快、而且安全——毕竟虚拟世界里撞坏东西不用赔钱。
富士康已经在用 Omniverse 构建 AI 服务器生产线的数字孪生工厂了。如果这个模式能跑通,未来所有的制造业、物流业都可能用上这套方案。NVIDIA 在这里的野心很明显:不仅要占领云端的 AI,还要占领现实世界的 AI。
供应链机会
说了这么多技术,最后咱们聊点实际的——投资机会。
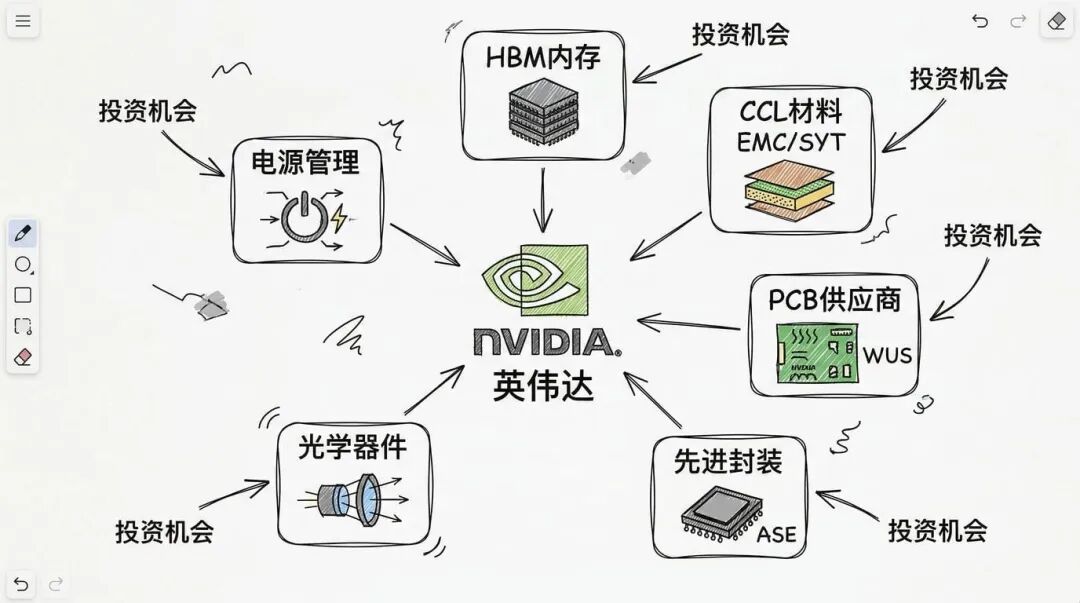
从研报来看,各大投行一致看好的是上游材料和封装厂商。PCB(印刷电路板)方面,花旗把 WUS(沪电股份)列为首选标的,为什么看好 WUS?因为不管是 LPU 还是 Kyber 中板,都需要用到 M9+Q 玻璃 CCL 这种最高端的材料,而 WUS 在这方面有量产经验。
CCL(覆铜板)材料供应商也会受益,特别是台光和生益。这两家都是 NVIDIA 认证的供应商,能生产 M9 级别的高频材料。
内存方面,虽然 LPU 用的是片上 SRAM,但 HBM仍然是 AI 芯片的核心。瑞银的报告特别强调,SRAM 有天然的容量限制,即使最先进的 SRAM,容量也只有 HBM 的五分之一左右。所以三星、SK 海力士、美光这些 HBM 供应商的地位短期内不会动摇。
先进封装领域,日月光(ASE)、安靠(Amkor)这些大厂会继续吃肉。光学器件方面,做硅光子的公司可能会有机会,但 CPO 的大规模应用可能要等到 2028 年,现在还处于布局阶段。
电源管理芯片也是个值得关注的赛道。800V HVDC 需要大量的 DC-DC 转换器、电源货架、备用电池单元(BBU)。台达、光宝科技这些公司都在这个领域有布局。
END