


人工智能(AI)领域的时髦术语往往相当有技术含量:感知机、卷积、变换器。这些词汇指的都是特定的计算方法。近来,有一个术语听起来很普通,却蕴含着革命性的意义,那就是“时间线”。如果向AI领域的某人询问他们的“时间线”,他们会告诉你预计何时能实现AGI,即通用人工智能,其定义有时可解读为一种能在大多数任务中媲美人类能力的AI技术。随着计算机速度的提升、算法的优化以及数据的积累,AI的成熟度日益提高,实现的时间线也在缩短。近期,包括OpenAI、Anthropic和谷歌DeepMind在内的大型AI实验室的负责人都表示,预计将在几年内实现AGI。 能像人类一样思考的计算机系统将实现紧密的人机协作。虽然实现AGI的近期和长期影响尚不明确,但可以预见的是,
它将在经济、科学发现和地缘政治领域引发变革。如果AGI进一步发展为超级智能,它甚至可能动摇人类在食物链顶端的地位。因此,我们必须追踪这项技术的发展进程,为即将到来的剧变做好准备。衡量AI的能力能让我们据此制定法律法规、确立工程目标、建立社会规范、调整商业模式,并从更广泛的层面去理解“智能”。
衡量任何智力能力都绝非易事,衡量AGI则面临着特殊的挑战,部分原因是人们对AGI的定义存在严重分歧。有些人通过它在基准测试中的表现来定义它,有些人则依据其内部工作原理、经济影响,甚至是基于一种“感觉”来定义。因此,衡量AI智能的第一步是就这个总体概念达成共识。
另一个问题是,AI系统相较于人类的优势和劣势不同。因此,即使将AGI定义为“在大多数任务中能媲美人类的AI”,我们依然可能会争论哪些任务真正重要,以及应以哪部分人类表现作为标准。直接比较非常困难。“我们正在构建的是‘异形’智能体。”多伦多大学荣休教授、因在AI领域的杰出贡献而获得诺贝尔奖的杰弗里·辛顿(Geoffrey Hinton)说。
尽管如此,研究人员并不气馁,而是积极设计和提出各种测试,以期能对我们的未来提供一些洞见。但有个问题依然存在:这些测试能否清楚地说明我们是否已经实现了长期追求的AGI目标?
智能的种类是无限的,即使人类的智能也是如此。智商测试包含了一系列涉及记忆、逻辑、空间处理、数学和词汇等内容的半关联性任务,可提供一种概括性的统计。从不同维度来看,个体在每项任务中的表现都依赖于流体智力(即实时推理能力)和晶体智力(即应用所学知识或技能的能力)的混合。
对于高收入国家的人群而言,智商测试往往能预测学业成就、事业成功等关键结果。但我们不能在AI上套用对人类的这种假设,因为AI的能力组合方式与人类截然不同。让机器完成为人类设计的智商测试,其结论可能与测试结果对人类的意义大相径庭。
此外,还有许多智力类型往往不在智商测试评估范围内,甚至当前大多数AI基准测试也很难对其进行衡量。这类智力包括社会智力(例如进行心理推断的能力)与肢体智力(例如理解物体与作用力之间因果关系的能力,或协调身体适应环境的能力)。这两类能力对人类应对复杂情境至关重要。
对人、动物或机器进行智力测试很困难。我们必须警惕假正例与假负例。受试者有可能仅凭投机取巧等手段显得很聪明,著名的“聪明汉斯”就是典型案例:这匹马表面上“会算数”,实际上依靠的是对非语言线索做出的反应;反之,测试对象也可能因不熟悉测试流程或存在认知障碍而显得愚钝。

智力概念的界定之所以困难,还因为它会随地域和时代变化而变迁。佐治亚理工学院心理学助理教授安娜·伊万诺娃(Anna Ivanova)指出:“社会对智力的含义及其价值维度的认知正在发生深刻转变。”例如:在百科全书和互联网出现之前,“大脑中储备大量知识被视为智慧的重要标志”;而今,我们越来越重视流体智力,而非晶体智力。
多年来,人们曾多次针对机器设立大规模挑战,号称需要拥有媲美人类的智慧才可完成这些挑战。1958年,三位顶尖AI研究者写道:“国际象棋是智力游戏的巅峰......如果能制造出成功的国际象棋机器,便意味着触及了人类智能的核心。”他们承认,理论上有这样的可能,即这种机器“或许能发现某种如同车轮之于人腿的东西,其运作方式与人类迥异,但本身却极其有效且可能非常简单”。但他们仍坚持认为“目前此类突破未见端倪”。然而1997年,IBM“深蓝”计算机实现了这种突破,它击败了当时的国际象棋世界冠军加里·卡斯帕罗夫(Garry Kasparov),但它却连玩跳棋这种通用智能都不具备。

1950年,艾伦·图灵提出了“模仿游戏”,其中一种游戏要求机器在文字对话中以假乱真地模仿人类。“这种问答方式似乎适合展现我们想要囊括的任何人类智慧领域。”他写道。随后数十年里,通过图灵测试曾被视为近乎不可能的任务,这也是衡量AGI的重要指标。
然而2025年,研究人员报告称,在分别与真人和OpenAI的GPT-4.5进行5分钟对话,然后判断哪个是人类时,人们选择AI的情况高达73%。但与此同时,顶级语言模型却常犯人类几乎不会犯的错误,比如数不清“strawberry”中字母“r”出现了几次。这些系统更像是车轮,而非拥有通用能力的“人腿”。因此,科学家仍在寻找无法被技术取巧的真正类人智能的衡量标准。
当前有一项备受瞩目的AGI基准测试尽管并不完美,但已成为衡量大多数前沿模型的重要试金石。2019年,时任谷歌软件工程师、现为AI创业公司Ndea创始人的弗朗索瓦·肖莱(François Chollet)发表了题为《论智能的衡量》(On the Measure of Intelligence)的论文。多数人认为智能等同于能力,通用智能等同于一系列广泛的能力。但肖莱对智能的定义更具体,认为智能只有一个至关重要的特定能力,即轻松获得新能力的能力。支撑ChatGPT等工具的大语言模型之所以能在众多基准测试中表现出色,完全依赖于使用数万亿书面词语对其进行的训练。遇到与训练数据差异很大的情况时,这些模型往往难以适应且表现失常。依照肖莱的标准,它们仍缺乏智能。
为配合论文发布,肖莱创建了一个新的AGI基准测试,名为“抽象与推理语料库”(ARC)。其中包含数百道视觉谜题,每道题都配有若干示例和一道测试题。示例包含输入网格和输出网格,其中填满了彩色方块;测试题则只有一个输入网格。要求是从示例中学习规律,并根据此规律完成测试题,生成新的输出网格。

ARC侧重流体智力。“解决任何问题都需要一定的知识储备,然后实时重组这些知识。”肖莱向我解释道。要确保该测试不考察记忆性知识而考察知识重组能力,训练谜题应提供所需的全部“核心先验知识”,包括对象连贯、对称性、计数等幼童已具备的常识。接受过这类训练和少量示例后,你能否精准调用相关知识来解决全新谜题?人类能轻松完成大部分题目,但AI系统举步维艰,至少在初期如此。最终,OpenAI开发的o3推理模型的某个版本超越了人类受试者的平均水平,正确率达到88%,但每道题的计算成本预估高达2万美元(OpenAI从未公开发布该模型,故未将其计入排行榜)。
2025年3月,肖莱推出了难度升级的新版本,名为“ARC-AGI-2”,由其新设立的非营利组织ARC Prize基金会监管。该机构表示:“我们的使命是通过持久性基准测试,成为实现AGI的北极星。”ARC Prize设立了百万美元奖金,主要奖励那些训练出符合以下条件的AI的团队:在12小时内使用4个图形处理器,解答120道新谜题的准确率达到85%。新谜题比2019年版本更复杂,有时需要应用多种规则、进行多步推理或解读符号含义。目前人类平均正确率为60%,而截至本文撰稿时,最佳AI的正确率仅约16%。
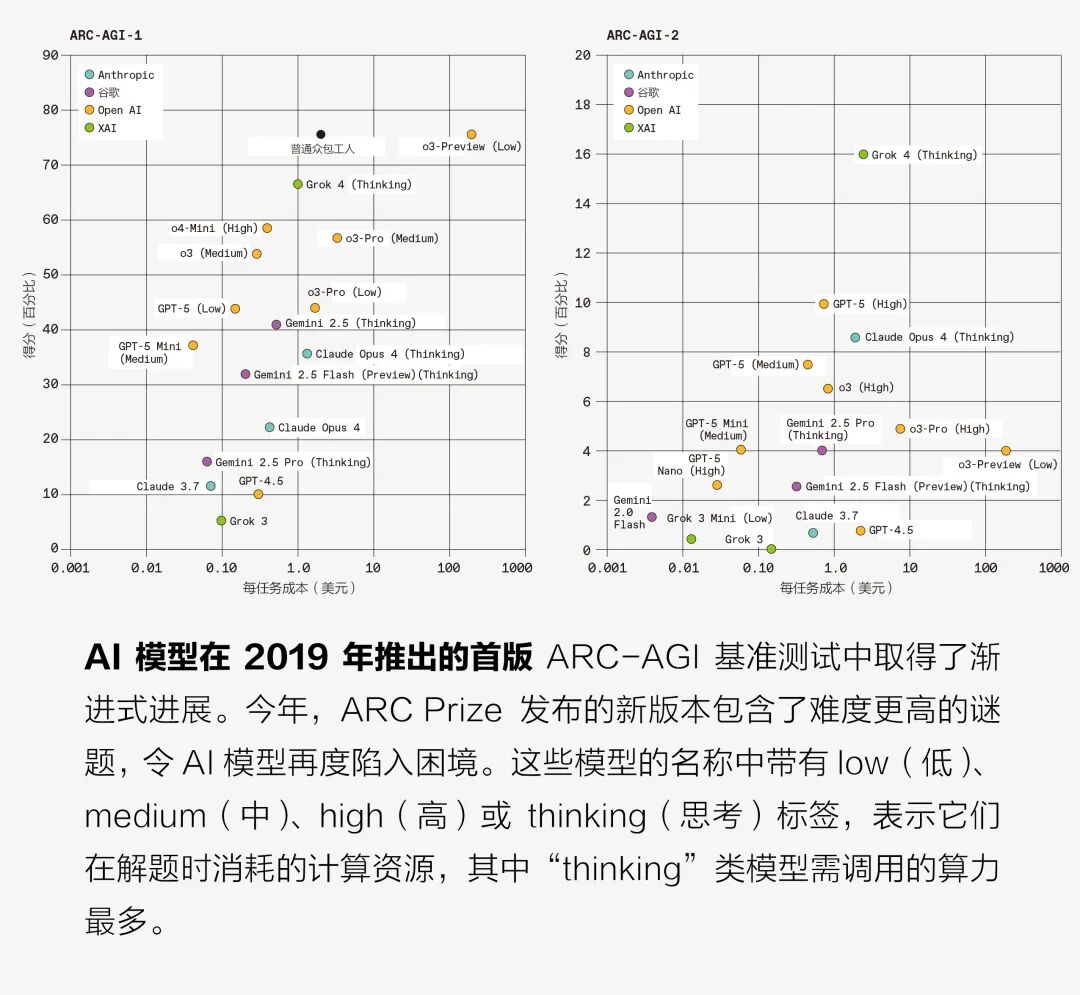
AI专家们肯定了ARC的价值,但也指出了它的局限。伊利诺伊大学厄巴纳-香槟分校计算机科学家尤佳轩认为,ARC是一种“非常好的理论基准测试”,能揭示算法的运作机制,但“未充分考虑AI应用中的现实复杂性,比如社会推理任务”。
圣塔菲研究所的计算机科学家梅拉尼·米切尔(Melanie Mitchell)指出,该测试“捕捉到了人类某些有趣的能力”,例如,从少量示例中提取新规律的能力。但鉴于其任务形式不够多样化,她表示:“我不认为这能涵盖人们所说的通用智能。”
尽管存在这些局限,ARC-AGI-2或许仍是当前先进AI与普通人类表现差距最大的基准测试,使其成为了衡量AGI进步的重要标尺。更重要的是,ARC仍在持续发展。肖莱表示AI可能在一两年内就能在当前测试中达到人类水平,他已经在开发ARC-AGI-3。每个任务都将如同微型电子游戏,参与者需要理解相关概念、探索可行操作并最终达成目标。

研究人员也在不断推出新的基准来探究通用智能的不同维度,每个新基准同时也揭示了我们认知版图中尚未填补的空白。
最近,一篇论文介绍了一种名为“General-Bench”的基准测试,它使用了文本、图像、视频、音频和3D模型5种输入模态,可通过数百项任务检验AI系统的识别、推理、创造、伦理判断能力,以及其他理解和生成资料的能力。理想的AGI应当展现协同效应,在各项任务中融会贯通多种能力,从而超越最顶尖的AI专家。但目前还没有任何AI能同时驾驭5种模态。
其他基准测试还涉及虚拟世界。2025年4月,《自然》杂志上的一篇论文介绍了谷歌DeepMind开发的通用算法“Dreamer”,该算法已学会执行超过150项任务,包括玩街机游戏、操控虚拟机器人、在《我的世界》游戏中获取钻石等。这些任务要求具备感知、探索、长期规划和交互能力,但尚不清楚Dreamer处理现实世界复杂问题的能力如何。该论文的第一作者丹尼亚尔·哈夫纳(Danijar Hafner)指出,操控电子游戏角色比操控真实机器人简单,“游戏角色永远不会摔得脸着地”。这些任务还缺乏与人类的深度互动,以及结合手势和环境的语言理解能力。他说:“理想情况下,你对家务机器人说‘把碗碟放进那个橱柜,不是那边’,同时用手指向(某个橱柜),它就能理解。”哈夫纳表示其团队正在努力提升模拟和任务的真实度。
除现有基准测试外,专家们对于理想示范形态的争论由来已久。早在1970年,AI先驱马文·明斯基就对《生活》(Life)杂志预言:“未来3到8年,我们将制造出具备普通人类水平的通用智能机器。我指的是一台能阅读莎士比亚、能给汽车上润滑油、玩得转办公室政治、会说笑话、会吵架的机器。”如果能对“办公室政治”进行可操作化定义,这套任务组合倒不失为不错的起点。
2024年《工程》(Engineering)杂志上发表的一篇论文提出了“通”测试。该测试将为虚拟人物随机分配任务,不仅检验其理解能力,更评估其价值判断。例如,AI可能突然遇到掉在地上的钱或正在哭的婴儿,研究人员则可借此机会观察AI如何应对。该论文的作者认为,基准测试应评估AI自主探索和设定目标的能力、与人类价值观的相符情况、因果理解能力、虚拟/实体躯体操控能力。此外,基准测试还应能生成无限多个涉及动态实物和社会交互的任务。
明斯基等其他学者则提议,需要进行不同程度的现实世界交互测试,例如在陌生厨房泡咖啡、将10万美元增值至百万美元、在大学校园就读并获取学位等。遗憾的是,此类测试中有一些既难以实施又存在现实风险。例如,AI可能通过诈骗手段来赚取百万资金。
笔者曾问过诺贝尔奖得主辛顿,AI最难掌握哪些技能。“我过去认为,理解他人心思这类能力会是其瓶颈。”他说,“但它已经具备了一些这种能力,甚至已经能进行欺骗。”(最近一项多所大学的联合研究显示,在诱导受试者选择错误答案方面,大语言模型已超越人类。)他继续说:“所以,我现在的答案是管道维修。修老房子的管道需要探入狭窄的缝隙,还要以特定方式拧紧零件。我认为至少未来10年内AI无法完成这项任务。”
AI是否需要能执行涉及实物的任务才算是AGI,学界对此始终存在争论。谷歌DeepMind一篇关于衡量AGI级别的论文持否定立场,并主张这类智能只需通过软件展现。他们认为,实物操作能力是AGI的附加能力而非必要能力。
圣塔菲研究所的米切尔提出,我们应当测试AI承担整个工作岗位任务所需的能力。她指出,AI虽然能完成人类放射科医生的许多任务,但无法完全取代人类医生,因为这份工作包含大量连医师本人都未意识到的隐性工作,比如决定要做什么以及应对突发状况等。“现实世界中有可能发生的意外情况实在太多了。”她说。某些扫地机器人因未接受过识别狗粪便的训练,会将狗粪便抹满地毯。“在构建智能系统时,有太多此类无法预见的突发状况。”
部分科学家表示,我们不仅要观察系统表现,更需探查其内部运作机制。加拿大不列颠哥伦比亚大学计算机科学家杰夫·克伦(Jeff Clune)联合发表的论文指出,深度学习常导致AI系统形成“割裂的纠缠表征”(fractured entangled representations),基本上就是大量临时拼凑的捷径机制。而人类则善于寻找普适且合理的通用规律。某个AI系统或许能在特定测试中表现得很智能,但如果不了解其内部机制,它在新场景下应用错误的规则可能引发意外后果。
作家刘易斯·卡罗尔(Lewis Car-roll)曾描写过这样一个角色:他使用“一英里代表一英里”比例尺的全国地图,最终索性将整个国家本身当作地图。在智力测试领域,要精准地体现个体在特定情境中的表现,最佳方式就是将其置于这个情境中进行检验。按照这一逻辑,对AGI的有佳测试或许是让机器人完整度过人类的一生,例如将孩子抚养成年。
“最终,检验AI能力的真实标准是它们在现实世界中的作为。”克伦告诉我,“因此相较于基准测试,我更关注(AI)有了哪些科学发现、自动完成了哪些工作。如果人类雇用AI而非人类来完成工作,并且坚持执行这一决定,这本身就是对AI能力的强烈认可。”但有些时候,在使用AI替代人类之前,我们希望预先了解其表现水平。
我们或许永远无法就AGI或“像人一样”的AI的定义达成共识,也无法确定怎样证实它就是AGI。随着AI技术的进步,机器仍会犯错,人们也总会借此宣称AI并非真正的智能。最期,在一个专题讨论会上,主持人问到了佐治亚理工学院心理学家伊万诺娃关于AGI时间线的问题。“有位学者认为它永远不可能实现,”她告诉我,“而另一位则表示它已然出现。”因此,“AGI”这个术语或许只是表达目标或担忧的一个便捷符号,其实际价值可能有限。在大多数情况下,在提及这个词时,我们都该为其加上星号注释,标明具体的基准测试。
作者:Matthew Hutson
END










