
代码仓库:https://github.com/SandAI-org/MagiAttention
使用文档:https://sandai-org.github.io/MagiAttention/docs
技术博客:https://sandai-org.github.io/MagiAttention/docs/main/blog/magi_attn
Blackwell 新架构适配:释放下一代算力红利
为了在下一代硬件上延续 Flex-Flash-Attention (FFA) 的灵活性,研发团队引入了基于 Flash-Attention 4 的 FFA_FA4 后端,完成了对 Blackwell 架构的初步适配:
灵活掩码支持:引入 HSTU Function 表达,在无需大幅改动 FA4 内核主体逻辑的前提下,实现了对任意掩码的无缝兼容,且性能损耗 < 5%。
高效分块稀疏生成:开发了高效分块掩码生成算子,大大降低了 FlexAttention 实例化完整掩码的性能开销和显存风险。
R2P 指令级加速:我们利用 Register-to-Predicate 技巧,将复杂的边界检查映射为单条硬件指令,大幅降低了指令周期。
极致显存和延迟:针对超长序列,对掩码元数据进行 CSR 压缩,对内核启动进行 FFI 加速,确保显存与延迟的双重极致。
原生 Group Collective 原语:突破 RDMA 带宽瓶颈
跨机通信效率决定了分布式扩展上限,受 DeepEP 启发,Sand.ai 构建了原生 Group Collective 通信内核,彻底重塑了分布式 Attention 在节点内外的数据交换范式:
算子级融合:研发团队将数据重排直接融合进通信算子,显著降低了访存和额外拷贝开销。
RDMA 传输去重:以 "NVLink 替代冗余 RDMA" 传输,实现节点间单次物理交换与节点内高效转发和规约,跨机通信量降低数倍,性能远超传统 AlltoAll-v 方案。
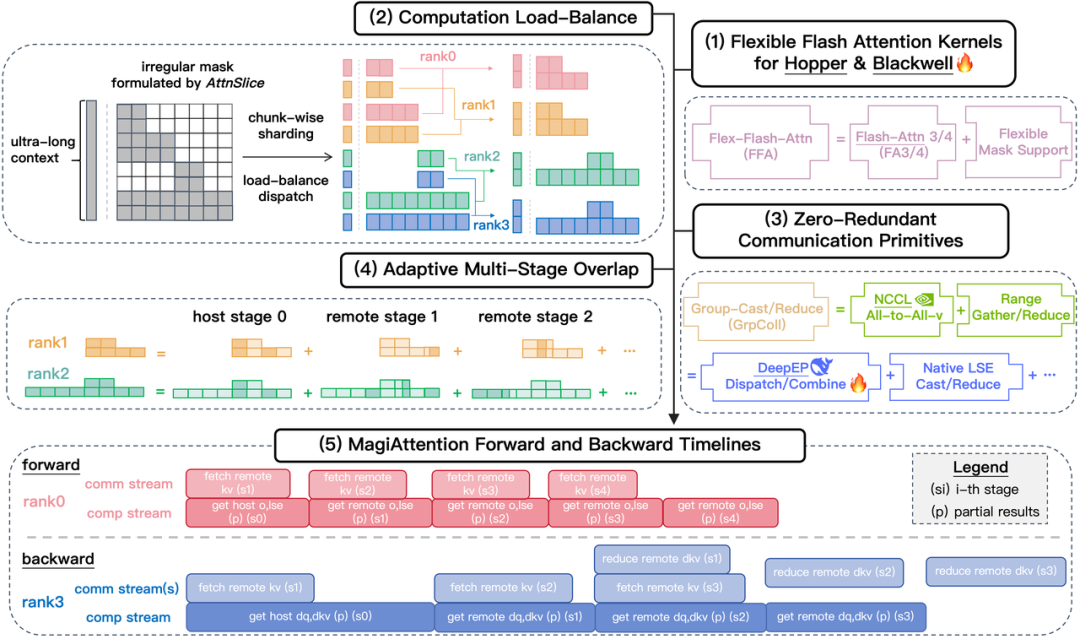
系统级协同优化:负载均衡与多阶段重叠
MagiAttention 的卓越性能不仅源于算子端的极致打磨,更得益于系统级的全栈协同调度和全场景通用的启发式算法:
Dispatch Solver: 基于最小堆贪心算法,实现序列的细粒度分配,保证任意掩码下设备的计算负载均衡,避免 “短板效应” 拖垮分布式整体性能。
Adaptive Multi-Stage Overlap: 突破静态流水线限制,自适应调整流水线阶段,通过最小化调度开销实现极致重叠,为超长序列训练提供线性扩展保障。
实测表现与应用
目前,MagiAttention v1.1.0 已在 Magi-1 等大规模视频生成模型训练中得到实证,也在各大厂中被 “悄悄” 应用于多模态大模型训练。为了验证 MagiAttention 在真实长文训练中的表现,Sand.ai 也给出了细致的 Benchmark 结果:
算子层面:支持灵活掩码并维持 SOTA 性能
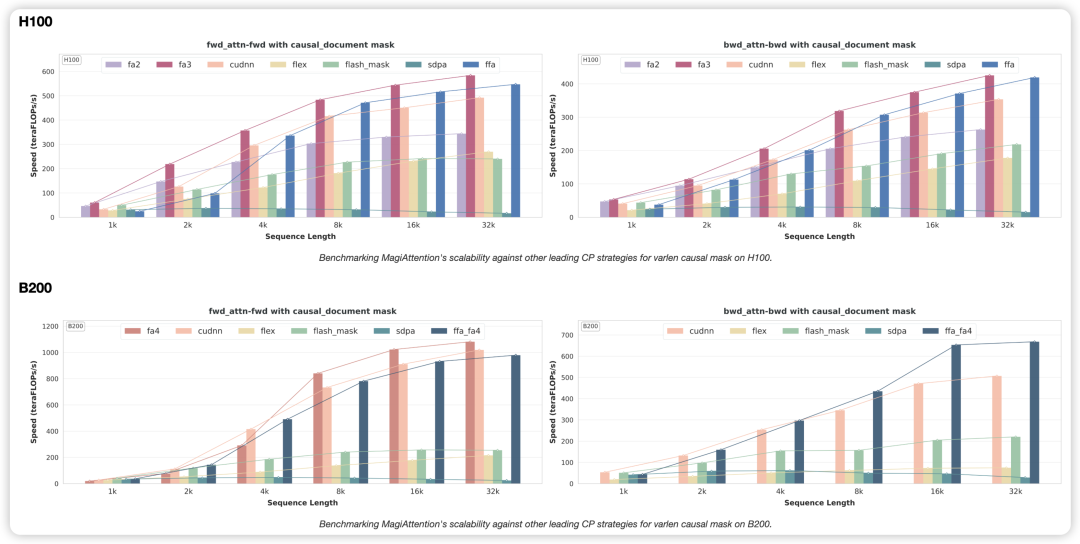
H100/B200 Varlen Causal 掩码下前反向的内核算子性能对比
分布式层面:重塑超长序列的扩展性曲线
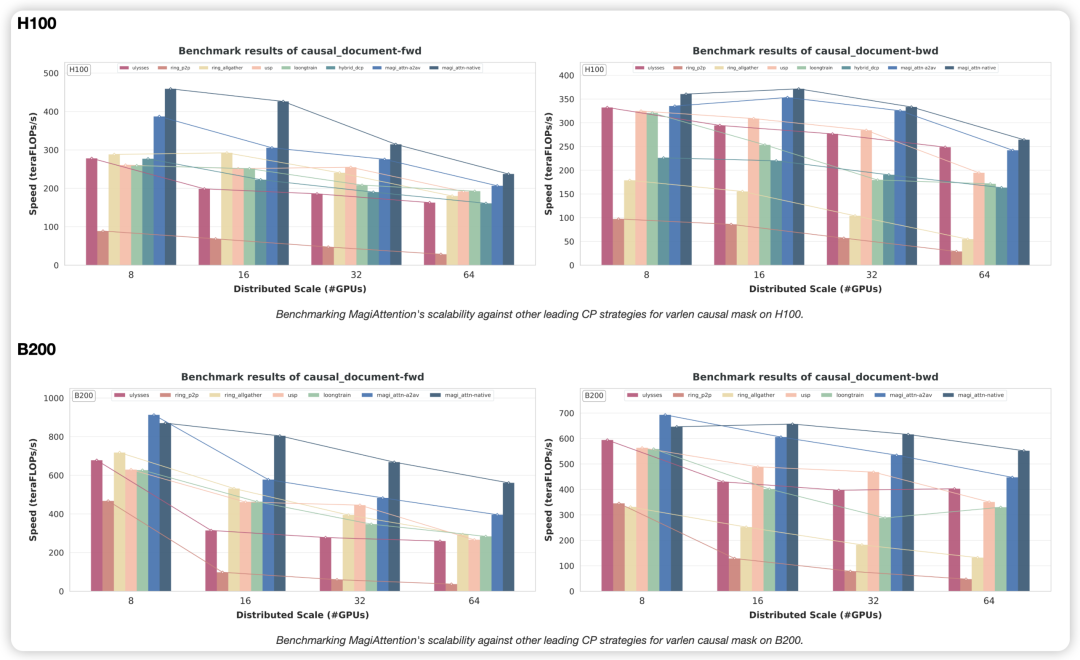
H100/B200 Varlen Causal 掩码下前反向的分布式性能对比
结语与未来展望
自去年 v1.0 发布以来,Sand.ai 收到的社区反馈让研发团队更加坚定:只有将底层算力压榨到极限,才能开启人工智能处理复杂多模态任务的新篇章。MagiAttention v1.1.0,是 Sand.ai 向这一愿景迈进的关键一步。Sand.ai 相信,强大的模型能力必须建立在普惠且极致的技术基石之上。
了解更多信息,欢迎访问 Sand.ai 官网:https://sand.ai
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










