过去几年,边缘AI一直处于"能做但不好用"的阶段,离真正规模化落地还有一定的距离。
德州仪器 (TI)最近推出两款具有边缘人工智能 (Edge AI) 功能的新型微控制器 (MCU) 系列,在2026 年国际嵌入式展上,展示技术的应用,通过边缘 AI 提升性能,以及如何在工厂、楼宇和汽车等场景的边缘端部署 AI 功能。
做MCU处理器都要找到自己的路,德州仪器把NPU塞进低成本MCU之后,是从MCU的算力升级的逻辑去思考。
在很多的应用领域里,算力需求是逐步释放的,AI不再需要依附高性能SoC,把NPU塞入MCU之后可以成为嵌入式系统本身具备的基础能力。
AI从"云端"回到"设备"
AI发展的主线是算力不断往中心集中。训练也好,推理也罢,大多数AI能力都跑在云上。
这套模式在互联网产品里很高效,但到了物理设备领域,一直有明显的不适配——延迟没保证、功耗下不来、数据出不了端,网络一断功能直接归零。
所以这两年行业逐渐形成一个判断:AI需要往边缘迁,计算要靠近数据。
但问题是,边缘设备本身没准备好。
典型的嵌入式系统尤其是MCU,资源极度有限:几十MHz主频、KB级内存,对功耗敏感到了极点。这类芯片可以做好控制和信号处理,但要跑神经网络推理,勉为其难。
所谓的"边缘AI"过去更多依赖高性能SoC,不是MCU。但SoC一上,成本、功耗、复杂度又回到原点,根本沉不下去。边缘AI的核心矛盾从来不是"有没有模型",而是:有没有一种足够轻量、足够便宜、还能跑AI的计算架构。
把NPU塞进MCU:一条更务实的路
德州仪器这次的方案,说起来并不复杂,但很工程化:既然MCU直接跑AI有难度,就不让它硬跑,给它一个专门负责AI的单元。这就是TinyEngine™ NPU。
架构上,这是一种很清晰的分工:MCU内核继续管控制、通信和系统任务,神经网络推理交给独立的NPU,两者并行运行。
最大的好处是,AI计算不会干扰实时控制——用CPU直接跑神经网络,一旦负载上来,控制环路的确定性就会受影响;NPU独立之后,AI是一条独立的计算路径,控制系统可以保持稳定。

真正让这套架构成立的,是围绕NPU的一整套优化。
◎ 首先是精度下沉,支持从8位到2位的低精度计算和混合精度模式,模型体积和计算复杂度大幅下降。
◎ 其次是存储和数据路径的优化,通过量化和就地计算,减少数据在芯片上来回搬运,降低带宽压力。
◎ 再加上对卷积、全连接等主流网络结构的硬件支持,神经网络推理可以在极小资源下运行。
最终的效果是:推理能耗下降超过百倍,延迟下降接近两个数量级。这意味着AI可以持续运行在MCU上,而不是偶尔跑一次。
更关键的是,TI把这套能力放进了基于Cortex-M0+的MCU里,千件起订单价可以做到1美元以内。
这不是单纯的性能突破,而是成本曲线的变化,当AI进入这个价格区间,它就不再是"高端功能",而是有机会成为默认配置。
算力和功耗问题解决之后,变化最先发生在最基础的交互和感知场景里。
语音唤醒是个很典型的例子。过去的语音系统,要么靠云端识别,要么用功耗较高的处理器持续监听,"功耗"和"响应"始终存在矛盾。
在MCU+NPU架构下,语音处理链路被压缩到本地:麦克风采集信号,经过模拟前端和ADC转为数字数据,由MCU接收,再由NPU运行轻量化卷积神经网络做关键词检测。
这个过程可以持续运行,功耗只有毫瓦级,只有检测到有效唤醒词时,系统才激活主处理单元。

这种变化带来的不只是体验优化,而是能力的外溢,语音不再局限于智能音箱,可以进入家电、可穿戴等各种低成本设备,具备基础语音交互能力。
可穿戴设备里的变化类似。
◎ 传统架构下,传感器数据往往需要上传云端或由主处理器集中处理;
◎ 现在,AI模型可以直接嵌入数据路径:加速度计、陀螺仪采集的运动信息,进入系统后立即由NPU分析,用于手势识别、睡眠监测甚至更复杂的生理信号判断。在这个过程中,AI不再是"功能模块",而是传感器系统的一部分。
这也是边缘AI真正有意义的地方:它不是增加一个功能,而是改变了数据被理解的方式。
AI进入控制系统,能不能用起来
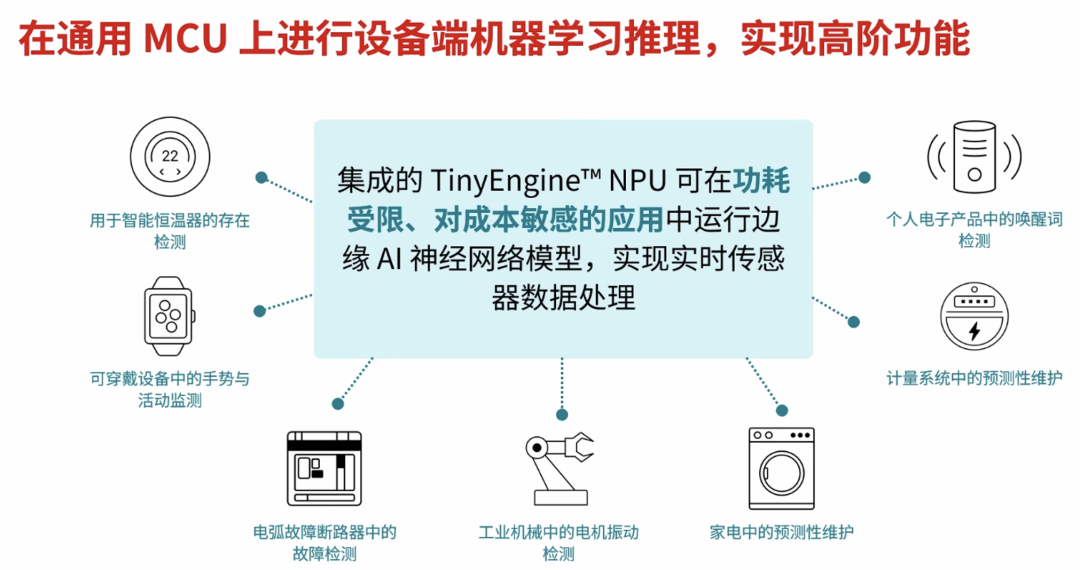
如果说消费电子体现的是边缘AI的可行性,工业和控制系统才是它价值真正释放的地方。
TI在另一类MCU上做的事情,是把"实时控制"和"AI推理"放在同一颗芯片上。CPU继续负责电机控制、采样和闭环算法,NPU并行运行神经网络,对系统状态进行判断。两者在硬件层面隔离,控制任务的确定性不会被AI干扰。
控制系统第一次具备了"自适应能力"。光伏系统里,电弧检测准确率可以从传统方法的85%提升到超过99%;电机系统里,可以通过AI模型识别轴承异常,实现预测性维护;家电里,可以根据负载状态动态调整控制策略。
这些能力在传统控制理论里并不是做不到,但实现成本极高,AI提供了一条更直接的路径。
从工程角度看,控制系统不再只是执行既定算法,开始具备对复杂状态的理解能力。
硬件能力解决之后,真正的瓶颈往往转移到开发侧。
边缘AI之所以长期难以落地,很大一部分原因在于开发流程过于复杂:数据采集、模型训练、量化压缩、嵌入式部署,每一步都需要不同背景的工程师参与。TI这次发布的另一个重点,其实是工具链。
通过统一的开发环境和Edge AI Studio,工程师可以在PyTorch、TensorFlow等主流框架里完成模型训练,再通过工具完成量化和部署,直接运行在MCU上。平台还提供参考模型和应用方案,降低从零开始的门槛。
生成式AI的引入更值得关注。通过自然语言生成代码,嵌入式开发的流程正在发生变化——从"手写代码"转向"描述需求"。这看起来是工具层面的改进,本质上是在重构开发门槛:让更多非AI背景的工程师也能参与到边缘AI系统的构建中。
当越来越多的计算将分布在系统的各个角落。云端仍然重要,但它更多承担训练和全局优化的角色;在终端侧,每一个传感器、每一个执行器,都开始具备本地决策能力。
MCU如果不升级是没出路的,而是最基础的AI节点。当这种能力进入1美元级别的器件时,有可能成为整个嵌入式系统的默认配置,AI开始无处不在。