MOCR团队 投稿
量子位 | 公众号 QbitAI
一个3B参数的小模型,在文档解析上打败了一众开源大模型,在图形重建上甚至反超了Gemini 3 Pro——而且不只是某一项指标,是在六个图形重建基准上全面超越。
这就是华中科技大学与小红书hi lab联合推出的MOCR(Multimodal OCR)。

它提出了一个大胆的新范式:不只识别文字,而是「解析一切」——文字、表格、图表、公式、流程图、化学结构式、UI组件……通通变成可编辑、可渲染的结构化代码。用论文的话说,这是把文档图形从「二等公民」升级为「一等解析目标」。
更关键的是,这不只是一个技术上的改进,而是一次范式级别的重新定义:文档解析的终点不应该是「把字认出来」,而应该是「把页面上的一切信息都变成机器可理解、可复用的结构化表示」

△ MOCR整体流程:给定文档图片,将页面上所有元素统一解析为结构化输出,忠实重建原始文档
传统OCR的致命短板:图表全丢了
我们日常打交道的PDF、论文、报告里,信息远不止文字。一张精心绘制的柱状图,可能浓缩了整份报告的核心结论;一个化学分子结构式,承载着关键的实验信息;一张流程图,描述了整个系统的运行逻辑。
但传统OCR怎么处理?框出来,裁成图片,丢掉。
这意味着文档里大量的结构化语义信息在解析环节就被永久性地丢弃了。论文中用一张对比图把这个问题说得很清楚:

△ 传统OCR vs MOCR:传统方案把图形当像素丢弃,MOCR将其解析为SVG等结构化代码
左边是传统路线:文本走OCR管线变成Markdown,图形直接裁成像素图——要么丢弃,要么只能做图像描述(caption)和视觉问答(VQA)这类粗粒度应用。右边是MOCR的路线:图形被解析为SVG代码,和文本一起形成图像-代码配对数据,可以直接用于文生图、细粒度感知、可控图像生成、统一的生成与理解等更广泛的下游任务。
MOCR的核心洞察很简单:文档中最有价值的监督信号,往往是视觉的而非文字的。把这些「丢弃的金矿」捡回来,就是MOCR要做的事。这不仅仅是对OCR的改进,而是对整个文档数据引擎的重新定义。
怎么做到的?一个3B模型的「全能之路」
说起来容易,做起来难。让一个模型同时处理文字识别和图形到代码的重建,面临的挑战远比单纯的OCR要复杂得多。论文中总结了三大核心难题:
第一,图形的监督信号极度稀缺。现实文档中很少会同时提供一张图表和对应的程序化表示(比如SVG源码)。换句话说,你能找到海量的文本-标注对,但图形-代码对就少得多。
第二,可渲染的程序表示天然不唯一。同一张图表,可以用完全不同的SVG代码来实现——结构不同、参数不同,但渲染出来视觉效果一模一样。这意味着训练目标本身就是多对一的,模型很难收敛。
第三,任务要求极高的视觉定位精度和超长序列生成能力。要把一张复杂的图表忠实地转化为SVG代码,模型需要同时做到精确的视觉grounding(每个图形元素的位置、大小、颜色都不能错)和长达数千token的结构化文本生成,这比纯文本OCR难得多。
模型架构:从零训练的视觉编码器+紧凑解码器
整体架构遵循经典的视觉-语言模型范式:高分辨率视觉编码器+轻量级多模态连接器+自回归语言模型解码器。但每个组件都针对文档场景做了深度优化。
1.2B参数视觉编码器——完全从零训练。
这是一个重要的设计选择。大多数视觉-语言模型会直接复用CLIP或SigLIP等预训练视觉编码器,但这些编码器是为自然图像设计的,对文档场景中的精细文字和几何图元(图表标记、图形笔触等)感知能力不足。从零训练意味着特征表示天然适配文档解析需求。这个编码器支持约1100万像素的原生高分辨率输入,不做降采样——对于小字号文字的辨识和图表细节的精确定位至关重要。
1.5B Qwen2.5语言解码器。
选择从base模型(而非chat版本)初始化,是因为MOCR的输出目标包含大量非自然语言的强结构化序列(如SVG代码),chat模型的对话先验反而会干扰学习。1.5B这个规模是精心权衡的结果:更小的模型难以同时处理文本、布局和图形的异构输出,更大的模型又会显著增加训练和推理成本。
三阶段渐进式预训练:先学看图,再学认字,最后学画图
训练策略是纯数据驱动的,不引入任何任务特定的优化技巧,而是通过精心设计的课程逐步降低学习难度、稳定多任务联合训练:
阶段一:建立视觉-语言接口。通用视觉训练,让语言模型学会可靠地消费视觉token,建立视觉输入到文本生成的基本映射。
阶段二:广泛预训练。混合通用视觉数据与纯文本文档解析监督,在保持视觉鲁棒性的同时打下文本OCR的坚实基础。
阶段三:MOCR专项强化。降低通用视觉数据比例,加大多模态文档解析权重,重点强化图形转SVG的能力。同时逐步提升输入分辨率,匹配密集页面解析和长序列结构化生成的需求。
全程保持单一的自回归训练目标,通过混合比例的调整和课程调度来控制优化稳定性。预训练之后还有高质量的指令微调(SFT),这一阶段特别关注监督信号的可靠性和任务输出的规范性——对于SVG解析来说,这意味着viewBox标准化、代码简化、格式规范化等一系列处理。
团队最终发布了两个版本:dots.mocr(均衡能力)和dots.mocr-svg(在SFT阶段增大SVG数据比例并加权困难样本的增强版)。
数据引擎:四大来源,解决「没有数据」的难题
训练一个MOCR模型对数据的要求异常苛刻:不仅要覆盖多语言、多样布局、长距离阅读顺序,还要让模型学会把图形解析为结构化代码——而目前没有任何现成数据集能提供这样的覆盖度。团队从四个互补渠道构建了训练语料:
PDF文档:用dots.ocr作为自动标注引擎,从原始PDF中生成带布局区域和阅读顺序的结构化页面转录。通过语言、领域和布局复杂度(文本密度、表格/公式出现频率等)的分层采样来强调困难样本。SFT阶段还引入了基于规则的一致性检查和基于渲染的比对验证。
网页渲染:将爬取的网页渲染为页面图像,转换为与PDF统一的解析格式。这个来源提供了天然高分辨率和复杂布局的数据,而且由于HTML/DOM的存在,标签噪声更低。更重要的是,网页中大量的图标、图表和UI组件天然以SVG格式存储,直接为图形解析提供了训练信号。
原生SVG资产:从多种来源收集天然的SVG文件,渲染后构建图像-SVG配对。整个管线包括两个阶段:清洗阶段用svgo去除无关元数据、标准化数值精度、统一代码结构,然后在代码和图像层面去重(文本匹配+感知哈希pHash);采样阶段做领域级均衡和基于SVG复杂度的采样,避免简单图形过度代表。
通用视觉数据:包括grounding、counting等通用视觉和OCR监督,确保模型在专注文档解析的同时不丧失广泛的视觉理解能力。
评估也要革新:OCR Arena——让大模型当裁判
值得一提的是,团队不仅在模型层面做了创新,在评估方法上也提出了新思路。
传统的OCR评估指标(如WER、NED、TEDS等)依赖规则化的字符串匹配,但对于复杂的Markdown输出来说,这类指标往往过于脆弱——语义完全等价但格式略有不同的输出可能被判为错误。这就像用字面匹配来判断两段代码是否功能一致,显然不够可靠。
为此,团队引入了OCR Arena框架:用Gemini 3 Flash这样的强VLM作为裁判,对两个模型的输出进行两两对比打分。为了消除位置偏好(LLM倾向于选择先出现的选项),每次对比都做正反两轮——只有两轮判断一致才计为有效胜负,否则算平局。最终用Elo评分系统汇总出可靠的排名,并通过1000次bootstrap重采样来增强统计稳健性。
这套评估体系比传统指标更能反映真实的端到端解析质量,对于输出越来越复杂、结构化程度越来越高的新一代OCR系统尤为重要。
效果有多猛?两个维度,全面碾压

△ 整体性能对比:(a)图形解析(b)文档解析(olmOCR-Bench、OmniDocBench 1.5、XDocParse)
维度一:文档解析,开源第一,仅次于Gemini 3 Pro
在OCR Arena的Elo评估中,dots.mocr在olmOCR-Bench、OmniDocBench 1.5和XDocParse三个主流基准上均拿到了开源模型第一名,平均Elo达到1125,仅次于闭源的Gemini 3 Pro(1211)。需要强调的是,dots.mocr只有3B参数,而它打败的对手中不乏同等甚至更大规模的专用OCR模型。

在olmOCR-Bench的细分评测中,dots.mocr同样取得了83.9的最高总分,刷新了该基准的SOTA——超过Infinity-Parser 7B(82.5)和olmOCR v0.4.0(82.4)。在ArXiv论文解析(85.9)、扫描数学文档(90.7)、表格识别(48.2)等子类别上均拿到最优成绩。
在OmniDocBench v1.5上,dots.mocr在文本转录和阅读顺序两项核心指标上也达到了所有模型中的最低编辑距离(TextEdit 0.031、ReadOrderEdit 0.029),说明不仅认字准,阅读顺序也排得对。
维度二:图形解析——3B模型全面反超Gemini 3 Pro
如果说文档解析是MOCR的「基本功」,那图形到SVG的重建就是它真正让人惊艳的地方。这也是MOCR范式与传统OCR最本质的区别所在。
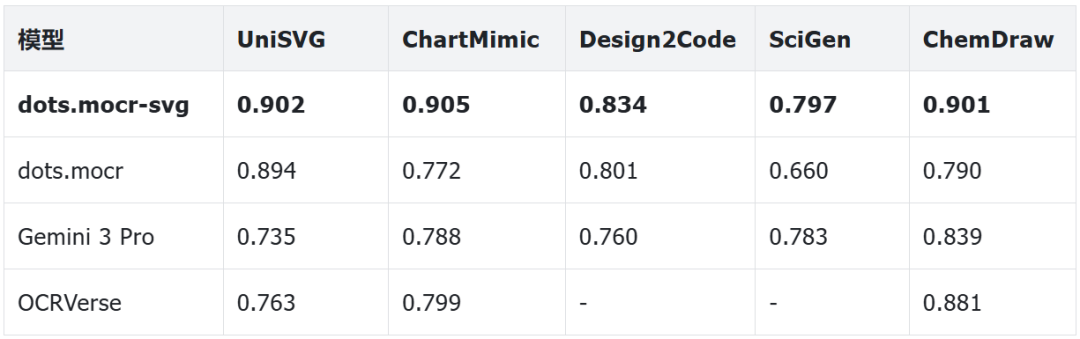
评估覆盖了六个不同领域的基准:通用矢量图形(UniSVG)、科学图表(ChartMimic)、网页和UI布局(Design2Code)、考试题目图形(GenExam)、科学插图(SciGen)、化学结构图(ChemDraw)。评估方式很直接:把模型输出的SVG代码渲染出来,跟原图做视觉相似度对比。
dots.mocr-svg在UniSVG整体基准上取得0.902分,大幅领先Gemini 3 Pro的0.735(+0.167)和OCRVerse的0.763(+0.139)。在全部六个下游基准上也全面超越了Gemini 3 Pro:
一个3B参数的紧凑模型,在自己最擅长的方向上比顶级闭源模型还强——这不仅验证了MOCR范式的可行性,也说明专注的架构设计和数据工程可以弥补参数规模上的差距。

△ dots.mocr-svg对各类统计图表的SVG重建效果,柱状图、折线图、散点图均可忠实还原为可编辑向量图形

△ 跨学科复杂插图的SVG重建:化学分子结构、物理示意图、数学图形、信息设计等
维度三:通用视觉问答——专项能力不影响通用水平
一个常见的担忧是:如此专注于文档解析和SVG重建,会不会牺牲通用的视觉理解能力?实验结果给出了否定的答案。
在CharXiv图表理解基准上,dots.mocr在描述性(77.4)和推理性(55.3)任务上均超过了同规模的Qwen3-VL-4B-Instruct(76.2 / 39.7),展现出更强的细粒度文本理解和多模态推理能力。在文档VQA(DocVQA 91.85)、信息图VQA(InfoVQA 73.76)、图表QA(ChartQA 83.2)、OCRBench(86.0)等下游任务上也保持了稳健表现。在需要视觉定位能力的RefCOCO(80.03)和计数能力的CountBenchQA(94.46)上同样不输——说明统一的MOCR训练不仅没有削弱通用能力,反而通过多任务协同有所增益。
不只是刷榜:MOCR为什么值得关注?
如果只是看数字,dots.mocr是一个很强的文档解析模型。但MOCR这篇工作真正的贡献,在数字之外。
一、重新定义「文档里有什么」
长期以来,文档解析社区的默认假设是:文档=文字+一些需要裁掉的图片区域。这种假设深深嵌入了从数据标注到模型设计到评估指标的整条链路。MOCR的第一个贡献,是打破了这个假设:文档中的图形不是噪声,而是信息密度最高的部分之一。一张包含六列数据的柱状图,其信息量可能等于半页文字。丢掉它们,就是在系统性地丢弃文档最有价值的部分。
二、开辟多模态预训练的新数据源
这是MOCR可能产生最深远影响的方向。当前多模态大模型的预训练数据中,图像-文本对(如LAION、CC12M)和图像-描述对是主流,但这些数据的局限性越来越明显:描述粒度粗、结构化程度低、且大多来自互联网图片而非信息密集的专业文档。
MOCR打开了一条全新的路径:每一张被解析为SVG的图表,天然就是一个(图像,代码,文本)三元组。这种三元组具备几个独特优势——代码是精确的、可执行的、可验证的(渲染出来就能对比),而且是可扰动的(修改代码参数就能生成新的训练样本)。论文指出,这意味着训练数据的规模上限仅取决于可用文档的数量,而全球的PDF、网页、技术文档是近乎无穷的。
三、范式可扩展,不止于SVG
虽然当前dots.mocr以SVG作为图形的目标表示,但MOCR的范式本身是表示无关的(representation-agnostic)。论文明确指出了多个可扩展方向:TikZ用于科学图形、D3.js用于交互式可视化、CAD格式用于工程图、SMILES用于化学结构、电路描述语言用于电路图……每一个方向都对应着一个专业领域的数据金矿。此外,将完整网页(包含多样布局、嵌入式图形和多语言内容)纳入解析范围,也大幅拓展了可用训练数据的池子,突破了传统OCR仅关注PDF的局限。
四、评估方法的启示
OCR Arena框架本身也值得关注。随着OCR输出从纯文本演进到带有表格、公式、SVG代码的复杂结构化文档,传统的基于字符串匹配的评估指标越来越力不从心。用强VLM做裁判的对比评估方式,配合消除位置偏好的双轮协议和Elo评分系统,提供了一个更可靠的评估框架。这种思路很可能成为结构化输出评估的新标准。
五、数据工程的价值被再次证明
dots.mocr的成功很大程度上归功于其数据引擎的精细设计——从PDF自动标注、网页渲染对齐、SVG清洗去重到基于渲染的质量验证,每一步都在解决图形监督信号稀缺和非唯一性的核心难题。论文提出的标准化(normalization)+基于渲染的验证(render-based verification)的组合策略,为处理「同一个视觉输出对应多种合法代码」这类问题提供了通用方法论,其意义超越了OCR本身。
写在最后
用一句话总结dots.mocr:一个3B参数的「全能选手」——文档解析开源第一(仅次于Gemini 3 Pro),图形重建全面反超Gemini 3 Pro,通用VQA上对标Qwen3-VL-4B毫不逊色。
但比数字更重要的是它背后的范式转变:文档解析的终极目标不应该是「把字认出来」,而应该是理解和重建页面上一切信息载体的结构化语义——文字、表格、公式、图表、图标,一个都不能少。
当OCR从「文字识别」进化为「全要素解析」,它就不再只是一个工具,而是成为了多模态智能的核心数据引擎。从这个意义上说,MOCR可能是文档AI领域一次真正的范式起点。
代码和模型均已开源,感兴趣的读者可以直接上手体验。
论文链接:
https://arxiv.org/abs/2603.13032
代码仓库:
https://github.com/rednote-hilab/dots.mocr
研究团队:
华中科技大学×小红书hi lab