早在去年 12 月底,英伟达就以200 亿美元的价格对 Groq 开展了一次 “人才收购”,拿下了该公司大部分开发团队,并获得了其用于 AI 推理的 LPU 数据流引擎底层技术授权。外界原本预计,英伟达会迅速部署由乔纳森・罗斯打造的张量流处理器。这位前谷歌工程师在离开这家搜索巨头后,设计出了一款全调度、可编程的张量处理器。随着生成式 AI 热潮兴起,这款处理器被更名为语言处理单元(LPU),但架构并未改变。如今,英伟达正与三星合作,将第三代LP30 芯片推向市场。英伟达联合创始人兼首席执行官黄仁勋在 2026 年 GTC 大会开幕主题演讲中表示,这款芯片将在今年下半年上市,极有可能是第三季度。
英伟达一刻也没有耽误,因为它根本耗不起。Groq 原本已经开始在低延迟推理领域崭露头角,就像 Cerebras Systems 以及 SambaNova Systems 一样 —— 这两家公司主打超高带宽 SRAM,搭配相对精简的算力,在大量计算引擎上实现极速推理。在对速度要求极高的场景下,这些系统厂商以及数十家试图规模化做推理的初创公司,就像一群食人鱼扑向站在亚马逊河里的一头肥牛。所以英伟达必须火速行动……
于是就有了这笔轰动业界的 200 亿美元 Groq 人才收购。之所以没有直接全资收购,是因为那样可能需要一两年时间,还未必能通过全球反垄断机构的审查。也正因如此,Groq 的技术被立刻整合进了Vera-Rubin 平台。鉴于黄仁勋在主题演讲中提到,低延迟、高定价的 Token 生成算力,大约会占到 AI 集群总算力的 25%,这个平台其实更应该被称作Vera-Rubin - Groq 平台。
还记得英伟达在 2025 年 9 月曝光的Rubin CPX 大上下文计算引擎吗?那款基于Rubin架构变体、搭配更便宜、供应更充足的 GDDR7 显存的产品?
“我们想到了一个绝佳的思路,” 英伟达 AI 与高性能计算副总裁伊恩・巴克在 GTC 2026 会前的系统发布沟通会上表示,“将 LPU 和 LPX 整合进我们的Rubin平台,对解码环节进行优化。这是我们当前的重点,我们也很期待将它推向市场。”
换句话说,Rubin CPX 项目直接被砍掉了。
黄仁勋在台上对比了两款芯片:一边是我们推测的“Rubin” R200 GPU 加速器,另一边是 Groq 的 “Alan-3” LP30 推理加速器。前者是通用型、动态调度的计算引擎,非常擅长批量处理大量推理任务,通过 HBM 堆叠内存做流水线处理,延迟适中,能支持大量并发用户。(这就是 GPU。)后者则是以机柜为单位、算力相对精简、专为推理设计、静态调度、确定性运行的计算引擎,多芯片协同工作,通常只为少量用户服务 —— 大多数时候甚至只服务一个用户。它会把模型权重(而非数据)分布在整体 SRAM 中,机器加得越多,Token 生成的响应速度就越快。
如果把 GPU 比作脱粒机,那 LPU 就是速度狂魔。二者可以通过 Dynamo 推理软件栈协同工作,在吞吐量和延迟区间内形成一条更均衡的推理性能帕累托曲线。
以下是 R200 和 LP30 芯片的规格与性能:

更完整的对比还需要考虑整套系统的内存层级,包括主机处理器中的闪存和主存,但大致意思已经很明显。另外,如果统一按 FP8 浮点算力计算,相同精度下二者性能差距为21 倍;如果 AI 工作负载的解码部分能用上 FP4—— 这个前提条件并不容易满足 —— 那么 R200 的理论峰值性能将达到 LP30 的42 倍。
但再看看 GPU 的复杂程度,这直接和成本挂钩。R200 的物料成本里,绝大部分都会花在 HBM4 堆叠内存以及连接内存与 GPU 所需的中介层上。所以必须认清一点:这位 “速度狂魔” 不仅延迟比 “脱粒机” 低得多,在达到合理交互体验的前提下,单 Token 成本也可能更低。
当下,AI 正从人类和聊天机器人交互,转向智能体 AI 之间高速对话、自主完成任务的时代。这类场景速度更快、推理更强,Token 生成量呈指数级增长。在这种趋势下,一个关键点显而易见:像 Groq、Cerebras、SambaNova 这样的架构将会变得越来越重要。谷歌 TPU、亚马逊 Trainium 也必然会推出专门面向智能体 AI 推理的版本,在内存带宽和算力之间取得更好平衡,同时不牺牲内存容量。
后续我们会对硬件做更深入的拆解,敬请期待。目前我们先梳理黄仁勋与巴克披露的战略思路。你只需要看懂两条帕累托性能曲线:一条是传统、当前和未来连贯 GPU 内存域系统的曲线,另一条是加入 Groq 设计的 LP30 之后的曲线。按照黄仁勋对推理市场的构想,目标是用推理硬件覆盖从免费到高端的全层级服务,这个思路是合理的。
下面是Hopper NVL8、Grace-Blackwell NVL72 和Vera-Rubin NVL72 系统在吞吐量(每兆瓦每秒 Token 数)和交互性(每用户每秒 Token 数)上的对比:
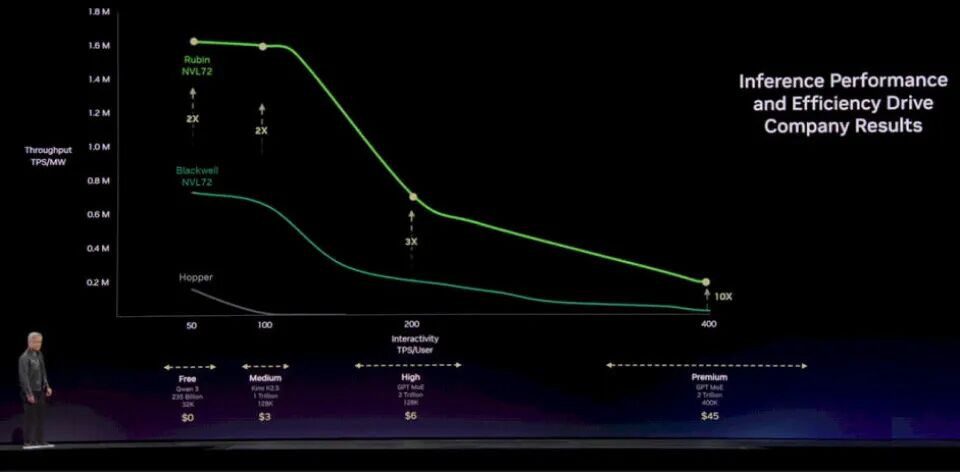
显而易见,借助 NVSwitch 实现的更大 GPU 共享内存域,让性能曲线从Hopper延伸到了布莱克威尔;但升级到Rubin GPU 后,内存、带宽和算力的提升只能让曲线向上抬升,却无法向右延展。英伟达未来会扩大这个内存域,但 2026 这一代硬件不会实现。
下面是系统中加入 Groq LP30 之后的效果:LP30 主攻中高端市场,随着部署数量增加,还能拓展到利润极高的顶级市场:
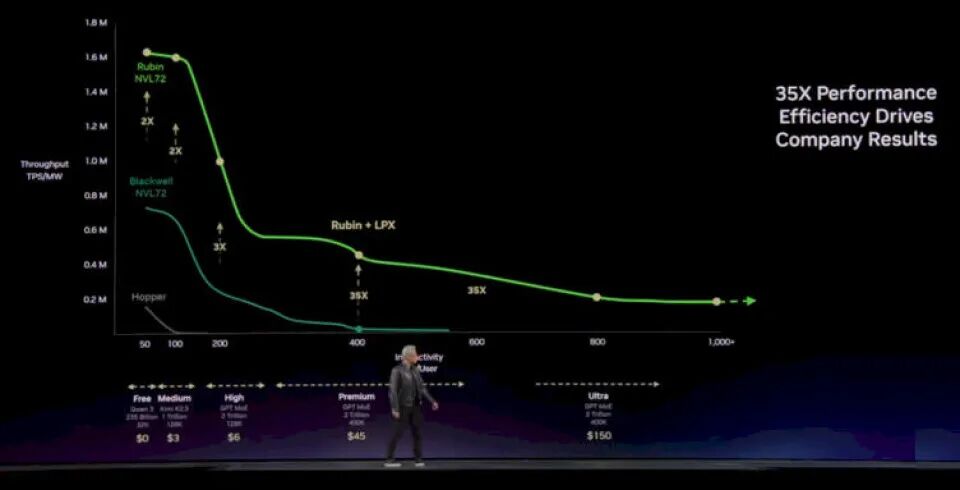
这条惊人的曲线说明了什么?我用大白话给你总结一下:
如果你只做低成本推理,对响应时间无所谓,比如人类慢悠悠地跟聊天机器人对话,或是几个智能体辅助做一些自动化工作,那Vera-Rubin完全够用。而且训练大概率也离不开它。但在智能体 AI 时代,需要生成的 Token 数量极其庞大,Token 生成延迟必须极低,才能让海量智能体完成任务 —— 任何延迟都是真金白银的损失,就像在数据中心地板上、或是在纽约证券交易所里直接烧钱。在这种场景下,没有人,我是说绝对没有人,会选择 CPU-GPU 混合系统来做解码工作。
这就是英伟达花 200 亿美元把 Groq 精华收入囊中的原因。
我目前只能透露一句:AMD 和 Cerebras 的联合创始人关系非常不一般。
Vera-Rubin架构由 88 核 “维拉” CV100 Arm 服务器处理器(搭载定制 “奥林匹斯” 核心)搭配 “Rubin” R200 GPU 加速器组成。整套方案包含七款不同芯片,可构成五种机架级系统,在Vera-Rubin AI 超算中自由组合搭配。

黄仁勋还展示了一组对比:1 吉瓦算力的 “Hopper” H100 GPU 搭配 X86 处理器,组成 HGX NVL8 系统(8 张 GPU 在纵向扩展网络中共享内存,通过 InfiniBand 横向扩展),对阵我们推测的 VR200 NVL72 机架级系统集群(GPU 实现 72 路内存共享)。
对比结果是:GPU 数量减半,AI 处理性能提升 13.3 倍。公平地说,H100 最低只支持到 FP8 精度,而 R200 支持 FP4 格式(和上一代布莱克威尔 GPU 一样)。所以 13.3 倍的提升里,有 2 倍来自精度压缩。而且 FP4 也不只是跑分噱头 —— 模型正在被持续优化,在把数据和运算精度减半的同时,让答案精度只比 FP8 低一两个点。业内已经在实际生产负载中做这种取舍。
但问题在于:即便 GPU 数量减半,可单颗价格却是原来的三四倍。英伟达通过卖出至少两倍数量的芯片,实现营收大幅增长;而你的 IT 预算并不会下降,如果 AI 负载继续扩张 —— 未来肯定会 —— 你的 IT 预算只会上涨。其他所有部署 AI 的机构也是如此。最终需求再次远超供应,推动价格进一步上涨,让英伟达的营收和利润比在供应不受限的环境下还要高。
当上“推理之王” 的滋味,确实不错。
但这一宝座本几乎属于乔纳森・罗斯—— 谷歌 TPU 的缔造者,也是设计出 Groq 这种堪称更优秀架构的人。罗斯收到了一份无法拒绝的邀约,而我认为,Cerebras 也极有可能收到类似的邀约。英特尔错过了与 SambaNova Systems 合作的机会,不过或许现在还有时间和资金促成一笔交易。
原文:
https://www.nextplatform.com/ai/2026/03/17/nvidia-finally-admits-why-it-shelled-out-20-billion-for-groq/5209495


![中国信号链模拟芯片行业产业链、市场规模、竞争格局及未来趋势分析:国产替代进程加速,高端产品技术瓶颈有望突破[图]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2026-03-23/69c09142381e9.jpeg)






