如您有工作需要分享,欢迎联系:aigc_to_future
作者:Yukang Chen等
解读:AI生成未来

论文链接:https://arxiv.org/pdf/2507.07966
Git链接:https://github.com/NVlabs/Long-RL

亮点直击
LongVILA-R1,一个面向长视频理解推理能力的综合性框架。 构建了一个高质量长视频推理数据集LongVideo-Reason,包含了带有链式思维(CoT)标注的推理样本。 整理了一个包含 1000 条长视频样本的平衡评估集 LongVideoReason-eval,从四个维度全面评估:时间推理、目标与意图推理、空间推理、情节与叙事推理。 提出了一种新的训练框架,用于提升 VLM 在长视频推理方面的能力。 LongVILA-R1-7B 在 VideoMME 上达到了 68.4% 的准确率。大幅超越了 Video-R1-7B和 GPT-4o,并与 Gemini-1.5-Pro 表现相当。

总结速览
解决的问题
长视频推理任务复杂性高:长视频包含丰富的时间动态、空间关系、目标导向行为和叙事结构,理解难度远高于短视频或图像。 缺乏高质量的长视频推理数据集:相比于数学或代码等领域,长视频推理缺乏结构化监督信号和大规模、高质量的标注数据。 长视频强化学习训练挑战大:
视频帧数多,导致内存需求高; rollout 过程长,训练效率低; 上下文长度大,预填充开销大; 训练成本高,难以扩展。
提出的方案
构建高质量推理数据集 LongVideo-Reason:
包含 52K 条长视频问答三元组(问题-推理-答案),涵盖体育、游戏、vlog 等多领域; 引入链式思维(Chain-of-Thought, CoT)标注; 数据集分为 CoT 微调用的 18K 条和 RL 训练用的 33K 条样本。
提出两阶段训练框架:
阶段一:Long CoT-SFT,通过链式思维监督微调,提升模型的基本推理与指令跟随能力; 阶段二:强化学习(RL)训练,进一步优化模型在复杂长视频推理任务中的表现。
开发 MR-SP 训练系统(Multi-modal Reinforcement Sequence Parallelism):
引入 vLLM 引擎,定制支持长视频; 实现 视频嵌入缓存机制,提升 rollout 和预填充效率; 采用 序列并行策略,解决内存瓶颈与计算瓶颈。
构建评估基准 LongVideo-Reason-eval:
包含 1000 条长视频样本; 从四个维度系统评估模型:时间推理、目标与意图推理、空间推理、情节与叙事推理。
应用的技术
视觉语言多模态模型(VLM):基于 NVILA-8B 和其他开源大模型; 链式思维监督微调(CoT-SFT):引导模型进行多步推理; 强化学习(RL):对齐模型行为与复杂推理目标; 多模态强化序列并行(MR-SP): 支持视频、文本、音频等多模态输入; 使用 vLLM 引擎与视频嵌入缓存优化长视频处理; 提升训练效率,降低资源消耗; 长上下文处理机制:支持处理长达一小时的视频(约 3600 帧 / 256k token); 开源训练系统:支持 VILA、Qwen 系列模型及图像/视频生成模型的 RL 训练。
达到的效果
在多个基准测试中表现优异:
在 VideoMME 基准测试中,LongVILA-R1-7B 达到 68.4% 的准确率; 在 LongVideo-Reason-eval 上四维推理平均准确率为 **67.9%**,超过 Video-R1-7B 和 GPT-4o,媲美 Gemini-1.5-Pro。
推理能力显著提升:
在时间推理、目标与意图推理、空间推理、情节推理四大维度均取得领先; 能够处理更复杂的推理任务,如战术分析、目标预测、空间定位、情节理解等。
训练效率显著提高:
MR-SP 系统在 RL 训练中实现 最高 2.1× 加速; 支持更长帧数训练,避免内存溢出问题。
良好的可扩展性与开源支持:
模型性能随输入帧数稳步提升; 训练系统已开源,支持多模态、多模型、多任务的强化学习训练。
LongVideo-Reason 数据构建
高质量的长视频标注数据集对于 VLM 至关重要。现有公开的长视频数据集缺乏高质量的推理标注。本节详细介绍了一个包含 52K 条带推理的长视频问答对的数据构建过程(见下图 4)。


数据整理概览
首先从 Shot2Story 数据集中整理出 18K 条长视频(下图 3,左)。随后,应用一个高质量的自动化链式思维(CoT)标注流程,最终构建了总计 52K 条“问题-推理-答案”三元组。每个样本根据其所涉及的推理类型,可被归类为时间推理、目标与意图推理、空间推理或情节与叙事推理(下图 3,中)。该数据集旨在全面支持各种类型的长视频推理任务。
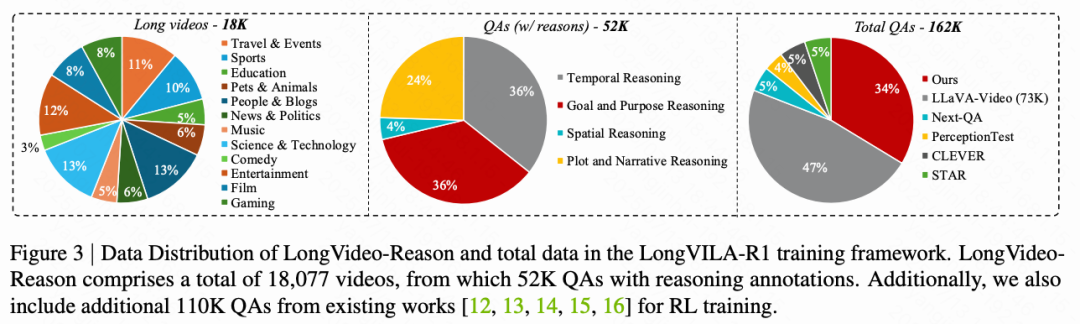
鉴于 GRPO 对 batch 采样的敏感性,采用了一种数据筛选方法。具体而言,使用一种测试缩放方法:LongVILA 对原始数据集进行 10 次推理。对问题始终回答正确或错误的样本被标记为“简单”或“困难”,而导致预测多样性的样本则被标记为“中等”。本文将“简单”和“困难”样本用于第 1 阶段的 COT-SFT,将“中等”样本用于第 2 阶段的强化学习训练。原因在于 GRPO 期望每个样本的 rollout 具有多样性,才能带来有效的优化优势;如果所有 rollout 都预测正确或错误答案,则梯度将消失。
COT-SFT 子集(18K)包含高质量的 CoT 推理过程,采用标准格式 <think></think><answer></answer>,为模型第 1 阶段的推理能力预热训练提供了丰富资源。与此同时,RL 子集包含 33K 条具有挑战性的长视频问答样本,用于第 2 阶段通过强化学习扩展推理能力。为了进一步提升 RL 的扩展性,本文还引入了来自其他数据集的额外 110K 条高质量开源视频(上图 3,右)。这种组合提高了模型的泛化能力。
长视频推理生成
本文引入了一个自动化标注流程(上图 4),用于从长视频中生成高质量的“问题-推理-答案”三元组。该流程首先将视频分割为多个短片段(每段约 10 秒),并使用 NVILA-8B 模型对每个片段生成描述性字幕。在此基础上,借助文本推理的突破,本文调用领先的开源推理大语言模型,提供整段视频中所有片段的字幕,并提示其生成涵盖整段视频内容的多种类型“问题-推理-答案”三元组。
具体而言,本文设计了四种提示词模板,引导大模型生成聚焦于以下四类推理之一的问答对:时间推理、目标与意图推理、空间推理或情节与叙事推理。为了确保 VLM 聚焦于视觉细节,本文在提示词中加入了“检查视频”、“分析场景”等短语,引导模型对视觉内容进行反复观察。最后,本文再使用一个大语言模型对推理步骤进行精炼与简化。
本文还手动整理了 1000 条涵盖四类推理的高质量复杂问题,作为新的评估基准(LongVideo-Reason-eval),用于评估 VLM 的推理能力。整个数据构建过程共消耗约 40,000 小时的 H100 GPU 计算资源。
LongVILA 训练流程
如下图 5 所示,LongVILA-R1 包含两个扩展训练阶段:(1) 使用 18K 条高质量 CoT 数据在 MM-SP 系统上进行 SFT,用于长视频推理的预热训练;(2) 使用密集帧的长视频进行强化学习训练。

长视频 CoT 监督微调
在 52K 条高质量“问题-推理-答案”数据的基础上,本文采用前文所述的数据筛选方法,选取其中 18K 条用于长视频 CoT-SFT,作为后续 RL 的预热阶段。该阶段赋予模型基本的推理能力和长视频场景下的指令跟随能力。为了高效地在数百帧视频上进行 SFT,本文采用了 LongVILA 的 MM-SP 训练系统。如下文所示,仅使用 LongVideo-Reason 数据集进行 SFT,也能有效提升模型的基础推理能力。
长视频的 GRPO
在 GRPO 算法的进展以及多模态推理训练的先前研究基础上,本文遵循标准的 GRPO 框架来训练模型。对于每个给定的问题 ,策略模型从旧策略 中生成一组候选响应 ,并计算其对应的奖励 ,这些奖励基于规则驱动的奖励函数(格式/准确性)计算得出。随后,通过最大化以下目标函数来优化模型 ,其中, 是基于奖励计算的加权因子,用于引导策略向高质量回答靠拢。
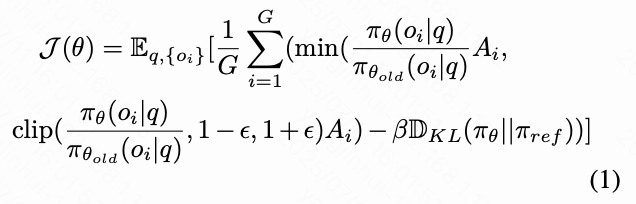
其中, 和 是超参数, 在本文的实验中设置为 8,上述采样的奖励被归一化以获得用于更新模型的优势值():
然而,由于处理数百到数千帧所需的高计算量,长视频的强化学习面临重大挑战。现有的强化学习框架在 rollout 和大语言模型预填充阶段难以应对如此长的上下文训练。为了解决这一问题,本文开发了 MR-SP 框架,该框架能够高效扩展用于长上下文视频推理的强化学习。
考虑到 GRPO 在训练过程中对采样的敏感性,本文使用前文汇总所述筛选后的 33K 条数据进行强化学习训练。此外,还引入了来自 Video-R1 的额外 110K 条样本以扩大强化学习规模。该方法旨在引导模型自由探索并发展出更有效且更具泛化能力的推理策略。
多模态强化学习序列并行
现有用于 VLM 的强化学习框架,如 R1-V 和 EasyR1,并未针对长视频设计,而长视频由于其巨大的 token 数量带来了独特挑战。为了解决这一问题,本文提出了多模态强化学习序列并行(MR-SP)框架,用于在长视频上进行高效的强化学习训练。MR-SP 在 rollout 和预填充阶段都采用了序列并行技术,从而在降低开销的同时实现长视频的强化学习。
阶段一:并行编码的 Rollout
为了高效支持长视频的强化学习,本文在视频编码阶段采用了序列并行(SP)策略。如下图 7 所示,输入的视频帧首先被平均分配到多个 GPU(例如 GPU 1 到 GPU 3)上,每个 GPU 配备其独立的视觉编码器。每个 GPU 独立处理视频的一部分,仅编码其分配到的帧子集。随后,通过如图中“All-Gather”箭头所示的 all-gather 操作,将得到的视频嵌入与文本嵌入进行聚合。该策略分散了编码负载,使系统能够借助更多 GPU 处理显著更长的视频,同时避免 GPU 内存溢出的风险。

这种并行编码方案确保了视觉编码器的负载均衡,并实现了原本在单设备上难以完成的可扩展长视频处理。
在全局聚合视频嵌入之后,它们会在整个强化学习流程中被重复使用。如上图 7 所示,这些聚合后的嵌入在多个 rollout 中被复用,无需重新计算。例如,在每个训练步骤中,本文通常执行 8 到 16 次 rollout。如果不进行复用,同一个视频在每一步中需要被重新编码数十次,严重影响训练速度。通过缓存并复用聚合嵌入,MR-SP 消除了这种冗余,大幅加快了训练过程。
阶段二:使用序列并行的预填充
对于每次 rollout,参考模型和策略模型都需要进行计算密集型的预填充操作,尤其是在处理长视频时。借助阶段一中复用的聚合嵌入,本文在推理阶段使用序列并行将计算分布到多个设备上。如上图 7 所示,聚合后的输入嵌入首先被填充至统一长度(Padding Sequence),然后平均划分到各个 GPU 上(Sharding to Local GPU)。这使得每个 GPU 在预填充时只需处理输入序列的一部分。
这种并行方式同时应用于策略模型和参考模型的预填充阶段。随后,每个 GPU 在本地为其对应的 token 子序列计算 logits,实现并行预填充。
实验结果
主要结果
下表 1 展示了在 9 个视频基准测试上的性能比较。LongVILA-R1-7B 在所有基准上均优于 LongVILA-7B,性能差距根据推理任务的复杂程度有所不同。

下表 3 展示了 LongVILA-R1 在 Video-MME 基准上与现有先进模型在相似模型规模下的整体性能比较。LongVILA-R1-7B 在不同视频长度下均取得领先分数。

LongVILA-R1-7B 在不同视频长度设置中均取得领先分数,在无字幕和有字幕设置下分别获得 和 的得分。
下表 2 比较了本文在 LongVideo-Reason-eval 基准上的结果。LongVILA-R1-7B 模型取得了平均得分 的强劲表现,显著超越了 Video-R1-7B 和 GPT-4o,略微优于 Gemini-1.5-Pro。

尽管 Gemini-1.5-Pro 在时间推理、目标与意图推理以及情节与叙事推理方面表现出色,LongVILA-R1-7B 的得分总体上也具有可比性。值得注意的是,在空间推理类别中,LongVILA-R1-7B 获得了 的得分。
消融实验
视频帧数扩展。 LongVILA-R1 的推理能力随着输入视频帧数的增加而持续提升。具体来说,下图 8 展示了 LongVILA-1.5B(灰线)和 LongVILA-1.5B-R1(红线)在不同帧数输入下,在长视频推理基准上的表现。

当输入帧数仅为 时,LongVILA-R1-1.5B 的表现接近 LongVILA-1.5B。然而,随着帧数增加至 ,LongVILA-R1-1.5B 持续优于 LongVILA-1.5B,最终达到 的得分。值得注意的是,LongVILA-R1-1.5B 在整个扩展过程中性能稳步提升。
相比之下,LongVILA-1.5B 在 帧时达到性能瓶颈,并在 帧时出现性能下降,这是由于其无法有效处理如此密集的视觉信息。LongVILA-R1-1.5B 增强的推理能力使其能够有效整合并推理来自长视频的信息。
训练流程与数据集的消融。 如下表 4 所示,本文从 LongVILA-1.5B 出发,评估训练阶段与数据集的有效性。准确率在 LongVideo-Reason-eval 上进行评估。✗ 表示跳过该阶段,✓ 表示使用本文数据集训练该阶段,O 表示使用其他数据集训练该阶段。

本文的 CoT-SFT 数据集比其他数据集带来更好的性能。此外,在预热阶段(CoT-SFT)基础上引入强化学习(RL)带来了额外提升,相较于仅使用 SFT 更为有效。
本文展示了如果跳过 CoT-SFT 阶段,直接使用 RL 训练模型,准确率会下降。如果在 CoT-SFT 和 RL 两个阶段都使用 Video-R1 数据集,性能也不如使用本文数据集。
MR-SP 的训练效率。
本文在一个 A100 节点(即 8 张 A100 80GB GPU)上对 MR-SP 系统的训练效率进行了比较。本文测量每个训练步骤的前向时间。结果是在 10 次预热迭代后,取 5 次迭代的平均值以减少方差。
本文使用 LongVILA-7B-R1 模型,训练时每个 GPU 的 batch size 为 ,rollout 数为 。上图 1 展示了在不同帧数下的训练效率比较,绘制了三种设置下每步运行时间(秒):不使用 MR-SP 的原始 RL 系统,仅使用 MR-SP 的阶段一,以及完整的 MR-SP 系统(阶段一和阶段二)。
基线系统的运行时间随着帧数的增加急剧上升。仅使用 MR-SP 的阶段一在 帧以内显著提升了效率,但在超过该点后出现 GPU 内存溢出(OOM)问题。相比之下,完整的 MR-SP 系统持续减少运行时间,在 帧时实现了最高 的加速,并可高效扩展至 帧而不会出现 OOM,突显了序列重用与序列并行结合在长视频强化学习训练中的优势。
结论
本文提出了一个全面的框架,旨在实现视觉语言模型(VLM)在长视频推理任务中的完全扩展。LongVILA-R1 包含一个精心构建的大规模数据集 LongVideo-Reason,以及一个并行化训练框架 MR-SP。借助本文整理的包含 条长视频问题-推理-答案对的数据集,并结合其他开源视频数据集,本文采用了结合 CoT-SFT 和 RL 的两阶段训练流程。
LongVILA-R1-7B 在主流视频基准上表现卓越,在带字幕的 VideoMME 上达到了 ,在 LongVideo-Reason 测试集中四类推理的平均准确率为 。LongVILA-R1 持续展现出性能提升,将可处理帧数从 扩展至 。值得注意的是,本文的 MR-SP 在长视频强化学习训练中实现了 的加速,支持在单个 8 卡 A100 节点上进行小时级别( 帧 / tokens)的 RL 训练。
此外,公开了训练系统,支持多模态(视频、文本和音频)下的 RL 训练,适用于多种模型(包括 VILA 和 Qwen 系列),甚至支持图像和视频生成模型。
参考文献
[1] Scaling RL to Long Videos
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!











