ShotBench团队 投稿
量子位 | 公众号 QbitAI
当前最强大的视觉语言模型(VLMs)虽然能“看图识物”,但在理解电影方面还不够“聪明”。
上海人工智能实验室联合新加坡南洋理工大学 S-Lab、同济大学和香港中文大学,正式推出ShotBench,配套模型ShotVL及训练集ShotQA,为VLM的“电影感”打开评测与训练的双重缺口。

ShotBench是一个专门为电影语言理解设计的综合基准。它包含超过3.5k个由专家标注的图像和视频片段问答对,来自超过200部备受赞誉(主要是奥斯卡提名)的电影,涵盖八个关键电影摄影维度——景别、取景构图、摄像机角度、镜头焦距、照明类型、照明条件、构图和摄像机运动。团队按照严格的标注流程,结合经过训练的标注员和专家监督,确保构建基于专业电影知识的、高质量的评估数据集。
ShotQA,是一个包含约7万个电影问答对的大规模多模态数据集。借助ShotQA,团队通过监督微调(SFT)和群体相对策略优化(GRPO)开发了ShotVL。ShotVL在ShotBench上显著优于所有现有的开源和专有模型,确立了新的顶尖性能。

团队在ShotBench上对24个领先的VLMs进行的评测揭示了现有模型的重大局限性:即使是表现最好的模型,平均准确率也低于60%,尤其是在处理细粒度视觉线索和复杂空间推理方面表现不佳。
与原始Qwen2.5-VL-3B相比,ShotVL-3B在所有ShotBench维度上均实现了持续且显著的提升(增益达19.0%),确立了新的顶尖性能,并明确超越了最佳开源模型(Qwen2.5-VL-72B-Instruct)和专有模型(GPT-4o)。

团队开源了其模型、数据和代码,以促进AI驱动的电影理解和生成这一关键领域快速发展。
一起来看详细内容。
现有问题与解决方法
团队通过对24个主流VLM进行深度测评,发现以下问题,
评测真空:现有基准(MMBench、MMVU等)关注通用视觉场景,却缺失对专业电影摄影语言的考查。
模型盲区:即使是表现最好的模型GPT-4o和Qwen2.5-VL-72B平均准确率不足60%,尤其在相机运动、镜头焦段等维度上表现不佳。
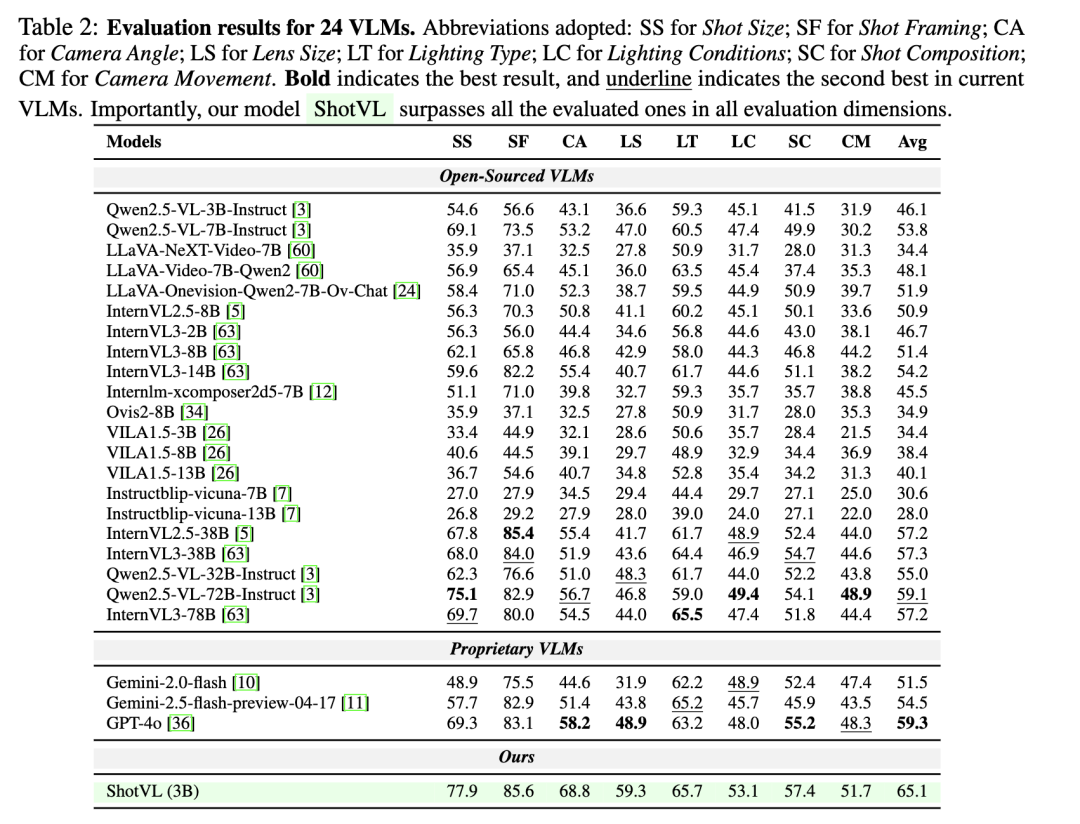
△图2:24个VLMs的评估结果
ShotBench:“电影镜头语言”理解综合基准
ShotBench中的每个样本都配有一道针对特定电影摄影方面的选择题,要求模型以一个专业摄影师的视角提取画面的视觉线索并推理其背后的电影技术。基准框架的概述下图所示。

数据策展与预处理:团队从获得或提名奥斯卡最佳摄影奖的电影中收集数据集,确保高质量和专业制作的镜头。数据来源于公共网站,包括高分辨率图像和视频片段。
标注员培训:团队首先从公开可用的电影摄影教程中收集了涵盖 ShotBench 所有八个维度的全面参考材料。标注员被要求在标注前学习这些材料。团队进行多轮试点标注,并得到专家审核和每日讨论的支持,以确保高质量的数据标注。
覆盖摄影语言8大核心维度: 
- Shot Size(景别)
画面中呈现人物的范围大小,是电影视觉语言的基本要素之一。常见类型包括近景(CU)、全景(WS)等,不同景别传达不同的叙事意义。 - Shot Framing(取景)
画面中人物或物体的摆放位置和构图方式。它不仅关乎拍摄谁,更重要的是如何在画面中安排主体与镜头及其他元素之间的关系,以增强视觉表达和叙事效果。 - Camera Angle(相机角度)
相机拍摄主体的角度,例如俯拍(highangle)显得主体渺小,仰拍(lowangle)则让主体显得强大,而倾斜镜头(Dutch angle)则用于制造不安或失衡的感觉。 - Lens Size(焦段)
焦段决定画面的视野与空间感。短焦镜头视野广、透视强,长焦镜头视角窄、背景压缩明显。 - Lighting Type(照明类型)
在影视中使用的光源类型和氛围,例如自然光(如白天、阴天、月光)、人造光(如荧光灯、火光),以及场景中可见并为叙事服务的实用光(Practical light)。不同光源不仅影响画面亮度和色温,还塑造情绪与空间感。 - Lighting Condition(照明条件)
光线的质感与方向,如柔光、硬光、高对比、低对比、背光、侧光等,用于塑造画面的氛围、立体感与情绪表达。 - Composition(构图)
画面中元素的空间排列方式,如左重、右重、对称和短边构图等,用于引导视线并强化视觉表达。 - Camera Movement(相机运动)
摄影机位置,焦距和角度的变化,用于调整画面视角。它能引导观众注意力,增强情绪张力,并赋予画面动态感。
质量保证标注。基于ShotBench预定义的维度,我们使用模板格式自动生成了问题提示(例如,“这个电影镜头的拍摄尺寸是什么?”)。对于图像数据,我们从Shotdeck(一个专业的电影摄影参考平台)中提取了候选标签,该平台上的元数据由经验丰富的摄影师整理。标注员根据ShotBench指南验证这些标签,并纠正任何差异。所有标签修改都经过专家审核。对于视频,标注员通过标记开始和结束时间戳来识别所有有效的摄像机运动区间。
验证。所有问答对都经过多位专家审核,分批迭代修改直至达到满意质量。通过这一严格流程,团队从验证数据中进一步采样,构建了最终的电影基准,包含3,049张图片和464个视频片段,最终形成涵盖所有八个电影摄影维度的3,572个高质量问答对,由资深摄影师与专业标注团队联合制作。
ShotQA&ShotVL:提升电影摄影理解能力
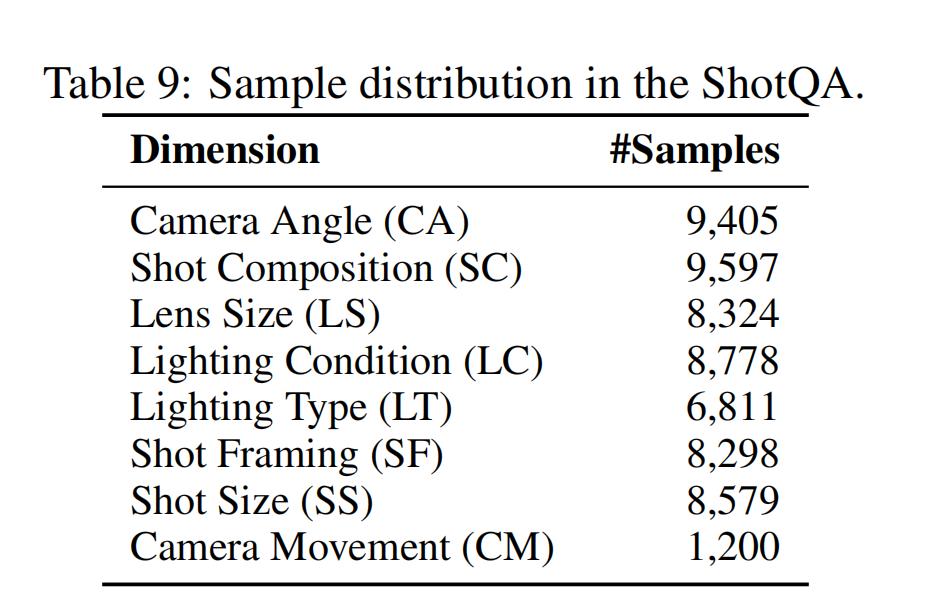
为解决数据稀缺问题,团队制作了带有摄影语言标注的大约60k电影截图和1.2k个视频片段的ShotQA数据集,自动生成约70kQA对,专供模型对齐“镜头语言”,是首个大规模综合摄影语言理解数据集。ShotQA的规模和针对性为该领域的研究提供了关键资源。
此外,团队设计了ShotVL这一专为电影摄影理解的 VLM。ShotVL 采用了一种策略性的两阶段训练流程:首先进行大规模的监督微调(SFT)以获取广泛知识,然后对精选子集进行群体相对策略优化(GRPO)以进行细粒度的推理优化。
团队以Qwen 2.5-VL-3B 为基础,发现先监督微调再引入GRPO进行强化微调的两阶段训练策略可以最大限度提升模型平均性能。
第一阶段:大规模监督微调以实现基础对齐。在基础的第一阶段,ShotVL使用从ShotQA数据集中采样的约7万个问答对进行SFT。团队使用Qwen-2.5-VL-3B-Instruct作为基础模型。该模型处理图像或视频,并结合问题以及多个选项,让模型直接预测正确答案。这一SFT阶段对于建立视觉特征与特定电影术语之间的强对齐至关重要,使模型具备对电影摄影概念的综合理解能力。
第二阶段:使用GRPO强化学习以增强推理。基于SFT初始化模型后,第二阶段采用GRPO进一步提升ShotVL的推理能力和预测精度。
性能评估:3B模型超越GPT-4o
团队通过评测发现,开源模型与专有模型之间的总体性能差异微乎其微。在每个系列中,更大的模型通常能获得更高的准确率。
图3展示了InternVL3、Qwen2.5-VL和VILA-1.5模型系列的总体性能比较,突出显示不同模型大小的变化。结果始终表明,每个系列中较大的模型通常能产生更优的性能结果。
图4展示了六种视觉语言模型(VLMs)在电影理解方面的性能评估,跨多个维度进行可视化。性能更强的模型在各个维度上表现良好,没有特定的维度弱点。

△左:图3 右:图4
团队对比了ShotVL与Qwen2.5-VL-72B-Instruct、GPT-4o、Qwen2.5-VL-3B-Instruct。与基线模型Qwen2.5-VL-3B-Instruct相比,ShotVL在所有维度上都取得了显著提升,平均提升19分,这证明了数据集和训练方法的有效性。
此外,尽管ShotVL只有3B参数,但它超越了GPT-4o和最强的开源模型Qwen2.5-VL-72B-Instruct,刷新SOTA,在电影语言理解方面设立了新的技术标准,同时提供了显著更低的部署和使用成本。

消融研究
团队研究了ShotVL两阶段训练策略的有效性,比较了五种训练策略:SFT、CoT-SFT、GRPO、SFT→GRPO和CoT-SFT→GRPO。
比较SFT与CoT-SFT,团队发现后者带来的增益非常小。这可能是由于Gemini-2.0-flash生成的推理链质量较低,无法提供有效的监督,并可能引入噪声。这进一步突显了GRPO的优势,它专注于结果奖励监督。

另一个观察是,推理增强训练在摄像机运动维度上性能始终得到提升,范围从+0.4%增长到+4.6%。尽管消融实验仅针对静态图像进行且不包含与摄像机运动相关的问题。这可能表明推理链生成可能隐含地增强了VLMs识别动态运动的能力。
从图7可以看出,GRPO在所有训练设置下始终在大多数维度上提升了性能。在所有配置中,SFT→GRPO的设置实现了最佳整体性能,证实了其在增强电影语言理解方面的有效性。(更多案例研究提供在论文附录A.2中。)

△图7:不同电影摄影维度下不同训练策略的比较。
此研究项目全面涵盖摄影语言理解核心维度的大规模评测基准,3B模型超越GPT-4o,验证MLLM的摄影语言理解潜力,为图像/视频生成、编辑等领域提供专业模型基座。
项目主页:
https://vchitect.github.io/ShotBench-project/
模型:
https://huggingface.co/collections/Vchitect/shot-vl-685e541cdc5583148b36c12f
论文:
https://arxiv.org/abs/2506.21356
Github:
https://github.com/Vchitect/ShotBench
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟










