过去很长一段时间,具身智能其实都缺一场真正像样的考试。
原因并不复杂。在这个行业里,一个 demo 做得漂亮,从来不算太难。
挑一套熟悉的环境,选一个调过很多遍的任务,控制好拍摄角度和执行流程,最后跑出一段顺畅的视频,这些都能证明方法“有希望,大有作为”。
但问题在于,机器人真正要面对的从来不是 demo 里的世界,而是充满摩擦、误差、遮挡、扰动和偶然性的物理世界。很多方法一旦放到真机上实测,就会迅速暴露出问题。也正因为如此,具身智能一直需要的,都不只是更丝滑的Demo,是一套更公开、更统一、可持续的真机评测体系。
而如今,这件事变得比过去更迫切了。
过去几个月,VLA、强化学习和世界模型都在快速迭代。模型越来越会“做事”,也越来越容易在单个任务上交出一份漂亮成绩单。可越是这样,行业就越需要一个足够权威的 benchmark,去回答一个更根本的问题:这些模型到底是真的更接近通用能力了,还是只是更擅长把某一道题做对?
半年前,RoboChallenge 先迈出了第一步。它推出了 Table30,把真机评测从零散的局部展示,往 benchmark 的方向推了一步:集中式、在线化、真实机器人、30 个任务、公开排行榜。
RoboChallenge先搭起的,不只是一个榜单,而是一个“真实具身考场” —— 让不同模型第一次能够在更统一的规则下,被持续地放到真机上比较。
而在这半年里,随着超过4万次的真机评测,新的问题也开始浮出水面:当越来越多的方法可以通过单任务精调把分数做高,原来的评测方式,是否还能真正测出下一代具身模型最关键的能力?
也正是基于这个背景,RoboChallenge 选择把 Table30 升级到 Table30 V2。
这次升级最值得注意的地方,并不只是“多了几道题”,而是它把过去半年真机评测里暴露出来的真实问题,系统性地写回了规则本身。作为 RoboChallenge 的联合发起方之一,原力灵机这次更像是在用一套新的评测设计回答同一个问题:当单任务高分越来越容易做出来,具身智能到底该怎么考,才能真正考到泛化能力本身。
此外,这次 RoboChallenge 正式发布的 Table30 V2,其预览版将也作为 RoboChallenge CVPR 2026 Workshop 竞赛的首秀上线发布。

单任务冠军越来越多,评测却越来越失真了
现在的具身模型,有点像什么?有点像那种刷题特别猛的学生。
你给他一道题,他能做得很好;你给他这一类题里的某一道变体,他也许还能顶住。
但你真把题库打乱、换个顺序、换个考场、再不允许他每道题单独准备一套答案,他的真实水平就开始暴露了。
而这,正是 Table30 V2 要解决的问题。
过去一段时间 VLA 和 WMA 在真机上的进步非常快,尤其像 π0.5 这类开源模型,已经在单任务精调设定里表现得相当强。
很多看起来很难的任务,只要训练数据认真整理、微调做得够狠,最后都能拿下来。但问题也随之出现:模型常常被微调到几乎失去任务外能力,榜单测出来的越来越像单题熟练度,而不是通用能力。
但这也背离了榜单的初衷:下一代具身模型真正该测的,不应只是单任务表现,而是泛化。这句话其实是在说:
我们不能再拿“这道题你做对了没”来判断一个机器人聪不聪明了,而要看它换一道题、换一个物体、换一张桌子,甚至换一台机器之后,还能不能做对。
这才是真正的具身智能需要解决的实际问题。
RoboChallenge
把“真机裸考”这件事做成了
这一点其实很重要。
今天谈 Table30 V2,容易直接从新任务、新协议讲起,但如果不把 RoboChallenge 之前做的事情讲清楚,就很难理解 V2 为什么值得认真看。
RoboChallenge做成的第一件事,是让真机评测从 demo 逻辑往 benchmark 逻辑走。
它证明了一件事:真机评测,值得业界投入精力去做。
过去的真机评测并不是没有,只是它们大多关注局部:在某个任务、某套环境、某台设备上跑出一个结果,证明了某个方法有效。也有更早的在线评测工作,或者更偏分布式的方案,让用户本地跑完再提交视频判分。
而RoboChallenge 则证明了集中式、在线化、真机集群这条路线是跑得通的,而且到目前为止,它仍是任务数量最大的那类。
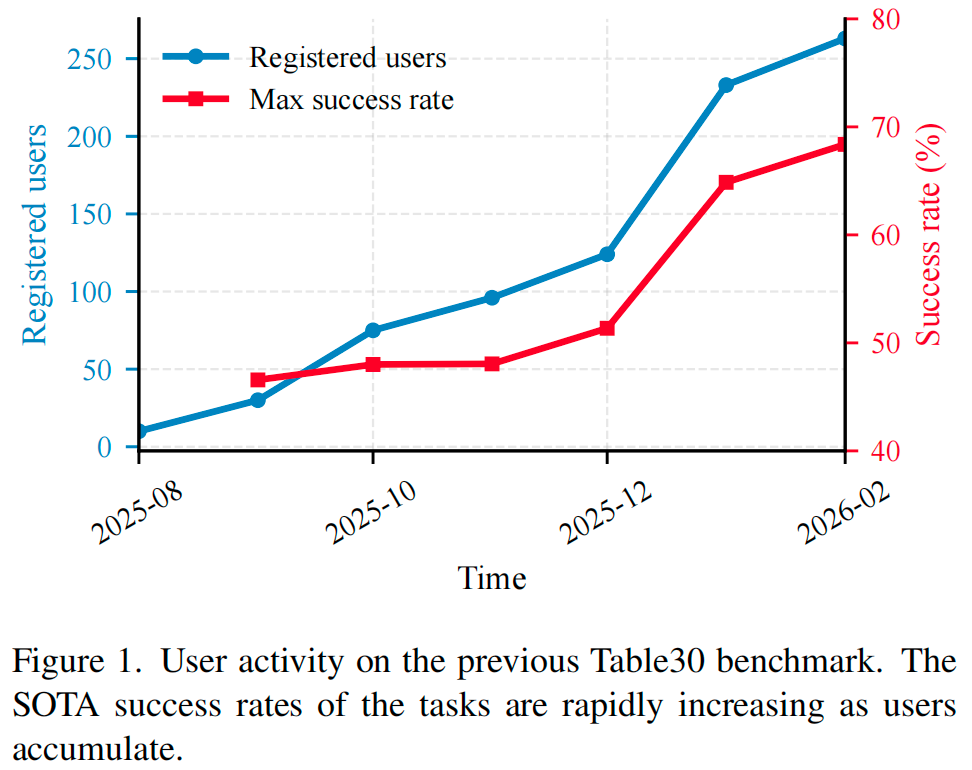
第二件事,是让行业第一次比较连续地看到模型能力变化。
RoboChallenge发现,随着注册用户增多,原 Table30 上的 SOTA 成功率也在快速抬升。
换句话说,RoboChallenge 不只是一个排行榜,它更像一个“能力地震仪”,把行业里 VLA/WMA 的进步曲线给测了出来。
第三件事,是把真实世界里的反馈收集回来了。
Table30 吸引到的用户数量远超预期,不仅有机构团队,也有个人研究者和学生;而大家围绕公平性、带宽、规则设计提出的大量反馈,直接推动了 V2 的诞生。
尤其一个很关键的观察是:原来如果要对 30 个任务分别调模型、分别做 fine-tune,个人研究者几乎没有成本优势,最后排行榜上更容易只剩机构玩家。这也是 V2 转向多任务评测的重要原因之一。
所以你会发现,Table30 V2 不是突然灵光一现的第二版。
它更像是 RoboChallenge 在做了 4 万多次真机测试之后,对“具身模型到底该怎么考”给出的一次系统回答。
Table30 V2,变的不只是题量,而是physical AI的体现
先说最直观的变化:题更难了,但不是那种“为了难而难”的设置。
Table30 V2 保留了 12 个上一代任务,同时新增了 18 个全新的双臂灵巧操作任务,组成新的 30 任务套件。这些任务把现实世界里的摩擦力、接触约束和物理复杂性带进来了。Table30 没有充分覆盖真实世界的难点,所以 V2 要把任务往软体、工具和双臂协作这几个方向拉。
为什么是这三个方向?
因为这三类任务,最不容易靠“背答案”混过去。
先看软连续体。
绳子、布料、带子这类东西的麻烦在于,它们没有固定形状。你今天看到的状态,下一次几乎不会一模一样。Table30 V2说得很直接:这类物体的状态很难 run-to-run 地复现,模型必须处理从未见过的形状和状态。换句话说,这种题天然就在考泛化,而不是考记忆。
再看工具使用。
会抓物体,和会用工具,根本不是一回事。拿起印章不难,难的是知道印章、印泥、纸面之间的空间关系;拿起刷子不难,难的是控制力度、角度和接触时机。Table30 V2 明显在往这种“带物理常识”的任务上加码。
最后是双臂同步协作。
很多双臂任务,过去其实还是“一只手干活,另一只手辅助一下”;但这次 V2 更强调两只手在受限空间里做高精度协同。
Table30 V2统计里,30 个任务中有 9 个要求双手协调,7 个涉及工具使用,6 个要求高位置精度,而且这些难点是彼此交叉的。你可以把它理解成:它不再满足于考“你会不会抓”,而是开始考“你会不会像一个熟练工那样同时处理多个物理约束”。

04
不仅任务变难了,
真机评测的规则也变了
如果说任务升级是在提高题目含金量,那么协议升级就是在反“刷榜工作”。
Table30 V2 最关键的一条新规则,是全面转向多任务模型。
这件事表面看只是换了评测口径,实际上是在打掉过去很常见的一种隐形优势:你不再能靠“一题一个模型”“一题一套调参策略”去拼榜。技术报告和官方材料都强调,V2 的目标是测试更通用的模型,而不是鼓励参赛者为每个任务单独训练一个专用模型。
这里最聪明的一个设计,是它的“临场抽题”逻辑。
系统会先问你:你是否已经为若干任务准备好了?你回答“准备好了”之后,平台只会在真正开始前几秒告诉你这次做哪一题,并要求立刻执行。Table30 V2 专门画图解释,这其实是在探测你有没有偷偷切模型。它不是绝对防作弊,但至少把“后台切换 task-specific policy”这件事的成本抬高了。

再往前一步,就是 Zero-Shot 和 OOD。
Zero-Shot 不是一个花哨词,它在这里的意思很朴素:
不给你额外微调,看你在没见过的物体、没见过的背景、甚至轻微变化过的环境里,还能不能把同一个任务做出来。
而OOD 则更像压力测试。
不是换个颜色这么简单,而是故意让环境往“不舒服”的方向偏,比如台面高度变了,摆放更别扭了,甚至把桌面换成沙发。
一句话我觉得总结很到位:Table30 V2要做的已经不是普通的分数对比,而是在逼问模型有没有学到任务的“智能本质”。
这两层测试加进来之后,Table30 V2 的气质就彻底变了。它不再只是一个“30 道桌面题”的合集,而更像是一套围绕真实泛化能力设计出来的考试系统。
05
系统升级,是这次极有价值的部分
很多人看 benchmark,只看任务和分数。
但对在线真机评测来说,真正决定它能不能长期跑下去的,往往是系统层面的东西:吞吐量够不够、调度稳不稳、初始状态准备麻不麻烦、机器实例之间是否一致、等待反馈是不是太久。
Table30 V2 这次在系统上也动了大手术。
最直接的一条是吞吐量提升到上一代的 300%。这件事最容易被大家忽视但却非常重要,因为一旦评测里引入多任务、zero-shot、OOD,单次实验背后的测试量会迅速膨胀,没有吞吐量,评测设计再先进也跑不起来。
具体怎么提上去的?
一个非常实用的改动是,把初始状态准备从像素级对齐放宽成粗略对齐。
这看起来像妥协,实际上很合理:既然你本来就在测泛化,那就没必要再把每次任务都摆成“和参考图一模一样”。论文明确说,这项改动显著加快了任务准备时间。换句话说,它是在把 benchmark 从“精致实验室”往“真实工位”上拉。
另一个关键变化,是把完成时间也拉进评价维度。
这个设计我很喜欢,因为它针对的是具身评测里一个特别常见、但很少被明说的问题:有些策略不是更聪明,而只是更慢。你给它足够长的时间,它当然更容易成功,但那并不意味着它更可用。
V2 把 Time to Complete 单独拎出来,本质上是在告诉大家:不只看你能不能做成,还看你是不是像一个能上岗的系统那样高效。
还有一个容易被忽略的点,是硬件维度也被重新设计了。
V2 引入了新的双臂平台 DOS-W1,配备三角尖端夹具,同时保留 Aloha;这样一来,“双臂表现”就不再等同于“在 Aloha 上的表现”。这件事很重要,因为它开始把“任务表现”和“特定机器适配”拆开来看了。官方统计里,DOS-W1 承担 12 个任务,Aloha 8 个,其余由 ARX5 和 UR5 分担。

06
横向看,Table30 V2到底站在哪条路线上
如果把它放进整个评测版图里看,Table30 V2 的位置会更清楚。
和原版 Table30 比,它最大的变化不是“第二代更难”,而是从测单点能力转向测泛化能力。原版更像在回答:你能不能把这 30 类桌面操作做出来;V2 则在追问:你到底是学会了,还是只是在一个窄分布里调通了。
和单任务榜单比,它最强的地方是不再奖励局部最优。
单任务榜单当然有价值,它能看清一个方法在某类技能上的上限。但它也天然容易把行业带进专项刷分的路径依赖里。Table30 V2 的多任务、Zero-Shot、OOD 设计,本质上是在把具身评测从“奥赛题思维”拉回“物理通识考试思维”。
和用户本地跑完再交视频的分布式评测路线相比,Table30 V2 仍然坚持集中式、在线、真机原生这条路。有些系统靠视频回传来扩大规模,而 RoboChallenge 这一系更强调统一环境、统一硬件和在线执行。前者更容易扩展,后者更容易控制变量。Table30 V2 显然押注的是后者。
这也解释了为什么它不是简单的新榜单,而更像一次评测哲学的切换。

07
它真正改写的,
是行业怎么考试
Table30 V2 最重要的,不是新增了多少任务,也不是吞吐量提了多少。
而是它把具身智能里一个越来越尖锐的问题,正式摆到台面上来了:当单任务 fine-tune 已经越来越强,下一代具身模型到底该凭什么分出高下?
Table30 V2 给出的答案很明确:
-
不是凭你能把某一道题调到多高;
-
而是凭你能不能拿一个更统一的模型,去面对更多任务、更多物体、更多环境变化,还保持稳定表现。
它不再想测“最会考试的人”,而是想测“真正拥有具身智能的人”。
这件事的意义,比一个 leaderboard 更大。
因为具身智能走到今天,行业最需要的已经不是另一个剪得更漂亮的 demo,或者另一个单项冠军。行业真正缺的,是一套越来越接近现实部署逻辑的评测:题不能太假,规则不能太松,系统不能太慢,结果还得尽量公平。
RoboChallenge 用 4 万多次真机测试,把这个考场搭到了第二阶段;而 Table30 V2,开始把泛化这件事,认真写进考纲。
这才是它最值得重视的地方。不是榜单升级了。而是具身智能终于开始换一种方式,被认真地评判了。