> 本文转载自「Disaggregated-AI」

|
|
对接哪个硬件生态?
-
我最终选择了让 SpinalGPU 对接英伟达的 CUDA 生态,具体来说,对接 NVIDIA PTX 一层(支持部分核心关键指令集)。 -
原因比较简单,设计任何一款系统或者芯片,最重要的是起其北向 API。英伟达芯片的北向 API - PTX ISA指令集,有较为全面的文档,因此我可以参考这些文档去实现底层的功能,实现完之后也能去跑英伟达生态下的算子等,可加速学习的过程。适配国产AI 芯片是一个道理,笔者把这个留给 Future Work 或者有感兴趣的同学可以联系我一起搞。

-
我使用了 SpinalHDL 来开发,所以取了 SpinalGPU 这个项目名。 -
对于硬件开发描述不熟悉的同学,解释如下:传统硬件开发语言是大家可能听过的 Verilog、VHDL,它们是类似于 C 语言的定位,是非常底层描述数字系统硬件结构和行为的语言,学习和开发成本比较陡峭;在 2012 年~2014 年,涌现了更高抽象层次的硬件编程语言例如 Chisel 和 SpinalHDL,它们是基于Scala语言构建的硬件构造语言,用户可使用 Scala 高级语言开发硬件,编译器会把 Scala 编译成 Verilog 或 VHDL,大大加速了硬件开发迭代速度。 -
Chisel 和 SpinalHDL 两个语言很像,我最终选择 SpinalHDL 的原因是因为我比较喜欢 SpinalHDL 的语法和内置组件。比如可以用 a >> b 来串联两个端口。我在博士期间也用过 SpinalHDL 开发过 2 篇论文:Clio, ASPLOS'22 和 SuperNIC, FPGA'24. 目前基于 Chisel 比较有名的项目有中科院计算所包云岗老师的香山开源芯片项目(https://xiangshan.cc/zh/)。
-
这个问题的答案有两个。第一个选择是功能仿真 only,也就是最后只用基于 CPU 的仿真来验收功能用例,不看最后硬件的时序等;第二个是选择上 FPGA 板子真实部署,也就是需要引入类似 Vivado 的软件、时序调试、上板部署等。 -
作为个人娱乐项目,我选择扣1。
|
|
我们先看看 SpinalGPU 在 Vibe 完后的架构总览。

class GpuTop(val config: GpuConfig = GpuConfig.default) extends Component {val io = GpuTopIo(config)val coreClock = in Bool()val coreReset = in Bool()val coreClockDomain = ClockDomain(clock = coreClock,reset = coreReset,config = ClockDomainConfig(resetKind = SYNC))val core = new ClockingArea(coreClockDomain) {val hostControlBlock = new HostControlBlock(config)val gpuCluster = new GpuCluster(config)hostControlBlock.io.axi <> io.hostControlgpuCluster.io.command.command := hostControlBlock.io.commandgpuCluster.io.command.start := hostControlBlock.io.startgpuCluster.io.command.clearDone := hostControlBlock.io.clearDonehostControlBlock.io.executionStatus := gpuCluster.io.command.executionStatusio.debugExecutionStatus := gpuCluster.io.command.executionStatusio.memory <> gpuCluster.io.memory}}
|
|
我们第一步要解决和生态的对接问题。


https://github.com/lastweek/SpinalGPU/tree/main/kernels
|
|
解决了生态对接之后,下一步就是实现 GPU 最核心的计算单元:Streaming Multiprocessor(SM)。
一个 GPU 通常由多个 SM 组成。SM 是 NVIDIA GPU 的基本执行与资源管理单元,负责驻留并调度多个 warp,并在本地的执行流水线、寄存器文件、shared memory / L1 cache 等片上资源上推进指令执行。 
从 CUDA 编程模型看,thread block 以 SM 为驻留边界:一个 block 中的所有线程都会在同一个 SM 上执行;而在 SM 内部,线程再按 32 个线程组织成一个 warp,warp 是硬件调度的基本粒度。 
从微结构上看,SM 并不是若干 CUDA Cores 的简单堆叠,而是一个完整的片上执行节点。它内部通常包含多类执行与访存部件,例如负责通用标量算术的 CUDA Cores、负责矩阵乘加的 Tensor Cores、负责特殊函数计算的 SFU、负责访存的 LSU,以及配套的寄存器文件、片上缓存与调度逻辑。以 H100 为例,一个 SM 包含 128 个 FP32 CUDA Cores 和 4 个第四代 Tensor Cores。 
进一步看,NVIDIA 近几代架构通常会把一个 SM 划分为多个内部处理分区。以 H100 这一代为例,可以把一个 SM 视为由 4 个 SM sub-partitions 组成;每个分区内部都有自己的 warp scheduler、register file 和一组执行单元,而一些缓存与共享资源则在整个 SM 范围内共享。也正因为如此,H100 的一个 SM 并不是“最多只能运行 4 个 warps”,而是“内部有 4 个主要处理分区,可在其上调度多个 ready warps”;从 occupancy 的角度看,一个 H100 SM 最多可驻留 64 个 warps,只是任一时刻真正被发射、向前推进的 warp 数会受到调度器和执行资源的限制。 
在 SpinalGPU 中,我们首先设计支持 multi-SM。其次,在一个 SM 内部, 我们设计包含一些公共资源和多个 SmPartition,一个 SmParition 会包含如下资源:
-
Warp Queue 任务队列 -
Warp Scheduler 调度器 -
执行 SIMT 指令的 CUDA Cores -
执行矩阵计算加速的 Tensor Cores -
执行特殊计算加速的 Special Function Unit (SFU) -
执行内存读写的 Load/Store Unit (LSU) -
数据和指令的 Cache -
大量的 Registers
// SpinalGPU written in SpinalHDL Language.class StreamingMultiprocessor(val config: SmConfig = SmConfig.default) extends Component {val io = StreamingMultiprocessorIo(config)private val subSmPartitions = Array.fill(config.subSmCount)(new SubSmPartition(config))private val smAdmissionController = new SmAdmissionController(config)private val warpStateTable = new WarpStateTable(config)private val warpBinder = new WarpBinder(config)private val l0InstructionCaches = Array.fill(config.subSmCount)(new L0InstructionCache(config))private val l1InstructionCache = new L1InstructionCache(config)private val l1DataSharedMemory = new L1DataSharedMemory(config)private val sharedMemory = new SharedMemory(config)private val externalMemoryArbiter = new ExternalMemoryArbiter(config)private val externalMemoryAdapter = new ExternalMemoryAxiAdapter(config)...
// 在 SpinalHDL 语言中, A端口 <> B 端口, 意味着双向对接 A 和 B// A >> B, 意味着 A 单向到 Bfor (subSm <- 0 until config.subSmCount) {l0InstructionCaches(subSm).io.request <> subSms(subSm).io.fetchMemReqsubSms(subSm).io.fetchMemRsp <> l0InstructionCaches(subSm).io.responsel1InstructionCache.io.subSmReq(subSm) <> l0InstructionCaches(subSm).io.l1Reql0InstructionCaches(subSm).io.l1Rsp <> l1InstructionCache.io.subSmRsp(subSm)、 .....}
// SpinalGPU written in SpinalHDL Language.class SubSmPartition(config: SmConfig) extends Component {val io = new Bundle {..}// 定义每个 SubPM 拥有的核心资源,比如寄存器、CudaCore、TensorCore 等private val registerFile = new WarpRegisterFile(config, slotCount = config.residentWarpsPerSubSm)private val slotTable = new LocalWarpSlotTable(config)private val scheduler = new LocalWarpScheduler(config)private val fetchUnit = new InstructionFetchUnit(config)private val decodeUnit = new DecodeUnit(config)private val specialRegisterUnit = new SpecialRegisterReadUnit(config)private val cudaCoreArray = new CudaCoreArray(config)private val loadStoreUnit = new LoadStoreUnit(config)private val specialFunctionUnit = new SpecialFunctionUnit(config)private val tensorCoreBlock = new TensorCoreBlock(config)..
// SpinalGPU written in SpinalHDL Language.// decoding and dispatch a warp's instruction...} elsewhen (decodeUnit.io.decoded.target === ExecutionUnitKind.CUDA) {cudaCoreArray.io.issue.valid := Truewhen(cudaCoreArray.io.issue.ready) {capturePendingOp(decodeUnit.io.decoded)engineState := EngineState.WAIT_CUDA}} elsewhen (decodeUnit.io.decoded.target === ExecutionUnitKind.LSU) {loadStoreUnit.io.issue.valid := Truewhen(loadStoreUnit.io.issue.ready) {capturePendingOp(decodeUnit.io.decoded)engineState := EngineState.WAIT_LSU}} elsewhen (decodeUnit.io.decoded.target === ExecutionUnitKind.SFU) {specialFunctionUnit.io.issue.valid := Truewhen(specialFunctionUnit.io.issue.ready) {capturePendingOp(decodeUnit.io.decoded)engineState := EngineState.WAIT_SFU}} elsewhen (decodeUnit.io.decoded.target === ExecutionUnitKind.TENSOR) {tensorCoreBlock.io.issue.valid := Truewhen(tensorCoreBlock.io.issue.ready) {capturePendingOp(decodeUnit.io.decoded)engineState := EngineState.WAIT_TENSOR}
|
|
完成了 SM 的顶层设计之后,下一步就是实现 SM 内最核心的执行部件:CUDA Cores。
简单来说,CUDA Core 是 SM 内负责通用数值计算的基础执行单元。它承担整数和浮点算术、比较、逻辑与类型转换等最常见的线程级操作,是 GPU 通用计算能力的基本来源。
在执行时,一个 warp 中的 32 个线程会在 SIMT 模型下并行推进,同一条指令会分发到多个 CUDA Cores 上执行。因此,从软件视角看,CUDA Core 不只是在做“单个标量运算”,而是在 warp 级并行中支撑起整个通用计算数据通路。早期 GPU 上的矩阵计算,本质上也是将矩阵乘法拆成大量标量乘加,再由许多 CUDA Cores 协同完成;而在后续架构中,像高吞吐矩阵乘加这样的工作负载,则进一步演进到由专门的 Tensor Core 承担。
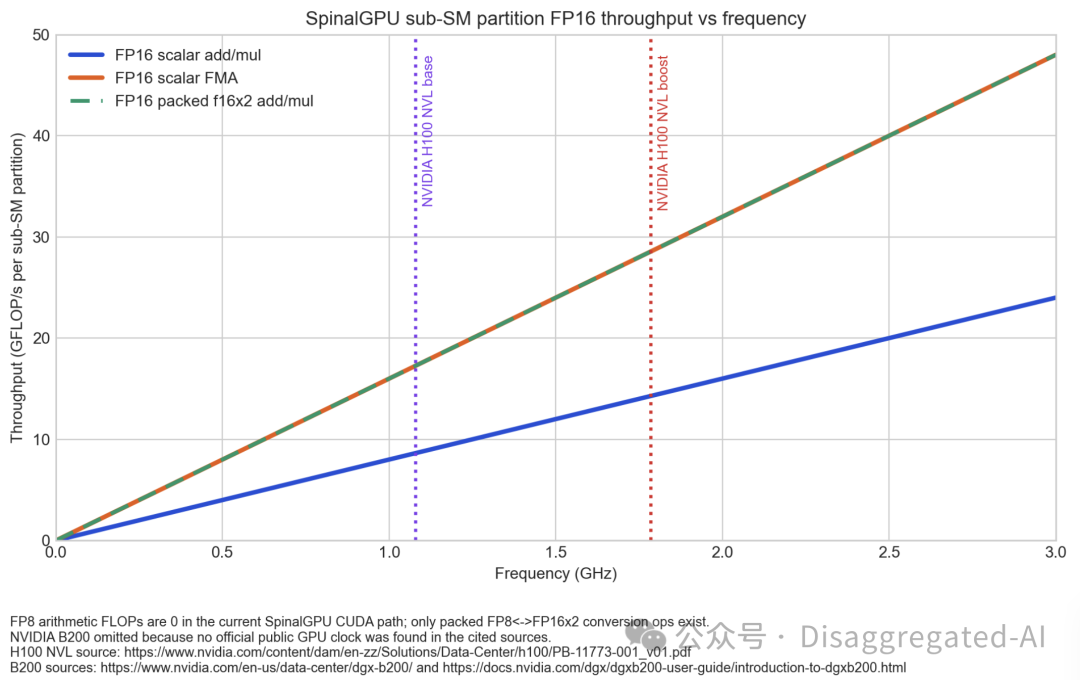
// SpinalGPU written in SpinalHDL Language.private def opResult(opcode: Bits, operandA: Bits, operandB: Bits, operandC: Bits): Bits = {..switch(opcode) {..is(B(Opcode.FADD, 8 bits)) {result := Fp32Math.add(operandA, operandB).asUInt}is(B(Opcode.FMUL, 8 bits)) {result := Fp32Math.mul(operandA, operandB).asUInt}..is(B(Opcode.HADD, 8 bits)) {result := Fp16Math.add(operandA(15 downto 0), operandB(15 downto 0)).asUInt.resize(config.dataWidth)}is(B(Opcode.HMUL, 8 bits)) {result := Fp16Math.mul(operandA(15 downto 0), operandB(15 downto 0)).asUInt.resize(config.dataWidth)}..is(B(Opcode.CVTF16X2E4M3X2, 8 bits)) {result := Fp8Format.e4m3x2ToF16x2(operandA(15 downto 0)).asUInt.resize(config.dataWidth)}is(B(Opcode.CVTF16X2E5M2X2, 8 bits)) {result := Fp8Format.e5m2x2ToF16x2(operandA(15 downto 0)).asUInt.resize(config.dataWidth)}..}result.asBits}
Load / Store- ld: loads data from .param, .global, or .shared into registers, so it is the main read path for kernel inputs and intermediate data.- st: stores register data back to .global or .shared, so it is the main write path for results.- mov: copies values between registers or materializes special values, so it is the basic data-shuffling/setup instruction.- cvt: converts between supported numeric formats, mainly for f16, f32, and packed FP8 teaching paths.Scalar Floating Point- add / sub: do basic floating-point arithmetic on scalar values.- mul: does scalar floating-point multiplication.- fma: does multiply-accumulate work and is the core math op in many matrix-style kernels.- neg / abs: apply simple unary FP transforms like sign flip and absolute value.- setp: compares floating-point values and produces predicates.- selp: picks between floating-point values without branching.- min / max: support clamp-style floating-point selection.Vector- mov.v2/v4: moves tuple-style vector data between FP registers, mainly for float2/float4 teaching kernels.- ld.v2/v4 / st.v2/v4: load or store tuple-style vector data from global memory, but the frontend lowers them into repeated scalar ops.- Packed add / mul on f16x2: operate on two packed half values in one register, which is the closest thing to native packed vector arithmetic today.Matrix- No dedicated matrix PTX instruction family exists yet, so matrix kernels are built from scalar mov, ld/st, add, mul, fma, setp, and bra.- No mma, wmma, or tensor PTX is exposed, so “matrix” here means matrix-shaped indexing and accumulation, not special tensor instructions.Control- bra: jumps to a label, including predicated forms, so it provides the current subset’s control flow.- ret: exits the kernel, not a full PTX function-call return model.- trap: intentionally raises a runtime fault for negative tests and fault handling.
|
|
完成了 CUDA Core 后,下一步自然是 Tensor Core。
__global__ void gemm_cuda_core(const float* A,const float* B,float* C,int M, int N, int K) {int row = blockIdx.y * blockDim.y + threadIdx.y;int col = blockIdx.x * blockDim.x + threadIdx.x;if (row < M && col < N) {float acc = 0.0f;for (int k = 0; k < K; ++k) {acc += A[row * K + k] * B[k * N + col];}C[row * N + col] = acc;}}
LOOP:ld.global.f32 %f1, [A...]ld.global.f32 %f2, [B...]fma.rn.f32 %f0, %f1, %f2, %f0 // 标量乘bra LOOP
__global__ void gemm_tensor_core(const half* A,const half* B,float* C,int M, int N, int K) {int tile_m = blockIdx.y * 16;int tile_n = blockIdx.x * 16;if (tile_m >= M || tile_n >= N) return;wmma::fragment<wmma::matrix_a, 16, 16, 16, half, wmma::row_major> a_frag;wmma::fragment<wmma::matrix_b, 16, 16, 16, half, wmma::row_major> b_frag;wmma::fragment<wmma::accumulator, 16, 16, 16, float> c_frag;wmma::fill_fragment(c_frag, 0.0f);for (int k = 0; k < K; k += 16) {wmma::load_matrix_sync(a_frag, A + tile_m * K + k, K);wmma::load_matrix_sync(b_frag, B + k * N + tile_n, N);wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);}wmma::store_matrix_sync(C + tile_m * N + tile_n, c_frag, N, wmma::mem_row_major);}
ldmatrix... // 加载矩阵mma.sync.aligned.... // 计算stmatrix... // 保存矩阵
https://github.com/lastweek/SpinalGPU/blob/main/src/main/scala/spinalgpu/TensorCoreBlock.scala
|
|
完成 CUDA Core 和 Tensor Core 之后,剩下的就是 SM 中的 Special Function Unit (SFU),负责一些特殊的数学计算(Tensor Core 和 SFU 都是 special 的..)。SFU 负责的一些常用数学计算有:
-
sqrt.approx.f32 — fast approximate square root for positive FP32 inputs.
-
rsqrt.approx.f32 — fast approximate reciprocal square root, common in normalization code.
-
sin.approx.f32 — fast approximate sine for FP32 inputs.
-
cos.approx.f32 — fast approximate cosine for FP32 inputs.
-
lg2.approx.f32 — fast approximate base-2 logarithm.
-
ex2.approx.f32 — fast approximate base-2 exponential, useful as a building block for exp-like math
-
...
这些都是用 CUDA Core 实现性能开销大,但用专有硬件实现代价小收益高的数值运算。
|
|
我们使用 Codex vibe 了 SpinalGPU,一个模仿英伟达 GPU 的学习项目。SpinalGPU 使用高级编程语言 SpinalHDL 完成,硬件代码逻辑清晰、组件化、可快速仿真。
-- 完 --