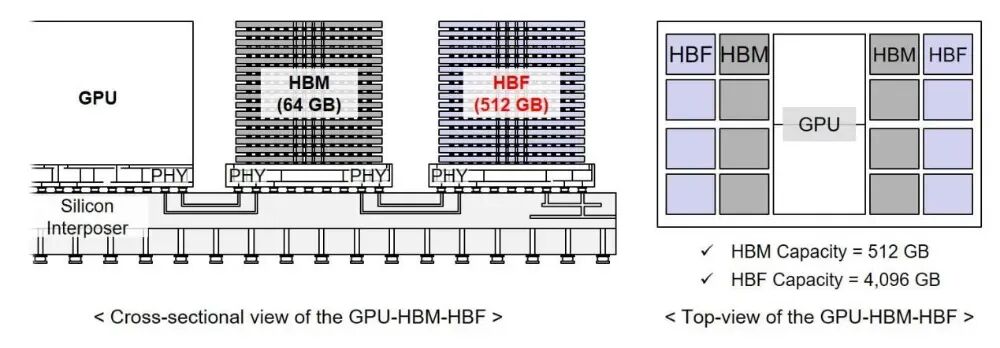
电子发烧友网报道(文/梁浩斌)“主板插显卡上”,是PC DIY玩家对高性能显卡体积越来越大的调侃,随着显卡功率越来越高,硕大的散热模组让显卡投影面积甚至已经大于ITX规格的主板,在PC里显卡取代了主板和CPU成为了主角。 而最近“HBM之父”金正浩教授也语出惊人,提出未来内存将成为主角:“GPU和CPU将会被集成到内存(HBM和HBF)里,沦为内存中的一个组件”。 倒反天罡,在内存里装GPU? 目前AI计算的架构以GPU为主导,核心计算单元是配备HBM的GPU,比如英伟达的Blackwell架构GPU,配备HBM3e内存,通过NVLink、NVSwitch等实现GPU间高速通信,形成比如NVL72等的机架级计算系统。 不过英伟达在Vera Rubin平台中,也展现出强烈的异构计算趋势,AI计算不再单纯依赖GPU,而是通过多芯片协同工作实现更高效的计算。Vera Rubin平台中,除了Rubin GPU之外,还有Vera CPU、Groq 3 LPU、NVLink 6 Switch、ConnectX-9 SuperNIC、BlueField-4 DPU等多种处理单元协同工作。 但异构计算或许也不是未来?金正浩预言,AI时代的最终赢家不是GPU,而是内存,目前以英伟达GPU为中心的AI计算架构,将会完全转向以内存为中心的架构。 “现在GPU或CPU是计算的中心。但今后,拥有庞大容量的HBM和HBF将成为中心,反而是GPU被装进其中的‘内存中心计算(Memory-Centric Computing)’时代将会到来。GPU和CPU沦为零部件的那个时刻,要想引领这一范式,HBF必须成为其基础。”他解释称,当前AI面临的幻觉问题,本质上是硬件瓶颈造成的。 当前业界正在从生成式AI转向代理式AI(Agentic AI),这个过程中内存瓶颈正在成为最大的难题。海量上下文需要同样大规模的内存,要真正实现快速、准确处理代理式AI的超长上下文数据,内存带宽和容量都需要比现在增加1000倍以上。同时,金正浩认为大模型的幻觉本质上也是内存问题,因为内存不足,只能根据已知内容回答,才会产生幻觉。 HBM在最近几年AI芯片热潮中已经成为了焦点,这是为了解决内存带宽瓶颈而诞生的一种DRAM技术,核心原理是将多个DRAM芯片进行垂直堆叠,通过TSV技术进行互连,带宽可以是传统内存的数十倍。 而HBF就较为陌生了,金正浩认为,仅靠HBM难以满足代理式AI的需求,HBM是为了快速回答而堆放在书桌旁的浅薄参考书,即短期记忆。而下一代的替代方案则是HBF高带宽闪存,HBF是用NAND闪存代替DRAM进行堆叠,大幅提升容量的巨大书架,即长期记忆。 GPU-HBM-HBF架构 图源:KAIST Terra Lab 具体来说,HBF核心思路是用HBM的封装技术来对NAND FLASH进行改造,包括3D堆叠、TSV、高并行接口等。根据目前业界多家厂商给出的技术指标,HBF的带宽可高达1.6TB/s,是传统PCIe4.0 SSD的200倍以上,基本达到了HBM3的带宽水平,但低于HBM4。 在容量上,HBF单堆栈能达到512GB,8 堆栈可至4TB,可支撑万亿参数模型本地加载,相比不HBM有显著的优势。当然,缺点是写入和耐久性都不如HBM,因此HBF主要适用于读取密集型AI推理任务;另外延迟也相比HBM更高,HBF的延迟约5μs,而HBM仅为100ns。 所以综合来看,HBF的定位可以看做是解决HBM容量不足和SSD速度太慢的存储产品,适用于储存模型权重、长文本、特征库等“温/冷数据”,而HBM则专注于频繁读写的“热数据”。 金正浩是是韩国科学技术院(KAIST)电气及电子工程系教授,同时是TERALAB负责人,被业界广泛誉为“HBM之父”。研究领域专注于专注于信号完整性、电源完整性、电磁兼容、3D/2.5D集成电路封装、TSV、硅中介层等先进封装技术,以及AI半导体内存架构。 其负责的TERALAB在HBM设计技术领域全球领先超过20年,自2010年起直接参与HBM的商业化设计,与三星电子、SK海力士、Google、NVIDIA、Apple、Tesla等全球巨头有深度合作。他主导了HBM从概念到实际产品的关键技术突破,包括TSV、互连优化、信号/电源设计等。 SK海力士、闪迪推动HBF标准化,2026推首批样品 得益于AI算力需求的爆发增长,HBF的产业化进程非常快,从学术提出到标准化启动,仅用了不到两年时间。在2025年6月,KAIST TERALab在HBM路线图Ver 1.7研讨会上首次系统介绍HBF架构,提出“HBM-HBF-存储网络”分层设计。 2025年底至2026年初,金教授多次在媒体和研讨会上发布HBF路线图和工作负载分析,强调HBF可将AI推理性能/瓦特提升至纯HBM配置的2.69倍,并在Llama 3.1 405B等模型上仅损失2.2%性能。 在2025年8月,闪迪和SK海力士签署谅解备忘录,正式启动HBF规格制定、技术要求定义和生态构建。闪迪也明确目标,在2026下半年交付首批HBF内存样品,2027年初首批搭载HBF的AI推理设备进入采样阶段。 今年2月25日,双方在美国加州米尔皮塔斯的闪迪总部联合举办“HBF规格标准化联盟启动会”。宣布在Open Compute Project (OCP) 框架下成立专用工作组,推动HBF全球开放标准化,这是HBF从双边合作转向行业生态的关键一步。 三星尽管未有直接参与标准化联盟,但已经独立切入HBF的赛道中,据披露,三星在去年10月开始启动概念设计与早期研发,积累多项HBF相关专利。凭借NAND市场份额领先和代工/逻辑工艺优势,三星正探索独特架构路径,其目标是2027年实现商用产品的推出。 根据金教授预测,HBF将在2027年开始小规模商用部署,导入到谷歌、英伟达、AMD等AI芯片中;2030年HBF将大规模普及,预计到2038年HBF市场可能超越HBM,成为AI存储的主力。 小结 HBF的产业化,不仅是填补了HBM和NAND FLASH之间的存储空缺,更是标志着AI算力硬件从算力芯片为中心,从GPU到异构架构之后,逐步向内存为中心加速转型,重塑AI服务器架构。不过,GPU是不是真的会沦为内存的“配件”,还不太好说,但至少在未来AI Agent的时代,存储芯片的地位将更加重要。