本周四晚,谷歌开源了当前开源世界最强的模型家族 Gemma 4 系列。
基于和 Gemini 3 相同的研究成果,新模型在 Arena AI 排行榜上拿到了全球第三的位置,而且超越了参数量比它大 20 倍的模型。更重要的是,这一代 Gemma 使用 Apache 2.0 开源许可证,可实现完全的商用自由。

Gemma 4 是 Google DeepMind 构建的最新开放模型系列,它们是多模态模型,用于处理文本和图片输入(小型模型支持音频输入)以及生成文本输出。此版本包含预训练和指令调优的开放权重模型。Gemma 4 的上下文窗口最多可容纳 25.6 万 token,并支持 140 多种语言。
谷歌表示,Gemma 4 同时采用密集型架构和混合专家 (MoE) 架构,非常适合文本生成、编码和推理等任务。这些模型有四种不同的规模:E2B、E4B、26B A4B 和 31B。这些模型的大小各异,因此可部署在从高端手机到笔记本电脑和服务器的各种环境中,从而让更多人能够使用最先进的 AI。
其中,体量最大的 31B 版本使用一块 80GB H100 就能实现完整精度推理,可见其能力水平已经与 Qwen 3.5 397B 相当了。

体量最小的 E4B 和 E2B 专为手机、平板等端侧设备本地推理设计,谷歌也与高通、联发科进行了联合优化。

总的来说,Gemma 4 引入的功能和架构改进包括:
推理 - 该系列中的所有模型都设计为高能力推理器,具有可配置的思考模式。
扩展的多模态功能 - 处理文本、支持可变宽高比和分辨率的图片(所有型号)、视频和音频(在 E2B 和 E4B 型号上原生支持)。
多样化且高效的架构 - 提供不同大小的密集型和混合专家 (MoE) 变体,以实现可伸缩的部署。
针对设备端进行了优化 - 较小的模型专为在笔记本电脑和移动设备上高效本地执行而设计。
更大的上下文窗口 - 小型模型的上下文窗口为 12.8 万个 token,中型模型的上下文窗口为 25.6 万个 token。
增强的编码和智能体功能 - 在编码基准方面取得了显著改进,同时支持原生函数调用,可打造功能强大的自主代理。
原生系统提示支持 - Gemma 4 引入了对 system 角色的原生支持,从而实现更结构化和可控的对话。
模型概览
Gemma 4 模型旨在在各种规模下提供前沿性能,目标部署场景涵盖移动设备和边缘设备 (E2B、E4B) 到消费类 GPU 和工作站 (26B A4B、31B)。它们非常适合推理、智能体工作流、编码和多模态理解。
这些模型采用混合注意力机制,将局部滑动窗口注意力和全局注意力交织在一起,确保最后一层始终是全局的。这种混合设计可提供轻量级模型的处理速度和低内存占用空间,同时不会牺牲复杂长上下文任务所需的深度感知能力。为了优化长上下文的内存,全局层采用统一的键和值,并应用比例 RoPE (p-RoPE)。

E2B 和 E4B 中的「E」表示「有效」形参。较小的模型采用 Per-Layer Embeddings (PLE),以最大限度提高设备端部署中的参数效率。PLE 不会向模型添加更多层或参数,而是为每个词法单元的每个解码器层提供自己的小型嵌入。这些嵌入表很大,但仅用于快速查找,因此激活参数的数量远小于总数。

26B A4B 中的「A」表示「有效参数」,与模型包含的参数总数相对。通过在推理期间仅激活 40 亿个参数子集,混合专家模型运行速度比其 260 亿个总参数所暗示的速度快得多。与密集型 310 亿参数模型相比,该模型几乎与 40 亿参数模型一样快,因此是快速推理的绝佳选择。
谷歌展示了一些 Gemma 4 的模型能力,比如测试它检测和指向 GUI 元素的能力:「图像中查看配方元素的边界框是什么?」
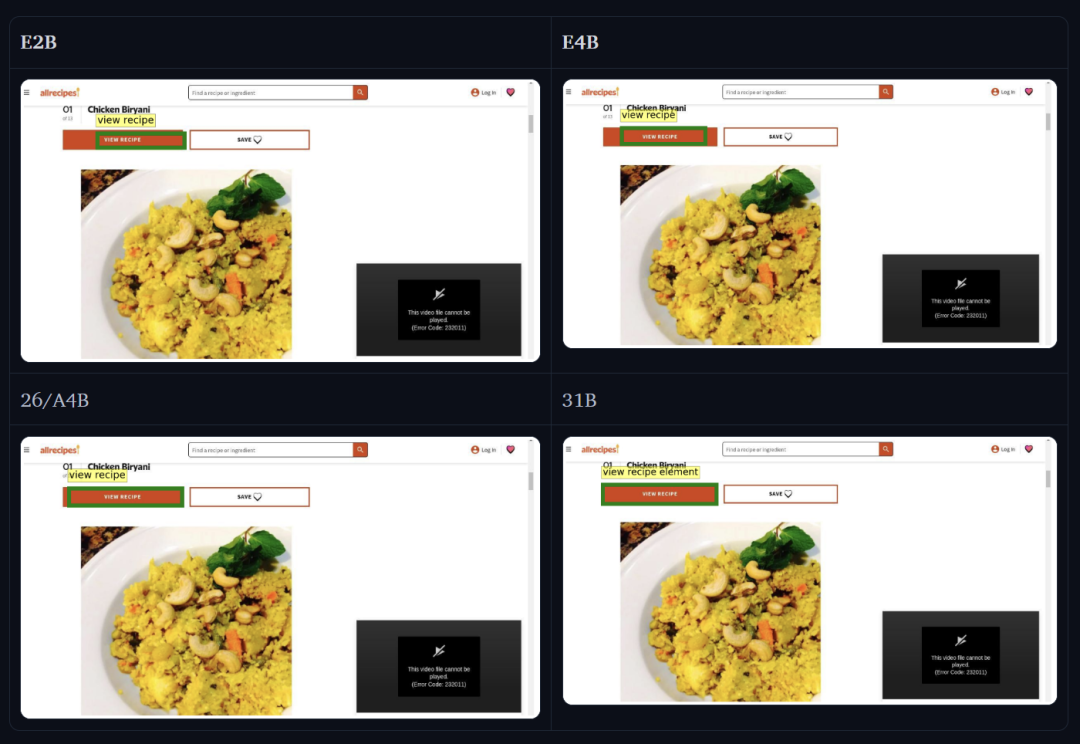
检测日常物体:

如果要求 Gemma 4 编写 HTML 代码来重建用 Gemini 3 创建的页面,Gemini 生成的网站是这样的:
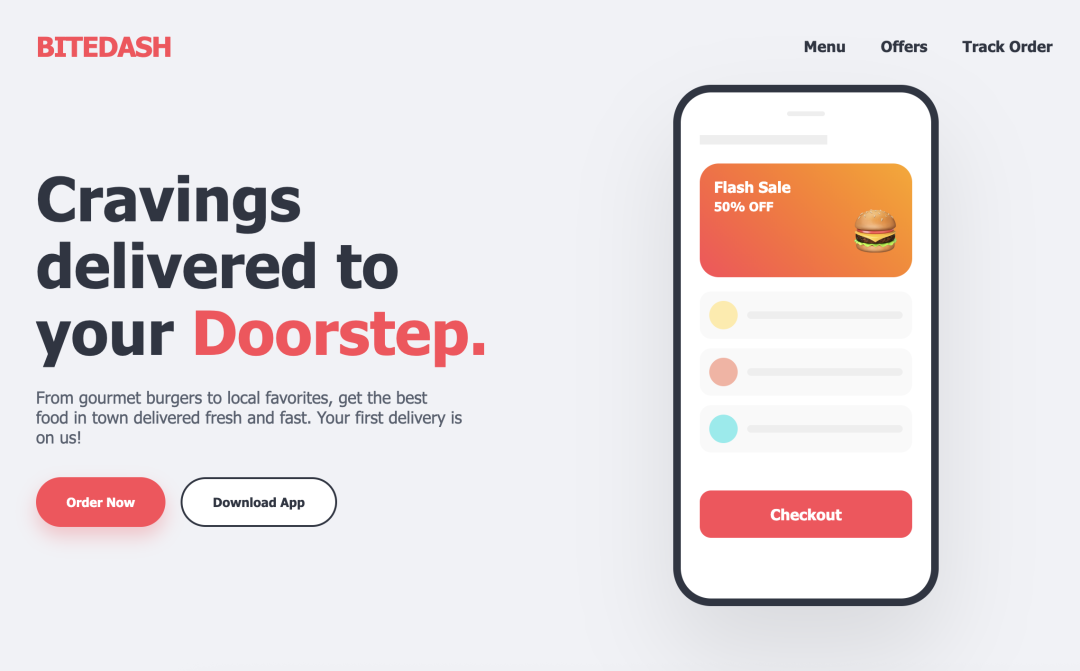
Gemma 4 重建的页面:
参数大小和量化
Gemma 4 模型提供 4 种参数大小:E2B、E4B、31B 和 26B A4B。 这些模型可以采用默认精度(16 位),也可以通过量化采用较低的精度。不同的尺寸和精度代表着 AI 应用的一系列权衡。参数和位数(精度)较高的模型通常功能更强大,但在处理周期、内存成本和功耗方面运行成本更高。参数和位数(精度)较低的模型功能较少,但可能足以满足您的 AI 任务的需求。
Gemma 4 推理内存要求
下表详细列出了使用各种大小的 Gemma 4 模型版本运行推理所需的大致 GPU 或 TPU 内存。

表 1. 加载 Gemma 4 模型所需的大致 GPU 或 TPU 内存,具体取决于参数数量和量化级别。
内存规划的行动要点
高效架构(E2B 和 E4B): 「E」代表「有效」参数。较小的模型采用每层嵌入 (PLE) 技术,以最大限度地提高设备端部署中的参数效率。PLE 不会向模型添加更多层,而是为每个词法单元的每个解码器层提供自己的小型嵌入。这些嵌入表很大,但仅用于快速查找,因此加载静态权重所需的总内存高于有效参数数量所暗示的内存。
MoE 架构(26B A4B): 26B 是混合专家模型。虽然在生成期间每个词法单元仅激活 40 亿个参数,但所有 260 亿个参数 都必须加载到内存中,以保持快速路由和推理速度。因此,其基准内存要求比 4B 模型更接近于密集型 26B 模型。
仅基准权重: 上表中的估算值 仅 考虑了加载静态模型权重所需的内存。它们不包括支持软件或上下文窗口所需的额外 VRAM。
上下文窗口(KV 缓存): 内存消耗将根据提示和生成的响应中的词法单元总数动态增加。除了基准模型权重之外,更大的上下文窗口还需要显著更多的 VRAM。
微调开销: 微调 Gemma 模型的内存要求远高于标准推理。您的确切占用空间将很大程度上取决于开发框架、批次大小,以及您是使用全精度调优还是使用参数高效微调 (PEFT) 方法(例如低秩适应 (LoRA))。
基准测试结果
我们针对大量不同的数据集和指标对这些模型进行了评估,以涵盖文本生成的各个方面。表格中标记的评估结果适用于指令调优模型。

核心功能
Gemma 4 模型可处理文本、视觉和音频方面的各种任务。主要功能包括:
思考 - 内置推理模式,可让模型在回答之前进行分步思考。
长上下文 - 上下文窗口最多可容纳 12.8 万个 token (E2B/E4B) 和 25.6 万个 token (26B A4B/31B)。
图片理解 - 对象检测、文档 / PDF 解析、屏幕和界面理解、图表理解、OCR(包括多语言)、手写识别和视觉定位。可以处理具有不同宽高比和分辨率的图片。
视频理解 - 通过处理帧序列来分析视频。
交织的多模态输入 - 在单个提示中,可以按任意顺序自由混合文本和图片。
函数调用 - 原生支持结构化工具使用,可实现智能体工作流。
编码 - 代码生成、补全和更正。
多语言 - 开箱即用,支持 35 种以上的语言,预训练了 140 种以上的语言。
音频(仅限 E2B 和 E4B)- 自动语音识别 (ASR) 和语音转译文翻译(支持多种语言)。
训练数据集
谷歌使用的预训练数据集是一个大规模、多样化的数据集合,涵盖广泛的领域和模态,包括网页文档、代码、图片、音频,截止日期为 2025 年 1 月。以下是关键组成部分:
网页文档:各种各样的网页文本可确保模型接触到广泛的语言风格、主题和词汇。训练数据集包含 140 多种语言的内容。
代码:让模型接触代码有助于其学习编程语言的语法和模式,从而提高其生成代码和理解代码相关问题的能力。
数学:通过数学文本训练,模型可以学习逻辑推理、符号表示,并能够回答数学问题。
图片:各种各样的图片可让模型执行图片分析和视觉数据提取任务。
这些多样化数据源的组合对于训练强大的模型至关重要,该模型能够处理各种不同的任务和数据格式。
数据预处理
以下是应用于训练数据的主要数据清理和过滤方法:
CSAM 过滤:在数据准备流程的多个阶段应用了严格的 CSAM(儿童性虐待内容)过滤,以确保排除有害和非法内容。
敏感数据过滤:为了确保 Gemma 预训练模型的安全性和可靠性,谷歌使用了自动化技术来过滤掉训练集中的某些个人信息和其他敏感数据。
其他方法:根据内容质量和安全性进行过滤。
参考内容:
https://deepmind.google/models/gemma/gemma-4/
https://x.com/Google/status/2039736220834480233
https://huggingface.co/blog/gemma4

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com