在当今由大语言模型驱动的多智能体世界中,无论是复杂的代码生成、智能搜索还是社会仿真模拟,我们常常看到数十甚至上百个智能体协同工作的场景。这些智能体在虚拟环境中交流、协作、竞争,共同推进任务的完成。然而,在这看似智能的背后,一个严峻的技术挑战正悄然浮现:支撑这些智能体运行的计算资源,尤其是宝贵的GPU内存,正随着智能体数量的增加而迅速耗尽。
问题的根源在于一个被忽视的“重复建设”现象。在多智能体系统中,智能体的执行通常被组织成同步的“轮次”。每一轮中,所有智能体产生输出,一个中央调度器收集这些输出,然后将整合后的上下文分发给每一个智能体,作为下一轮推理的输入。这个模式在分布式计算中被称为“All-Gather”模式。它带来了一个严重的副作用:每个智能体的提示词中都包含了上一轮所有其他智能体的输出(共享块),但由于每个智能体自身的历史记录(私有块)长度不同,这些相同的共享块在不同智能体的提示词中处于完全不同的位置。对于现有的大模型服务系统而言,它们看到的只是扁平的令牌序列,无法识别出这些内容相同但位置不同的“共享块”,结果就是为每个智能体都单独计算并存储了一份近乎相同的键值缓存,造成了巨大的内存冗余。
这种冗余直接限制了系统能同时支持的智能体数量。当开发者试图在单个GPU上运行更多智能体以模拟更复杂的社会交互时,很快就会撞上内存的“天花板”,导致服务延迟飙升,甚至系统崩溃。
最近,来自北京大学和上海交通大学的研究团队注意到了这一核心矛盾,并提出了一个名为 TokenDance 的创新系统。
TokenDance 的核心思想是:既然多智能体应用天然以“轮次”为单位进行组织,且同一轮内的智能体共享大量上下文,那么服务系统的优化单元也应当从“单个请求”提升到“整个轮次”。通过集体共享KV缓存,TokenDance 旨在显著降低每个新增智能体带来的计算开销和存储成本,从而在同等硬件条件下,支持更多智能体并发运行。

论文标题: TokenDance: Scaling Multi-Agent LLM Serving via Collective KV Cache Sharing
论文链接: https://arxiv.org/pdf/2604.03143
理解多智能体服务的“内存之痛”
为了直观理解这个问题,我们可以看一组对比数据。在一个80GB显存的A100 GPU上运行Qwen2.5-14B模型,服务包含250个子请求的多智能体会话时,KV缓存占用了高达41.5 GiB的显存,几乎耗尽了缓存池。而作为对比,服务250个完全独立的单请求,KV缓存仅占用24.8 GiB。多智能体场景下的内存占用高出近70% 。

图1:多智能体与独立工作负载在单A100 GPU上的子请求延迟对比。多智能体工作负载由于缓存共存,从一开始就面临高延迟。

图2:两种工作负载的峰值KV缓存使用量对比。多智能体工作负载因需跨轮次保留每个智能体的缓存副本,几乎耗尽缓存池。
这种差异的根源在于,独立请求在完成后会立即释放其KV缓存,而多智能体应用中的智能体状态需要在整个交互过程中持续保留在内存中。当大量近乎相同的缓存副本共存时,内存池迅速饱和,迫使调度器进行频繁的换入换出操作,严重拖慢整体速度。
现有的大模型服务系统为何无法解决这个问题?它们主要分为两类:
面向智能体的调度器:如 Parrot、Autellix 等,它们优化的是子请求的执行时机和卸载策略,但底层仍然将每个智能体的KV缓存视为独立对象进行管理。 以KV缓存为中心、但无视智能体的引擎:如 vLLM、SGLang 采用的前缀缓存,只能在请求共享完全相同的开头部分时生效,一旦私有历史导致前缀不同,共享便失效。而 CacheBlend、EPIC 等位置无关缓存方法虽然能跨位置重用缓存块,但它们仍然独立处理每个请求。对于N个智能体的一轮,同一组共享块会触发N次独立的重用分析过程,计算开销线性增长。
更重要的是,即使缓存块被成功重用,系统仍然会为每个智能体存储一份完整的、密集的KV缓存副本。研究表明,在一轮8个智能体的交互中,不同智能体缓存块之间的相似度高达91%到97%。这意味着,存储多份副本造成了巨大的内存浪费。
 图3(左):KV缓存存在高度的结构重叠。(右):经过位置无关缓存重用后,KV缓存块的成对相似度测量结果。
图3(左):KV缓存存在高度的结构重叠。(右):经过位置无关缓存重用后,KV缓存块的成对相似度测量结果。
TokenDance的设计哲学:从“单打独斗”到“集体协作”
TokenDance 的设计遵循两个核心原则:第一,让“轮次”结构对运行时系统可见,直到系统能够利用它为止;第二,在保持每个请求缓存状态正确性的前提下,尽可能共享轮次内真正共通的工作和状态。
基于此,TokenDance 构建了三个核心组件来实现其目标:
轮次感知的提示词接口:让系统能“看见”块边界。 集体KV缓存重用算法:将重用开销分摊到整个轮次。 差异感知的存储方案:只存储智能体间的差异部分。
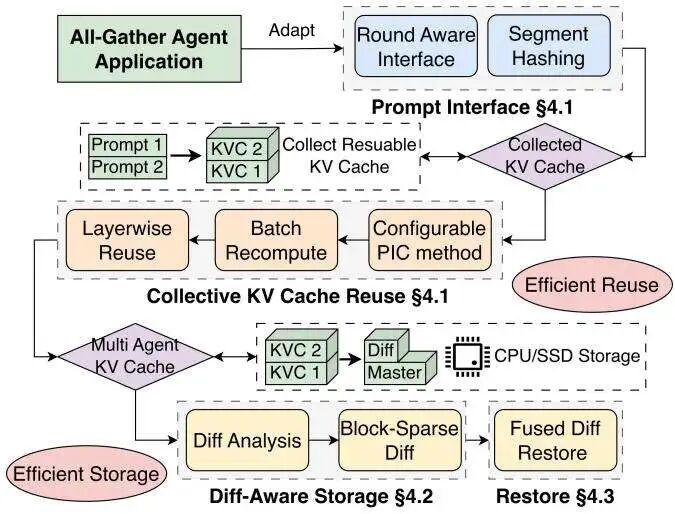
图4:TokenDance 系统概览。
1. 让系统“看见”结构:轮次感知提示词接口
如果运行时系统只能接收到扁平的令牌流,那么它永远无法识别出共享块。TokenDance 要求多智能体框架在组装每个智能体的提示词时,在相邻的逻辑块(如私有历史、每个共享的输出块)之间插入一个保留的分隔符令牌(如 <TTSEP>)。

图5:TokenDance轮次感知提示词接口示例。分隔符令牌明确了块边界。
这样一来,运行时系统就能从基于固定大小块的哈希,切换到基于段的哈希。每个共享更新块由其内容本身索引,而不是由它在长提示词中的绝对位置索引。因此,包含相同共享块的两个请求会将该块映射到同一个缓存对象,即使它们的私有历史长度不同。这是将All-Gather模式转化为服务优化的第一步。
2. 分摊计算开销:集体KV缓存重用
当轮次结构可见后,下一个要解决的问题是重复的重用计算工作。现有的位置无关缓存方法虽然能跨前缀重用,但仍独立处理每个请求。在N个智能体的一轮中,运行时要为同一组共享块执行N次独立的重用过程(包括RoPE旋转、关键位置差异计算等),而这些操作的结果在不同请求间几乎是相同的。
TokenDance 通过 集体KV缓存重用 来解决这一冗余。其核心组件 KV收集器 会将同一轮次内、提示词跨度兼容的请求分组。对于每个兼容组,运行时以锁步的方式驱动逐层的检索和模型执行。

图6:集体KV缓存重用示意图。T3路径将多个请求分组,共享RoPE和关键位置选择工作,只需支付一次重用开销。
具体来说,在每一层,KV收集器将所有请求的Q和K张量拼接成一个组合张量,并执行一次批处理的RoPE调用。在设定的检查层,运行时通过一次批处理的差异计算,同时识别出每个请求的“关键位置”(即缓存值与新计算值显著不同的令牌位置)。随后,运行时仅刷新每个请求缓存K/V张量中的这些关键位置。
昂贵的操作(RoPE旋转和关键差异分析)因此只需为整个组执行一次,而非每个请求一次。只有最终的缓存更新是请求特定的。当一轮中的智能体数量增加时,这种分摊机制显著降低了每轮的总重用工作量,这是实现计算侧性能提升的关键。
3. 压缩存储成本:差异感知存储与融合恢复
集体重用减少了冗余计算,但并未消除冗余存储。重用完成后,系统仍为每个请求保存一份密集的KV缓存。TokenDance 采用 主-镜像 布局来压缩每轮的缓存家族。

图7:采用主-镜像布局的差异感知存储。只存储一个完整的主缓存,其余缓存仅存储与主缓存差异的部分(稀疏差异)。
系统保存一个密集缓存作为“主缓存”,而将其余每个缓存存储为仅包含与主缓存差异的“镜像”。差异以块稀疏的K/V差异形式存储。由于差异通常集中在对应于私有历史段或共享块边界区域的连续块中,这种块粒度的表示能以较低的元数据成本捕获这种聚集性。
读取时,存储层并不急于重建一个密集的镜像张量,而是返回一个轻量级的镜像对象,其中包含对主缓存的引用和稀疏差异元数据。这为调用者保留了标准的逻辑KV缓存抽象,同时将具体化延迟到运行时真正需要数据之时。
然而,压缩只有在恢复过程足够高效时才有意义。TokenDance 通过 融合差异恢复 路径消除了额外的开销。它不是在恢复时先加载完整主缓存、复制到新缓冲区、再覆盖差异块,而是将稀疏修正内嵌到本就存在的、逐层将缓存数据移入分页GPU内存的传输路径中。

图8:块粒度的融合差异恢复。带有差异的块在SM内存中修正后再参与注意力计算,无差异的块则直接进入注意力计算。
两个GPU缓冲区以乒乓方式交替工作:一个从存储中接收主缓存块,另一个则进行原地修正并写回。在每个层,该路径应用块稀疏差异,恢复RoPE位置,并将结果写入分页KV缓存内存——所有这些都在普通缓存加载 already 执行的同一流程中完成。从未物化过一个单独的密集镜像。
性能评估:能支持多少智能体?
研究团队在 NVIDIA A100 80GB GPU 上,使用 Qwen2.5-7B 和 Qwen2.5-14B 模型,对来自 GenerativeAgents 和 AgentSociety 两个代表性多智能体框架的轨迹进行了评估。对比基线包括:带前缀缓存的 vLLM、不带恢复的 CacheBlend 以及带完整逐请求恢复的 CacheBlend。
核心评估问题是:在相同的延迟目标或每秒查询数目标下,每个系统能支持多少智能体?

图9:跨两种工作负载和两种模型的扩展能力概览。TokenDance(橙色)在全部QPS范围内持续支持比所有基线更多的智能体。
结果显示,TokenDance 在所有配置和智能体数量下都实现了最低的轮次延迟。例如,在 GenerativeAgents / Qwen2.5-7B 配置下,当 QPS=16 时,TokenDance 能支持8个智能体,而 CacheBlend 降至4个,vLLM 降至2个。对于更大的14B模型,优势更加明显:TokenDance 的存储优势直接将模型尺寸增加带来的缓存压力抵消了。
那么性能提升从何而来?
计算侧:集体重用分摊了开销。实验显示,在10个智能体、低QPS情况下,集体重用相比串行处理带来了最高2.57倍的预填充加速。 内存侧:差异感知存储大幅降低了缓存占用。对于14B模型,镜像缓存被压缩到完整缓存的约6%,实现了高达17.5倍的压缩比。这意味着10个智能体的KV缓存内存成本从10份完整缓存减少到约1.5份,减少了6.7倍。 恢复路径:融合差异恢复确保了压缩带来的收益不会在在线服务时被重建延迟抵消。相比简单的密集重建,融合恢复路径将镜像状态重建延迟降低了1.3到2.6倍。

图10:集体KV缓存重用相对于串行处理的加速比。

图11:KV缓存冗余特征分析。14B模型因每令牌缓存张量更大,而差异块数量相似,获得了更高的压缩比。
在准确性方面,TokenDance 的集体路径和主-镜像存储产生的输出,与底层位置无关缓存方法逐请求应用时的输出相同。评估显示,其输出差异完全源于底层缓存方法引入的微小数值扰动,TokenDance 本身并未引入额外的精度损失。
总结与展望
TokenDance 通过将优化单元从单个请求提升到整个多智能体轮次,巧妙地利用 All-Gather 通信模式中固有的结构相似性,同时攻克了KV缓存冗余在计算和存储两方面的挑战。集体重用算法避免了N次重复分析,差异感知存储则将N份密集缓存压缩为一份主缓存加N-1份稀疏差异。最终,在同等硬件和延迟目标下,系统能支持的并发智能体数量提升了多达2.7倍。
这项工作更深远的意义在于,它揭示了将通信结构作为大模型服务中一等公民的重要性。All-Gather 模式只是一个起点,随着多智能体系统的多样化发展,其他重复出现的通信模式(如广播、散射-收集)很可能也蕴含着类似的优化机会。一个能够感知通信模式的服务栈,对于构建未来高效、可扩展的多智能体平台至关重要。
TokenDance 的实现基于 vLLM 和 LMCache,代码修改量约3500行,为社区探索更高效的多智能体服务架构提供了新的思路和实用的工具。
> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对
-- 完 --
机智流推荐阅读:
1.
2.
3.
4.
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 智能体 | Agent 技术交流群