UniT 是小鹏机器人联合清华大学、香港大学提出的跨具身统一表征框架,核心目标是解决人形机器人数据稀缺、人类–机器人运动学不匹配的行业难题。它以视觉作为通用物理锚点,通过统一离散隐空间将人类与机器人的异构动作映射为与躯体无关的物理意图,形成一套可同时用于机器人闭环控制与世界模型仿真的统一物理语言。
项目链接:https://xpeng-robotics.github.io/unit/

人形机器人学习的两大核心瓶颈
当前通用人形机器人的发展,被两个底层问题严重限制:
第一,机器人高质量演示数据极度稀缺,真机采集成本高、覆盖任务窄,难以支撑大模型规模化训练。
第二,人类与人形机器人在自由度、关节构型、控制空间上存在巨大差异,传统运动重定向(motion retargeting)依赖复杂运动学求解器,逐案例适配、不可扩展,且容易生成物理不可行的动作。

现有方法存在明显缺陷:仅依赖动作信息会出现严重的跨躯体分布偏移;仅依赖视觉信息容易被光照、背景、纹理干扰,丢失精细运动信号;多模态分开编码则无法形成真正统一的表示。在此背景下,UniT 提出最核心的洞察:
不同躯体的运动学结构不同,但物理意图带来的视觉结果是通用且一致的。
因此可以用视觉作为 “锚”,把人类和机器人的动作对齐到同一个共享隐空间,绕开运动学差异,直接实现人类→人形机器人的无重定向迁移。
UniT 核心设计:统一隐动作 Tokenizer
UniT 的全部能力建立在统一动作编码器(UniT Tokenizer) 之上,它以三分支结构为骨架,通过共享量化与双向交叉重构,把异构动作提炼为与躯体无关的离散物理意图符号。

三分支并行编码
UniT 同时处理三类信息,形成互补的视–动表示:
-
视觉分支:输入连续两帧画面,用预训练 DINOv2 提取帧间变化,作为跨躯体的通用物理参照; -
动作分支:输入状态与连续动作块,将人类、机器人格式不同的动作统一对齐后编码; -
融合分支:融合视觉与动作特征,输出更紧凑、鲁棒的统一表示。
三支特征会进入共享残差量化模块,把连续特征映射到离散空间,保证人类、机器人、视觉/动作/融合特征都使用同一套 “词汇”:
共享码本是实现跨躯体兼容的基础,它强制所有模态、所有躯体的动作最终落到同一套离散表示中。
双向交叉重构:视觉锚定的核心机制
UniT 最关键的创新是双向交叉重构,它让每一个符号同时满足 “可还原画面” 和 “可还原动作”,这也是论文最核心的设计:
这一机制带来两个关键效果:
动作被牢牢锚定在视觉结果上,不会因为人和机器人躯体不同而出现分布偏移;
视觉信息被过滤掉光照、背景等无关干扰,只保留和物理运动相关的部分。
在训练过程中,模型会不断优化交叉重构与量化损失,最终只保留视觉与动作的交集——与躯体无关的物理意图。
两大下游范式:VLA-UniT 与 WM-UniT
在统一 Tokenizer 之上,UniT 扩展出两套完整系统,分别对应具身智能两大核心方向。

策略学习 VLA-UniT
VLA-UniT 将统一物理意图融入视觉–语言–动作框架,用于机器人闭环控制。
模型不再直接预测复杂的机器人关节动作,而是先预测 UniT 提炼的统一符号,再用轻量级流匹配模块生成可执行动作。这种设计让模型不需要强行拟合人与机器人之间巨大的动作分布差异,只需要学习物理意图,因此泛化能力更强、数据效率更高。在训练时,视觉–语言模型根据画面与指令预测统一符号,再生成平滑连续的控制指令,整个流程天然支持人类数据迁移。
世界建模 WM-UniT
WM-UniT 将 UniT 符号作为世界模型的统一控制条件,用于动作可控的视频生成。
传统世界模型只能用机器人原始动作做条件,无法直接使用人类数据;而 WM-UniT 用统一符号替代躯体特定动作,让模型只关注物理意图,不关注动作来源。
因此模型可以在人类数据上学习物理规律,再直接迁移到人形机器人上,生成更可控、更符合物理规律的长时序画面,并支持自回归滚动推演。
核心实验结果
论文在RoboCasa GR1 仿真、IRON-R01 真机、EgoDex 人类数据集、DROID 数据集上做了全面验证,结果高度一致。

跨躯体表征对齐
图 7 是 UniT 有效性最直观的证明:
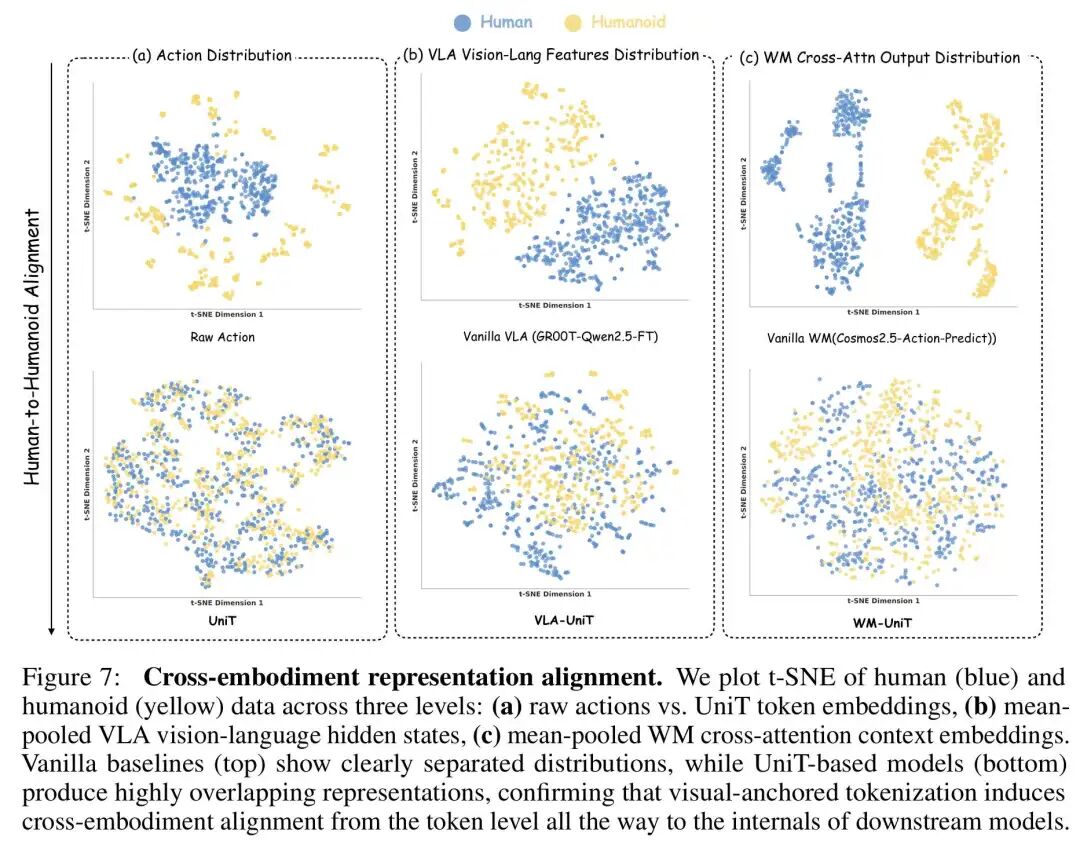
-
在原始动作空间中,人类与机器人数据呈现完全分离的两个集群; -
经过 UniT 编码后,两者高度重叠、无法区分,证明异构动作被成功映射到共享流形; -
这种对齐会传导到下游策略模型与世界模型内部,让整个系统从特征层面实现人与机器人统一。
动作噪声鲁棒性
真实人类动作数据普遍存在噪声,而 UniT 凭借视觉锚定展现出极强的去噪能力。

在同等噪声强度下,UniT 的重建误差远低于仅动作编码器与 FAST 方法,性能退化幅度仅为 1.7 倍,远优于对比方法。这意味着 UniT 可以直接使用大量未精细清洗的野外人类数据。
策略学习性能
在 RoboCasa 仿真完整数据下,VLA-UniT 整体成功率达到66.7%,超过 Diffusion Policy、GR00T 等全部主流基线。在少样本设置下,仅用 10% 数据即可达到传统方法全数据水平,数据效率提升近 10 倍。加入人类数据后,模型泛化能力进一步提升,在未见外观、组合、物体类型上均稳定上涨。


在 IRON-R01 真机上,UniT 在拾取放置、双手倾倒任务上成功率远超基线;在几何变化、干扰物、新背景、新目标、组合指令五大分布外场景中保持强鲁棒性。尤其在零样本堆叠任务中,借助人类数据迁移,成功率从 10% 提升到 60%,并出现腰部旋转、头部调姿等涌现性上身协同动作。


世界建模与跨躯体迁移


WM-UniT 在 PSNR、SSIM、LPIPS、FVD、EPE 等指标上全面优于原始动作与仅动作条件。在人类–机器人联合训练下,提升幅度更加显著。
跨躯体迁移实验进一步证明:人类动作符号可直接控制机器人视频生成,机器人符号也可生成符合人类运动规律的画面,在语义、时序、几何一致性上全面领先,实现双向跨躯体动态迁移。
消融实验

仅视觉、仅动作均明显弱于 UniT;去掉交叉重构后性能急剧下跌;单向重构效果同样不如双向交叉重构。
这充分说明:视觉–动作协同 + 双向交叉约束,是 UniT 实现跨具身迁移的核心。
总结与技术价值
UniT 的核心贡献,是首次建立了一套不依赖运动学重定向、可扩展、同时支撑策略学习与世界建模的统一物理语言。它以视觉为锚、以交叉重构为核心、以共享离散符号为接口,从表征层面抹平人类与人形机器人的躯体差异,让海量廉价的人类第一人称视频成为人形机器人可直接学习的知识来源。
它不是简单的模仿学习升级,而是真正把物理意图从具体躯体中抽离出来,让机器人理解 “人在做什么、要达成什么目的”,而不是复制表面动作。UniT 为人形机器人基础模型的规模化、通用化、泛化能力提升,提供了一条清晰可行的技术路径,是迈向通用具身智能的关键一步。










