1. 痛点:老硬件已经跟不上新AI的需求了
现在AI发展太快,原来的模型是 dense 大语言模型,现在开始往大规模混合专家模型(MoE)走,推理需求越来越重,还要跑Agentic AI——也就是能自己做规划、多轮推理的智能体,还要支持世界模型做模拟想象。
老的AI硬件只知道堆浮点算力,已经跟不上新 workload 对算力效率、延迟、带宽的要求了。谷歌这次出的第八代TPU,就是专门解决这个问题的答案,不管是预训练第一个token,还是多轮推理最后一步,都能走最有效率的路径,甚至能跑DeepMind的Genie 3这种世界模型,给上百万智能体做模拟训练。
核心结论:这次第八代TPU没有做一款通吃所有场景的芯片,而是拆成了TPU 8t(预训练专用)和TPU 8i(推理部署专用)两款,针对AI全生命周期不同阶段的瓶颈做专门优化,配合Arm架构Axion CPU解决数据准备的 host 瓶颈,整体效率比上一代提升非常明显。

谷歌第八代TPU
2. 为什么要做两款芯片?需求本来就不一样
预训练、后训练、实时推理这三个阶段,对硬件的要求本来就差很多,一款芯片打全场,结果就是每个场景都做不到最优,浪费算力和成本。
所以谷歌这次直接拆分出两个产品线,都属于谷歌云AI超级计算机的核心部分,共享谷歌AI栈的基础设计,但各自解决不同的瓶颈,效率针对性优化。另外全系列都集成了Arm架构的Axion CPU做主控,解决了之前数据准备延迟导致的主机瓶颈——Axion能扛住复杂的数据预处理和调度,保证TPU一直有数据吃,不会空转等数据。
3. TPU 8t:大规模预训练的性能猛兽
TPU 8t专门优化大规模预训练和 embedding 密集型 workload,延续了谷歌成熟的3D环面网络拓扑,一个超级 pod 就能放下9600颗芯片,几百个pod 并行也能保证吞吐量,训练不会延期。
我们一个个说它的核心改进:
1. SparseCore专门解决稀疏计算瓶颈
SparseCore是TPU 8t的核心,专门处理 embedding 查询这种不规则内存访问的场景。原来矩阵计算都交给MXU单元做,现在数据相关的全收集操作这种麻烦活,都卸载给SparseCore做,避免了通用芯片经常遇到的空操作瓶颈。
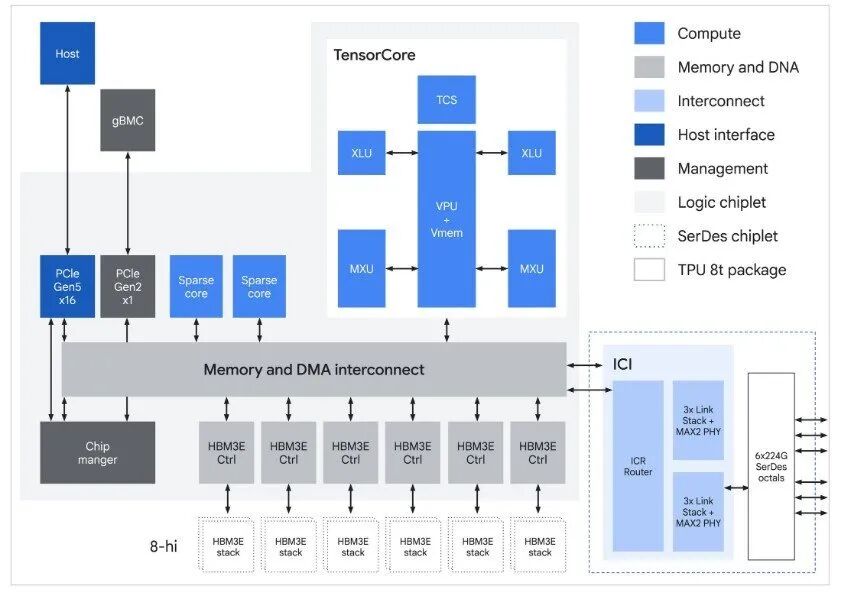
TPU 8t ASIC 模块框图
2. VPU/MXU并行,提升算力利用率
TPU 8t重新平衡了向量处理单元(VPU)的规模,把量化、softmax、层归一化这些向量操作,和MXU的矩阵乘法更好的并行起来,减少了芯片等串行向量任务的时间,让买来的每一块浮点算力都能用满。
人话解释就是:原来芯片做完矩阵乘法要等向量处理完才能开下一轮,现在两个活儿一起干,芯片不摸鱼了,整体利用率就上去了。
3. 原生支持FP4,直接翻倍MXU吞吐量
TPU 8t第一次加入了原生4位浮点(FP4)支持,解决内存带宽瓶颈——更低精度不仅不损失大模型精度,还能把MXU的吞吐量直接翻一倍。每个参数占的位更少,需要搬的数据就少,能耗更低,还能放下更大的模型层在本地缓存里,算力利用率拉满。
4. Virgo新网络,最高4倍数据中心带宽
为了满足大规模训练的海量数据需求,TPU 8t用上了全新的Virgo网络架构,是专门为现代AI workload 做的扩展架构。
它用高基数交换机,每个交换机能放更多端口,直接减少了网络层数,做成了扁平的两层无阻塞拓扑,比传统数据中心网络跳数更少,延迟更低。同时用多平面设计,独立控制域连接芯片,机架还能接Jupiter南北向骨架访问计算存储服务。
对比上一代,芯片间互联(ICI)带宽翻了一倍,数据中心扩展带宽最高翻了4倍,直接砍掉数据瓶颈。配合JAX和Pathways软件,现在一个训练集群能扩展到超过100万颗TPU芯片,Virgo网络能连13.4万颗TPU 8t,整个 fabric 能提供47Pb/s的无阻塞对剖带宽,总算力超过160万exaFLOPS,还能接近线性扩展。

5. TPUDirect技术,存储访问快10倍
TPU 8t加入了TPUDirect RDMA和TPUDirect Storage,把数据绕开了主机CPU和内存,直接在TPU的HBM内存和网卡、存储之间传输。
TPUDirect RDMA减少了TPU之间通信的延迟和主机瓶颈,提升有效带宽;TPUDirect Storage让TPU直接访问高速存储,大规模数据传输带宽直接翻一倍,能让芯片满速吃数据,就算处理多模态大数据集,MXU也能一直满负载运行。
配合10T Lustre托管存储,直接把百PB级数据送到芯片,避免数据吃不上导致的训练延期。对比上一代Ironwood TPU,存储访问速度快了10倍。

有无TPUDirect Storage的数据路径对比图
4. TPU 8i:后训练和高并发推理的专家
TPU 8i专门优化后训练采样和高并发推理,用上了谷歌目前容量最大的片上SRAM,新的集合加速引擎(CAE),还有专门优化推理的Boardfly网络拓扑,针对性解决推理场景的痛点。
1. 更大的片上SRAM,解决长上下文等待问题
对比上一代,TPU 8i的片上SRAM容量翻了3倍,能把更大的KV缓存全部放在芯片上,长上下文解码的时候核心不用等数据,直接减少空闲时间,提升推理速度。

2. 集合加速引擎CAE,集体操作延迟降5倍
采样和自回归推理最头疼的就是不同核心之间的结果聚合同步,TPU 8i专门做了CAE硬件单元,做聚合几乎零延迟,特别适合自回归解码和思维链推理的同步步骤。
每颗TPU 8i有2个张量核心在核心裸片上,1个CAE放在小芯片上,替换了上一代Ironwood TPU核心裸片上的4个SparseCore。专门做硬件加速之后,片上集体操作的延迟直接降了5倍,更少时间等同步,就能支撑更高并发,同时跑上百万个智能体都没问题。
3. Boardfly新拓扑,全对全通信延迟砍一半
原来预训练用的3D环面拓扑,虽然适合大规模邻居之间的通信,但任何芯片都可能要和任何其他芯片通信的MoE和推理场景,跳数太多,延迟太高。
所以TPU 8i换了全新的Boardfly拓扑,用高基数设计,最多连1152颗芯片,直接减少网络直径,减少数据包要走的跳数。针对MoE和推理模型最核心的全对全通信,Boardfly把延迟降低了最多50%。
我们算个数学你就懂了,同样是1024颗芯片的pod:
3D环面的结构是8*8*16,最远的芯片要走 4+4+8=16 跳
Boardfly拓扑,最远的芯片只要走7跳,直接减少了56%的跳数,尾巴延迟直接降下来了,CAE不用一直等数据。

Boardfly是层级结构,分三层:
第一层是基础块,每个托盘用内部ICI链路做成4芯片环,留16个外部接口做扩展
第二层是本地组,8个板用铜线全连接成一个组,用11个外部接口做组内通信
第三层是pod结构,最终一个pod放36个组,最多1024颗活跃芯片,用光线路由器连接,任意芯片通信最多7跳就到了
5. 一张表看完两款芯片的参数对比
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6. 软件栈:不丢性能还能方便开发
硬件再强也要软件配,第八代TPU延续了上一代Ironwood TPU的性能优先软件栈,既不用你写底层代码,也不会丢性能:
Pallas和Mosaic:原生支持Pallas,这是谷歌自定义的内核语言,能用Python写硬件感知的内核,把TPU 8i的CAE和TPU 8t的SparseCore性能榨干。
原生PyTorch支持:现在TPU已经预览支持原生PyTorch了,你原来的PyTorch模型不用大改就能直接搬过来,完全支持Eager Mode这些你常用的原生特性。
可移植性:原来跑在Ironwood上的JAX、PyTorch、Keras代码,直接就能在这代TPU上扩展,XLA会自动处理不同拓扑和CAE同步的复杂转换,你不用管互联,专心做模型就行。
7. 性能提升到底有多大?对比上一代说话
谷歌一直坚持软硬件协同设计,这代的收益很明确:
训练性价比:TPU 8t对比上一代Ironwood TPU,大规模训练的每美元性能最高提升2.7倍。
推理性价比:TPU 8i对比上一代,大规模MoE模型低延迟推理场景,每美元性能最高提升80%。
能效比:两款芯片的每瓦性能都最高提升2倍,对于可持续大规模扩展AI非常重要。
8. 最后说点看法:这才是Agent时代硬件该有的样子
现在AI走到Agentic时代,对硬件的要求已经变了。
能做规划、能在反馈循环里学习的推理Agent,用原来给传统训练和事务推理优化的老硬件,根本跑不出最优效率——它们的运算特征本来就完全不一样。
谷歌这次没有硬堆通用算力,而是直接拆分产品,针对AI生命周期不同阶段的瓶颈专门做设计,和DeepMind深度合作从头重构,就是看准了这个趋势:
未来的AI基础设施,一定是专业化分工,而不是一款芯片打全场。
引用:https://cloud.google.com/blog/products/compute/tpu-8t-and-tpu-8i-technical-deep-dive
文章来源于歪睿老哥,作者










