点击下方卡片,关注“具身智能之心”公众号
自22年到现在,机器人的基础模型已经越来越多:不同技术路线、同一技术路线下的不同模型,不断刷新着性能的上限。
早期是以ACT为代表的VA方案——模型能看懂画面、输出动作,但不会“听话“。适合简单抓取、实时性要求高的任务。
然后是VLA,加上了语言模块,能听懂指令,但问题是本质还是行为克隆。模仿学习的弊病也比较突出,泛化弱,换个场景就崩。
而如今,WAM和VAM正在挑战VLA范式......
当前,行业在机器人大模型上基本分化出了三条路线:VLA的优化、WAM、VAM。
而每条路线都有比较具有代表性的模型:π0.7、DreamZero、VPP。
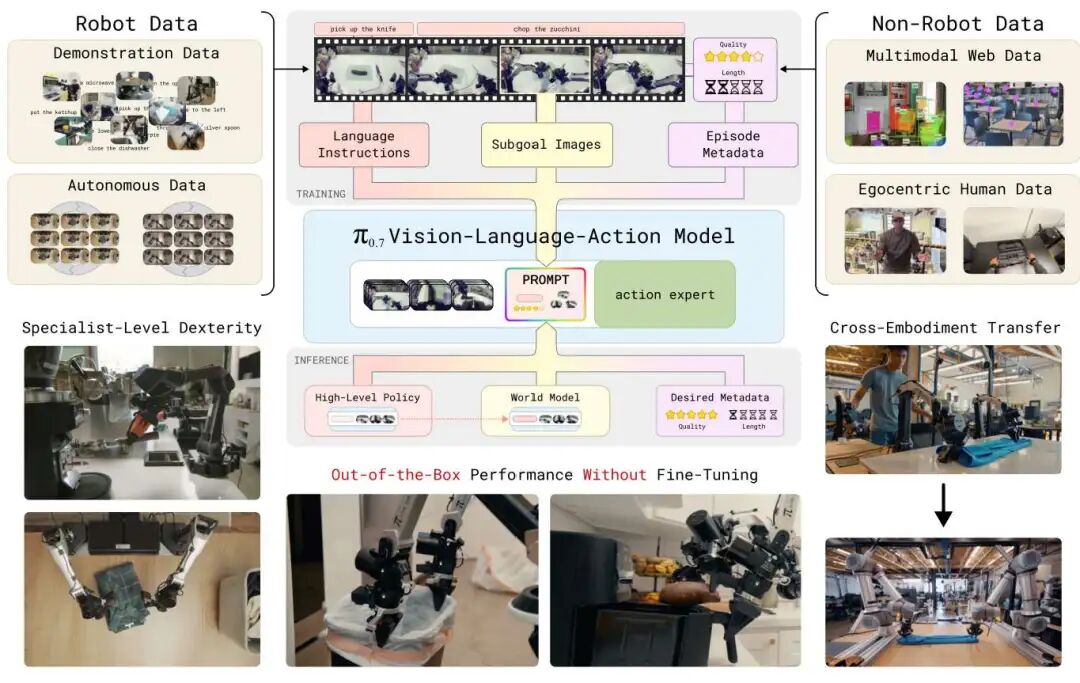
π0.7:VLA路线
相比于之前的系列,没改VLA架构,改的是prompt。子任务指令、视觉子目标、速度质量标签,全塞进去。
模型学到的不是“看到A做B”,而是“什么条件下怎么做”。world model异步生成子目标,不阻塞控制循环,但整体系统复杂度确实增加了。
DreamZero:WAM路线
把视频生成模型当大脑。14B参数,训练时同时预测视频和动作,推理时用真实观测覆盖KV Cache,斩断误差积累。
在没见过的任务上(解鞋带、摘帽子),从头训练的VLA几乎零进度,DreamZero平均进度39.5%。

VPP:VAM路线。
不自己学物理,直接借现成的视频生成模型当物理先验。冻结视频骨干,在latent上挂动作解码器。推理快,样本效率高,在CALVIN和真实灵巧手任务上均有提升。

三条路线技术细节各不相同,但都在回答同一个问题:怎么让机器人真正理解物理世界、连续完成长程任务。
这也指向了行业的下一个竞争焦点:谁先做出真正通用的机器人大脑。
而这,也不仅仅是工业界的事情,学术界更是需要率先突破。
然而,对很多科研入门的同学来说,有一个很痛的点:不知道怎么入坑,许多论文只讲了“模型怎么样”,没讲“怎么训、如何从零跑通”、“还有哪些创新点可以做”、“论文怎么设计”。
仿真里跑得通,一上真机就崩,数据采集等、部署到真机等很多细节没有教程。
很多同学折腾好久都无法有效入门。
具身智能之心联合业内科研大牛,推出首个机器人基础大模型方向科研辅导小班课。每期6人,招满开课,不仅讲算法怎么做,还有很多细节和创新点,更能发论文~
更多内容欢迎咨询小助理微信:AIDriver005了解更多~

这门课程的目标不是“再讲一遍论文”,而是:
一套跑通全流程的代码与工程经验 从idea到初稿的论文写作全流程 少踩坑,把“别人半年踩的雷”压缩到数周
课程的目的是辅导机器人基础大模型方向的同学快速展开科研,形成论文~
课程大纲
第 1 讲 具身智能的挑战与 Foundation Model 范式
VLA 定义与范式;
领域主流方法介绍;
机器人领域期刊和会议介绍
第 2 讲 VLA 模型基础与典型框架
VLM 编码;
动作表示;
时序建模;
端到端 vs 分模块;
主流 benchmark 与评价指标
第 3 讲 强化学习基础与机器人特点
Value/Advantage 介绍;
PPO/SAC 介绍;
奖励函数;
稳定性问题;
多 seed 评测
第 4 讲 RL 在 VLA 中的融合方式
RL fine-tuning;
reward shaping;
critic 引入;
RL 对稳定性与泛化的影响
第 5 讲 奖励设计与 Reward Model
奖励函数设计原则;
稀疏 vs 稠密奖励;
reward model 训练与应用
第 6 讲 端到端与分层 VLA 系统
端到端:Diffusion/Flow matching-based VLA;
Token-based Action;
优缺点分析分层:高层 VLM/VLA 负责子目标/抽象动作;
低层policy 负责连续控制;
层间接口设计
第 7 讲 学术会议视角下的技术版图
RL 在 VLA 中的角色;
关键挑战;
如何定义研究问题
第 8 讲 VLA+RL 仿真平台搭建
IsaacLab / MuJoCo / ManiSkill;
任务定义;
观测与动作空间设计;
复现与工程规范
第 9 讲 世界模型导论:从预测到行动
世界模型基本概念;
预测驱动的决策范式;
从感知预测到行动规划的过渡
第 10 讲 Video Action Model:视频预测驱动决策
视频生成模型在机器人决策中的应用;
VAM 架构与训练方式;
视频预测作为隐式 world model
第 11 讲 World Action Model:统一感知-预测-行动
WAM 统一建模框架;
感知、预测与行动的联合建模;
与端到端 VLA的关系与差异
第 12 讲 长时任务、记忆机制与泛化能力
长时任务挑战;
时序信用分配;
显式/隐式记忆机制;
history / state aggregation; 语义 token 与动作抽象;
数据多样性;
跨任务泛化分析
第 13 讲 选题、论文写作与投稿指导
当前瓶颈与可创新点分类;
实验设计与评价指标;
问题定义与方法对齐;
Abstract / Introduction / Experiments 写作
辅导老师介绍
Mason 老师,欧洲 Top 名校 PhD,美国德克萨斯大学奥斯汀分校访问学者,曾工作于德国人工智能研究中心 DFKI、ABB 机器人的 AI 机器人研究部门。研究包 括:深度强化学习,机器人学习,模仿学习,迁移学习。在 RAL,ICRA,IROS 等顶刊顶会发表多篇论文。担任 RAL,ICRA,IROS,TMECH 等期刊和会议审稿人。
硬件与基础要求
具身智能领域研究方向,推理要求 4090 以上算力,训练算力自备(建议 4 卡 4090,可以租借); 一定的 pytorch 和 python 基础,能够自己修改代码
预期收获
完成本课程后,你将能够:
全面掌握机器人基础模型(VLA、WAM、VAM)的理论基础与技术演进路径 熟练使用各类仿真环境进行实验,具备从零搭建训练环境的能力 理解RL在基础模型中的融合方式,掌握奖励设计、策略优化等关键技能 具备独立发现研究问题、设计实验方案的能力 掌握学术论文撰写与投稿的完整流程 形成自己的研究idea并完成初步实验验证 建立具身智能领域的学术视野与研究思维 产出一篇完整的论文初稿
课程细节
5 月 31 号正式开课, 报名前需联系小助理和老师约meeting筛选简历,通过后,进入课题。
时间安排:13 周集中辅导+8 周课后答疑。

推荐阅读 :










