新智元报道
【新智元导读】微软用一套多 Agent 系统在 AI 漏洞发现的顶级基准测试上拿下第一,超过 Anthropic 最强模型 Mythos 五个百分点。诡异的是,微软自己并没有一个能打的前沿模型。它用别人的模型组了个系统,打败了造出这些模型的公司。这对AI竞争格局的启示,比这个工具挖出了大量 Windows 漏洞本身更重要。
最强黑客大模型 Mythos,居然被黑马超越了!
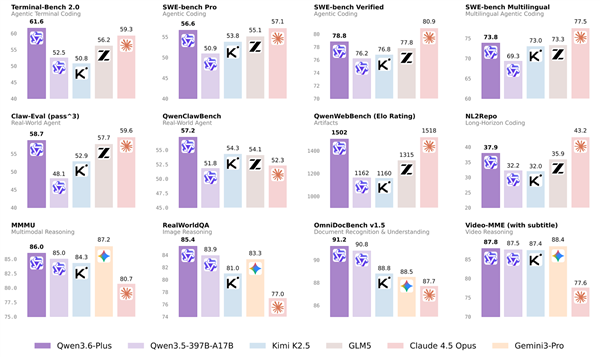
5 月 12 日,微软发布了代号 MDASH 的 AI 安全系统,同时登顶 CyberGym 基准测试榜首,成绩 88.45%。
排在它后面的是 Anthropic 的 Mythos Preview(83.1%)和 OpenAI 的 GPT-5.5(81.8%)。

https://www.cybergym.io/
CyberGym 榜单上,Anthropic 用的是自家最强模型 Mythos,OpenAI 用的是自家最强模型 GPT-5.5。
微软用的是什么?
答案是,别人家的模型。
微软在博客里明确写道,MDASH 使用的全部是「generally available models」,即市面上公开可用的模型。


https://www.microsoft.com/en-us/security/blog/2026/05/12/defense-at-ai-speed-microsofts-new-multi-model-agentic-security-system-tops-leading-industry-benchmark/
微软自己并没有一个能与 Mythos 或 GPT-5.5 竞争的前沿模型。
在这张榜单上,如果微软拿单个模型去跑,成绩大概率会落到中下游。
但它组了一套系统,调度 100 多个专业化 Agent,让多个模型分工协作,跑出了比任何单一模型都高的分数。
用别人的砖,盖了最高的楼。
微软已经用这套工具,挖出了自家 Windows 11 系统 16 个高危漏洞!
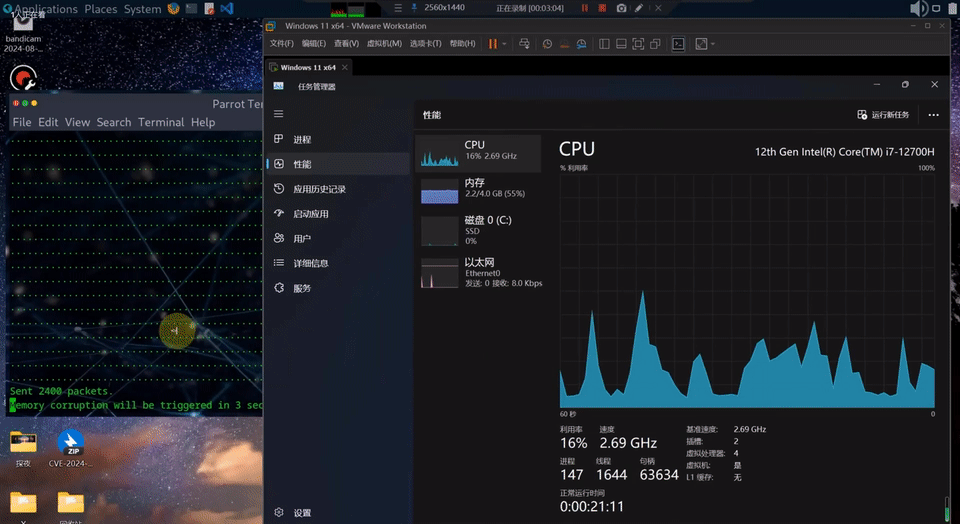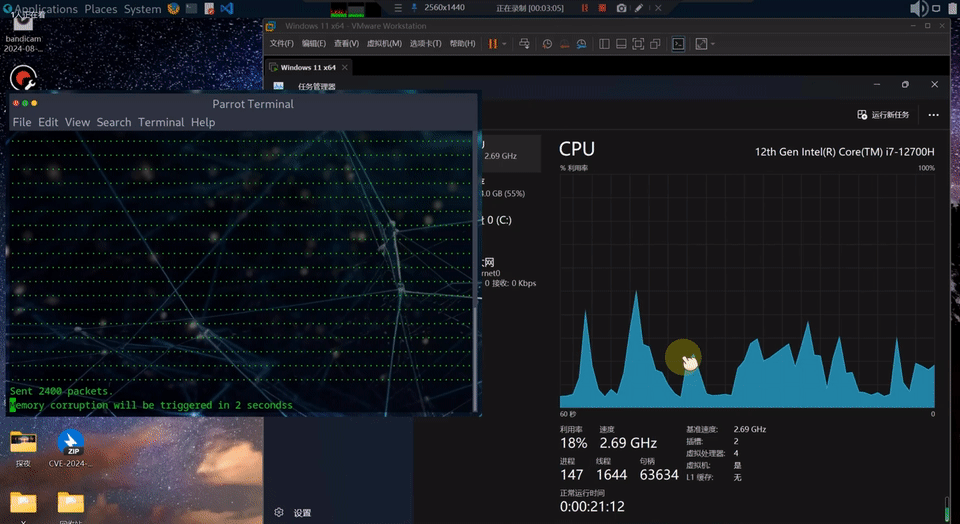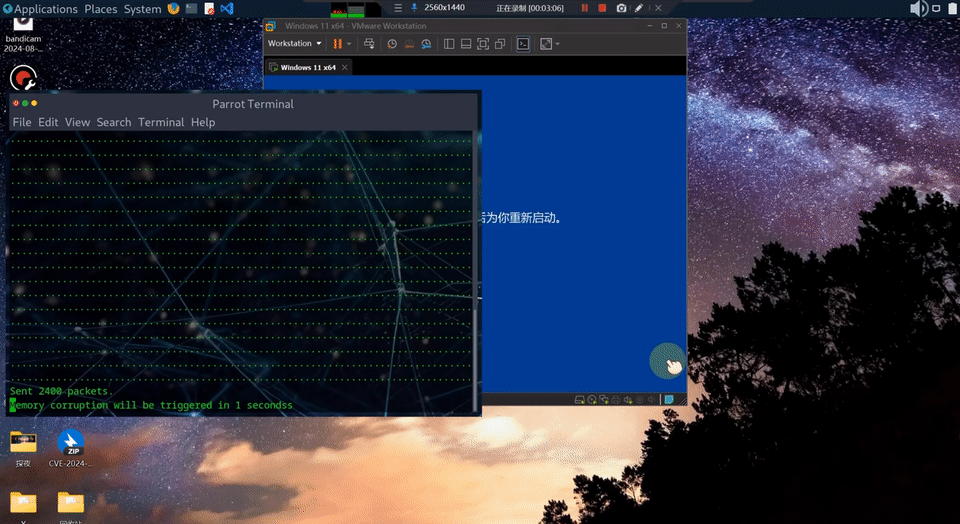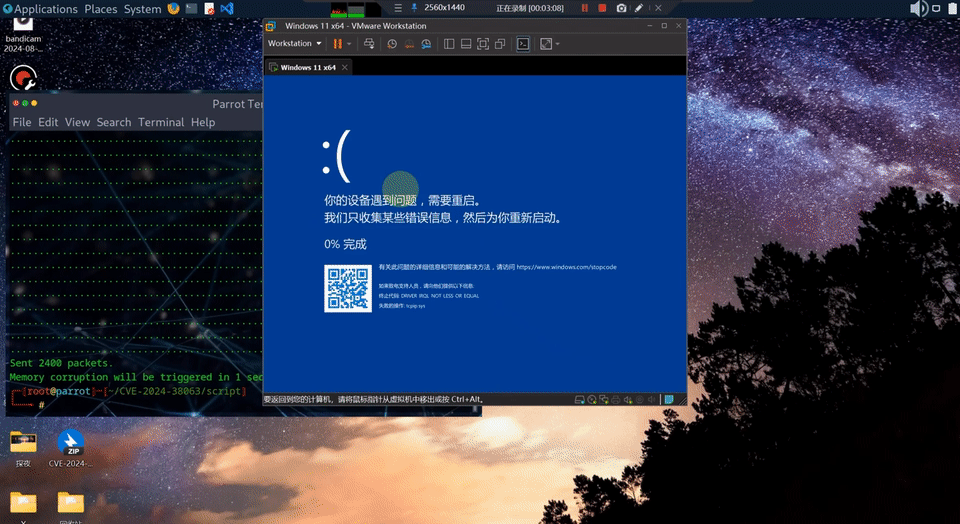
远程执行导致蓝屏的漏洞 CVE-2026-33827 效果演示

CyberGym 由 UC Berkeley 团队开发,论文发表在 ICLR 2026,是目前 AI 安全能力评估领域最权威的公开基准之一。

https://arxiv.org/pdf/2506.02548
Anthropic、OpenAI、Meta、智谱都在上面提交过成绩。
测试方式很直接,给 AI 一段有已知漏洞的代码和漏洞描述,让它自己写出能触发漏洞的攻击代码。
1507 道题,来自 188 个真实开源项目。
能不能挖到漏洞、能不能证明它可被利用,一测便知。
一个细节值得留意,榜单成绩由各公司自行提交,基准代码公开但无独立第三方验证。

MDASH 带来的核心启示:「系统」可以抹平甚至反超「模型」的差距。
Anthropic 花了巨大的研发投入训练出 Mythos,这是目前公认的安全领域最强单一模型,强到 Anthropic 自己都不敢公开发布,只通过一个叫 Project Glasswing 的联盟向少数公司定向开放。
OpenAI 的 GPT-5.5 同样是倾全公司之力训出的前沿模型。
微软没有这样的模型。
但它有一套流水线,把「准备→扫描→验证→去重→证明」五个阶段拆开,每个阶段用不同的 Agent、不同的模型去跑。
审计 Agent 和辩论 Agent 分开,发现漏洞和证明漏洞分开,重度推理用大模型、高频验证用蒸馏小模型。

关键在于,这套系统对底层模型不绑定。
新模型出来,换个配置跑 A/B 测试就行,前面积累的所有工程资产全部复用。
微软在博客里特别强调了这一点——「the model is one input」,模型只是众多输入之一。

这对 Anthropic 和 OpenAI 构成一种新型威胁。
它们烧了天文数字的美元训出来的模型优势,被一个系统层的竞争者用工程手段消解了。
更扎心的是,微软用的还是它们自己的模型。

在前沿模型这张牌桌上,真正有筹码的只有 Anthropic 和 OpenAI。
微软虽然是 OpenAI 最大的投资方和云计算合作伙伴,但它自己并没有训出过一个真正进入第一梯队的旗舰大模型。
这次 CyberGym 的结果把一个问题摆上了台面,通往 ASI 的路径,到底是一条还是两条?
路径一是 Anthropic 和 OpenAI 正在走的,把单一模型推到极致。
Mythos 在安全领域的能力已经强到需要限制发布,GPT-5.5 在多个基准上持续刷新纪录。

Mythos 仅通过 Project Glasswing 测试
这条路需要海量算力、海量数据、顶尖的研究团队,门槛极高。
路径二就是微软用 MDASH 展示的,不追求造出最强的单一模型,转而构建一个能把现有模型能力最大化的系统。
100 多个 Agent 各司其职,模型之间的分歧变成信号,多阶段流水线把单次推理做不到的事情通过任务分解实现。
MDASH 的成绩证明了路径二至少在特定领域是可行的。
但这不代表路径二可以替代路径一。
MDASH 用的底层模型仍然来自路径一的公司。
如果 Anthropic 和 OpenAI 停止训练更强的模型,MDASH 的天花板也会停滞。

多 Agent 系统作为一种范式,正在从实验走向生产。
MDASH 团队的多位核心成员来自 Team Atlanta,就是在 DARPA AI 网络挑战赛中赢得 2950 万美元奖金的队伍。
他们验证过的一个核心判断是,让 AI 做到专业级别的安全审计,工程量远超模型本身。
微软这次同时公布了 16 个由 MDASH 辅助发现的 Windows 漏洞,其中 4 个是 Critical(关键)级别的远程代码执行。
这些漏洞大多可以在无需认证的情况下从网络侧触发,已在 5 月 Patch Tuesday 中修复。
在内部回溯测试中,MDASH 对 Windows 核心组件 clfs.sys 过去五年的已确认漏洞召回率达到 96%,tcpip.sys 达到 100%。

这些数字的分量在于,它们来自实战,不只是跑分。
16 个 CVE 已经进入微软的正式补丁流程,96% 的召回率对标的是过去五年真实被攻击者利用过的漏洞。
微软在博客中说,以后的 Patch Tuesday 会越来越大。
AI 正在加速漏洞发现的速度,补丁规模自然水涨船高。
这句话的另一面同样成立,攻击者也能用同样的技术。
MDASH 用的全是公开可用的模型,没有任何技术上的独占壁垒。

对行业来说,MDASH 的意义大于 MDASH 本身。
它验证了一个猜想:在 AI 能力的下一阶段竞争中,「围绕模型构建系统」可能和「训练更强模型」同等重要。
这对三类人有不同的含义。
对模型公司(Anthropic、OpenAI),它敲响了一个警钟。
模型能力的领先不能自动转化为应用层的领先。
别人可以用你的模型,在你的地盘上赢你。
对平台公司(谷歌、微软),它指出了一条差异化路径。
没有最强模型?没关系,构建最强系统。
但前提是,你得深刻理解具体领域的工程细节,100 多个 Agent 的分工设计、领域插件、验证流水线,这些东西的积累门槛同样很高。
对普通用户,这件事的直接影响很简单,及时打补丁,否则不懂技术的人也能借助 AI 利用这类漏洞。
MDASH 目前也像 Mythos 和 GPT-5.5 Cyber 一样,正在进行小范围客户私测,微软未公布定价和正式发布时间。