过去两年,自动驾驶和大模型的结合越来越热。一个很自然的方向是:既然视觉语言模型已经具备很强的场景理解和推理能力,那能不能让它像人类司机一样,先理解环境、再做判断、最后输出轨迹?
这条路线听起来很合理,但真正落到自动驾驶上,很快就会遇到一个问题:很多方法虽然引入了大模型,却仍然把「推理」做成了文本链式推理。也就是说,模型要先生成中间解释,再把这些解释一步步转成动作或轨迹。这样做的优点是看起来 「更会思考」,但代价也非常明显:文本是离散 token,而轨迹是连续控制;文本推理还依赖自回归解码,速度慢、链路长,不太适合实时驾驶。
来自清华大学与香港中文大学 MMLab 的研究团队提出了全新的隐空间推理与层次化轨迹规划的 VLA 框架 --ColaVLA,论文已经被 CVPR2026 主会接收。

论文标题:ColaVLA: Leveraging Cognitive Latent Reasoning for Hierarchical Parallel Trajectory Planning in Autonomous Driving
论文链接: https://arxiv.org/abs/2512.22939
代码链接: https://github.com/pqh22/ColaVLA
这篇论文给出的答案很直接:自动驾驶中的推理,不一定要写成文字。
与其让模型「边说边想」,不如让它在统一潜空间里完成推理,再把结果直接交给动作规划器。这样既能保留 VLM 的语义先验和知识能力,又能绕开显式文本生成带来的延迟和表示错位。
整篇论文最重要的贡献,其实可以概括成两句话:第一,把推理从文本空间搬到潜空间;第二,把轨迹生成从串行过程改成分层并行过程。

一、核心思路:先「想清楚」,再「开出来」
ColaVLA 的整体框架由两个核心部分组成:
Cognitive Latent Reasoner:负责完成高层驾驶认知
Hierarchical Parallel Planner:负责把高层策略展开成连续轨迹
作者的目标不是简单把一个大模型接到规划器前面,而是重新定义「推理」和「动作」之间的接口,让二者真正对齐。
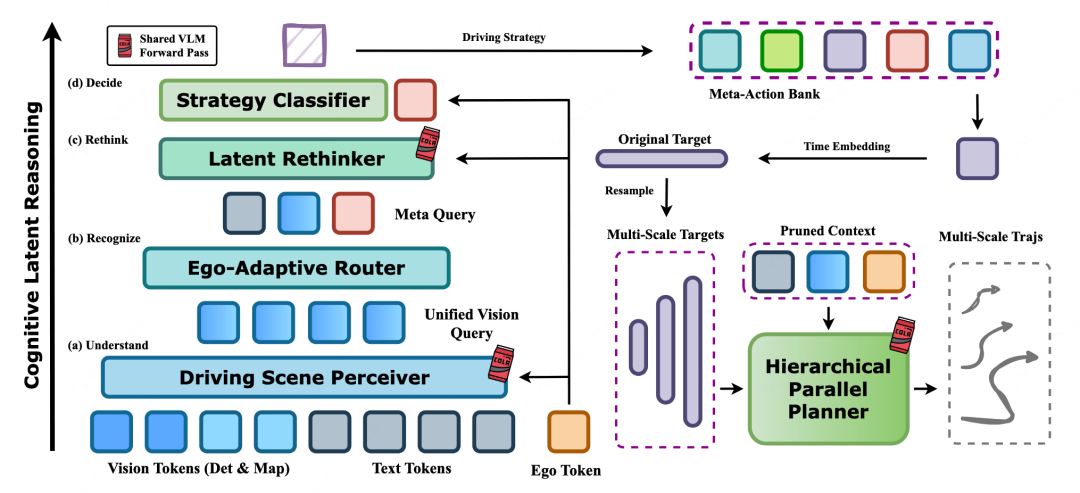
先看前半部分,也就是潜空间推理器。作者把它设计成一个很像人类司机的四步过程:
Understand
Recognize
Rethink
Decide
这四步看上去很直观,但真正巧妙的地方在于,它们都不是通过自然语言完成的,而是在统一潜空间中隐式完成。
第一步 Understand,是先整体看懂场景。模型会把多视角视觉信息、固定驾驶提示和 ego 车状态一起送入共享 VLM,先建立一个全局场景理解,而不是一上来就直接回归轨迹。
第二步 Recognize,是从大量视觉信息里筛出真正和当前驾驶动作相关的关键实体。这里论文设计了一个 ego-adaptive router,根据当前自车状态动态选择最重要的视觉 token,保留的通常是车道、邻近车辆、行人、交通灯这些安全关键线索,而不是无差别地处理整张图。
第三步 Rethink,则是在压缩后的关键信息上再做一次 “复核式推理”,并借助一组可学习的 meta-query 来表示不同高层驾驶策略。
最后一步 Decide,输出的也不是一句解释文本,而是一组面向动作生成的高层驾驶先验。这样一来,模型就不再需要把推理结果先翻译成自然语言,再从语言翻译回动作空间,而是直接完成从认知到策略的内部闭合。
二、真正落到动作层面,它的规划器为什么更合理?
很多自动驾驶方法的问题,不只是上游推理方式不合适,下游轨迹生成方式也未必真正符合驾驶动作的结构。有些方法一次性直接回归整条轨迹,虽然简单,但缺少层次;有些方法依赖复杂生成过程,虽然表达能力强,但效率和部署稳定性不一定理想。
ColaVLA 这里的思路很清晰:驾驶轨迹本来就是分层的,所以生成过程也应该分层。
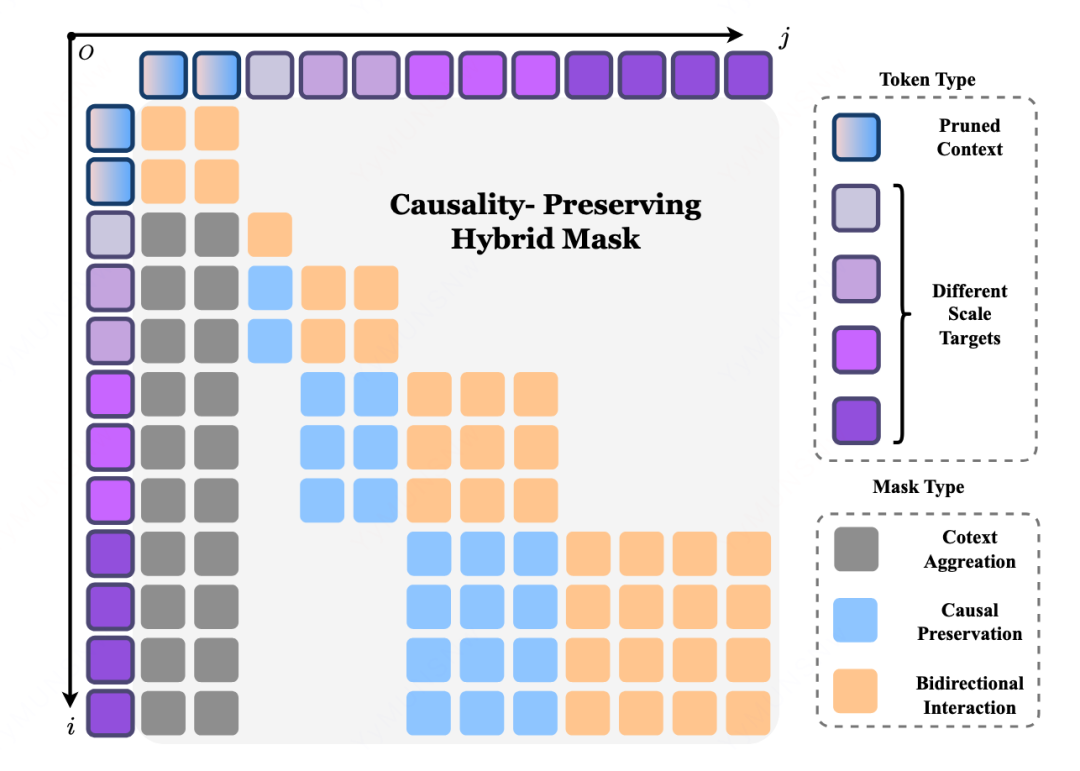
论文提出的 Hierarchical Parallel Planner 有三个关键词:
先粗后细
保持因果
并行解码
它不是把未来轨迹当作一个扁平输出,而是先确定粗粒度意图,再逐步补足中间细节。这更像真实驾驶员的决策方式:先想清楚「往哪去」,再决定「具体怎么走」。
同时,作者还设计了一个 causality-preserving 的注意力机制,保证不同尺度之间的信息流是从粗到细、逐层细化的,而不是相互泄漏。这样一来,多尺度结构就不只是形式上的分解,而是真正具有因果约束的轨迹生成过程。
更重要的是,这个 planner 可以在单次前向传播中并行完成多尺度、多模式轨迹解码,不用再像文本 CoT 那样一步一步串行生成。
三、实验结果说明了什么?
从结果上看,ColaVLA 最打动人的地方,不只是「指标更高」,而是它同时兼顾了精度、安全和效率。
1. Open-loop:不只是预测更准,而且更安全
在 nuScenes 的开环评测中,ColaVLA 在动作类方法里取得了最优综合表现,平均 L2 误差为 0.30 m,平均碰撞率为 0.23%。相比强基线 SOLVE-E2E,L2 进一步下降,碰撞率也明显降低。
这说明它输出的轨迹并不只是数值上更接近真值,而是在安全性层面也更优。

2. Closed-loop:真正体现方法价值的部分
在更关键的闭环评测 NeuroNCAP 中,ColaVLA 的平均得分达到 3.48,平均碰撞率降到 36.8%,明显优于多种前序方法。
论文特别指出,相比依赖文本推理、并使用额外数据的 ImpromptuVLA,ColaVLA 在不显式生成文本思维链的情况下,依然取得了更好的闭环表现。
这个结果很有说服力,因为它说明:对自动驾驶来说,更长、更复杂的文字推理链,并不一定能带来更好的真实驾驶行为;真正关键的,还是内部决策表征是否适合动作生成,以及规划器是否具有合理的因果结构。

3. 推理效率:它把「落地可能性」往前推了一步
效率上,ColaVLA 也给出了非常亮眼的结果。在扎实的工程优化后,它的在 H200 上的端到端推理延迟为 228 ms/frame,而对比的文本式方法整体快了 5 倍到 10 倍左右。
这意味着,把推理从文本搬到潜空间,并不只是概念上更优雅,而是真的换来了实打实的速度收益。对于强调闭环和实时性的自动驾驶来说,这一点尤其关键。
四、消融实验最值得记住的几点
这篇论文的消融实验也比较完整,但最值得记住的其实只有四点。
第一,潜空间推理本身确实有效。只要加入 latent reasoning,模型的轨迹误差就会下降;再加入 rethink 阶段,效果还会进一步提升。这说明「先抓关键、再做复核」的认知链条不是叙事包装,而是真正有助于决策质量。
第二,分层并行规划器本身也很重要。即便把 reasoning 模块去掉,作者的 planner 在闭环上依然明显优于普通 MLP 头和 diffusion 头,说明它确实更符合真实驾驶动作的生成逻辑。
第三,关键 token 不是越多越好,而是平衡最好最重要。保留太少会丢信息,保留太多又会引入冗余,论文最终选择了一个在表达能力和效率之间更均衡的配置。
第四,最优的轨迹生成方式不是一次性回归整条轨迹,而是先确定关键点,再逐层补齐中间细节,这和驾驶动作本身的因果结构是对得上的。
五、这篇论文真正有价值的地方是什么?
如果只把 ColaVLA 看成「又一个自动驾驶模型」,其实低估了它。
我觉得这篇工作的更大意义在于,它提出了一个非常明确的判断:
自动驾驶中的推理,不一定需要显式写成文字。
过去很多工作默认认为,大模型的优势来自「会解释」「会说话」「能输出思维链」。但 ColaVLA 给出的答案是:在自动驾驶这种连续控制任务里,更重要的也许不是「让模型把思考说出来」,而是「让模型在内部真正想清楚,并用更适合动作生成的方式表达出来」。
从这个角度看,它代表的是一种很值得重视的范式变化:
从 text reasoning 转向 latent reasoning
从 sequential decoding 转向 parallel decoding
从「展示推理过程」转向「兼顾安全、效率和闭环表现」
论文最后的结论也很清楚:把推理从文本迁移到潜空间,为自动驾驶中的知识驱动决策提供了一条更可扩展、也更现实的路径。
六、总结
如果要用一句话总结 ColaVLA,我会这样说:
它不是让自动驾驶大模型「更会说」,而是让它「更会在内部想清楚,再更快地开出来」。
这篇论文最核心的贡献,不只是提出了一个新模块,也不只是刷新了几项指标,而是它证明了下面几件事:
自动驾驶里的推理,可以不依赖显式文本思维链;
潜空间推理同样可以保留高层驾驶决策能力;
分层并行、因果一致的规划器,更适合真实驾驶动作生成;
当推理形式和动作生成真正对齐时,系统才能同时获得更好的安全性、效率和闭环表现。
对于后续自动驾驶大模型的发展来说,这篇工作很可能代表着一个很值得继续深入的方向:
不是把大模型硬塞进自动驾驶,而是重新设计一种真正适合自动驾驶的大模型推理方式。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com