梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
AI再也不是“回合制”了。
Thinking Machines Lab(以下简称TML)发布首个模型,让实时交互能力成为模型原生能力。
联合创始人翁荔出镜演示。
从“人说完→AI答→人再说→AI再答”,变成了“人和AI都可以随时插嘴,说完了代码也写完了”。
音频和代码同时输出,说完了活也干完了。
在测试结果上,响应延迟比GPT-realtime-2.0快4倍,交互质量测评领先GPT-realtime-2.0,只在模型智力上还不如GPT-2.0 xhigh模式。

在几个月里,团队训练了12个版本,留下了137页的训练日志。

今天,这家由OpenAI前CTO创办的实验室,终于交卷首个模型TML-Interaction-Small。
也让外界知道了“Thinking Machines”的真正含义:
把语音助手、视频理解和Agent协作放到同一个框架里解决。
增加人机交互带宽,模型边听边说边想
真实工作里,很多需求根本不可能一开始就完全说清楚。
你可能讲到一半想改方向,看到结果后想补条件,发现模型误解了一个词,或者只想在关键节点插一句“不是这个意思”。
如果人类之间只能用邮件沟通,效率就太低了。
现在大多数AI系统的基本节奏,也是邮件式的“回合制”。
用户输入时,模型等着。模型生成时,它对新信息的感知又会冻结。除非被打断,否则它不知道你正在做什么、看到什么、纠结什么。

这就把人和AI的协作压在一个很窄的通道里,人的知识、意图、判断,被这条邮件式窄带宽漏掉了大半。
同时,回合制的AI系统不支持精确的时间估计或同步语音。
比如这些任务现有AI就完全无法回答:“我跑一英里花了多长时间?”、“请纠正我的发音错误”或“我写这个函数花了多长时间?
要解决这些问题,TML让AI在任何模态上都能实时交互,让接口去适应人,而不是反过来让人去迁就接口。
现在多数AI模型解决交互问题,是外挂一层harness,拼接 VAD(语音活动检测)、turn-detection、TTS这些组件,模拟出实时感。
TML搬出了新的“Bitter Lesson”:
这些拼接出来的系统,长期看会被通用能力的扩展给追平甚至超越。
想让交互能力随着智能一起scale,交互能力就必须做进模型本身。
那么,“交互做进模型”具体是怎么实现的?
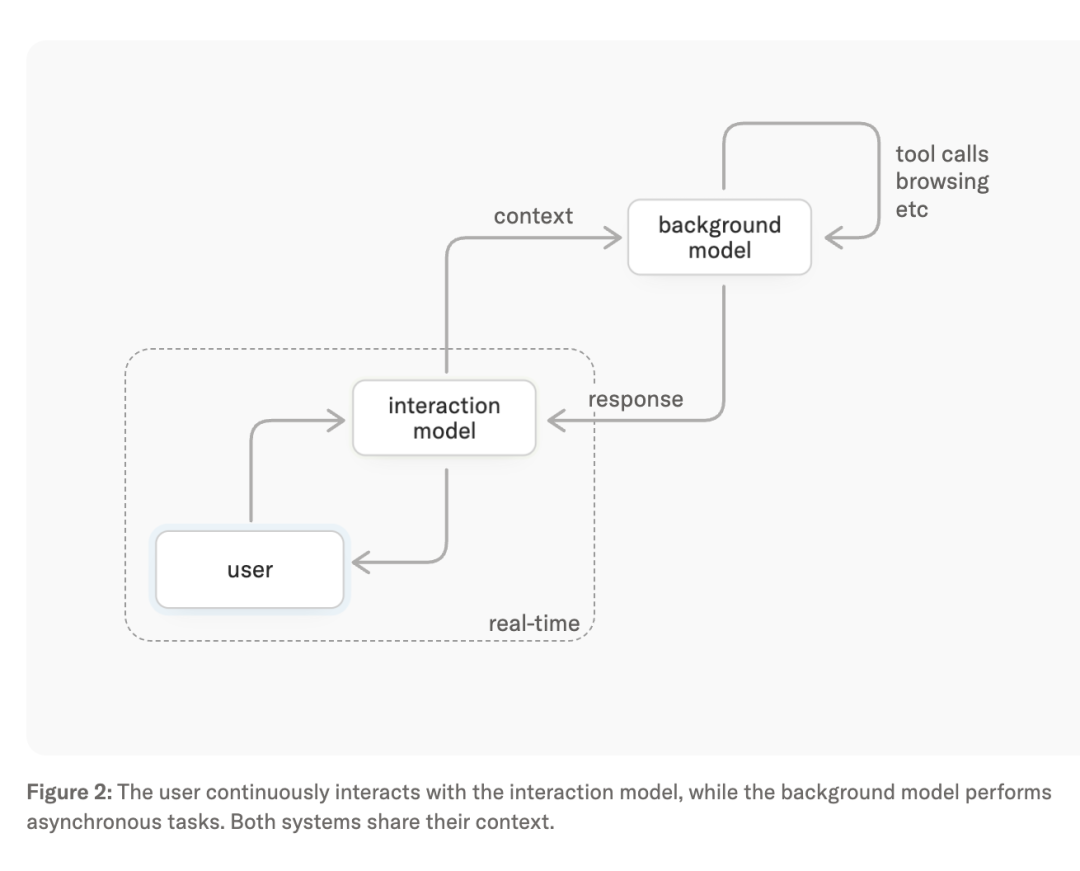
前台及时响应,后台干重活
这套交互模型最关键的机制,是把连续音频、视频、文本都切成200ms的“微回合”,
让输入和输出在时间上交错输入同一个模型。
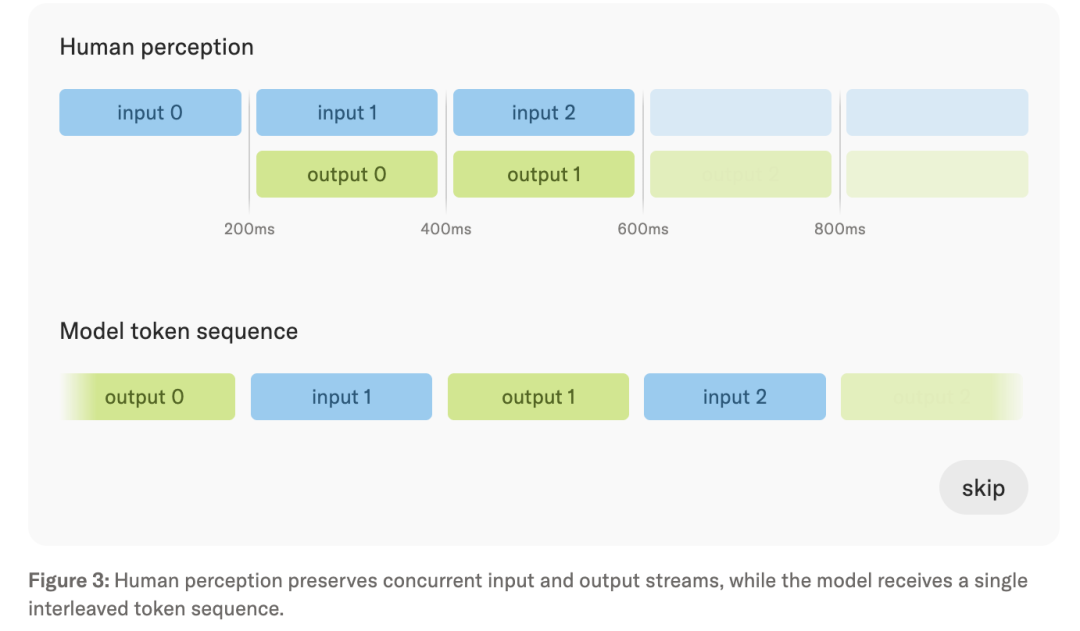
沉默、重叠说话、用户自我修正、视觉变化都不再是外部状态,而是模型能直接学习和响应的上下文。
旧方法:模型等完整用户轮次,再生成完整回应;实时感主要靠外部组件判断谁该说话。
新方法:每 200ms 处理输入,也生成输出,输入输出像流一样交错。
整体架构是双模型协同。
前台模型持续接收新输入、回应追问、维持上下文;后台模型异步跑长推理、工具调用和Agent工作流。
遇到不能即时算出来的任务,Interaction Model 把完整对话上下文打包丢给后台。
后台一边算,结果一边流式回传过来,前台找个合适的时机插进对话里。
训练阶段的核心方法是encoder-free early fusion。
大多数全模态模型要么训独立的encoder(类Whisper),要么训独立的decoder(类TTS),
TML的做法:
音频编码不用一个庞大的独立encoder,而是用dMel加一个轻量embedding层,图像切成 40x40的patch由hMLP编码,音频输出用flow head解码。
所有这些组件,跟Transformer一起从头共同训练,在训练阶段就让它们共享一个实时互动语境。

200ms的响应速度也带来工程压力。
每200ms一次请求,意味着大量小prefill和小decode。传统LLM推理库并不擅长这种高频小块工作,开销可能被请求管理、内存分配、元数据计算吃掉。
TML又做了一层streaming sessions。
客户端仍然按 200ms chunk 发送请求,服务端则把这些 chunk 追加到 GPU memory 里的 persistent sequence 中,避免反复重分配。发布方还称,相关功能的已经发布到SGLang。
重新认识Thinking Machines Lab
过去说到Thinking Machines Lab这家公司,最容易被记住的标签是再0产品、0收入阶段,就拿到高融资。
Mira Murati从OpenAI离开后创办TML,很快完成约20亿美元种子轮融资,估值达到120亿美元。
这个数字太醒目,但很长一段时间大家都不知道这家公司到底要做什么?
后来的线索也有点分散。
一边是人。
到2026年,TML约140 人,Meta是它挖人最多的来源。从CTO Soumith Chintala,到参与过Segment Anything相关工作的 Piotr Dollar,再到多位 FAIR、多模态、LLM 训练背景的研究员,都加入了TML。
一边是算力。
2026年3月,TML和英伟达宣布长期合作,计划通过Vera Rubin系统获得至少1GW算力,英伟达也参与了TML的融资。
2026年4月22日,TML和谷歌签下单个位数十亿美元级别的云计算协议,将获得基于英伟达 GB300 的系统,用于模型训练和部署。
但很长一段时间,他们的产品就只有一个训练基础设施Tinker。

这次交互模型,TML第一次把自己的技术路线完整摆出来:把AI的交互范式从产品外壳,推进到模型本体。
以前的动作也都看清了:
200ms需要低延迟推理系统; 前台交互模型和后台模型需要稳定的训练、调度和工具链; 多模态实时输入输出需要更强的训练和部署底座; 更大规模模型要在这种实时设定里跑起来,更离不开GB300、Vera Rubin这类算力。
TML 想赌的,是下一个人机协作界面。
今年新加入团队的斯坦福博士Zitong Yang,还设想过把整个大模型预训练数据重写成智能体轨迹。

这次发布的TML-Interaction-Small还只是第一步。
按照发布方说法,它是276B 参数 MoE、12B激活参数,目前更大规模的预训练模型还无法胜任实时交互任务。

更大规模的模型,计划在今年晚些时候发布。
参考链接:
[1]https://thinkingmachines.ai/blog/interaction-models/
[2]https://x.com/thinkymachines/status/2053938906689884279
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
中国AIGC产业峰会最新嘉宾阵容来了!
从AI最新架构到应用生态,从AI音乐、AI漫剧、AI浏览器再到世界模型、AI硬件... 这一次,我们希望聚齐AI赛道的实战派,百度、智谱、昆仑万维、模思智能、蚂蚁灵波都会来。🔍
5月20日,北京·金茂万丽酒店,@所有人,马上AI起来!👉

一键关注 👇 点亮星标