> 作者:李剑锋
前言
在前面的课程中,我们已经重点讲解了 SFT(监督微调) 的相关内容,并在上一节课中进一步介绍了 继续预训练 的基本思路。而在这一节课里,我们将继续沿着模型训练能力不断增强的这条路线,进入一个更进阶的话题:强化学习阶段的模型训练方法。
事实上,早在课程第二节介绍大模型训练流程时,我们就已经提到过,像早期的 GPT-3.5 这类模型,其训练过程通常并不是单一阶段完成的,而是经历了一个较为典型的三阶段流程——预训练(Pretraining)→ SFT 微调 → RLHF 对齐。其中,前两个阶段主要解决的是“让模型具备知识能力”和“让模型学会按照指令回答”的问题;而最后的 RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习),则进一步承担了“让模型回答更符合人类偏好”的任务。

换句话说,仅仅让模型“会回答”还不够,我们还希望它能够回答得更自然、更有帮助、更符合人类使用习惯。例如,面对同一个问题,模型也许能够给出多个都“基本正确”的答案,但其中有的表达更清晰,有的结构更合理,有的语气更符合用户期待。RLHF 的核心价值就在于帮助模型学会这种“偏好层面”的优化。
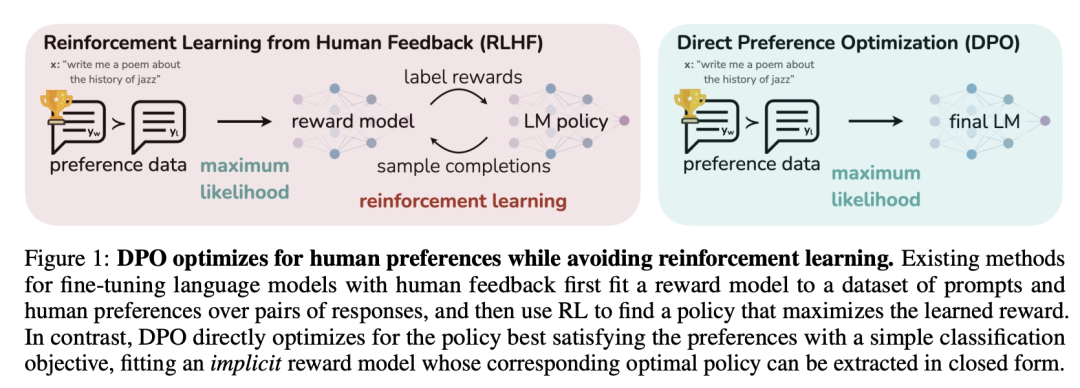
不过,传统 RLHF 的实现流程其实并不简单。通常来说,它并不是直接拿偏好数据去训练语言模型,而是要先经过一个中间步骤,即先收集大量人类偏好比较数据(即对于一个问题的两个回复判断哪个回复更好并打分),训练一个奖励模型(Reward Model),让这个奖励模型学会判断“哪个回答更好”;然后再把这个奖励模型作为打分器,结合强化学习算法(例如 PPO),去进一步优化原有的大语言模型。也就是说,传统 RLHF 往往包含了“偏好数据 → 奖励模型 → 强化学习优化”这样一整套较长的链路。

也正因为这一流程涉及的模块较多、训练步骤较长、实现成本较高,研究者们很自然地会去思考一个问题:既然我们手里已经有了“哪个回答更好、哪个回答更差”的偏好数据,能不能不再额外训练奖励模型,而是直接利用这些偏好信息来优化语言模型本身?
从这个角度看,DPO(Direct Preference Optimization,直接偏好优化) 的提出,其实正是对这一问题的直接回应。它试图绕开传统 RLHF 中“先训练奖励模型、再用强化学习优化策略模型”的复杂流程,转而采用一种更直接的方式:直接使用偏好数据对模型进行优化。因此,从理解路径上来说,你完全可以把 DPO 看作是对传统 RLHF 流程的一种简化——它并没有否定“人类偏好”这件事的重要性,而是试图用一种更简洁、更稳定、也更易于落地的方式,把“人类更喜欢什么样的回答”这件事直接融入模型训练中。
也正因为如此,DPO 成为了近年来偏好对齐领域中非常重要的一类方法。它既保留了“通过偏好数据优化模型”的核心思想,又尽可能降低了传统 RLHF 在工程实现上的复杂度。在本节课中我们也会对其重点进行讲解。
DPO 原理剖析
在正式进入 DPO(Direct Preference Optimization) 之前,我们其实有必要先退一步,先弄清楚两个更基础的问题:
什么是强化学习(Reinforcement Learning, RL)? 为什么大语言模型已经做了预训练、又做了 SFT,却还需要 RLHF 这类方法继续优化?
只有把这两个问题想明白,后面再去理解 DPO、PPO 这些方法时,才不会觉得它们只是“又一种新的训练算法”,而会真正明白:它们其实是在解决大模型训练流程中一个非常关键、但又很难靠传统监督学习彻底解决的问题——如何让模型的回答更符合人类偏好。
强化学习原理
从直觉上看,强化学习(Reinforcement Learning, RL) 其实并不难理解。它所研究的核心问题并不是“给定输入,如何直接拟合标准答案”,而是:当一个系统不断采取行动并获得反馈时,它要怎样逐渐学会更优的行为策略。
这和我们熟悉的监督学习有一个很明显的区别。监督学习更像是在做“对照答案练习”:模型看到输入,再去逼近一个明确给定的目标输出;而强化学习更像是在做“不断试错后的行为调整”:系统先自己作出一个选择,然后外部环境再告诉它,这次做得是好是坏,接着系统再根据这个反馈去修正自己的下一步行为。
因此,强化学习里最重要的,不再只是“答案本身”,而是行为之后得到的反馈。
通常来说,在强化学习框架中,会有几个最基本的角色。首先是 Agent(智能体),也就是负责作出决策的主体;然后是 Environment(环境),也就是智能体所处的外部系统;智能体会在环境中采取某种 Action(动作),环境则根据这个动作返回一个 Reward(奖励);而智能体最终真正要学会的,则是一套更好的 Policy(策略),也就是“在什么情况下,更应该采取什么样的动作”。

如果把这个思路放到日常生活中,其实很好理解。比如一个人刚开始学骑自行车时,并不会一开始就知道怎样保持平衡。他只能不断尝试:重心偏了会摔倒,方向控制得更好时就能骑得更稳。经过反复试错后,他并不是背下了某一个固定动作,而是逐渐形成了一套更有效的控制策略。强化学习本质上也是一样,它并不是简单地记住某个标准答案,而是通过不断试错—获得反馈—调整策略的过程,逐步学会更好的决策方式。

所以,如果要用一句话概括强化学习的本质,那么可以这样理解:
强化学习不是在直接学习“正确答案”,而是在学习“什么样的行为更值得被继续强化”。
这其实非常重要,因为后面当我们把视角转到大语言模型时就会发现,在很多场景下,模型面对的并不是“只有一个标准答案”的问题,而是“有很多都能说得通的回答,但其中有些明显更好”。而这种“在多个可能行为中学习更优倾向”的问题,恰恰就是强化学习所擅长处理的。
强化学习作用
理解了强化学习之后,接下来就要问一个更贴近大模型训练流程的问题:为什么大语言模型需要强化学习?
从表面上看,一个大模型在完成预训练和 SFT 之后,好像已经具备了相当强的能力。它能理解问题,能生成通顺的回答,也能完成很多复杂任务。那么,为什么还要继续引入强化学习这一步?
其根本核心原因就在于,“会生成”并不等于“生成得更符合人类偏好”。
在预训练阶段,模型最主要的学习目标通常是根据上文预测下一个 token。通过这种方式,模型的确能够掌握大量语言规律、知识模式以及文本组织能力,因此它会变得“很会说”。但这里的“会说”,更多解决的是语言流畅性与知识建模能力,而不是回答质量的价值判断。模型可能能说出一段很像样的话,但这段话未必最有帮助、未必最安全,也未必最符合用户真正想要的表达方式。
而到了 SFT 阶段,情况虽然进一步改善了。通过人工构造的指令—回答样本,模型开始学会按照人类要求来回答问题,看起来也更像一个“助手”了。但 SFT 本质上仍然是在做监督拟合。也就是说,它更擅长让模型学习“面对这种输入,大致应该生成什么样的输出”,却不太擅长精细地区分:当两个回答都不算错时,到底哪一个更值得优先生成。
比如,面对同样一个问题:“什么是过拟合?”,模型可能给出两种不同回答。第一种结构清晰、表达自然、照顾初学者理解;第二种虽然术语上也没错,但行文混乱、重点不清、读者读完后帮助有限。对于人来说,我们很容易判断前者更好;但对模型而言,如果只是依赖预训练或普通的监督学习,它未必能真正学会这种“相对偏好关系”。
这也意味着,大模型训练到了这个阶段,关注点就不再只是“能不能回答问题”,而是开始转向另一个更高层次的问题:
在多个可能回答都成立的前提下,模型究竟应该更倾向于哪一种回答,才能更符合人类真实偏好?
而这,正是强化学习在大模型中最重要的作用。它的意义并不是取代预训练或 SFT,而是在这些基础能力之上,进一步推动模型从“会回答”走向“回答得更好”。这里的“更好”通常体现在很多维度上,比如更有帮助、更自然、更安全、更符合人类表达习惯,或者更符合具体任务目标。也正因为如此,强化学习在大模型中的角色,往往不是去教模型基础语法和知识,而是对模型已有能力进行进一步的行为校正与偏好优化。
换句话说,如果说预训练主要解决的是“模型有没有语言能力”,SFT 主要解决的是“模型能不能按指令做事”,那么强化学习进一步解决的,就是“模型在已经能做事的基础上,能不能做得更符合人类期待”。
DPO 核心思想
当我们已经意识到,大模型需要学习“什么样的回答更值得被偏好”之后,接下来的问题就是:这种人类偏好,到底要怎样变成模型真正可以学习的训练信号?无论是 PPO 还是 DPO 算法,其本质上都在解决同一个核心问题:当同一个问题可能对应多种回答时,模型究竟应该更倾向于生成哪一种回答,才能更符合人类的偏好。
举个例子,假设面对同一个问题:“什么是过拟合?”,模型可以给出两个不同的回答:
chosen:解释清晰,结构自然,对初学者友好rejected:虽然不一定完全错误,但表达混乱、帮助有限
在人类偏好对齐训练中,我们的目标并不是简单地让模型把 chosen 这条答案“背下来”,而是希望模型真正学会这样一种倾向:
当面对同样的输入时,更倾向于为“被偏好”的回答分配更高的概率,而为“未被偏好”的回答分配更低的概率。
也正因为如此,与 SFT 主要基于“一问一答”的监督样本不同,人类偏好对齐训练的核心学习对象不再是单条答案,而是一组成对出现的偏好样本,也就是常说的 preference pair(偏好对)。
其典型的数据形式通常如下所示:
{
"prompt":"...",
"chosen":"...",
"rejected":"..."
}
在这样的数据结构中,prompt 表示用户输入的问题,chosen 表示人类更偏好的回答,而 rejected 则表示相对不被偏好的回答。模型训练的关键,不是孤立地学习某一个答案本身,而是学习在同一个问题下,为什么一个回答比另一个回答更值得被优先生成。
这也是它和普通 SFT 的根本区别。SFT 更关注的是“给定一个输入,模型能否生成目标答案”;而 DPO 进一步关注的是“面对多个都可能成立的回答时,模型是否能够更稳定地倾向于人类更喜欢的那个版本”。因此,DPO 所优化的,不再只是单个回答的生成能力,而是回答之间的相对偏好关系。
理解了这一点之后,DPO 的工作方式就比较自然了。它和 PPO 一样,通常不是从零开始训练,而是建立在一个已经完成 SFT 的模型之上。也就是说,在进入 DPO 训练之前,模型已经具备了基本的指令跟随能力和任务完成能力,能够“基本回答问题”。而 DPO 的任务,则是在这个基础上进一步调整模型的输出倾向,让它回答得更自然、更有帮助、更符合人类偏好。只不过 PPO 里是通过奖励模型(Reward Model)打分来优化模型,而 DPO 则是直接把“人类更喜欢 chosen、而不是 rejected”这件事,直接写进模型训练目标之中。
具体来说,在 DPO 训练中,模型会反复看到大量这样的偏好样本,同一个 prompt 对应一个 chosen 和一个 rejected。训练的目标,就是让模型逐步学会:在面对这个 prompt 时,更倾向于生成 chosen,而不是 rejected。
不过,这里还有一个关键问题,即模型怎么知道自己现在的“偏好方向”是不是合理的?或者说,它怎么知道自己是在“朝着更好的方向移动”,而不是过度偏移、破坏原有能力?这就引出了 DPO 中一个非常重要的角色:参考模型(reference model)。
通常来说,这个参考模型就是前面经过 SFT 之后得到的模型副本,并且在 DPO 训练阶段保持冻结,不参与参数更新。它的作用并不是继续学习,而是充当一个稳定的比较基准。因此,在训练过程中,DPO 并不是只看“当前模型是否更喜欢 chosen”,而是进一步比较:
当前模型对 chosen和rejected的偏好差异参考模型对 chosen和rejected的偏好差异
DPO 真正关心的是当前模型相对于参考模型,是否变得更加偏向 chosen,同时更加远离 rejected。这一点非常关键。因为如果没有参考模型,训练目标就会变成一种比较粗暴的形式:不断提高 chosen 的概率、不断压低 rejected 的概率。虽然表面上也能体现偏好优化,但这样做容易导致模型更新过猛,偏离原本通过 SFT 学到的语言能力和任务能力。
而引入参考模型后,模型的更新就不再是“无约束地拉高和压低”,而是变成了以原有模型能力为锚点,在此基础上朝着更符合偏好的方向进行调整。
因此,从训练流程上看,DPO 大致可以理解为以下逻辑:
首先,先通过 SFT 训练得到一个具备基本能力的初始模型; 然后,复制出一个冻结的参考模型,作为训练中的比较基准; 接着,在每一条偏好样本上,比较当前模型和参考模型对 chosen、rejected的相对偏好程度;最后,通过优化,让当前模型相对于参考模型更明显地偏向 chosen,同时更明显地远离rejected。
从直觉上看,DPO 的训练就像是在不断重复这样一个过程:
这两个回答中,人类更喜欢 chosen参考模型对这两个回答已经有一个原始倾向 当前模型需要在这个基础上进一步强化对 chosen的支持,并削弱对rejected的偏好当这种训练在大量样本上持续进行之后,模型整体输出就会越来越符合人类偏好
也正因为如此,DPO 常常被认为是把传统偏好对齐问题转化成了一种更直接的比较学习问题。它不再像传统 RLHF 那样,先训练奖励模型去学习“哪个回答值多少分”,再借助 PPO 等强化学习算法去优化语言模型;而是直接利用“这两个回答谁更好”这样的偏好关系,把偏好信息本身变成训练信号,从而更直接地更新模型参数。
除了最基础的 prompt + chosen + rejected 结构之外,偏好数据集还可以加入一些额外设计,以进一步提升训练效果。例如,可以加入 system prompt(系统提示),为模型提供更明确的行为约束与回复风格指导;也可以包含 多轮对话数据,以支持带有偏好标注的更复杂交互场景;此外,还可以补充适当的 元数据,如偏好强度、标注者一致性等信息,为训练提供更多辅助信号。总体来看,高质量的偏好数据集是成功开展 DPO 训练的关键。这类数据不仅需要具备清晰、稳定且一致的偏好标注,还应尽可能贴合具体目标场景与实际应用需求。
比如,在实际操作中,我们就可以到 ModelScope 或其他开源平台上查看和 DPO 相关的偏好数据集,观察它们是如何组织 prompt、chosen 和 rejected 的,并进一步理解 DPO 训练所依赖的数据基础。

综合来看,DPO 的核心思想其实并不复杂。它希望模型不要只是“能回答”,而是要“更倾向于回答得更好”;而它的工作方式也并不是凭空完成的,而是依赖 偏好对数据 + 当前模型 + 参考模型 之间的比较关系,把“人类更喜欢哪个回答”这件事直接转化为模型的训练目标。
不过,到这里我们仍然还停留在直觉层面。接下来还有一个更关键的问题:
这种“让模型更偏向 chosen、远离 rejected”的目标,究竟是如何被写成一个具体的损失函数的?
这也正是下一部分要进一步讨论的内容——DPO 的核心损失函数。
损失函数
函数解析
DPO 的核心思想最终体现在它的损失函数中,所以我们可以基于该公式来深入的看看其是如何运转的。下面部分可能有一点点难懂,但是假如你慢慢跟随着我的思路的话,理解肯定是没有问题的:
其中:
表示当前正在训练的模型; 表示参考模型,通常就是前面提到的 SFT 模型; 表示更受偏好的回答; 表示相对不被偏好的回答; 是一个控制优化强度的超参数; 是 sigmoid 函数。
从整体上看,这个损失函数的目标可以概括为一句话:希望当前模型相对于参考模型,进一步拉大“优质回答”和“劣质回答”之间的偏好差距。也就是说,模型不仅要更倾向于生成更优的回答,还要尽量减少对较差回答的偏向。
在整条公式中,最核心的部分其实是下面这一项:
如果暂时忽略掉 ,那么这一部分实际上是在比较两件事。其中,第一项 可以理解为当前模型相较于参考模型,对优质回答的支持变化了多少;而 则表示:当前模型相较于参考模型,对劣质回答的支持变化了多少。

为了更好地理解这一点,我们可以继续往下拆。首先 表示当前训练中的模型,在给定输入 的情况下生成优质回答 的概率;而 则表示参考模型在同样条件下生成这一优质回答的概率。对于劣质回答 来说,含义也是完全对应的。
因此,这里先做“相除”,本质上是在看一个相对变化倍数。例如,对于优质回答来说,此时返回的值表示当前模型相对于参考模型,对这一回答的支持是增强了还是减弱了。
如果这个比值大于 1,说明当前模型比参考模型更偏向这个优质回答; 如果这个比值小于 1,说明当前模型反而比参考模型更不偏向这个优质回答; 如果这个比值等于 1,说明当前模型与参考模型对它的偏向没有变化。
对劣质回答的那一项也是同样的道理。接下来再取 ,其主要作用是把原本的“倍数关系”转化为更方便比较和优化的形式。取对数之后:
比值大于 1 时,对应的结果为正; 比值小于 1 时,对应的结果为负; 比值等于 1 时,对应的结果为 0。
这样一来,我们就可以更直观地判断:当前模型相对于参考模型,到底是更支持某个回答,还是更不支持某个回答。最后,再将前后两项相减:
这一步就非常关键了。它表示的并不是“模型是否提高了优质回答的概率”这么简单,而是在比较当前模型相对于参考模型,对优质回答的偏向增强了多少;以及对劣质回答的偏向又增强了多少。
如果前者更大、后者更小,那么这个结果就会更大,也就意味着当前模型正在比参考模型更明显地偏向优质回答,同时远离劣质回答。这正是 DPO 希望通过训练实现的目标。
换句话说,DPO 真正关心的,并不是某个回答的绝对概率高不高,而是:
优质回答相对于劣质回答,是否在当前模型中获得了更大的相对优势。
这也是为什么 DPO 本质上学到的不是“某一条固定答案”,而是一种回答之间的偏好排序关系。
案例解析
我们可以举一个例子来实际计算一下,例如,假设在某个输入 xxx 下:
当前训练模型对优质回答 的概率为 0.5 当前训练模型对非优质回答 的概率为 0.3 参考模型对优质回答 的概率为 0.1 参考模型对非优质回答 的概率为 0.3
对于优质回答,其计算出来的比值为:
这说明当前模型相对于参考模型,对优质回答的支持增强了 5 倍。而对于非优质回答,其计算出来的比值为:
这说明当前模型相对于参考模型,对非优质回答的支持没有变化。接着我们可以代入 DPO 的核心比较项,由于 ,所以结果就是:
这个值是正数,并且还比较大,说明当前模型相对于参考模型,明显更加偏向优质回答,而并没有同步增强对非优质回答的支持。这正是 DPO 希望模型学习到的方向。
如果进一步假设 ,那么再经过 sigmoid 计算(把任意实数压缩到 0 到 1 之间的函数):
对应的单条样本损失为:
此时这个损失值比较小,说明这条样本上模型已经较好地朝着“偏向优质回答、远离非优质回答”的方向进行了调整。
相反,假如在同一个输入下:
当前训练模型对优质回答 的概率为 0.15 当前训练模型对非优质回答 的概率为 0.6 参考模型对优质回答 的概率为 0.1 参考模型对非优质回答 的概率为 0.3
那么此时对于优质回答:
对于非优质回答:
代入核心比较项后得到:
这个值变成了负数,说明虽然当前模型对优质回答的支持比参考模型略有提升,但它对非优质回答的支持提升得更多。也就是说,模型并没有真正朝着“更偏向优质回答”的方向优化,反而在某种程度上更靠近了非优质回答。
如果继续取 ,对应的单条样本损失为:
这个损失值明显更大,也说明这一条样本上的优化方向并不理想。
所以,从这个例子可以看出,DPO 并不是只看模型有没有提高优质回答的概率,而是看:
模型相对于参考模型,对优质回答的偏向,是否超过了它对非优质回答的偏向。
只有当前者提升更多、后者没有同步提升甚至被压低时,模型才算真正朝着我们期望的方向在优化。
损失值的判定标准
前面所说的“损失值较小”或者“损失值较大”,其评判标准通常可以以 0.693 作为一个重要的分水岭。这个标准来自于 DPO 核心比较项恰好为 0 的情况。也就是说,当下面这一项两者相减后结果为 0 时:
此时 ,也就意味着基于 DPO公式的缩写计算出来的值约为 0.693:
所以当 loss 约等于 0.693 ,说明模型在这条样本上基本是中立的。也就是没有明显更偏向 chosen,也没有明显更偏向 rejected。
当 loss 小于 0.693,说明 ,也就是说模型已经开始朝着我们想要的方向走了,它更偏向 chosen 而不是 rejected 。并且,loss 越小,通常说明这种偏向越明显。例如:
0.5:说明模型已经有一定程度地偏向 chosen0.3:说明这种偏向已经比较明显 0.1:说明模型对 chosen的偏向已经很强
当然,在真实训练过程中,我们通常不会只关注单条样本的损失,而是更关注整体训练过程中的平均表现,例如:
一个 batch 的平均 loss 整个训练集的平均 loss 验证集的平均 loss
这时候,“loss 大还是小”就不能只看某一个静态数值,而更应该关注它的变化趋势。例如,如果训练过程中 loss 呈现出这样的变化:
第 1 轮:0.82 第 2 轮:0.71 第 3 轮:0.60
这通常说明模型正在逐渐学会更稳定地偏向 chosen,训练方向是合理的。相反,如果 loss 的变化是:
第 1 轮:0.60 第 2 轮:0.75 第 3 轮:0.88
那么这往往说明模型在这项偏好学习任务上的表现变差了,训练方向可能出现了问题。因此,在实际训练中,loss 的变化趋势往往比某一个单独数值更重要。单个时刻的 loss 只能提供局部信息,而持续下降的 loss 才更能说明模型是否真的在朝着我们期望的方向优化。
概率计算方式
在理解 DPO 损失函数时,还有一个非常关键的问题需要说明,就是像 这样的概率值到底是怎么得到的?这里的“概率”看起来像是在给整条回复打分,但大语言模型本身明明是一个 token 一个 token 地往后生成的,那么为什么公式里却直接写成了“整条回答的概率”呢?
要理解这一点,需要先明确, 并不是某一个单独 token 的概率,而是在给定输入 的条件下,模型生成整条优质回复 的条件概率。
假设优质回复 由 个 token 组成,即:
那么对于一个自回归语言模型来说,这整条回复的概率并不是一次性算出来的,而是按照“逐 token 生成”的方式分解得到的:
$$\pi_\theta(y_w \mid x) = \prod_{t=1}^{T} \pi_\theta(y_{w,t} \mid x, y_{w,<t}) $$="" 其中,$y_{w,<t}$ 表示在第="" $t$="" 个="" token="" 之前已经生成出来的所有="" token。这条公式表示整条回复的概率,等于模型在每一步生成当前 token 的条件概率连乘起来。换句话说,模型虽然是逐个 token 进行预测的,但当我们想评价“整条回复在模型看来有多合理”时,就需要把这条回复中每一个 token 的生成概率都结合起来考虑。因此,DPO 公式中写的 ,本质上表示的是模型对整段回答作为一个完整序列的支持程度。
同理,对于较差回答 ,也有:
$$\pi_\theta(y_l \mid x) = \prod_{t=1}^{T'} \pi_\theta(y_{l,t} \mid x, y_{l,<t}) $$="" 因此,DPO 在比较的并不是“某一个 token 是否更可能被生成”,而是在同一个输入条件下,模型对整条优质回复和整条劣质回复分别赋予了多大的整体概率。不过,在实际计算时,如果直接对很多个 token 的概率做连乘,数值会变得非常小,不方便计算,也不利于训练稳定。因此,工程实现中通常不会直接使用原始概率,而是改为计算对数概率(log probability)。根据对数的性质,上面的连乘可以转化为连加:
$$\log \pi_\theta(y_w \mid x) = \sum_{t=1}^{T} \log \pi_\theta(y_{w,t} \mid x, y_{w,<t}) $$="" 同样对于较差的回复也是:还需要特别说明一点,这里通常只统计回复部分(completion)的 token,而不会把输入 prompt 本身也作为需要优化的输出一起计入。也就是说, 的含义是:在给定输入 的前提下,模型生成回复 的条件概率。输入 只是条件,而不是被评分的对象。
综合来看,DPO 公式中的 和 ,并不是单独某一个 token 的概率,而是模型对整条优质回复和整条劣质回复的整体支持程度。也正因为如此,DPO 学到的并不是局部某几个 token 的偏好,而是对整段回答质量的一种整体性偏好判断。
参考模型的价值
在 DPO 中,参考模型(reference model)通常就是前面经过 SFT 后得到的模型,并且在后续偏好优化阶段保持冻结,不再参与更新。它的存在并不是为了单独完成某项预测任务,而是为了给当前正在训练的模型提供一个稳定的比较基准。换句话说,DPO 真正关心的,并不是当前模型绝对上是否喜欢某个回答,而是当前模型相对于参考模型,是否更偏向优质回答,同时更远离劣质回答。
这一点非常重要。因为如果没有参考模型,训练目标就会变成单纯地“提高 chosen 的概率、降低 rejected 的概率”。虽然听起来合理,但这样做容易导致模型为了追求偏好优化而发生过大的分布漂移,进而破坏原本已经具备的语言能力、指令跟随能力以及泛化能力。参考模型的作用,正是在偏好优化过程中为当前模型提供一个“锚点”,使模型的更新始终建立在已有能力基础之上,而不是无限制地偏离原始分布。
简单来说所以假如没有参考模型,我们只能判断当前模型在同一个输入下是否更偏向 chosen,而无法判断这种偏向是否相对于原始模型真正有所提升;有了参考模型之后,我们比较的就不再是当前模型的绝对偏好,而是当前模型相对于参考模型的偏好变化。
举个例子,若当前模型对 chosen 和 rejected 的概率分别为 0.4 和 0.2,那么从绝对值看,它确实更偏向 chosen。但如果参考模型对 chosen 和 rejected 的概率分别为 0.1 和 0.2,则说明当前模型显著增强了对 chosen 的支持,属于有效进步;而如果参考模型对 chosen 和 rejected 的概率分别为 0.3 和 0.05,则说明当前模型虽然表面上仍更偏向 chosen,但相较于参考模型,其对 rejected 的支持反而提升得更多,这就不能算作真正朝着偏好优化方向改进。由此可见,参考模型的价值不在于提供一个额外分数,而在于提供一个稳定的比较基线,使我们能够判断模型是否相对于原有能力基础发生了真正有意义的偏好改进。
从这个角度来看,DPO 中参考模型的价值,其实和传统 RLHF 中的 KL 控制 有着非常接近的思想来源。在传统 RLHF 中,模型通常先经过 SFT,随后再通过奖励模型和 PPO 等强化学习算法继续优化。在这个过程中,如果只是一味追求更高的奖励分数,模型就可能逐渐偏离原来的 SFT 分布,出现回答风格失真、语言质量下降甚至奖励投机等问题。因此,RLHF 往往会在目标函数中显式加入一个 KL 惩罚项,用来约束当前策略模型不要离参考策略太远。其形式通常可以写成:
这里的含义是模型一方面希望获得更高的奖励,另一方面又要受到 KL 项的约束,避免与参考模型之间的差异过大。也就是说,在 RLHF 中,参考模型主要承担的是一种分布约束器的角色,它通过 KL 惩罚告诉当前模型:“可以往高奖励方向优化,但不要偏离原来的能力基线太远。”
而在 DPO 中,虽然不再显式写出一个单独的 KL 控制项,但参考模型的思想并没有消失,而是被更紧密地融入到了损失函数内部。DPO 的核心比较项写作:
从形式上看,这里并不是直接比较当前模型对 chosen 和 rejected 的绝对概率,而是在比较当前模型相对于参考模型,对优质回答的支持增强了多少,以及对劣质回答的支持又增强了多少。
因此,DPO 中的参考模型实际上仍然在发挥“约束分布漂移”的作用,只不过这种约束不再是 RLHF 里那种显式的 KL 惩罚,而是转化成了一种相对偏好优化的方式。也就是说,DPO 不再单独告诉模型“你不能离参考模型太远”,而是通过“相对于参考模型的概率比”来隐含地控制更新方向。
因此,可以把两者的关系概括为:
RLHF 中的参考模型主要通过显式 KL 惩罚来限制策略漂移;而 DPO 中的参考模型则通过相对概率比的形式,被直接写进了偏好优化目标之中。
两者虽然实现方式不同,但底层思想是一致的,其都是希望模型在学习人类偏好的同时,尽可能保留原有模型已经具备的语言能力和任务能力,避免因为偏好优化过于激进而“学偏”。
从工程实现上看,这也是 DPO 相比传统 RLHF 的一个重要优势。传统 RLHF 需要单独考虑奖励模型训练、策略优化以及 KL 系数调节等多个环节;而 DPO 则把“偏好优化”和“参考约束”更自然地统一到了同一个损失函数中。这样一来,参考模型不再只是一个训练过程中的附加控制项,而成为了 DPO 数学形式中不可缺少的一部分。
综合来看,参考模型在 DPO 中至少具有三层价值:
它为当前模型提供了一个稳定的能力基线; 它帮助限制模型在偏好优化中的过度漂移; 它使得“偏好学习”能够被写成一个清晰的相对优化目标。
也正因为如此,参考模型并不是 DPO 中一个可有可无的辅助模块,而是整个方法能够成立并保持稳定训练的关键支点之一。
应用场景
那 DPO 最常应用的场景和 RLHF 类似,其通常适用于这样一类场景,即模型本身已经具备基本回答能力,但还需要进一步优化其输出风格、帮助性、稳定性以及与人类偏好的一致性。 换句话说,这类方法更适合放在模型训练流程的后段,用来解决“模型会答之后,如何答得更符合人类预期”这一问题。
从应用类型上看,DPO 比较适合用于开放式对话、通用助手对齐、指令跟随优化、格式约束、风格调优,以及多轮交互和 Agent 场景中的最终收束阶段。在这些任务中,模型面对的往往不是“唯一正确答案”,而是多个都基本可行的回答,因此训练的重点不再只是“能不能答对”,而是“能不能更稳定地生成更符合偏好的结果”。这正是 DPO 擅长处理的问题。
一个很有代表性的例子是 GLM-5。根据其技术报告,GLM-5 的后训练流程采用了一种顺序式强化学习管线,先进行多任务监督微调(Supervised Fine-Tuning, SFT),然后依次进入推理强化学习(Reasoning RL)、智能体强化学习(Agentic RL),最后进入通用强化学习(General RL)。报告中明确写到,这一最后阶段用于“人类风格对齐(human-style alignment)”,也就是说,它的目标是在专项能力训练之后,再进一步优化模型整体的回答风格与通用交互质量。这个位置和目标,与 DPO 常见的应用场景非常接近。

另一个例子是 Qwen3。Qwen3 的技术报告将后训练划分为四个阶段:Long-CoT Cold Start、Reasoning RL、Thinking Mode Fusion,以及最后的 General RL。报告中明确提到,这一阶段用于广泛增强模型在多种任务下的表现,包括指令跟随、格式跟随、偏好对齐等能力。也就是说,Qwen3 的 General RL 同样承担了“在所有专项能力训练之后,再做通用偏好优化和体验收束”的角色。

虽然根据目前公开资料,我们不能直接断言 GLM-5 的通用强化学习(General RL)或 Qwen3 的通用强化学习(General RL)就等同于标准 DPO。但是从训练阶段的位置和功能来看,GLM-5 与 Qwen3 的 通用强化学习(General RL) 都可以被看作与 DPO 目标高度接近的一类后训练步骤:它们都放在训练流程的后段或末段,用于把模型从“已经具备能力”进一步推向“更符合人类偏好、更稳定、更好用”的状态。
综合来看,DPO 最典型的应用场景,就是出现在模型后训练流程的后段或末段,用来提升模型的通用交互质量、偏好一致性与最终使用体验。GLM-5 和 Qwen3 的 General RL,都可以看作这一思路在当前大模型训练实践中的典型体现。
实操指南
在前面的内容中,我们已经从原理层面理解了 DPO(Direct Preference Optimization)到底在做什么,也知道了它的核心目标并不是单纯“记住某个标准答案”,而是让模型学会面对同一个问题时,更倾向于生成更符合人类偏好的回答。
接下来我们就正式进入实战部分,完整走一遍一次 DPO 训练的基本流程。整个实验将围绕一个开源偏好数据集展开,我们会先从原始数据中筛选出偏好关系明确、回答质量较高的样本,并将其整理成 TRL 中 DPOTrainer 所需要的标准格式;随后,再基于这些数据分别尝试 全量微调 和 QLoRA 参数高效微调 两种训练方式,观察它们在本地环境下的训练表现。
需要说明的是,这里的实验更偏向于一次教学演示型实践。我们的目标并不是在有限数据和有限显存条件下训练出一个能力大幅跃迁的模型,而是帮助大家真正看清楚 DPO 训练的数据应该如何准备、训练参数应当怎样设置、训练日志应该怎么看,以及训练完成后又该如何验证模型是否真的学到了偏好关系。
也就是说,这节实验最重要的意义,不在于“把模型训得多强”,而在于带大家亲手跑通一条完整的 DPO 偏好优化流程。只要把这一套流程真正理解并实践下来,后续无论是更换数据集、扩大训练规模,还是进一步尝试其他偏好优化方法,都会更容易上手。
代码实战
数据集准备
数据集格式
无论是对于 SFT 微调,还是对于后续的强化学习/偏好对齐训练而言,数据集的准备都是决定模型能否顺利训练、以及训练效果是否理想的核心因素之一。在 TRL 中,不同的 Trainer 对应着不同的预期数据格式,因此在正式训练之前,首先需要明确当前所使用的训练器究竟需要什么样的数据结构。

例如,前面介绍过的 SFTTrainer 主要支持 Language Modeling 和 Prompt-Completion 等数据格式;而对于 DPOTrainer 来说,它主要面向的是 Preference(偏好数据集) 格式,并且通常更推荐使用 explicit prompt(显式提示) 的写法。其基本样式如下所示:
# 标准格式
## 显式 prompt(推荐)
preference_example = {"prompt": "The sky is", "chosen": " blue.", "rejected": " green."}
## 隐式 prompt
preference_example = {"chosen": "The sky is blue.", "rejected": "The sky is green."}
# 对话格式
## 显式 prompt(推荐)
preference_example = {
"prompt": [{"role": "user", "content": "What color is the sky?"}],
"chosen": [{"role": "assistant", "content": "It is blue."}],
"rejected": [{"role": "assistant", "content": "It is green."}]
}
## 隐式 prompt
preference_example = {
"chosen": [
{"role": "user", "content": "What color is the sky?"},
{"role": "assistant", "content": "It is blue."}
],
"rejected": [
{"role": "user", "content": "What color is the sky?"},
{"role": "assistant", "content": "It is green."}
]
}
从上面的示例可以看出,DPO 所使用的偏好数据大致可以分为两类:一类是 标准格式(Standard format),另一类是 对话格式(Conversational format)。
其中,标准格式更适用于传统的文本补全或续写场景;而 对话格式则更贴近当前大语言模型最常见的聊天式交互场景。由于我们这里训练的是面向对话的大语言模型,并且希望模型能够在对话任务中学习我们的偏好,因此显然更适合选择 对话格式。同时,为了让输入结构更加清晰,也为了更方便模型明确区分“提示词”和“回复内容”,这里进一步采用 显式偏好格式 进行组织:
preference_example = {
"prompt": [
{"role": "user", "content": "What color is the sky?"}
],
"chosen": [
{"role": "assistant", "content": "It is blue."}
],
"rejected": [
{"role": "assistant", "content": "It is green."}
]
}
在这个数据结构中,prompt 表示用户输入的问题或指令,chosen 表示人类更偏好的回答,而 rejected 则表示相对不被偏好的回答。表面上看,这只是一个包含三个字段的简单字典;但从训练目标上看,它所承载的信息却比普通的一问一答数据更丰富。因为它不仅告诉模型“可以怎样回答”,更进一步告诉模型:在面对同一个问题时,为什么一个回答比另一个回答更值得被优先选择。
这也恰好与前面提到的 DPO 核心思想形成呼应:DPO 并不是单纯训练模型去复现某个答案文本,而是在训练模型学习一种偏好关系。 它真正关心的,不是让模型死记某一条 chosen 回复本身,而是让模型逐步建立起一种更稳定的生成倾向——在面对同一个 prompt 时,应该更偏向 chosen,而不是 rejected。
数据集选择
在了解完数据集格式后,接下来我们来看看这次我们训练的数据集是什么。在数据集的选择上,这里我们选择了有 ModelScope 官方开源的 DPO 训练数据集 distilabel-intel-orca-dpo-pairs[1] :
在明确了 DPOTrainer 所需要的偏好数据格式之后,接下来还需要进一步解决一个更实际的问题,究竟应该选择什么样的数据集,来完成本次 DPO 实战演示。
从训练目标来看,理想的 DPO 数据集至少需要满足几个基本条件:第一,数据本身已经具备较规范的 chosen / rejected 偏好对结构,能够较方便地转换为 TRL 所要求的格式;第二,数据规模不宜过大,否则会明显增加教学演示时的数据处理和训练成本;第三,数据质量应尽量可靠,避免由于偏好标签本身存在较大噪声而影响训练效果。
基于这些考虑,这里选择使用 AI-ModelScope/distilabel-intel-orca-dpo-pairs 作为本次实验的数据来源。该数据集对应的 Hugging Face 版本 argilla/distilabel-intel-orca-dpo-pairs 已经以标准的 chosen、rejected 结构组织好,并明确说明其适用于 preference tuning,因此非常适合作为 DPO 入门实践的数据基础。

进一步来看,这个数据集的优势并不只在于“能用”,更在于它相较于原始 Intel/orca_dpo_pairs 做过额外整理与修正。原始数据集本身大约包含 12k 条样本,而 distilabel 版本则在此基础上重新进行评估与后处理,最终形成约 12.9k 条样本的数据集。更重要的是,数据集作者指出:其中约 2000 对样本需要将原本的 chosen 与 rejected 进行交换,约 4000 对样本则应被视为 tie,即两侧回答质量接近,并不存在非常明确的偏好关系。也就是说,这个版本并不是机械地继承原始偏好标签,而是对偏好关系进行了进一步校正,这使得它更适合用来进行 DPO 训练。
除此之外,该数据集还额外提供了 status、chosen_score、original_chosen、original_rejected 等字段。这些附加信息的价值在于,它不仅方便我们直接训练,也方便我们在教学中进一步说明偏好数据并不是“只要成对就能直接拿来训练”,而是还需要考虑偏好是否足够明确、标签是否可靠、样本是否值得保留。
例如,数据集官方就给出了一个典型过滤方式:去除 tie 样本、保留 chosen_score >= 8 的高质量样本,并剔除部分可能存在污染风险的数据。经过这样的过滤后,样本量会从 12,859 条减少到 5,922 条,但作者指出这种更精炼的数据反而能够带来更好的训练效果。
因此,综合来看,选择 AI-ModelScope/distilabel-intel-orca-dpo-pairs 的原因,并不是因为它一定是所有 DPO 数据集中最强或最全面的一个,而是因为它在格式规范性、数据规模、可操作性以及偏好标签质量之间取得了较好的平衡。对于本节课这样的实战教学场景而言,我们更关注的是先让读者顺利理解 DPO 所依赖的数据结构、掌握基本的数据处理流程,并完成一次可复现的偏好训练实验。从这个角度出发,这个数据集恰好提供了一个较为合适的起点。
数据集下载
在正式使用该数据集之前,首先需要通过以下命令在终端中将其下载到本地:
modelscope download --dataset AI-ModelScope/distilabel-intel-orca-dpo-pairs --local_dir ./data/raw_data
当下载开始后,终端中就会出现熟悉的 ModelScope 标志:

待下载完成后,即可在本地看到对应的数据集文件目录:

在这些文件中,最核心的内容是 raw_data 目录下 data 文件夹中的 train-00000-of-00001.parquet 文件。这个文件中保存的就是已经整理好的 Hugging Face Dataset 格式数据,也就是后续进行 DPO 训练所需要使用的原始偏好样本。
不过,在实际训练过程中,我们通常并不会直接将整份数据集全部用于训练。一方面,受限于本地设备的显存条件,直接使用全量数据往往会带来较大的资源压力;另一方面,从教学演示的角度来看,完整数据集的训练耗时也相对较长,不利于我们快速验证训练流程与观察实验结果。因此,在本次实战中,我们将从原始数据中进一步筛选出一部分质量较高、规模更合适的样本,并在此基础上完成后续的数据清洗与格式处理工作。
数据集清洗
数据查看
在正式进行数据清洗之前,我们可以先对数据集的整体结构做一个初步查看,先弄清楚这个数据集究竟包含哪些字段、每条样本大致是什么样子。可以通过下面的代码完成这一过程:
from datasets import load_dataset
parquet_path = r"D:\微调与部署\DPO\data\raw_data\data\train-00000-of-00001.parquet"
dataset_dict = load_dataset(
"parquet",
data_files={"train": parquet_path}
)
train_ds = dataset_dict["train"]
print("总样本数:", len(train_ds))
print("列名:", train_ds.column_names)
print("第一条样本:", train_ds[0])
此时输出的结果如下:
总样本数: 12859
列名: ['system', 'input', 'chosen', 'rejected', 'generations', 'order', 'labelling_model', 'labelling_prompt', 'raw_labelling_response', 'rating', 'rationale', 'status', 'original_chosen', 'original_rejected', 'chosen_score', 'in_gsm8k_train']
第一条样本: {
"system": "",
"input": "You will be given a definition of a task first, then some input of the task... Output:",
"chosen": "[ ... ]",
"rejected": "Sure, I'd be happy to help! ...",
"generations": [
"[ ... ]",
"Sure, I'd be happy to help! ..."
],
"order": ["chosen", "rejected"],
"labelling_model": "gpt-4-1106-preview",
"labelling_prompt": [
{"role": "system", "content": "..."},
{"role": "user", "content": "..."}
],
"raw_labelling_response": "...",
"rating": [9.0, 9.0],
"rationale": "...",
"status": "tie",
"original_chosen": "[ ... ]",
"original_rejected": " ... ",
"chosen_score": 9.0,
"in_gsm8k_train": False
}
从输出结果可以看出,这个数据集总样本数有 12859 条。并且除了保存偏好训练所需的核心内容之外,还附带了不少与样本评审、打分和状态标记相关的辅助信息。其中,真正与后续 DPO 训练最直接相关的,主要是前四个字段:
system:系统提示词,用于设定模型在当前任务中的角色、语气或整体行为规则。可以把它理解为对模型的“全局说明”。input:输入内容,也就是模型需要回答的任务描述和具体问题本身。这个字段往往不仅仅是一句简单提问,还可能包含任务背景、输出要求、格式说明等信息。因此,在后续数据转换时,可以将它理解为偏好训练里的prompt,也就是模型生成回答时所面对的输入条件。chosen:偏好数据中被认为更优的回答。也就是说,在同一个input下,标注系统或评审过程认为这个回答整体质量更高,更值得模型学习。rejected:偏好数据中相对较差的回答。这里需要特别注意,“较差”并不一定等于“错误”。很多时候,rejected也可能是基本正确的,只是相比chosen来说不够简洁、不够自然、不够符合格式要求,或者在帮助性、准确性、表达质量等方面略逊一筹。
当然,除了这几个核心字段之外,数据集中还有一些元数据对于后续的数据筛选同样非常重要。例如:
rating:用于记录候选回答的评分结果。通常可以理解为对不同回答质量的量化评价,它有助于我们判断样本中的偏好差异是否足够明显。status:用于记录当前样本的状态,例如tie、unchanged、swapped等。这个字段很重要,因为它反映了这条样本在后处理或重新评估之后的偏好关系是否发生变化。比如,tie往往表示两个回答质量接近,偏好关系并不明显。chosen_score:表示chosen这一回答对应的得分。这个字段可以帮助我们进一步筛选高质量样本,例如只保留那些chosen_score较高的数据,从而让训练数据更加可靠。
这些字段虽然不会直接作为模型训练输入,但却能够为后续的数据清洗与筛选提供重要依据。也正因为如此,在真正开始构造训练集之前,先对数据集结构进行一次完整查看,是非常有必要的一步。
数据清除
由于我们这里希望保留的是偏好关系足够明确的样本,因此首先需要对原始数据集做一次初步清洗。在该数据集中,status 为 tie 的样本表示两个候选回答得分一致,也就是说,这类样本并没有体现出足够清晰的偏好差异。对于 DPO 训练而言,这种“优劣不明显”的数据通常价值有限,因此我们可以优先将其去除,仅保留 unchanged 和 swapped 两类样本。
其中,
unchanged表示该样本的偏好顺序与原始数据保持一致;swapped则表示该样本在重新评估后发现原有优劣顺序存在问题,因此已经完成了对调。无论是哪一种,只要偏好关系已经明确,都可以继续作为后续筛选的候选样本。
我们可以先通过如下代码统计各类 status 的数量分布:
from collections import Counter
status_counter = Counter(train_ds["status"])
print(status_counter)
运行后可以看到,数据集中共有 4009 条样本属于 tie:
Counter({'unchanged': 6884, 'tie': 4009, 'swapped': 1966})
接下来,我们可以使用一个简单的过滤条件,将这部分 tie 样本移除,只保留偏好关系明确的数据:
# 第一步:去掉 tie,只保留明确偏好的样本
dpo_candidate_ds = train_ds.filter(lambda x: x["status"] != "tie")
print("原始总样本数:", len(train_ds))
print("过滤 tie 后样本数:", len(dpo_candidate_ds))
# 再统计一下过滤后的 status 分布
from collections import Counter
print("过滤后的 status 分布:", Counter(dpo_candidate_ds["status"]))
此时返回的结果为:
原始总样本数: 12859
过滤 tie 后样本数: 8850
过滤后的 status 分布: Counter({'unchanged': 6884, 'swapped': 1966})
可以看到,去除 tie 之后,数据集还剩下 8850 条样本。到这一步为止,我们完成的只是第一层过滤,即先剔除偏好关系不明显的数据。接下来,还需要进一步根据回答质量和偏好强度继续筛选。
数据筛选
在完成 tie 样本的清洗之后,接下来就可以进一步根据评分信息对样本进行筛选。根据官方给出的建议,我们通常会优先保留 chosen_score 较高的样本,也就是那些“优选回答本身质量较高”的数据。这里我们先统计一下 chosen_score 的分布情况:
from collections import Counter
score_counter = Counter(x for x in dpo_candidate_ds["chosen_score"] if x is not None)
print("chosen_score 分布:")
for k in sorted(score_counter):
print(f"{k}: {score_counter[k]}")
print("chosen_score >= 8 的样本数:", sum(v for k, v in score_counter.items() if k >= 8))
输出结果如下:
chosen_score 分布:
1.0: 14
2.0: 69
3.0: 106
4.0: 192
5.0: 737
6.0: 523
7.0: 1237
8.0: 1863
9.0: 1463
10.0: 2646
chosen_score >= 8 的样本数: 5972
从结果可以看出,在过滤后的 8850 条样本中,共有 5972 条样本的 chosen_score 不低于 8 分,说明其中相当一部分样本的优选回答质量是比较高的。
不过,仅仅要求 chosen 得分高还不够。因为对于 DPO 来说,另一个同样重要的问题是:chosen 和 rejected 之间的偏好差距是否足够明显。
如果两个回答的分数非常接近,那么即便 chosen 本身质量不错,这条样本所提供的偏好信号也可能并不强。相反,如果两个回答之间存在较大的分差,就说明这条样本能够更清楚地告诉模型:在面对同一个问题时,哪一种回答更值得优先生成。
基于这一思路,我们可以进一步根据 rating 字段计算两个候选回答之间的绝对分差,并将其记为 margin:
from collections import Counter
def add_margin(example):
r = example["rating"]
if r isNone:
return {"margin": None}
return {"margin": abs(r[0] - r[1])}
scored_ds = dpo_candidate_ds.map(add_margin)
# 看看 margin 分布
margin_counter = Counter(scored_ds["margin"])
print("margin 分布:")
for k in sorted(margin_counter):
print(f"{k}: {margin_counter[k]}")
print("超过 8 分的样本数:", sum(count for margin, count in margin_counter.items() if margin isnotNoneand margin >= 8))
这里的 margin 可以理解为 chosen 与 rejected 之间的偏好强度。margin 越大,说明两者优劣差异越明显;margin 越小,则说明这条样本的偏好关系越弱。运行结果如下:
margin 分布:
1.0: 2717
2.0: 1948
3.0: 1108
4.0: 756
5.0: 685
6.0: 373
7.0: 207
8.0: 255
9.0: 770
10.0: 31
偏差超过 8 分的样本数: 1056
可以看到,在当前数据中,真正分差达到 8 分及以上的样本只剩下 1056 条。这说明虽然高分样本数量不少,但其中能够提供强偏好信号的样本其实并没有想象中那么多。
因此,接下来我们就可以同时使用这两个条件进行进一步过滤:
chosen_score不低于 8 分,保证优选回答本身质量较高;margin不低于 8 分,保证chosen与rejected之间存在足够明显的偏好差异。
对应代码如下:
from collections import Counter
# 第一步质量筛选:高质量 + 明显偏好
quality_ds = scored_ds.filter(
lambda x: x["chosen_score"] >= 8 and x["margin"] >= 8
)
print("过滤后样本数:", len(quality_ds))
print("status 分布:", Counter(quality_ds["status"]))
print("chosen_score 分布:", Counter(quality_ds["chosen_score"]))
print("margin 分布:", Counter(quality_ds["margin"]))
经过这一步筛选后,最终保留下来的就是同时满足“回答质量高”和“偏好关系明显”这两个条件的样本。由于前面已经统计过 margin >= 8 的样本数量,因此这里最终保留下来的样本数同样为 1056 条:
过滤后样本数: 1056
status 分布: Counter({'unchanged': 989, 'swapped': 67})
chosen_score 分布: Counter({10.0: 980, 9.0: 71, 8.0: 5})
margin 分布: Counter({9.0: 770, 8.0: 255, 10.0: 31})
考虑到本次实验的目标主要是完成一次教学演示,同时也希望尽量控制训练时间和显存消耗,因此这里不再使用全部 1056 条样本,而是从中随机抽取 500 条作为最终的数据集:
shuffled_ds = quality_ds.shuffle(seed=42)
final_500_ds = shuffled_ds.select(range(500))
print("最终选中的样本数:", len(final_500_ds))
返回的结果为:
最终选中的样本数: 500
这样处理之后,数据规模更加适合本地环境下的快速实验,也更便于后续观察训练效果。
实际上,Hugging Face 文档中也对偏好数据集的规模给出了一定的经验性建议:
至少准备约 1000 条高质量偏好数据; 更推荐使用 10000 条以上、类型更加丰富的数据; 与其使用大量低质量样本,不如优先保证少量样本的高质量。 为了避免到新场景中效果不佳,建议数据集能够覆盖全部用例并且多样化。
这也说明,在偏好优化任务中,数据质量往往比单纯的数据数量更重要。因此,在本次实验中,我们虽然最终只选取了 500 条样本作为教学演示使用,但这更多是出于本地显存条件和训练耗时控制的考虑。
如果本地设备显存更充足、训练时间也允许,那么更推荐直接使用前面筛选出的 1000 条左右高质量样本 来进行训练。这样不仅能够让模型接触到更多有效的偏好信号,也通常更有助于提升最终的训练效果。
格式调整
到这一步为止,我们已经得到了一份质量较高、偏好关系较为明确的候选数据集。但这部分数据还不能直接用于 qwen3-0.6B 的 DPO 训练,因为其字段组织方式与 TRL 推荐的偏好训练格式还不完全一致。
在前面已经提到过,TRL 推荐使用如下形式来组织偏好数据:
preference_example = {
"prompt": [
{"role": "user", "content": "What color is the sky?"}
],
"chosen": [
{"role": "assistant", "content": "It is blue."}
],
"rejected": [
{"role": "assistant", "content": "It is green."}
]
}
对于当前数据集而言,chosen 和 rejected 两个字段本身已经具备一一对应的内容,因此处理起来相对直接;真正需要额外注意的是 prompt 的构造方式。
这里不能简单地把 input 直接塞进去作为唯一输入,因为部分样本还带有 system 提示词。在这种情况下,我们需要将 system 和 input 一起组织成消息列表:如果 system 非空,就先加入一条 system 消息;然后再将 input 作为 user 消息加入进去。
除此之外,由于原始数据集并没有专门考虑“思考模式”和“非思考模式”的统一格式,而我们这里训练的目标是让模型以 no_think 的方式完成输出,因此还需要进一步补充两项格式约束:
第一,在用户输入末尾统一追加 /no_think,明确告诉模型当前样本应以非思考模式进行回复;第二,在回答开头统一补上空的思考标签 <think>\n\n</think>\n\n,从而使整个数据集在输出形式上保持一致。
也就是说,我们并不是只做字段改名,而是在完成一次面向目标模型的格式适配。只有在经过这样的转换之后,这份数据集才真正符合我们后续训练所需要的输入结构。对应的转换代码如下:
NO_THINK_SUFFIX = " /no_think"
EMPTY_THINK_PREFIX = "<think>\n\n</think>\n\n"
def build_prompt_messages(system_text, input_text):
messages = []
system_text = (system_text or"").strip()
input_text = (input_text or"").strip()
if system_text:
messages.append({
"role": "system",
"content": system_text
})
messages.append({
"role": "user",
"content": input_text + NO_THINK_SUFFIX
})
return messages
def build_assistant_message(text):
text = (text or"").strip()
return [{
"role": "assistant",
"content": EMPTY_THINK_PREFIX + text
}]
def convert_to_dpo_format(example):
return {
"prompt": build_prompt_messages(example["system"], example["input"]),
"chosen": build_assistant_message(example["chosen"]),
"rejected": build_assistant_message(example["rejected"]),
}
converted_ds = final_500_ds.map(
convert_to_dpo_format,
remove_columns=final_500_ds.column_names
)
print("转换后样本数:", len(converted_ds))
print("转换后列名:", converted_ds.column_names)
for i in range(1):
print(f"\n===== 转换后样本 {i} =====")
print(converted_ds[i])
转换完成后,数据集中的字段被统一整理为 prompt、chosen 和 rejected 三部分,同时所有样本也都被调整为符合 no_think 训练目标的统一格式。这样一来,后续就可以直接用于 DPO 训练了:
转换后样本数: 500
转换后列名: ['chosen', 'rejected', 'prompt']
===== 转换后样本 0 =====
{'chosen': [{'content': "<think>\n\n</think>\n\nThe total percentage of imports that come ... to the article.", 'role': 'assistant'}], 'rejected': [{'content': "<think>\n\n</think>\n\nBased on the information provided in the article...", 'role': 'assistant'}], 'prompt': [{'content': 'You are an AI assistant...', 'role': 'system'}, {'content': 'In 2011, Macaus free-market economy ... Hong Kong, or France? /no_think', 'role': 'user'}]}
数据集划分
在完成格式转换之后,接下来还需要将这 500 条样本划分为训练集和验证集。这样做的目的,是为了在训练完成后能够利用验证集对模型效果进行一个初步观察,而不是只看训练过程本身。
这里的划分方式与前面的实验保持一致,仍然采用 9:1 的比例进行切分:
split_ds = converted_ds.train_test_split(test_size=0.1, seed=42)
train_dpo_ds = split_ds["train"]
eval_dpo_ds = split_ds["test"]
print("总样本数:", len(converted_ds))
print("训练集样本数:", len(train_dpo_ds))
print("验证集样本数:", len(eval_dpo_ds))
输出结果如下:
总样本数: 500
训练集样本数: 450
验证集样本数: 50
也就是说,最终将有 450 条样本用于模型训练,另外 50 条样本用于后续验证。这样的划分方式既能保证训练集规模相对充足,也能保留一部分样本用于简单评估。
数据集保存
在完成切分之后,最后一步就是将处理好的数据集保存到本地。为了兼顾后续训练使用和人工查看的便利性,这里同时采用两种保存方式:
一种是保存为 Hugging Face Dataset 格式目录,便于后续直接通过 load_from_disk()读取;另一种是额外保存为 .jsonl文件,便于我们直接查看样本内容,或者在需要时做进一步的数据检查与分析。
对应代码如下:
from pathlib import Path
import json
save_dir = Path(r"D:\微调与部署\DPO\data\processed")
save_dir.mkdir(parents=True, exist_ok=True)
train_jsonl_path = save_dir / "train_dpo_no_think_450.jsonl"
eval_jsonl_path = save_dir / "eval_dpo_no_think_50.jsonl"
train_hf_path = save_dir / "train_dpo_no_think_450"
eval_hf_path = save_dir / "eval_dpo_no_think_50"
# 1. 保存 train jsonl
with open(train_jsonl_path, "w", encoding="utf-8") as f:
for item in train_dpo_ds:
f.write(json.dumps(item, ensure_ascii=False) + "\n")
# 2. 保存 eval jsonl
with open(eval_jsonl_path, "w", encoding="utf-8") as f:
for item in eval_dpo_ds:
f.write(json.dumps(item, ensure_ascii=False) + "\n")
# 3. 保存 HuggingFace Dataset 目录
train_dpo_ds.save_to_disk(str(train_hf_path))
eval_dpo_ds.save_to_disk(str(eval_hf_path))
print("训练集 jsonl:", train_jsonl_path)
print("验证集 jsonl:", eval_jsonl_path)
print("训练集 HF目录:", train_hf_path)
print("验证集 HF目录:", eval_hf_path)
print("训练集样本数:", len(train_dpo_ds))
print("验证集样本数:", len(eval_dpo_ds))
最后就能看到我们保存下的路径了:
训练集 jsonl: D:\微调与部署\DPO\data\processed\train_dpo_no_think_450.jsonl
验证集 jsonl: D:\微调与部署\DPO\data\processed\eval_dpo_no_think_50.jsonl
训练集 HF目录: D:\微调与部署\DPO\data\processed\train_dpo_no_think_450
验证集 HF目录: D:\微调与部署\DPO\data\processed\eval_dpo_no_think_50
训练集样本数: 450
验证集样本数: 50
至此,整个数据准备流程就完成了。我们已经从原始偏好数据出发,依次完成了数据清洗、质量筛选、格式转换、训练/验证集划分以及本地保存等步骤。接下来,就可以在此基础上进一步进行超参数设置,并正式开始模型训练。
超参数准备
在前面的 SFTConfig 中,我们已经介绍过大多数通用训练参数,例如学习率、批大小、梯度累积、训练轮数,以及保存与日志策略等。这些参数在 DPOConfig 中同样存在,因此这里不再重复展开。
对于 DPO 而言,更值得重点关注的是那些与偏好优化机制本身直接相关的参数。换句话说,DPO 的关键并不只是“像普通微调一样把模型继续训练下去”,而是在训练过程中回答这样几个更核心的问题:模型应当以多大的力度朝着人类偏好的方向更新、这种偏好优化具体采用什么样的损失函数形式、参考模型在其中承担什么作用,以及在有限显存条件下如何让训练过程更加稳定可控。
因此,接下来我们重点介绍几个在 DPOConfig 中更具代表性的参数,包括:控制偏好优化强度的 beta,决定损失函数形式的 loss_type,用于处理噪声偏好的 label_smoothing,以及与参考模型计算和训练稳定性密切相关的 precompute_ref_log_probs、reference_free 和 learning_rate 等参数。理解了这些参数,也就基本把握住了 DPO 训练配置中最核心的部分。
beta
beta 是 DPO 中最核心的参数之一。官方文档将其解释为用于控制当前策略模型相对于参考模型的偏离程度。beta 越大,模型越不容易偏离参考模型。在标准 DPO 中,它本质上决定了“偏好优化信号”施加得有多强。TRL 文档中给出的默认值是 0.1,这也是很多入门实验里最常见的起点。
其对应到损失函数的公式中其实就是 的值:
直观来说,可以把 beta 理解成一根“拉绳”:
当 beta较小的时候,模型会更积极地朝着chosen方向移动,也更容易远离原来的 SFT/参考模型;当 beta较大的时候,模型更新会更保守,更强调“在原有能力基础上微调偏好”,不容易发生过大的分布漂移。
对于我们这小规模 DPO 实验,通常直接从 beta=0.1 开始就可以了。后续如果发现模型变化太猛、输出风格漂移明显,可以尝试适当调大;如果发现偏好学习不明显,再考虑适当调小。
loss_type 与 loss_weights
loss_type 用来指定 DPO 训练所采用的损失函数形式。对于最标准、最经典的 DPO,通常使用的是 loss_type="sigmoid",这也是 TRL 中的默认设置,对应的正是前面介绍过的标准 DPO 损失函数。
不过,TRL 并不仅仅支持原始 DPO 一种形式,它还额外提供了 hinge、ipo、exo_pair、robust、bco_pair、aot、apo_zero、apo_down、discopop、sft 等多种变体。这也意味着,DPOConfig 并不只是简单实现了一个固定的 DPO 算法,而是统一承载了一整类偏好优化方法。不同的 loss_type,本质上对应着不同的优化目标,也就是说,虽然它们都在学习“让模型更偏向 chosen、远离 rejected”,但具体采用的损失函数形式并不相同。
例如,当 loss_type="hinge" 时,其思路就不再是通过 sigmoid 去平滑建模偏好概率,而更接近于一种 margin loss。它要求模型对 chosen 相对于 rejected 的优势至少超过某个间隔;如果尚未达到这个间隔,就继续产生损失并推动模型更新。其形式可以写为:
可以看到,虽然它仍然围绕 chosen 和 rejected 的相对偏好展开,但具体的优化方式已经和标准 DPO 的 sigmoid 损失不同了。
除此之外,在较新的 TRL 版本中,loss_type 不仅可以写成一个字符串,也可以写成一个列表。这意味着训练时并不一定只优化一种目标,而是可以将多种损失函数组合起来共同训练。此时,与之配套的 loss_weights 就用于指定各个损失项的权重。例如:
loss_type=["sigmoid", "sft"]
loss_weights=[1.0, 1.0]
这组配置的含义并不是“只做 DPO”,而是同时优化偏好损失和监督微调损失,也就是一种 DPO + SFT 联合训练 的思路。这样做的好处在于,模型在学习偏好关系的同时,也能够继续维持一定的生成稳定性与原有输出能力。
不过,对于本节课这样的入门实战来说,并不打算把重点放在这些变体或混合损失上。这里我们仍然选择最基础、也最适合作为起点的配置方式:
loss_type="sigmoid"
也就是说,本节课将先聚焦于最标准的 DPO 训练形式,先把最核心的偏好优化逻辑跑通,再在后续需要时进一步讨论其他损失函数变体或联合训练方法。
label_smoothing
label_smoothing 在 DPO 里不是默认必须调的参数。但它在某些变体中非常重要。这个参数背后的含义是:现实中的偏好数据并不一定完全干净,有些 chosen / rejected 可能存在误标、边界模糊或评审不稳定的情况。此时,适当引入 label_smoothing,相当于告诉模型:“不要把每一条偏好标签都当成百分之百绝对正确。”
不过,对于我们这部分数据集已经经过筛选、而且专门保留了高分高分差样本的数据集来说,通常可以先保持:
label_smoothing=0.0
也就是先按“偏好标签可信”来训练。后续假如我们用的数据集可能不一定准确时可以看情况进行添加。
precompute_ref_log_probs 与 precompute_ref_batch_size
DPO 训练与普通的监督微调有一个很明显的不同点:在训练过程中,它不仅需要计算当前模型对 chosen 和 rejected 的输出概率,还需要同时计算参考模型在相同样本上的输出概率。也正因为如此,参考模型的前向计算会额外带来显存占用和计算开销。
其中,precompute_ref_log_probs 的作用,就是在正式训练开始之前,先将参考模型在训练集和验证集上的 log probability 预先计算并缓存下来。这样一来,后续训练时就不需要反复调用参考模型进行前向计算,从而能够减少重复计算带来的额外开销,并在一定程度上缓解训练阶段的显存压力。
而与之配套的 precompute_ref_batch_size,则用于控制预计算参考模型 log probability 时所使用的批大小。它影响的并不是正式 DPO 训练阶段的 batch size,而是“预计算这一步”一次送入多少条样本。这个参数同样需要结合显存情况来设置:如果设得过大,预计算时依然可能出现显存不足;如果设得过小,虽然更稳妥,但预计算过程也会相对更慢一些。
一般来说,在以下几种情况下,这组参数会尤其值得考虑:
参考模型本身较大,前向计算成本较高; 本地显存资源比较紧张; 数据集规模相对可控,适合提前完成预计算。
当然,这两个参数也并不是在任何场景下都必须开启。因为预计算本身需要额外的时间,同时缓存结果也会带来一定的存储开销。不过,结合本次实验的实际情况来看,我们当前的显存条件相对有限,而数据集规模又不算特别大,因此提前缓存参考模型的 log probability 往往是一个更稳妥的选择。
基于这一点,这里建议将 precompute_ref_log_probs 开启;同时,precompute_ref_batch_size 则应根据显存大小设置为一个相对保守的值,例如:
precompute_ref_log_probs=True
precompute_ref_batch_size=1
其中,precompute_ref_log_probs=True 的作用是启用参考模型概率的预计算与缓存,而 precompute_ref_batch_size=8 则表示在预计算阶段每次使用 1 条样本进行前向计算。这样做的主要目的,并不是改变 DPO 本身的训练逻辑,而是通过提前完成参考模型结果的计算,尽量减轻正式训练阶段的显存压力,使整个训练过程更容易在本地环境下顺利跑通。
reference_free
在标准 DPO 中,参考模型(reference model)扮演着非常重要的角色。它通常就是前面经过 SFT 得到的初始模型,并在后续偏好优化阶段保持冻结不变。而 reference_free 这个参数,控制的就是训练时是否显式使用这份参考模型。
当设置为 reference_free=True 时,训练过程将不再显式依赖一份冻结的参考模型,而是近似地假设参考分布是一个“均匀的、常数式的基准分布”。换句话说,此时模型优化时关注的重点就不再是“相对于参考模型的变化”,而更接近于只根据当前模型自身对 chosen 和 rejected 的偏好差异来学习。
这样做的好处是,训练流程会更简化一些,也不需要再额外维护一份真正的参考模型;但它的代价也很明显,那就是标准 DPO 中最关键的“参考锚点”被弱化了。一旦失去了这个对照基准,模型虽然仍然可以学习偏好关系,但“是在原模型基础上做受约束的偏好优化”这一层含义就不再那么明确了。
也正因为如此,在本节课的实战中,更推荐保持默认设置:
reference_free=False
这样做的原因并不是因为 reference_free=True 一定不能用,而是因为对于入门阶段来说,保留参考模型能够更完整地体现 DPO 的核心思想,也更有利于理解后续损失函数中为什么会同时出现当前模型和参考模型的概率项。
learning_rate
虽然学习率在之前的课程里也有提到过,但在 DPO 训练中,学习率是一个需要特别谨慎设置的超参数。与普通的监督微调相比,DPO 的目标并不是让模型大幅度学习全新的生成模式,而是在原有模型能力的基础上,进一步调整其对 chosen 与 rejected 的偏好关系。也正因为如此,DPO 往往更强调一种保守、稳定的更新方式,以避免模型在偏好优化过程中偏移过快,进而破坏原本已经具备的语言能力、指令跟随能力以及输出稳定性。因此,在实际训练中,DPO 的学习率通常会设置得比 SFT 更低一些,比如设置为 5e-6。
不过,学习率也不能脱离具体训练方式单独来看。若采用全参数训练,由于模型中所有参数都会参与更新,因此学习率通常需要设置得更加保守,一般可以从较小的范围开始尝试;而如果采用的是 LoRA / QLoRA 这类参数高效微调方法,由于真正被更新的只是少量新增参数,因此学习率可以适当提高一些,但整体上仍然建议保持比 SFT 更谨慎的设置。
结合本节课的实验目标来看,我们这里更关注的是完成一次稳定的小规模 DPO 偏好优化,而不是对模型能力进行大幅度改写。因此,学习率更适合从一个偏保守的范围开始设置。如果后续训练过程中出现 loss 波动明显、输出质量下降或者模型回答风格异常偏移等现象,就应优先考虑进一步减小学习率。
也就是说,在 DPO 训练中,学习率的设置原则并不是“越大越快”,而是要尽量在训练稳定性和偏好学习效果之间取得平衡。对于入门实验而言,宁可设置得稍微保守一些,也比因为学习率过大而导致训练不稳定更稳妥。
训练脚本准备
在介绍完 DPO 中几个较为关键的超参数之后,接下来就可以正式进入训练代码部分了。总体来看,DPO 的训练流程与前面介绍过的 SFT 训练并没有本质上的差别,核心步骤仍然包括:准备模型路径、读取数据集、加载 tokenizer、构建模型以及配置训练参数等。真正的区别主要体现在两个方面:一是 DPO 训练通常还需要额外考虑参考模型的处理方式;二是训练参数中会多出一些与偏好优化直接相关的配置项。
全量模型训练脚本
首先来看最基础、也最容易理解的一种方式——全量模型训练。所谓全量训练,指的是在训练过程中直接对模型本体参数进行更新,而不是只训练附加的小规模适配参数。对于理解 DPO 的完整训练流程来说,这种方式最直观,因为它完整保留了“策略模型 + 参考模型 + 偏好优化目标”这一标准结构。
在这一版本的脚本中,我们首先需要完成几项基础准备工作:定义基础模型路径、训练集与验证集路径,以及最终模型输出目录;随后读取前面已经处理好的 DPO 数据集,并加载对应的 tokenizer。由于这里使用的是 Qwen 系列模型,因此还需要保证 pad_token 可用,避免后续在批处理时出现不必要的问题。
接下来最关键的一步,是同时加载两份模型:一份作为当前参与训练的 policy model,另一份作为保持冻结的 reference model。这正是 DPO 与普通 SFT 相比最典型的区别之一。在 SFT 中,我们通常只关心一个模型如何去拟合目标答案;而在 DPO 中,训练时还需要额外保留一个参考模型,作为当前模型进行偏好更新时的比较基准。也正因为如此,在代码层面会看到同时加载 model 和 ref_model 两份模型。
随后,就可以通过 DPOConfig 配置训练所需的各项参数。例如,批大小、梯度累积、训练轮数、学习率调度策略,以及前面已经介绍过的 beta、loss_type、precompute_ref_log_probs 等。这些参数共同决定了 DPO 训练究竟会以怎样的方式进行:既要让模型学习偏好关系,又要尽量控制训练过程中的稳定性与显存消耗。
在完成参数配置之后,使用 DPOTrainer 将模型、参考模型、训练参数、数据集和 tokenizer 组织起来,就可以正式开始训练了。整体来看,这套全量训练脚本最适合用来帮助读者理解 DPO 的标准训练流程,因为它把参考模型、偏好损失以及完整参数更新过程都保留得比较清晰。训练完成后,模型的检查点和相关输出结果会被保存到指定目录中,便于后续继续评估或加载使用。
具体脚本内容如下所示:
import torch
from datasets import load_from_disk
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import DPOConfig, DPOTrainer
# =========================
# 1. 路径配置
# =========================
model_name_or_path = r"D:\微调与部署\qwen" # 改成你的基础模型路径
train_dataset_path = r"D:\微调与部署\DPO\data\processed\train_dpo_no_think_450"
eval_dataset_path = r"D:\微调与部署\DPO\data\processed\eval_dpo_no_think_50"
output_dir = r"D:\微调与部署\DPO\outputs\qwen3_dpo_full"
# =========================
# 2. 读取数据集
# =========================
train_dataset = load_from_disk(train_dataset_path)
eval_dataset = load_from_disk(eval_dataset_path)
# =========================
# 3. 加载 tokenizer
# =========================
tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path,
trust_remote_code=True
)
# Qwen 一类模型通常需要确保 pad_token 可用
if tokenizer.pad_token isNone:
tokenizer.pad_token = tokenizer.eos_token
# =========================
# 4. 加载 policy model 和 reference model
# 这是最朴素的 DPO 写法
# =========================
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
ref_model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# 关闭 cache,训练时更稳一些
model.config.use_cache = False
ref_model.config.use_cache = False
# =========================
# 5. DPO 训练参数
# =========================
training_args = DPOConfig(
output_dir=output_dir,
# 基础训练参数
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=8,
num_train_epochs=1,
# 学习率
learning_rate=5e-6,
lr_scheduler_type="cosine",
warmup_ratio=0.1,
# 日志与保存
logging_steps=5,
eval_strategy="steps",
eval_steps=20,
save_strategy="steps",
save_steps=20,
save_total_limit=2,
# DPO 核心参数
beta=0.1,
loss_type="sigmoid",
# 长度控制
max_length=512,
# 让训练时不常驻 reference model,节省显存
precompute_ref_log_probs=True,
precompute_ref_batch_size=1,
)
# =========================
# 6. 构建 DPOTrainer
# =========================
trainer = DPOTrainer(
model=model,
ref_model=ref_model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
processing_class=tokenizer,
)
# =========================
# 7. 开始训练
# =========================
trainer.train()
训练完成后大家就可以在文件夹中看到对应的输出结果:

QLoRA 模型训练
除了直接进行全参数训练之外,在实际使用中,更常见也更实用的一种做法是采用 QLoRA 方式来完成 DPO 微调。这样做的主要原因在于全量训练对显存要求较高,而 QLoRA 通过低比特量化与 LoRA 适配参数训练的结合,可以显著降低资源消耗,使得在本地设备上完成 DPO 训练成为可能。
与前面的全量训练相比,QLoRA 版本的整体流程仍然是相似的:同样需要准备路径、读取数据集、加载 tokenizer,并设置好训练参数。不同之处主要在于模型加载与训练方式的变化。这里不再直接加载完整精度模型,而是先通过 4bit 量化配置对模型进行压缩,然后在此基础上为 k-bit 训练做准备。这样做的目的,是在尽可能保留模型能力的前提下,大幅降低显存占用。
在完成量化模型加载后,还需要进一步配置 LoRA 参数。也就是说,此时真正参与训练的并不是原始模型的全部参数,而是插入到模型线性层中的一小部分可训练适配参数。这样做的好处非常明显,一方面,显存占用会显著下降;另一方面,训练速度通常也会更加可控。对于本节课这种以教学演示为主的实验场景来说,QLoRA 往往是更具有现实可操作性的方案。
在训练参数设置上,QLoRA 版本也会与全量训练略有区别。例如,为了进一步节省显存,通常会启用梯度检查点;同时,由于训练的只是少量适配参数,学习率往往可以设置得比全量训练略高一些。此外,在这个版本中,ref_model 不再单独显式加载,而是由 Trainer 以初始策略模型作为参考,这也是参数高效微调场景中较常见的一种写法。
总体来看,QLoRA 版本的代码虽然在工程配置上比全量训练稍复杂一些,但它更贴近实际开发中的常见做法。尤其是在本地显存有限的情况下,QLoRA 能够显著降低 DPO 训练门槛,使得偏好优化不再只是高算力环境下才能完成的任务。训练结束后,同样会在输出目录中生成对应的模型文件与检查点,便于后续继续使用和测试。
具体的脚本设置如下所示:
import torch
from datasets import load_from_disk
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, prepare_model_for_kbit_training
from trl import DPOConfig, DPOTrainer
# =========================
# 1. 路径配置
# =========================
model_name_or_path = r"D:\微调与部署\qwen" # 改成你的基础模型路径
train_dataset_path = r"D:\微调与部署\DPO\data\processed\train_dpo_no_think_450"
eval_dataset_path = r"D:\微调与部署\DPO\data\processed\eval_dpo_no_think_50"
output_dir = r"D:\微调与部署\DPO\outputs\qwen3_dpo_qlora"
# =========================
# 2. 读取数据集
# =========================
train_dataset = load_from_disk(train_dataset_path)
eval_dataset = load_from_disk(eval_dataset_path)
# =========================
# 3. tokenizer
# =========================
tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path,
trust_remote_code=True,
use_fast=False,
)
if tokenizer.pad_token isNone:
tokenizer.pad_token = tokenizer.eos_token
# =========================
# 4. 4bit 量化配置(QLoRA)
# =========================
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16,
)
# =========================
# 5. 加载量化模型
# =========================
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
trust_remote_code=True,
quantization_config=bnb_config,
device_map="auto",
)
model.config.use_cache = False
# 为 k-bit 训练做准备
model = prepare_model_for_kbit_training(model)
# =========================
# 6. LoRA 配置
# QLoRA 风格建议 target_modules="all-linear"
# =========================
peft_config = LoraConfig(
r=8, # 6GB 显存先保守一点
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
)
# =========================
# 7. DPO 训练参数
# =========================
training_args = DPOConfig(
output_dir=output_dir,
# 小显存核心参数
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=8,
gradient_checkpointing=True,
# 训练轮数
num_train_epochs=1,
# LoRA 训练学习率可略高一些
learning_rate=1e-5,
lr_scheduler_type="cosine",
warmup_steps=0.1,
# 日志 / 验证 / 保存
logging_steps=5,
eval_strategy="steps",
eval_steps=20,
save_strategy="steps",
save_steps=20,
save_total_limit=2,
# DPO 核心
beta=0.1,
loss_type="sigmoid",
# 长度可以适度增加,QLoRA 训练时通常不会爆显存
max_length=1024,
# 让训练时不常驻 reference model,节省显存
precompute_ref_log_probs=True,
precompute_ref_batch_size=1,
)
# =========================
# 8. DPOTrainer
# ref_model=None:让 Trainer 使用初始 policy 作为 reference
# =========================
trainer = DPOTrainer(
model=model,
ref_model=None,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
processing_class=tokenizer,
peft_config=peft_config,
)
# =========================
# 9. 开始训练
# =========================
trainer.train()
训练完后我们同样可以看到对应的模型文件:

训练过程
全量模型
从这次全量 DPO 微调的训练日志来看,整体训练过程是比较正常且有效的。模型在训练过程中逐步学会了更明显地区分 chosen 与 rejected,也就是说,偏好优化确实起到了作用。虽然中间个别 step 会有一定波动,但从总体趋势上看,关键指标大多在朝着较好的方向发展。
{'loss': '0.6829', 'grad_norm': '146', 'learning_rate': '3.333e-06', 'entropy': 'nan', 'num_tokens': '3.742e+04', 'logits/chosen': '-2.176', 'logits/rejected': '-2.543', 'mean_token_accuracy': '0.6143', 'rewards/chosen': '-0.0184', 'rewards/rejected': '-0.04012', 'rewards/accuracies': '0.325', 'rewards/margins': '0.02172', 'logps/chosen': '-116.6', 'logps/rejected': '-223.3', 'epoch': '0.08889'}
...
{'eval_loss': '0.3418', 'eval_runtime': '94.85', 'eval_samples_per_second': '0.527', 'eval_steps_per_second': '0.527', 'eval_entropy': 'nan', 'eval_num_tokens': '2.739e+05', 'eval_logits/chosen': '-2.295', 'eval_logits/rejected': '-2.405', 'eval_mean_token_accuracy': '0.7018', 'eval_rewards/chosen': '-0.8888', 'eval_rewards/rejected': '-2.682', 'eval_rewards/accuracies': '0.8', 'eval_rewards/margins': '1.794', 'eval_logps/chosen': '-165.1', 'eval_logps/rejected': '-275.8', 'epoch': '0.7111'}
...
{'loss': '0.3594', 'grad_norm': '55.25', 'learning_rate': '4.257e-08', 'entropy': 'nan', 'num_tokens': '3.776e+05', 'logits/chosen': '-2.438', 'logits/rejected': '-2.569', 'mean_token_accuracy': '0.6791', 'rewards/chosen': '-0.9492', 'rewards/rejected': '-2.772', 'rewards/accuracies': '0.825', 'rewards/margins': '1.823', 'logps/chosen': '-231.9', 'logps/rejected': '-293.4', 'epoch': '0.9778'}
{'train_runtime': '3519', 'train_samples_per_second': '0.128', 'train_steps_per_second': '0.016', 'train_loss': '0.4387', 'entropy': '0.5963', 'num_tokens': '3.845e+05', 'logits/chosen': '-2.749', 'logits/rejected': '-2.81', 'mean_token_accuracy': '0.8045', 'rewards/chosen': '-1.056', 'rewards/rejected': '-2.601', 'rewards/accuracies': '0.8', 'rewards/margins': '1.546', 'logps/chosen': '-125.7', 'logps/rejected': '-296.1', 'epoch': '1'}
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 57/57 [58:38<00:00, 61.73s/it]
先看这些日志字段本身的含义。
loss表示当前训练步的 DPO 损失值,它反映的是模型在当前批次上对偏好关系的学习情况。这个值越小,通常说明模型越能够把chosen和rejected区分开来。不过需要注意,DPO 的loss和前面 SFT 中的逐 token 负对数似然不是同一种定义,因此它的绝对数值不能直接和 SFT 的 loss 横向比较。这里更重要的是观察它在同一次训练内部是否大体呈下降趋势。grad_norm表示当前梯度的范数,可以粗略理解为“这一步参数更新信号有多强”。如果这个值过大并持续剧烈波动,往往意味着训练可能不够稳定;如果整体逐步回落,则通常说明训练逐渐进入更平稳的阶段。在你的日志中,grad_norm从前期的146、95.5,到中间出现一次较高的217,随后又下降到32.5、55.25这一带,整体上说明训练后期的更新幅度比前期更趋于平稳。learning_rate就是当前步对应的学习率。由于你这里使用了余弦退火调度,因此它会随着训练推进逐渐下降:前期大约在5e-6附近,后期逐步衰减到7.597e-07、2.975e-07,最后接近4.257e-08。这说明训练后半段会越来越偏向于细致、小步幅的调整,而不是继续做大幅更新。num_tokens表示到当前为止累计处理过的 token 数量,它更多是一个训练进度指标。你的训练最终累计处理了大约3.845e+05个 token。epoch则表示训练已经推进到当前数据集的哪个阶段,这里最终完成了1个 epoch。对应的总训练时间大约是3519秒,也就是接近58分钟,和最后显示的57/57步、总耗时58:38是一致的。logits/chosen和logits/rejected表示模型在chosen和rejected上的平均 logit 表现;logps/chosen和logps/rejected则更直接,表示模型对这两类回答的对数概率。一般来说,我们更关心的是:模型是否在训练过程中逐渐让chosen的表现优于rejected。从你的日志看,logps/chosen始终明显高于logps/rejected,例如一开始是-116.6对-223.3,后面也多次保持类似差距,最终汇总时为-125.7对-296.1,这说明模型整体上确实更倾向于给chosen更高概率。mean_token_accuracy表示在 token 层面上的平均正确率,它可以帮助我们粗略观察模型输出与目标的一致程度。不过在 DPO 训练里,这个指标并不是最核心的,因为 DPO 的目标并不是单纯复现某个标准答案,而是学习偏好关系。因此,它可以作为辅助参考,但不能代替偏好指标本身。你的日志中这个值大多在0.56到0.71之间波动,最终训练汇总为0.8045,验证时大约在0.70左右,整体表现还可以,但它并不是这里最应该重点解读的指标。
真正最值得关注的是 rewards/chosen、rewards/rejected、rewards/accuracies 和 rewards/margins 这组指标。
其中,rewards/chosen 和 rewards/rejected 可以理解为模型分别对优选回答和劣选回答打出的相对奖励;通常我们希望 chosen 的奖励高于 rejected。rewards/accuracies 表示在当前批次中,有多少比例的样本满足“chosen 的奖励高于 rejected”,这个值越接近 1 越好。rewards/margins 则表示两者之间的平均奖励差距,差距越大,说明模型对偏好关系的区分越明显。
从这次训练结果来看,这组指标的趋势是非常有代表性的。训练刚开始时,rewards/accuracies 只有 0.325,rewards/margins 也几乎只有 0.02172,这说明模型在初期对 chosen 和 rejected 的区分还非常弱。可是在训练继续推进后,rewards/accuracies 很快提高到 0.825、0.75、0.8,中后期最高达到 0.85;与此同时,rewards/margins 也从几乎接近 0 快速扩大到 0.5326、1.252、1.352,再到后面的 1.797、2.396。这说明模型越来越能够把优选回答和劣选回答拉开距离,也就是偏好优化正在发挥作用。验证集上的表现也基本一致,第一次验证时 eval_rewards/accuracies=0.82、eval_rewards/margins=1.562,第二次验证时 eval_rewards/accuracies=0.8、eval_rewards/margins=1.794,说明模型不仅在训练集上学到了偏好关系,在验证集上也保持了较好的泛化。
最后再看 eval_loss,两次验证分别为 0.3473 和 0.3418,整体比较稳定,而且略有下降。这说明模型在验证集上的 DPO 目标并没有变差,反而有小幅改善。结合 eval_rewards/accuracies 始终维持在 0.8 左右、eval_rewards/margins 保持在 1.5 到 1.8 之间来看,可以认为这次训练并没有出现明显的过拟合迹象,至少从当前这一个 epoch 的结果上看,训练和验证的趋势是比较一致的。
不过,这份日志中也有几个细节值得提醒。第一,loss 虽然总体是在下降,但并不是单调下降的,例如中间从 0.404 又回到了 0.5066,后面也有 0.2004 之后回升到 0.4518 的情况。这其实很正常,因为 DPO 本身是小批次偏好优化,训练波动往往比传统 SFT 更明显。只要整体趋势没有失控,而且验证指标保持稳定,就不必因为个别 step 的反弹而过于紧张。第二,日志中的 entropy 多次显示为 nan,这通常说明当前训练配置下并没有有效记录这个指标,或者该项统计在当前实现里没有正常输出。由于其他关键指标都比较完整,因此这个问题本身不算严重,不会影响我们对整体训练趋势的判断。
综合来看,这次全量 DPO 微调的结果是比较积极的。一方面,训练损失总体下降,验证损失保持稳定;另一方面,更关键的偏好指标——尤其是 rewards/accuracies 和 rewards/margins——都呈现出明显改善,说明模型确实越来越倾向于给 chosen 更高奖励、给 rejected 更低奖励。换句话说,这次训练基本达到了 DPO 的核心目的:模型学会了更明显地偏向人类偏好的回答。
参数高效模型
另外,从这次参数高效微调(QLoRA)的训练日志来看,整体训练过程同样是有效的,模型也逐步学会了更明显地区分 chosen 和 rejected。虽然从绝对数值上看,它的提升幅度没有全量微调那样激进,但整体趋势依然是比较正常的,说明即使只训练少量适配参数,模型仍然能够学到较清晰的偏好关系。
{'loss': '0.6921', 'grad_norm': '16.75', 'learning_rate': '6.667e-06', 'entropy': 'nan', 'num_tokens': '3.742e+04', 'logits/chosen': '-2.733', 'logits/rejected': '-2.983', 'mean_token_accuracy': '0.6883', 'rewards/chosen': '-0.01511', 'rewards/rejected': '-0.01862', 'rewards/accuracies': '0.525', 'rewards/margins': '0.003508', 'logps/chosen': '-153.3', 'logps/rejected': '-311.9', 'epoch': '0.08889'}
...
{'eval_loss': '0.3693', 'eval_runtime': '42.31', 'eval_samples_per_second': '1.182', 'eval_steps_per_second': '1.182', 'eval_entropy': '0.758', 'eval_num_tokens': '2.739e+05', 'eval_logits/chosen': '-2.832', 'eval_logits/rejected': '-3.036', 'eval_mean_token_accuracy': '0.7488', 'eval_rewards/chosen': '-0.6262', 'eval_rewards/rejected': '-1.921', 'eval_rewards/accuracies': '0.9', 'eval_rewards/margins': '1.294', 'eval_logps/chosen': '-203', 'eval_logps/rejected': '-360.7', 'epoch': '0.7111'}
...
{'loss': '0.3591', 'grad_norm': '11.06', 'learning_rate': '8.513e-08', 'entropy': '0.8417', 'num_tokens': '3.776e+05', 'logits/chosen': '-2.767', 'logits/rejected': '-3.096', 'mean_token_accuracy': '0.6809', 'rewards/chosen': '-0.5866', 'rewards/rejected': '-1.818', 'rewards/accuracies': '0.925', 'rewards/margins': '1.231', 'logps/chosen': '-271.1', 'logps/rejected': '-351.7', 'epoch': '0.9778'}
{'train_runtime': '1396', 'train_samples_per_second': '0.322', 'train_steps_per_second': '0.041', 'train_loss': '0.472', 'entropy': '0.6444', 'num_tokens': '3.845e+05', 'logits/chosen': '-2.886', 'logits/rejected': '-2.887', 'mean_token_accuracy': '0.7769', 'rewards/chosen': '-0.5687', 'rewards/rejected': '-1.703', 'rewards/accuracies': '0.7', 'rewards/margins': '1.134', 'logps/chosen': '-134.2', 'logps/rejected': '-315.2', 'epoch': '1'}
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 57/57 [23:16<00:00, 24.49s/it]
先看损失值,训练初期 loss=0.6921,后续逐步下降到 0.5986、0.534、0.4265,中后期最低达到 0.2548,最后整体训练汇总为 train_loss=0.472。这说明模型确实在逐步学习偏好关系,虽然过程中也存在一定波动,但总体方向是向下的。验证集上的 eval_loss 也从第一次的 0.4367 下降到第二次的 0.3693,说明模型在验证集上的表现也在同步改善。
更关键的是偏好相关指标。训练开始时,rewards/accuracies 只有 0.525,rewards/margins 几乎为 0.003508,说明模型一开始对优选回答和劣选回答的区分还非常弱。随着训练推进,这两个指标明显变好:rewards/accuracies 多次达到 0.85、0.875、0.925,在 epoch=0.7111 时甚至达到 1.0;与此同时,rewards/margins 也从几乎为零逐步提升到 0.5673、1.059、1.443。这说明模型越来越能够把 chosen 和 rejected 拉开差距,也就是偏好优化在发挥作用。验证集上的表现同样较好,两次验证的 eval_rewards/accuracies 都稳定在 0.9,而 eval_rewards/margins 也从 0.8181 提升到了 1.294,说明模型在验证集上也保持了不错的偏好判断能力。
从训练稳定性上看,这次参数高效微调还有一个比较明显的特点,就是 grad_norm 整体比全量微调小得多,大多在 7 到 17 左右波动,没有出现特别夸张的梯度峰值。这通常意味着训练过程会更平稳一些,也更符合参数高效微调“更新幅度较小、训练成本较低”的特点。
另外,从效率上看,参数高效微调的优势也比较明显。这次训练总耗时约 23:16,而前面的全量微调大约需要 58:38,也就是说,在相同数据规模和训练轮数下,QLoRA 版本明显更省时间,也更适合本地资源有限的实验环境。综合来看,整体训练是成功的,偏好关系学到了,验证集表现也比较稳定,而且训练效率明显优于全量微调。
模型验证
在模型训练完成之后,接下来需要进一步验证本次 DPO 训练是否真正产生了效果。与前面的 SFT 模型不同,这里其实并不一定要先通过主观对话去判断模型是否“回答得更好了”,因为 DPO 训练本身优化的目标并不是单纯生成某个标准答案,而是让模型在面对同一个 prompt 时,更加偏向 chosen,而不是 rejected。
也正因为如此,对于 DPO 模型而言,一个更直接的验证思路是在验证集上分别计算模型对 chosen 和 rejected 的条件概率,然后比较模型是否确实对 chosen 赋予了更高的概率。如果训练有效,那么训练后的模型理论上就应该比原始模型更频繁地满足“chosen 的概率高于 rejected”这一条件,同时两者之间的差距也应当更明显。
换句话说,这里的验证并不是在做开放式主观评测,而是在做一种偏好一致性验证:检查模型是否真的学会了训练数据中所要求的偏好关系。
验证脚本
从整体结构上看,这个验证脚本的核心任务其实并不复杂,我们只需要设置 train_mode 并把对应的权重文件路径(也就是前面 checkpoint-xxx 文件夹的路径)进行切换即可开始测试:
import gc
import json
from pathlib import Path
import torch
from datasets import load_from_disk
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel
# =========================
# 1. 路径配置
# =========================
base_model_path = r"D:\微调与部署\qwen"
eval_dataset_path = r"D:\微调与部署\DPO\data\processed\eval_dpo_no_think_50"
# 二选一:
# 方案A:如果你要评估 QLoRA 结果
adapter_path = r"D:\微调与部署\DPO\outputs\qwen3_dpo_qlora\checkpoint-57"
trained_mode = "qlora" # 可选: "qlora" 或 "full"
# 方案B:如果你要评估 full 模型结果,就把下面路径改对
full_model_path = r"D:\微调与部署\DPO\outputs\qwen3_dpo_full\checkpoint-57"
# =========================
# 2. 基础配置
# =========================
use_bf16 = torch.cuda.is_available() and torch.cuda.is_bf16_supported()
compute_dtype = torch.bfloat16 if use_bf16 else torch.float16
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=compute_dtype,
)
tokenizer = AutoTokenizer.from_pretrained(
base_model_path,
trust_remote_code=True,
use_fast=False
)
if tokenizer.pad_token isNone:
tokenizer.pad_token = tokenizer.eos_token
eval_ds = load_from_disk(eval_dataset_path)
print("验证集数量:", len(eval_ds))
print("示例:")
print(eval_ds[0])
# =========================
# 3. 工具函数:序列化 prompt / prompt+answer
# =========================
@torch.no_grad()
def ensure_input_ids(x):
if isinstance(x, dict):
return x["input_ids"]
if hasattr(x, "input_ids"):
return x.input_ids
return x
def build_prompt_ids(prompt_messages):
x = tokenizer.apply_chat_template(
prompt_messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
)
return ensure_input_ids(x)
def build_full_ids(prompt_messages, completion_messages):
x = tokenizer.apply_chat_template(
prompt_messages + completion_messages,
tokenize=True,
add_generation_prompt=False,
return_tensors="pt",
return_dict=True,
)
return ensure_input_ids(x)
# =========================
# 4. 核心函数:计算 completion 的 logprob
# =========================
@torch.no_grad()
def get_completion_logprob(model, prompt_messages, completion_messages):
prompt_ids = build_prompt_ids(prompt_messages)
full_ids = build_full_ids(prompt_messages, completion_messages)
prompt_len = prompt_ids.shape[1]
full_ids = full_ids.to(model.device)
outputs = model(full_ids)
logits = outputs.logits[:, :-1, :]
target_ids = full_ids[:, 1:]
log_probs = torch.log_softmax(logits, dim=-1)
token_log_probs = torch.gather(
log_probs, dim=2, index=target_ids.unsqueeze(-1)
).squeeze(-1)
positions = torch.arange(target_ids.shape[1], device=full_ids.device)
completion_mask = positions >= (prompt_len - 1)
selected = token_log_probs[0, completion_mask]
seq_logp = selected.sum().item()
n_tokens = selected.numel()
avg_logp = seq_logp / max(n_tokens, 1)
return seq_logp, avg_logp, n_tokens
# =========================
# 5. 加载模型
# =========================
def load_base_model():
if trained_mode == "qlora":
base_model = AutoModelForCausalLM.from_pretrained(
base_model_path,
trust_remote_code=True,
quantization_config=bnb_config,
device_map="auto",
)
base_model.eval()
return base_model
elif trained_mode == "full":
model = AutoModelForCausalLM.from_pretrained(
base_model_path,
trust_remote_code=True,
device_map="auto",
)
model.eval()
return model
def load_trained_model():
if trained_mode == "qlora":
base_model = AutoModelForCausalLM.from_pretrained(
base_model_path,
trust_remote_code=True,
quantization_config=bnb_config,
device_map="auto",
)
model = PeftModel.from_pretrained(base_model, adapter_path)
model.eval()
return model
elif trained_mode == "full":
model = AutoModelForCausalLM.from_pretrained(
full_model_path,
trust_remote_code=True,
device_map="auto",
)
model.eval()
return model
else:
raise ValueError("trained_mode 只能是 'qlora' 或 'full'")
# =========================
# 6. 评估函数
# =========================
def evaluate_preference(model, dataset, model_name="model"):
results = []
chosen_better_sum = 0
chosen_better_avg = 0
sum_margins = []
avg_margins = []
for idx, ex in enumerate(dataset):
prompt = ex["prompt"]
chosen = ex["chosen"]
rejected = ex["rejected"]
chosen_sum, chosen_avg, chosen_n = get_completion_logprob(model, prompt, chosen)
rejected_sum, rejected_avg, rejected_n = get_completion_logprob(model, prompt, rejected)
sum_margin = chosen_sum - rejected_sum
avg_margin = chosen_avg - rejected_avg
if chosen_sum > rejected_sum:
chosen_better_sum += 1
if chosen_avg > rejected_avg:
chosen_better_avg += 1
sum_margins.append(sum_margin)
avg_margins.append(avg_margin)
results.append({
"idx": idx,
"chosen_sum": chosen_sum,
"rejected_sum": rejected_sum,
"sum_margin": sum_margin,
"chosen_avg": chosen_avg,
"rejected_avg": rejected_avg,
"avg_margin": avg_margin,
"chosen_tokens": chosen_n,
"rejected_tokens": rejected_n,
"prompt": prompt,
"chosen": chosen,
"rejected": rejected,
})
if (idx + 1) % 10 == 0:
print(f"[{model_name}] 已完成 {idx + 1}/{len(dataset)}")
metrics = {
"model_name": model_name,
"num_examples": len(dataset),
"pref_acc_sum": chosen_better_sum / len(dataset),
"pref_acc_avg": chosen_better_avg / len(dataset),
"mean_margin_sum": sum(sum_margins) / len(sum_margins),
"mean_margin_avg": sum(avg_margins) / len(avg_margins),
}
return metrics, results
# =========================
# 7. 先评估原始模型,再评估训练后模型(顺序执行,省显存)
# =========================
print("\n===== 评估原始模型 =====")
base_model = load_base_model()
base_metrics, base_results = evaluate_preference(base_model, eval_ds, model_name="base_model")
print("\n原始模型指标:")
print(json.dumps(base_metrics, ensure_ascii=False, indent=2))
del base_model
gc.collect()
torch.cuda.empty_cache()
print("\n===== 评估训练后模型 =====")
trained_model = load_trained_model()
trained_metrics, trained_results = evaluate_preference(trained_model, eval_ds, model_name="trained_model")
print("\n训练后模型指标:")
print(json.dumps(trained_metrics, ensure_ascii=False, indent=2))
del trained_model
gc.collect()
torch.cuda.empty_cache()
# =========================
# 8. 汇总对比
# =========================
print("\n===== 对比结果 =====")
print(f"pref_acc_sum: {base_metrics['pref_acc_sum']:.4f} --> {trained_metrics['pref_acc_sum']:.4f}")
print(f"pref_acc_avg: {base_metrics['pref_acc_avg']:.4f} --> {trained_metrics['pref_acc_avg']:.4f}")
print(f"mean_margin_sum: {base_metrics['mean_margin_sum']:.4f} --> {trained_metrics['mean_margin_sum']:.4f}")
print(f"mean_margin_avg: {base_metrics['mean_margin_avg']:.4f} --> {trained_metrics['mean_margin_avg']:.4f}")
# =========================
# 9. 保存详细结果,方便你后面人工看
# =========================
save_path = Path(r"D:\微调与部署\DPO\eval_compare_results.json")
with open(save_path, "w", encoding="utf-8") as f:
json.dump(
{
"base_metrics": base_metrics,
"trained_metrics": trained_metrics,
"base_results": base_results,
"trained_results": trained_results,
},
f,
ensure_ascii=False,
indent=2
)
print("\n详细结果已保存到:", save_path)
这个脚本真正的核心逻辑在 get_completion_logprob() 中。这个函数会先让模型对完整序列做一次前向计算,得到每个位置上的 logits;随后再通过 log_softmax 和 gather 的方式,提取出目标 token 的对数概率。需要特别注意的是,这里并不是对整条序列的所有 token 都进行统计,而是通过 completion_mask 只保留 completion 部分 的 token 概率。也就是说,最终比较的并不是“模型对整段 prompt+answer 的总概率”,而是“在给定 prompt 条件下,模型对 answer 本身的概率”。这一步非常关键,因为只有这样才能真正反映模型对不同回答的偏好,而不会被 prompt 本身的固定部分所干扰。
在得到 chosen 和 rejected 各自的概率之后,脚本又进一步计算了两类指标:
第一类是 总对数概率,也就是 chosen_sum和rejected_sum。它们反映的是模型对整段 completion 的累计偏好强度。第二类是 平均对数概率,也就是 chosen_avg和rejected_avg。它们相当于把总概率再除以 completion 的 token 数量,从而得到一个按长度归一化后的结果。
之所以要同时保留这两类指标,是因为 chosen 和 rejected 的长度并不总是完全一致。如果只看总和,那么较短回答有时天然更占优势;而如果看平均值,则可以在一定程度上减弱长度因素的影响。因此,脚本同时给出了基于总概率和基于平均概率的两种比较方式。
在 evaluate_preference() 函数中,脚本会遍历整个验证集,并统计四个核心指标:
pref_acc_sum:在多少比例的样本中,chosen_sum > rejected_sumpref_acc_avg:在多少比例的样本中,chosen_avg > rejected_avgmean_margin_sum:chosen_sum - rejected_sum的平均值mean_margin_avg:chosen_avg - rejected_avg的平均值
其中,前两个指标可以理解为“模型判断偏好是否正确的准确率”,后两个指标则可以理解为“模型对这种偏好的区分幅度有多大”。
因此,若训练有效,通常会看到:
pref_acc_sum和pref_acc_avg上升;mean_margin_sum和mean_margin_avg变大。
最后,脚本会分别评估原始模型和训练后模型,并把两者的指标并排输出,同时保存详细结果,方便后续人工查看具体样本。这里采用“顺序加载、顺序评估”的方式,而不是一次性把两个模型都放到显存中,也是为了降低显存占用,更适合本地实验环境。
总体而言,这个脚本本质上是在回答一个非常明确的问题:
训练之后,模型是否比训练前更倾向于为
chosen赋予更高概率,并且这种偏好差距是否变得更加明显。
这与 DPO 的训练目标是直接对应的,因此它是一种相对客观且贴合任务本身的验证方式。
指标说明
为了更方便理解后面的结果,这里再对几个关键指标做一个简要说明。
pref_acc_sum表示:在验证集全部样本中,有多少比例的样本满足chosen的总对数概率高于rejected。这个值越高,说明模型越经常能够在整体上偏向正确的偏好回答。pref_acc_avg表示:在验证集全部样本中,有多少比例的样本满足chosen的平均 token 对数概率高于rejected。与前者相比,它更强调在长度归一化之后,模型是否仍然偏向chosen。mean_margin_sum表示:chosen_sum - rejected_sum的平均值。它可以反映训练后模型在整体概率层面把两类回答拉开的程度。mean_margin_avg表示:chosen_avg - rejected_avg的平均值。它同样表示偏好差距,但由于做了长度归一化,因此更适合用来排除回答长短差异带来的影响。
简单来说:
pref_acc_*更像是在看“判断对了多少次”mean_margin_*更像是在看“拉开了多大差距”
全量模型测试结果
对于全量微调模型,原始模型与训练后模型的对比结果如下:
===== 评估原始模型 =====
Loading weights: 100%|████████████████████████████████████████████████████| 311/311 [00:00<00:00, 447.50it/s, Materializing param=model.norm.weight]
The tied weights mapping and config for this model specifies to tie model.embed_tokens.weight to lm_head.weight, but both are present in the checkpoints, so we will NOT tie them. You should update the config with `tie_word_embeddings=False` to silence this warning
[base_model] 已完成 10/50
[base_model] 已完成 20/50
[base_model] 已完成 30/50
[base_model] 已完成 40/50
[base_model] 已完成 50/50
原始模型指标:
{
"model_name": "base_model",
"num_examples": 50,
"pref_acc_sum": 0.78,
"pref_acc_avg": 0.64,
"mean_margin_sum": 138.12267578125,
"mean_margin_avg": 0.38326766388284333
}
===== 评估训练后模型 =====
Loading weights: 100%|████████████████████████████████████████████████████| 311/311 [00:01<00:00, 192.01it/s, Materializing param=model.norm.weight]
The tied weights mapping and config for this model specifies to tie model.embed_tokens.weight to lm_head.weight, but both are present in the checkpoints, so we will NOT tie them. You should update the config with `tie_word_embeddings=False` to silence this warning
[trained_model] 已完成 10/50
[trained_model] 已完成 20/50
[trained_model] 已完成 30/50
[trained_model] 已完成 40/50
[trained_model] 已完成 50/50
训练后模型指标:
{
"model_name": "trained_model",
"num_examples": 50,
"pref_acc_sum": 0.82,
"pref_acc_avg": 0.68,
"mean_margin_sum": 161.1673046875,
"mean_margin_avg": 0.48905581394906167
}
===== 对比结果 =====
pref_acc_sum: 0.7800 --> 0.8200
pref_acc_avg: 0.6400 --> 0.6800
mean_margin_sum: 138.1227 --> 161.1673
mean_margin_avg: 0.3833 --> 0.4891
从这些结果可以看出,训练后的全量模型在四项指标上都出现了提升。
其中,pref_acc_sum 从 0.78 提升到 0.82,说明训练后模型在更多样本上能够正确地给 chosen 更高的整体概率;pref_acc_avg 也从 0.64 提升到 0.68,说明即使在按回答长度归一化之后,模型对 chosen 的偏好仍然有所增强。
与此同时,mean_margin_sum 和 mean_margin_avg 也都变大了,这说明训练后模型不仅“更经常判断对了”,而且“拉开正确回答与错误回答之间的差距”也更明显了。尤其是 mean_margin_avg 从 0.3833 增长到 0.4891,意味着这种提升并不只是来源于回答长度差异,而是真正体现在 token 平均概率层面上的偏好增强。
当然,从数值上看,这种提升并不算特别剧烈,更适合描述为“有一定改善,但幅度相对有限”。这其实也是比较正常的,因为本次训练所使用的数据规模本身就不大,而且训练轮数也较少,因此模型更多是在原有能力基础上做一次较温和的偏好修正,而不是发生大幅度能力跃迁。
QLoRA 模型测试结果
对于参数高效微调模型,原始模型与训练后模型的对比结果如下:
===== 评估原始模型 =====
Loading weights: 100%|████████████████████████████████████████████████████| 311/311 [00:01<00:00, 298.82it/s, Materializing param=model.norm.weight]
The tied weights mapping and config for this model specifies to tie model.embed_tokens.weight to lm_head.weight, but both are present in the checkpoints, so we will NOT tie them. You should update the config with `tie_word_embeddings=False` to silence this warning
[base_model] 已完成 10/50
[base_model] 已完成 20/50
[base_model] 已完成 30/50
[base_model] 已完成 40/50
[base_model] 已完成 50/50
原始模型指标:
{
"model_name": "base_model",
"num_examples": 50,
"pref_acc_sum": 0.76,
"pref_acc_avg": 0.56,
"mean_margin_sum": 147.4578125,
"mean_margin_avg": 0.24917676116046616
}
===== 评估训练后模型 =====
Loading weights: 100%|████████████████████████████████████████████████████| 311/311 [00:01<00:00, 300.83it/s, Materializing param=model.norm.weight]
The tied weights mapping and config for this model specifies to tie model.embed_tokens.weight to lm_head.weight, but both are present in the checkpoints, so we will NOT tie them. You should update the config with `tie_word_embeddings=False` to silence this warning
[trained_model] 已完成 10/50
[trained_model] 已完成 20/50
[trained_model] 已完成 30/50
[trained_model] 已完成 40/50
[trained_model] 已完成 50/50
训练后模型指标:
{
"model_name": "trained_model",
"num_examples": 50,
"pref_acc_sum": 0.8,
"pref_acc_avg": 0.56,
"mean_margin_sum": 155.537578125,
"mean_margin_avg": 0.28404735577789203
}
===== 对比结果 =====
pref_acc_sum: 0.7600 --> 0.8000
pref_acc_avg: 0.5600 --> 0.5600
mean_margin_sum: 147.4578 --> 155.5376
mean_margin_avg: 0.2492 --> 0.2840
从结果来看,参数高效微调同样带来了正向变化,但整体提升幅度比全量微调更小一些。
其中,pref_acc_sum 从 0.76 提升到 0.80,说明训练后模型在整体概率层面上,确实更常倾向于 chosen;mean_margin_sum 和 mean_margin_avg 也都有所增长,这表明训练后模型对两类回答之间的偏好差距也有所扩大。
不过需要注意的是,pref_acc_avg 在这里保持为 0.56,没有出现提升。这说明当我们把回答长度因素去掉,仅从平均 token 概率的角度来看,参数高效微调后的模型并没有表现出特别明显的改善。换句话说,它确实学到了一部分偏好关系,但这种学习还不够充分,提升更多体现在整体概率和累计差距层面,而不是在长度归一化后的细粒度概率层面上。
因此,如果将这一结果与前面的全量微调进行对比,可以得到一个比较清晰的结论:参数高效微调是有效的,但提升幅度整体弱于全量微调。 这也符合直觉,因为参数高效微调本身只更新少量适配参数,其训练开销更低,但可调整的自由度也更有限,因此在相同条件下,偏好学习效果通常不会像全量更新那样明显。
综合两组实验结果来看,全量微调和参数高效微调都能够在验证集上提升模型对偏好关系的识别能力,这说明前面的 DPO 训练整体是有效的。只不过,从提升幅度上看,全量微调的效果更为明显:它不仅在偏好准确率上有所提高,而且在长度归一化后的平均概率差距上也提升得更明显;相比之下,参数高效微调虽然同样取得了改进,但整体变化更加温和。
总结
通过本节课的学习,我们围绕 DPO(Direct Preference Optimization,直接偏好优化),较为系统地完成了从原理理解到工程实战再到结果验证的完整梳理。整体来看,DPO 所要解决的核心问题并不是“模型会不会回答”,而是“当多个回答都基本可行时,模型究竟应当更倾向于哪一种回答,才能更符合人类偏好”。这也意味着,DPO 关注的重点不再只是单个答案本身,而是答案之间的相对偏好关系。
在原理层面,我们首先回顾了传统 RLHF 的基本训练链路,即通过“偏好数据 → 奖励模型 → 强化学习优化”来实现模型对齐,并进一步说明了 DPO 的提出背景:在已经拥有偏好对数据的前提下,是否可以绕开奖励模型与 PPO 等复杂强化学习步骤,直接利用偏好信息来优化语言模型。正是在这一思路下,DPO 成为了一种更加简洁、更加稳定、也更容易工程落地的偏好对齐方法。它并没有否定 RLHF 所强调的“人类偏好”本身,而是把偏好对齐问题转化成了一种更直接的比较学习过程。
在方法理解层面,我们重点剖析了 DPO 的核心损失函数,并结合具体案例说明了其中几个最关键的角色:当前训练模型、冻结参考模型、优选回答 chosen、劣选回答 rejected,以及控制偏好优化强度的超参数 beta。通过逐步拆解公式可以看到,DPO 真正优化的并不是某个回答的绝对概率,而是当前模型相对于参考模型,对优质回答的偏向增强了多少,同时对劣质回答的偏向又削弱了多少。也正因为如此,参考模型在 DPO 中并不是一个可有可无的辅助模块,而是整个方法能够成立的重要支点。它既为模型提供了稳定的能力基线,也帮助限制了偏好优化过程中可能出现的过度漂移。
在工程实践部分,我们基于 AI-ModelScope/distilabel-intel-orca-dpo-pairs 数据集完成了一次完整的 DPO 数据准备流程,包括数据结构查看、tie 样本清理、高分高分差样本筛选、对话格式转换、训练集与验证集划分以及最终保存。这一过程也进一步说明了,偏好训练的数据并不是“只要成对出现就可以直接使用”,而是需要额外关注偏好是否明确、样本质量是否足够高以及格式是否真正适配训练框架。在这个意义上,数据质量对于 DPO 的重要性,甚至往往高于单纯的数据规模。
随后,在训练配置部分,我们进一步介绍了 DPOConfig 中几个更具代表性的参数,包括控制偏好优化强度的 beta、决定损失形式的 loss_type、用于处理标签噪声的 label_smoothing,以及与参考模型计算方式相关的 precompute_ref_log_probs、reference_free 和 learning_rate 等。通过这些参数可以看到,DPO 的训练并不是简单地“把 SFT 再跑一遍”,而是需要在偏好学习强度、参考模型约束以及训练稳定性之间进行一定的平衡。
在训练实现部分,我们分别给出了全量微调和参数高效微调(QLoRA)两套训练脚本。前者更适合理解标准 DPO 的完整训练流程,后者则更贴近实际开发中对显存和资源的约束条件。训练日志分析表明,无论是全量微调还是参数高效微调,模型都能够逐步学会更明显地区分 chosen 与 rejected,说明偏好优化目标得到了有效学习。其中,全量微调在关键偏好指标上的提升幅度相对更明显,而参数高效微调虽然改善更温和,但在训练效率和资源消耗方面具有明显优势。
最后,在模型验证部分,我们没有仅依赖主观对话体验来判断训练效果,而是通过计算验证集上 chosen 与 rejected 的条件对数概率,构建了一套相对客观的偏好一致性评估方法。验证结果表明,训练后的模型无论在整体概率层面,还是在长度归一化后的平均概率层面,都比原始模型更倾向于为 chosen 分配更高概率;并且,全量微调的提升幅度整体上略强于参数高效微调。这一结果与前面的训练日志分析基本一致,也说明本次 DPO 训练是有效的。
综合来看,本节课的重点并不只是让大家“会写一个 DPO 脚本”,而是希望帮助大家真正建立起这样一种认识:DPO 的本质,是在已有模型能力基础上,利用偏好对数据,让模型学会更稳定地朝着人类偏好的方向进行输出。 它既是对传统 RLHF 的简化,也是当前大模型后训练流程中非常重要的一类方法。对于后续进一步学习更复杂的偏好优化、通用强化学习以及人类对齐方法来说,DPO 都是一个非常值得掌握的起点。
distilabel-intel-orca-dpo-pairs: https://www.modelscope.cn/datasets/AI-ModelScope/distilabel-intel-orca-dpo-pairs
-- 完 --
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有与、、、、等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 lc|LangChain 技术交流群 code | AI Coding 交流群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 推理 | AI 推理框架交流群 智能体 | Agent 技术交流群