点击下方卡片,关注“具身智能之心”公众号
01.
前言:
为什么机器人“看得懂”,却总是“做不好”?
近年来,视觉语言模型(Vision-Language Models, VLMs)已经展现出强大的多模态理解能力:它们可以识别物体、描述场景、回答问题,甚至完成复杂的视觉推理。随着具身智能的发展,VLM 也逐渐成为 Vision-Language-Action(VLA)系统中的核心“大脑”,被用于驱动机器人完成真实环境中的操作任务。
但一个关键问题仍然存在:模型会说,不代表它会做;模型看懂图像,不代表它真正理解三维物理世界。
例如,当机器人面对桌面上的杯子、餐具、衣物或背包拉链时,它不仅要识别“这是什么”,还要判断物体之间的相对距离、遮挡关系、深度结构、可操作区域,以及手臂下一步动作会如何影响环境。换言之,具身智能需要的不只是语义理解,而是对空间结构和物理约束的内在建模能力。
现有具身 VLM 的主流训练范式,往往依赖大规模视觉问答数据。这样的数据可以显著提升模型在语义问答、场景描述等任务上的表现,但它们主要强调“被动理解”,并不天然要求模型学习细粒度几何结构。另一方面,一些 VLA 方法尝试在下游动作模型中额外引入 3D、深度或空间先验,但这些物理信息往往被放在训练流程的后端,难以真正融入 VLM 的基础表征之中。那么,一个自然的问题是:能否在 VLM 预训练阶段,就让模型学会空间结构和物理 grounding?
基于这一思路,腾讯混元与清华大学团队提出了GEM:Generative Supervision Helps Embodied Intelligence。GEM 的核心思想非常直接:让具身 VLM 不仅学习“回答问题”,还要学习“生成深度”。通过将深度图生成作为辅助生成监督信号,GEM 在语言建模之外显式注入空间结构学习,使模型在预训练阶段就获得更强的三维感知、空间推理和物理操作能力。
论文标题:GEM:Generative Supervision Helps Embodied Intelligence
项目主页:https://zhaorw02.github.io/GEM/
代码:https://github.com/zhaorw02/GEM
模型 / 数据集:已在项目主页开放

02.
核心思想:给具身VLM加上“深度生成监督”
传统 VLM 的训练目标通常是文本生成,即给定图像和语言指令,让模型预测正确的回答文本。这类目标能够帮助模型建立视觉语义和语言之间的对应关系,但并不强制模型保留物体距离、几何结构和场景深度等低层物理信息。
GEM 则进一步提出:让模型在理解图像和语言的同时,生成对应的深度图。
具体来说,GEM 在 VLM backbone 之上引入一个基于 Diffusion Transformer(DiT)的深度生成头。模型首先通过自回归 VLM 提取视觉 token 和文本 token,再将最终层视觉特征通过轻量 connector 投影到生成模块的条件空间中,随后由深度生成头重建当前图像对应的深度图。
这样一来,VLM 的视觉表征就不再只是服务于语义问答,而必须同时包含足够的结构信息,以支持深度生成。模型想要生成准确深度,就必须理解哪些物体更近、哪些区域更远、物体边界在哪里、空间关系如何组织。即深度生成任务迫使模型在内部形成更具物理含义的空间表征。
这也是 GEM 与普通 SFT 具身 VLM 的关键区别:普通 SFT 更关注“图像里有什么、应该回答什么”,而 GEM 进一步要求模型理解“物体在三维空间中如何存在”。
03.
方法设计:
自回归理解 + 扩散生成的混合架构

为了同时兼顾语义理解和结构生成,GEM 采用了一种混合自回归-扩散架构。
整体框架包含三个部分:
VLM Backbone:负责图像和语言的多模态理解,提供语义和视觉 token 表征;
Connector:将 VLM 的视觉特征映射到深度生成头可用的条件空间;
Depth DiT Head:以 VLM 视觉特征为条件,通过扩散式生成目标预测深度图。
训练目标由两部分组成:一方面,模型继续使用语言建模损失,保持原有视觉语言理解能力;另一方面,模型通过 flow matching 目标学习深度图生成。两者共同优化,使模型既能保留语义理解能力,又能学习低层空间结构。
为避免生成模块和理解模块直接联合训练带来的不稳定,GEM 进一步采用渐进式训练策略:
第一阶段:Connector 初始化。 冻结 VLM backbone 和深度生成头,只训练 connector,让语义特征初步对齐到生成空间。
第二阶段:深度生成头初始化。 冻结 backbone,训练 connector 和 DiT 生成头,使生成模块具备基本的深度图重建能力。
第三阶段:生成监督联合训练。 解冻整体框架,同时优化语言建模目标和深度生成目标,让语义理解与结构建模在统一表征空间中融合。
通过这样的设计,GEM 不只是“外挂一个深度头”,而是让深度生成真正反向塑造 VLM 的视觉表征,使其更适合具身场景下的空间推理和真实操作。
04.
GEM-4M:面向具身预训练的大规模数据集
为了支撑这一训练范式,团队进一步构建了 GEM-4M,一个面向具身智能的大规模高质量预训练数据集。
GEM-4M 覆盖多类具身核心能力,包括:
具身 Grounding。 数据包含开放词汇目标检测、基于语言指令的目标定位、物体 affordance 识别等任务,帮助模型理解“哪里可以抓”“哪个物体与当前任务相关”。

物理与空间推理。 数据覆盖距离估计、空间关系判断、3D 场景理解、物理属性感知等任务,强化模型对空间结构和物理世界的基本理解。

时空规划。 数据进一步包含机器人任务中的子任务规划、下一步预测、轨迹理解等内容,使模型能够从静态理解走向动态行动规划。


通过这些数据,GEM 不仅学习了“视觉-语言”对齐,也学习了更接近机器人实际操作所需的“视觉-语言-空间-物理”统一表征。
05.
从GEM到GEM-VLA:
空间表征如何迁移到机器人操作?
具身智能模型最终要回到真实动作执行。因此,团队进一步将 GEM 扩展为 GEM-VLA,用于机器人动作预测。
在 GEM-VLA 中,模型在 GEM 的多模态表征基础上接入一个基于 DiT 的 action expert,用于生成连续动作。具体而言,模型从 VLM backbone 的注意力模块中提取多模态历史观测的 key-value token,并将其作为动作生成模块的条件表示,进而预测机器人连续动作 chunk。
这一设计的意义在于:GEM 在预训练阶段学到的空间结构和物理 grounding,并不会停留在“问答 benchmark”中,而是可以进一步迁移到真实机器人操作中,帮助动作模型做出更准确、更稳定的控制决策。
换句话说,GEM 试图回答的是一个更底层的问题:如果一个 VLM 在预训练阶段就学会了深度和几何结构,它是否会成为更好的具身大脑?
实验结果给出了肯定答案。
06.
实验结果:空间推理、具身grounding、
仿真操作、真实机器人全面提升
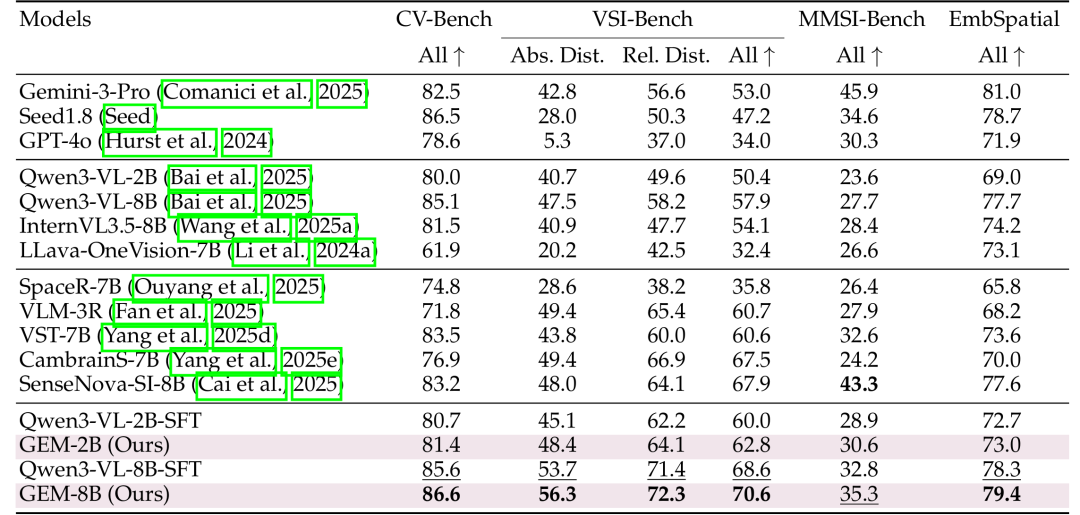
在空间推理和具身理解任务上,GEM 在多个公开 benchmark 上取得了领先表现。相比初始化 backbone,GEM 在 VSI-Bench、MMSI-Bench 等空间相关任务上带来显著提升,尤其在距离关系、相对空间判断等需要几何理解的任务中优势明显。
在细粒度具身 grounding 任务中,GEM 同样表现突出。面对 RefSpatial、Where2Place、RoboSpatial 等需要物体放置、指代表达和空间 grounding 的 benchmark,GEM在整体表现上超过了多类通用 VLM 和具身专用模型。

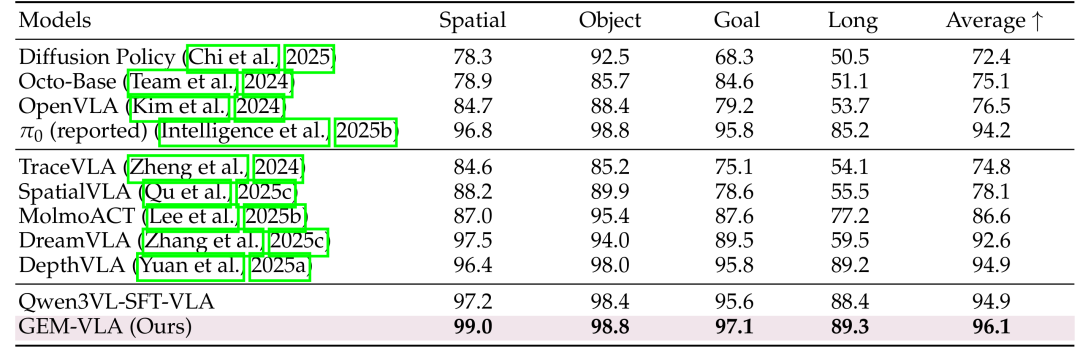
更重要的是,GEM 带来的收益并不止于视觉语言理解任务。在下游机器人操作场景中,基于 GEM 构建的 GEM-VLA 在不进行额外 VLA 预训练的情况下,便在 LIBERO 仿真 benchmark 上取得了 96.1% 的平均成功率,超过 OpenVLA、π0、DepthVLA 等代表性基线模型;并且在 Spatial、Object、Goal、Long 四类任务中均表现出稳定的泛化能力,这表明,深度生成监督所带来的空间表征增强,不只是提升了模型的理解能力,也能够进一步转化为更可靠的动作决策能力。
在真实机器人实验中,GEM-VLA 在多个具有挑战性的真实任务上进行验证,包括:
叠衣服等柔性物体操作;
拉开背包拉链;
餐具整理等长程桌面操作任务。

实验结果显示,GEM-VLA 在真实任务中的平均成功率显著超过 π0-FAST, π0.5等对比方法。尤其是在多步骤、长程操作以及柔性物体操作等更具挑战性的场景中,GEM 所学习到的空间结构与物理 grounding 能力能够带来更稳定的动作执行表现。
与此同时,消融实验也表明,深度生成监督不仅在预训练阶段有效,在 VLA finetune 阶段同样关键:当去除 finetune 过程中的深度图生成监督后,机器人操作成功率出现下降,进一步说明显式空间结构学习能够持续提升模型的具身控制能力。

07.
总结:从“会看会说”到“理解空间并能行动”
GEM 的提出,为具身 VLM 的训练提供了一条新的路径。
过去,很多工作试图通过更大规模的视觉问答数据提升具身模型能力,但问答监督本身并不一定能让模型真正掌握三维空间和物理约束。GEM 则证明,将深度图生成作为预训练阶段的辅助目标,可以有效增强模型的结构感知能力,并进一步提升空间推理、物理 grounding 和真实机器人操作表现。
从这个角度看,GEM 的意义不只是提出了一个新的具身 VLM 或 VLA 模型,而是强调了一个更基础的观点:
真正的具身智能,不应只训练模型“说出正确答案”,还应训练模型在内部形成对物理世界的结构化理解。
通过生成深度,GEM 让 VLM 学会更接近人类“空间感”的能力;通过扩展到 GEM-VLA,它进一步证明这种空间感可以迁移到真实机器人操作中。对于迈向通用具身智能而言,这或许是从语义理解走向物理行动的重要一步。












