![]() 更多精彩,请点击上方蓝字关注RVEI
更多精彩,请点击上方蓝字关注RVEI

随着大模型应用从云端训练走向推理服务、边缘部署和多样化硬件环境,AI 基础软件正在从单一加速器优化,转向 CPU、GPU、NPU 与系统软件协同演进。RISC-V作为开放指令集架构,凭借开放、低功耗、可扩展等特性,正在成为端侧 AI 推理的重要选择。
近日,MNN 官方发布 3.5.0 版本,首次官宣纳入 RISC-V 向量扩展(RVV)后端支持。在中国科学院软件研究所与南京大学持续推动下,相关优化工作围绕 MNN RISC-V 后端持续展开,标志着 RISC-V 在主流端侧 AI 推理框架中的生态适配迈出关键一步。
该成果由中国科学院软件研究所智能软件研究中心工程师刘雨冬主导完成,项目组围绕主流的 RISC-V 硬件平台,完成了 120 余个高性能算子的深度优化,在矩阵乘法、INT8 量化推理、卷积计算、图像处理等关键路径上取得最高 67.12 倍的实测加速,为开放算力时代的大模型端侧部署注入新动能。
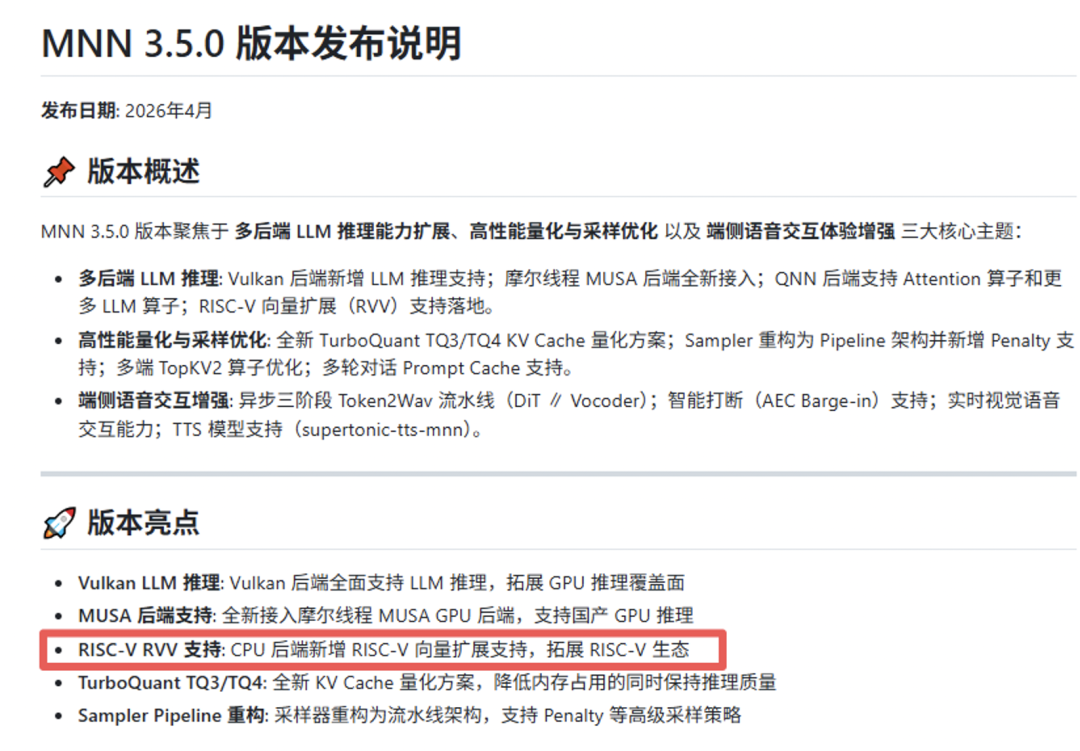
图1 MNN 3.5.0 版本发布说明中的 RISC-V RVV 支持亮点
MNN 是面向端侧推理的重要 AI 框架,广泛覆盖移动端、嵌入式设备、边缘计算与轻量化大模型场景。
项目组面向真实端侧AI 推理链路,逐层解决 MNN 在 RISC-V 平台上的后端接入、函数分发、RVV kernel 实现、INT8 量化路径补齐和跨硬件性能验证问题。
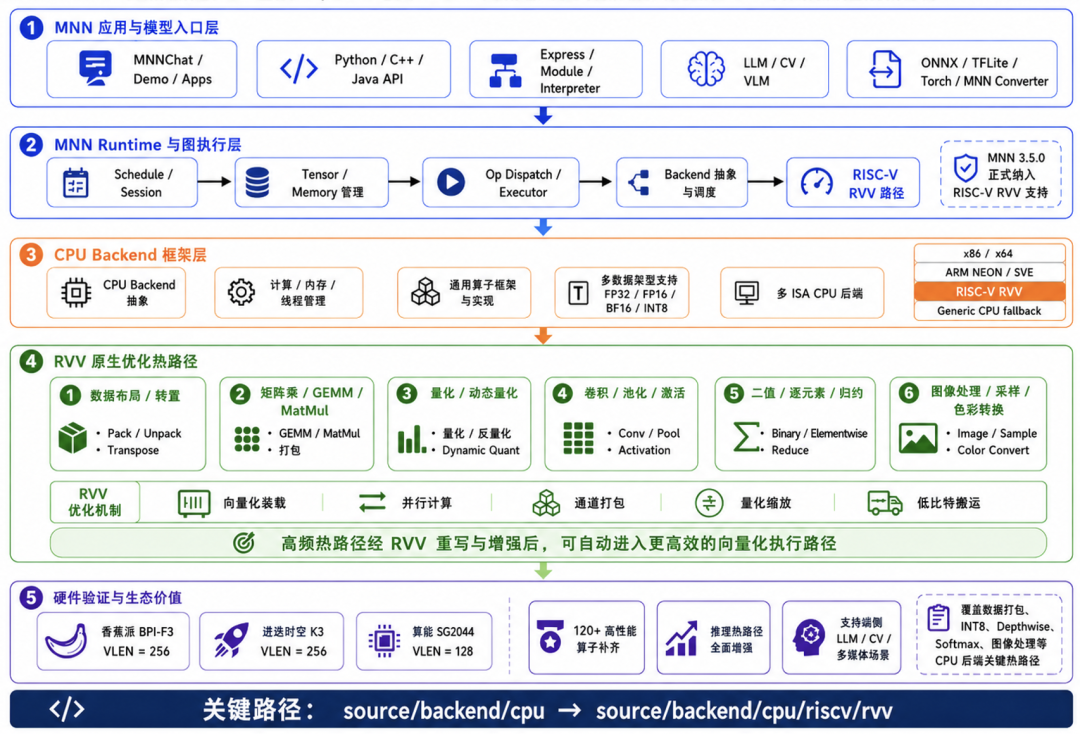
图2 MNN架构下的 RISC-V CPU 后端生态补齐
1. CPU 后端能力先行打通
MNN 要在 RISC-V 上充分释放 RVV 能力,首先需要让 RISC-V 后端进入框架原生 CPU Backend 体系,而不是停留在独立 benchmark 或外部补丁中。
项目组围绕 source/backend/cpu与source/backend/cpu/riscv/rvv 路径展开,在 CPU 后端框架层补齐 RISC-V RVV 支持,使 RVV kernel 能够通过 MNN 的 Core Function Table、MNNCoreFunctionInit、Int8FunctionsOpt 等机制进入真实算子执行路径。
这意味着,RISC-V RVV 优化不再只是“某个函数跑得快”,而是开始成为 MNN CPU 后端能力的一部分。
2. 端侧推理关键链路持续补齐
端侧推理的性能瓶颈往往并不只出现在矩阵乘或卷积大算子中。模型推理前后的数据布局转换、量化与反量化、池化、激活、Softmax、Top1、图像格式转换等基础函数,同样会影响整体推理体验。
因此,本轮优化没有只聚焦单一热点,而是围绕端侧推理链路补齐 120+ 高性能算子,覆盖:
数据布局与矩阵乘前处理
INT8 量化推理链路
卷积、Depthwise 与池化
规约、Top1、Softmax 与量化辅助
图像预处理与颜色转换
低比特数据搬运与本地候选优化
这使 MNN 在 RISC-V 上的优化从“局部算子加速”走向“端侧推理关键路径补齐”。
3. 推理热路径引入 RVV 原生优化
在 MNN 端侧推理中,数据打包、INT8 量化、Depthwise 卷积、Softmax、图像输入处理等函数调用频繁、粒度多样,是 CPU 后端的重要热路径。
本次工作通过 RVV 向量化装载、并行计算、通道打包、量化缩放、低比特搬运等机制,对这些高频路径进行重写和增强,使 RISC-V 平台能够自动进入更高效的向量化执行路径。
围绕 MNN RISC-V CPU 后端,项目组先后解决了从后端接入到核心算子的多层问题。
1. RISC-V RVV 后端工程化接入
MNN 3.5.0 官方发布说明首次将 RISC-V RVV 支持列入版本亮点,说明 RISC-V 向量扩展已经进入 MNN CPU 后端的正式能力体系。这一点非常关键。它意味着相关工作不只是实验性函数优化,而是得到了官方社区认可,开始进入 MNN 面向多硬件后端的长期演进路径。
2. 上游社区持续贡献与 PR 分类概览
截至目前,项目组围绕 MNN RISC-V/RVV CPU 后端已累计向上游社区提交 23 个 PR,其中 17个已成功合入,覆盖数据布局转换、矩阵运算、INT8 量化推理、卷积与池化、Softmax/Top1 后处理、插值采样以及图像格式转换等方向。
表1 MNN RISC-V 关键贡献概览
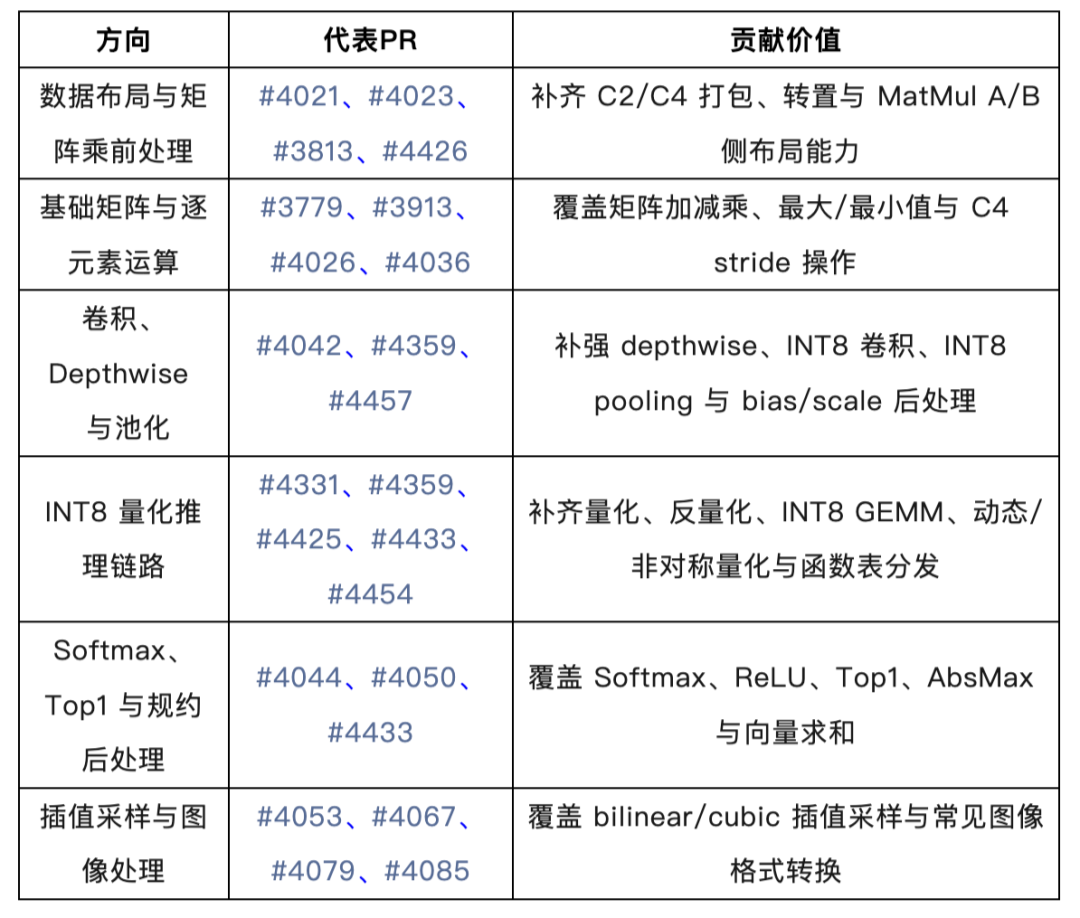
相关工作推动 RISC-V RVV 支持从单点算子优化走向 MNN CPU 后端主线能力建设,也为端侧 AI 推理在开放算力平台上的落地提供了更完整的底层执行基础。
3. 120+高性能算子补齐端侧关键路径
本轮优化覆盖 120 余个高性能算子,涉及数据布局、矩阵乘、INT8 量化、卷积、池化、Softmax、Top1、图像处理和低比特数据搬运等方向。
这些函数共同构成端侧 AI 推理中的基础执行能力。对 MNN 这类端侧推理框架来说,补齐这批函数的意义不只是提升单点性能,更是提升完整推理链路在 RISC-V 平台上的可用性和效率。
4. INT8量化推理链路系统补强
INT8 是端侧 AI 推理的重要方向,直接关系到模型运行时的内存占用、带宽压力和计算效率。
本轮优化覆盖MNNFloat2Int8、MNNInt8ScaleToFloat、MNNMaxPoolInt8、MNNAvgPoolInt8、CPUQuantizedAdd、INT8 Depthwise/Conv 等关键函数,使 MNN 在 RISC-V 平台上的低精度推理链路得到系统补强。
5. 跨 RISC-V 硬件验证与 VLEN 适配
本次测试覆盖香蕉派 BPI-F3、进迭时空 K3 和算能SG2044。其中,BPI-F3 与 K3 更贴近端侧应用场景,SG2044 则用于观察 VLEN=128 场景下的跨硬件迁移能力。
测试结果表明,RVV 优化收益不仅取决于 VLEN,也受到微架构、缓存、内存带宽和标量基线影响。这为后续做 VLEN 自适应、kernel 选择性启用和跨平台调优提供了重要依据。
验证平台:
BPI-F3:基于 SpacemiT K1,8 核 X60 RISC-V 处理器,支持 RVV 1.0,VLEN=256。
K3 Pico-ITX :包含 8 个 X100 通用 CPU 核和 8 个 A100 AI 计算核,VLEN=256。
SG2044:64 核 RISC-V 高性能处理器,支持 RVV 1.0,VLEN=128。
测试覆盖 MNN RISC-V/RVV CPU 后端中的数据布局、矩阵乘前处理、INT8 量化推理、卷积与 Depthwise、规约与 Softmax、图像预处理以及低比特数据搬运等关键路径。
图 3 展示端侧关键路径代表测试项的最佳实测加速比,不区分具体平台,便于读者快速理解各类优化在真实端侧硬件上的收益。

图 3 MNN RISC-V RVV 端侧关键路径代表加速结果
1. 数据布局与 MatMul 前处理:最高 67.12x
数据布局转换是 MNN CPU 后端的基础能力。端侧模型推理中,矩阵乘、卷积和量化计算往往都依赖前置的数据打包、通道重排和内存布局整理。RVV 优化的目标,是让这些高频数据搬运路径从标量循环进入向量化执行。
在实测结果中,MNNPackC4ForMatMul_A 是本轮最突出的单点性能亮点,它面向MatMul A 侧 C4 打包,将原本分散的访存、索引计算和逐元素搬运,整理成更适合 RVV 连续装载、批量写入和向量化重排的执行模式。实测达到 67.12x,说明该类前处理函数在大规模、规则数据搬运场景中非常适合 RVV 发挥吞吐优势。
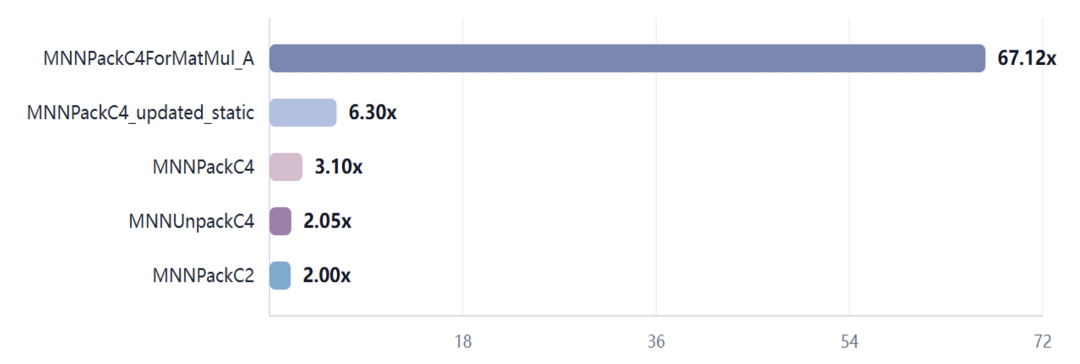
图 4 数据布局与矩阵乘前处理加速结果
对 MNN 后端来说,MNNPackC4ForMatMul_A 的提升并不只是一个数据搬运函数的单点加速。它更重要的意义在于,把矩阵乘入口处的数据组织方式提前规整好,让后续 GEMM、卷积和量化计算能够以更连续、更稳定的内存访问模式消费输入。
也就是说,RVV 在这里优化的是整个推理链路的“前置通道”,为后续计算减少了布局转换和访存整理带来的额外开销。
2. INT8量化推理链路:多项核心函数超过 20x
INT8 是端侧 AI 推理中最具工程价值的路径之一。它直接关系到模型运行时的内存占用、访存带宽和计算效率。
INT8 链路的性能收益主要来自两类操作:一类是 FP32 与 INT8 表示之间的批量转换,另一类是在 INT8 特征图上执行池化、激活、量化加法等高频计算。前者影响量化模型进入和离开低精度路径的成本,后者直接影响端侧推理过程中大量中间特征的处理效率。

图 5 INT8 量化推理链路加速结果
实测显示,MNNMaxPoolInt8 提升 30.08x,MNNInt8ScaleToFloat 提升 21.00x,MNNFloat2Int8 提升 20.95x,MNNAvgPoolInt8 提升 10.56x。
此外,CPUQuantizedAdd 单核 RVV 路径最高提升 15.45x,onExecute 集成模拟路径最高提升 9.81x,
这些结果说明,MNN 在 RISC-V 上的 INT8 优化已经不再停留于单个转换函数,而是覆盖了“量化转换、低精度计算、结果回写/反量化”的连续路径。从池化、量化/反量化到 CPUQuantizedAdd 的集成执行,RVV 优化正在把 INT8 推理链路中的多个高频环节串联起来。
对于端侧设备而言,这类优化会同时降低访存压力、提升计算吞吐,并改善量化模型的整体执行效率。
3. 卷积与 Depthwise:进入端侧视觉模型核心路径
卷积和 Depthwise 卷积仍是大量端侧视觉模型、轻量 CNN 和多模态输入模型中的核心计算路径。
本轮优化围绕 depthwise 行计算、INT8 行卷积、bias/scale 后处理等函数展开,使 RVV 能力进入模型计算主路径。
相比单个 unit 级 kernel,line 级卷积函数更接近真实算子执行形态,能够在一行或一段连续输出上摊薄调度成本,也更容易形成连续访存和批量计算。

图 6 卷积与 Depthwise 计算加速结果
实测结果显示,MNNConvRunForLineint8_t 优化提升 12.50x,MNNConvRunForLineDepthwise updated 提升 11.86x,MNNConvRunForLineDepthwise 提升 9.69x。表明本次优化不仅补齐了数据搬运和后处理函数,也已经进入端侧视觉模型中的核心卷积计算路径。
相比单纯补齐后处理或数据搬运函数,卷积与 Depthwise 的加速更直接关系到轻量 CNN、视觉模型和多模态输入模型的实际推理效率。
4. 规约、Top1、Softmax 与量化辅助:补齐高频基础算子
规约、Top1、Softmax 和量化辅助函数通常不是宣传中最显眼的大算子,但它们广泛分布在分类输出、动态量化、Attention 前后处理和统计类计算中。真实推理链路里,这类“小而频繁”的函数如果仍由标量路径执行,会形成许多分散的尾部开销。

图 7 规约、Top1、Softmax 与量化辅助加速结果
实测结果中,MNNAsyQuantInfo_FP32 优化提升 11.79x,MNNAbsMaxFP32 与MNNVectorTop1Float 均提升 10.50x,MNNSoftmax 提升 6.52x。
这类基础函数通常不是最显眼的“大算子”,但它们在真实推理链路中出现频率很高。AbsMax、Top1、Softmax 和非对称量化统计等路径一旦仍然依赖标量实现,就会在模型前后处理、分类输出和动态量化过程中形成零散开销。
本轮优化对这些基础核的补强,意味着 MNN RVV 后端不仅关注主计算路径,也在逐步减少端侧推理中的细碎性能损耗。
5. 图像预处理、采样与颜色转换:覆盖真实端侧输入链路
MNN 不只是模型执行引擎,也承担图像输入预处理、颜色空间转换和格式整理等工作。对于端侧视觉应用而言,输入链路的开销同样会影响整体响应时间。
例如,摄像头输入、NV21 转 RGB/BGR、C3 转 float、HSV 颜色转换等预处理步骤,往往发生在模型执行之前,却直接影响用户感知到的整体响应时间。
这类函数的共同特点是数据量大、格式规则、处理逻辑重复,适合 RVV 做批量装载、通道展开、类型转换和连续写回。
例如,MNNC3ToFloatC3_static 需要把 uint8 图像数据转换为 float 输入;MNNNV21ToRGB/BGR 涉及 YUV 到 RGB/BGR 的格式转换;MNNC3ToHSV 则对应颜色空间变换。它们虽然不是神经网络算子本身,却是端侧视觉模型进入推理前的关键入口。
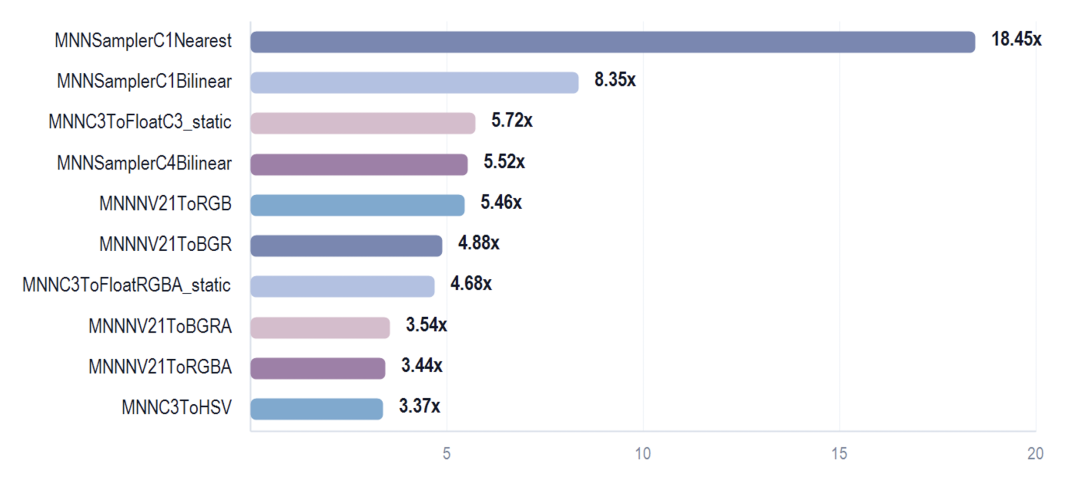
图 8 图像预处理、采样与颜色转换加速结果
在图像处理方向,MNNC3ToFloatC3_static 提升 5.72x,MNNNV21ToRGB 提升 5.46x,MNNNV21ToBGR 提升 4.88x,MNNC3ToHSV 提升 3.37x。
此外,采样类函数也完成了正确性与性能验证,MNNSamplerC1Bilinear 与 MNNSamplerC4Bilinear 分别取得最高 8.35x和 5.52x加速;MNNSamplerC1Nearest 最高提升 18.45x。
这体现了 MNN RVV 优化对真实输入链路的覆盖能力,意味着RVV 优化不仅覆盖颜色转换和格式整理,也开始进入图像进入模型前的 resize / sampler 路径,让 MNN 在 RISC-V 平台上不只是“模型算得更快”,也能让输入准备过程更高效。
6. 低比特数据搬运:为量化和压缩路径铺路
低比特数据搬运面向的是后续模型压缩、低比特量化和稀疏表示等方向。随着端侧模型继续压缩,1bit、2bit、4bit 数据的打包、展开和复制会越来越频繁。如果这些路径仍由标量循环逐位处理,低比特表示节省下来的内存和带宽收益,可能会被搬运和解包开销抵消。
本次优化工作的价值在于,把低比特数据复制中的位级整理、批量搬运和连续写回尽可能向量化。RVV 在这里承担的是“压缩数据路径加速器”的角色,使低比特表示不仅更省空间,也更容易进入高吞吐执行路径。
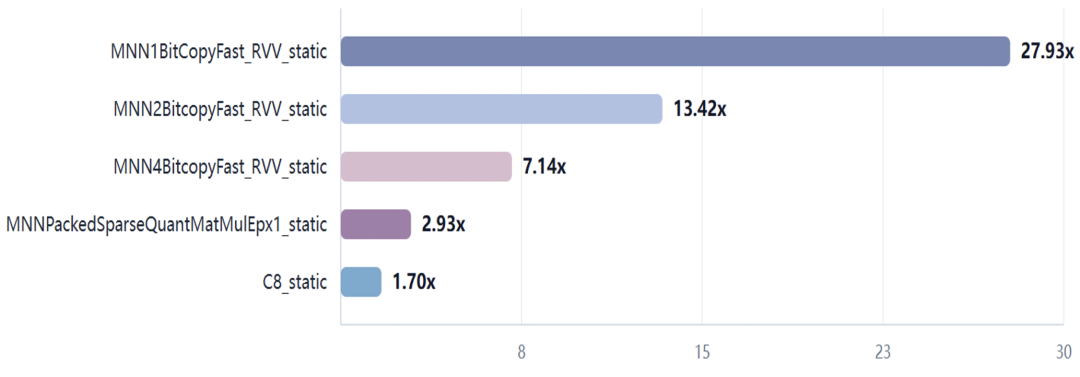
图 9 低比特数据搬运与本地候选优化加速结果
实测中,MNN1BitCopyFast_RVV_static 提升 27.93x,MNN2BitcopyFast_RVV_static 提升 13.42x,MNN4BitcopyFast_RVV_static 提升 7.14x。低比特数据搬运的价值在于为后续模型压缩、低比特量化和稀疏表示打基础。1bit、2bit、4bit 数据虽然可以显著降低存储和带宽压力,但如果打包、展开和复制仍由标量循环逐位处理,节省下来的收益很容易被搬运开销抵消。
7. 端到端 LLM 推理实测:decode 达到 10.49 tok/s
在端到端推理层面,本文选取 Qwen2.5-0.5B 进行实测,用于观察函数级优化进入完整模型执行链路后的整体收益。
三个硬件平台中,SG2044 在 4 线程、prompt_len=128、generate_len=64 场景下取得优化后最高吞吐表现:prefill 从 7.32 tok/s 提升到 17.63 tok/s,decode 从 5.15 tok/s 提升到 10.49 tok/s。按 tokens/tps 推导,prefill 耗时从 17.48s 降至7.26s,decode 耗时从 12.42s 降至 6.10s,p128+n64 总耗时从 29.90s 降至 13.36s,下降约 55.3%。

图 10 Qwen2.5-0.5B 端到端推理实测结果
结果表明,RVV 优化带来的收益已经从单个基础函数扩展到真实 LLM 推理链路:数据布局、量化、矩阵乘前处理与后端调度的改进,最终能够反映到用户更关心的 token 生成速度和整体响应时间上。MNN 在 RISC-V 平台上的优化已经不再停留在“个别函数加速”,而是开始形成覆盖端侧 AI 推理关键路径的系统性后端能力。
MNN 3.5.0 首次官宣 RISC-V RVV 后端支持,是 RISC-V 端侧 AI 软件生态的重要节点。中国科学院软件研究所和南京大学将持续推进这一系列优化,后续工作将继续围绕以下方向推进:
持续推动关键热函数合入上游:包括CPUQuantizedAdd、增强版 depthwise、低比特 copy、C3ToFloat、C8 pack/unpack 等函数,进一步完善代码 review、测试覆盖和工程化集成。
补强 LLM Attention 相关辅助路径:围绕Attention、KV-Split、长上下文混合 Batch 等场景,继续完善 RVV 辅助核实现、边界 case 验证和可复现性能测试,并探索 FlashAttention 相关路径的工程化可能性。
释放 FP16/BF16 原生计算能力:在支持 Zvfh、Zvfbfmin 等扩展的新一代 RISC-V 芯片上,深度优化 FP16/BF16 计算路径。
完善 VLEN 自适应与跨硬件迁移:BPI-F3、K3 与 SG2044 的测试结果显示,VLEN、微架构、缓存、内存带宽和标量基线都会影响最终收益。未来可结合硬件计数器与更多case,完善 RVV kernel 的选择性启用策略。
从官方版本认可,到端侧平台实测,再到 120+ 高性能算子补齐,MNN RISC-V RVV 优化正在把开放指令集能力转化为真实端侧 AI 推理能力。
随着更多优化进入上游、更多硬件平台完成验证,MNN 有望成为 RISC-V 开放算力生态中重要的端侧 AI 推理基础设施。
来源:如意社区











