Lance团队 投稿
量子位 | 公众号 QbitAI
多模态模型,终于不只是“会看”或者“会画”了。
字节跳动Intelligent Creation Lab这次开源的Lance,直接把图像和视频的理解、生成、编辑塞进了同一个原生统一模型里。

它能看图、看视频,能文生图、文生视频,还能按自然语言指令改图、改视频。
更反差的是,Lance不是动辄几十B、上百B参数的大块头,而是一个激活参数只有3B的原生统一多模态模型;
在最大128-GPU训练预算下,就把视频生成、视频理解、图像生成、图像编辑四类任务一起跑通了。
成绩也已经摆上桌:
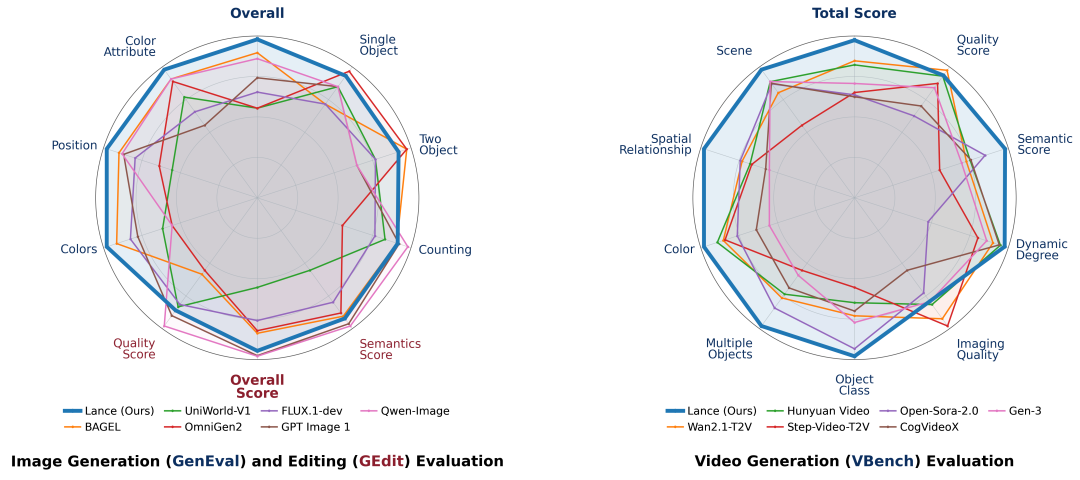
VBench 85.11,MVBench 62.0,GenEval 0.90,GEdit-Bench 7.30。
换句话说,它不是只在某一个单项上“刷存在感”,而是把图像和视频的“看、画、改”放到同一张考卷上一起考。
统一多模态这条路,开始往“小而全”卷了。
统一多模态,卡在哪?
统一多模态这件事,听起来很自然:
人可以一边看图、一边看视频、一边描述、一边修改,模型为什么不行?
但真做起来,问题就来了。
只做理解,生成能力缺位;只做生成,问答和推理又不够;把多个模块拼起来,系统复杂、训练成本高,还很难形成真正的跨任务迁移。
所以说,现在的模型做起来,要么模型太大,训练和部署成本高;要么能力覆盖不全,尤其视频这块,经常只做生成或只做理解。
Lance要解决的,正是这个长期痛点。
它把X2T、X2I、X2V三类任务统一起来:图像/视频到文本理解,文本到图像/视频生成,以及图像/视频到图像/视频编辑。
这样一来,模型不是只会“看”或者只会“画”,而是能在同一套上下文里处理不同模态和不同任务。
更有意思的是,团队观察到:任务覆盖越完整的统一模型,越容易出现emergent generalization,也就是跨任务的涌现泛化。
也就是说,多任务不是简单拼盘。任务之间可能真的会互相“喂经验”。
开源之后,Lance也很快冲上Hugging Face Trending第一。
这类榜单本身不是论文指标,但能说明一件事:社区对轻量级原生统一多模态模型的需求很直接。
毕竟,3B激活参数、同时覆盖图像/视频理解生成编辑,还开放模型权重和代码,这几个关键词放在一起,对研究者和开发者都相当有吸引力。
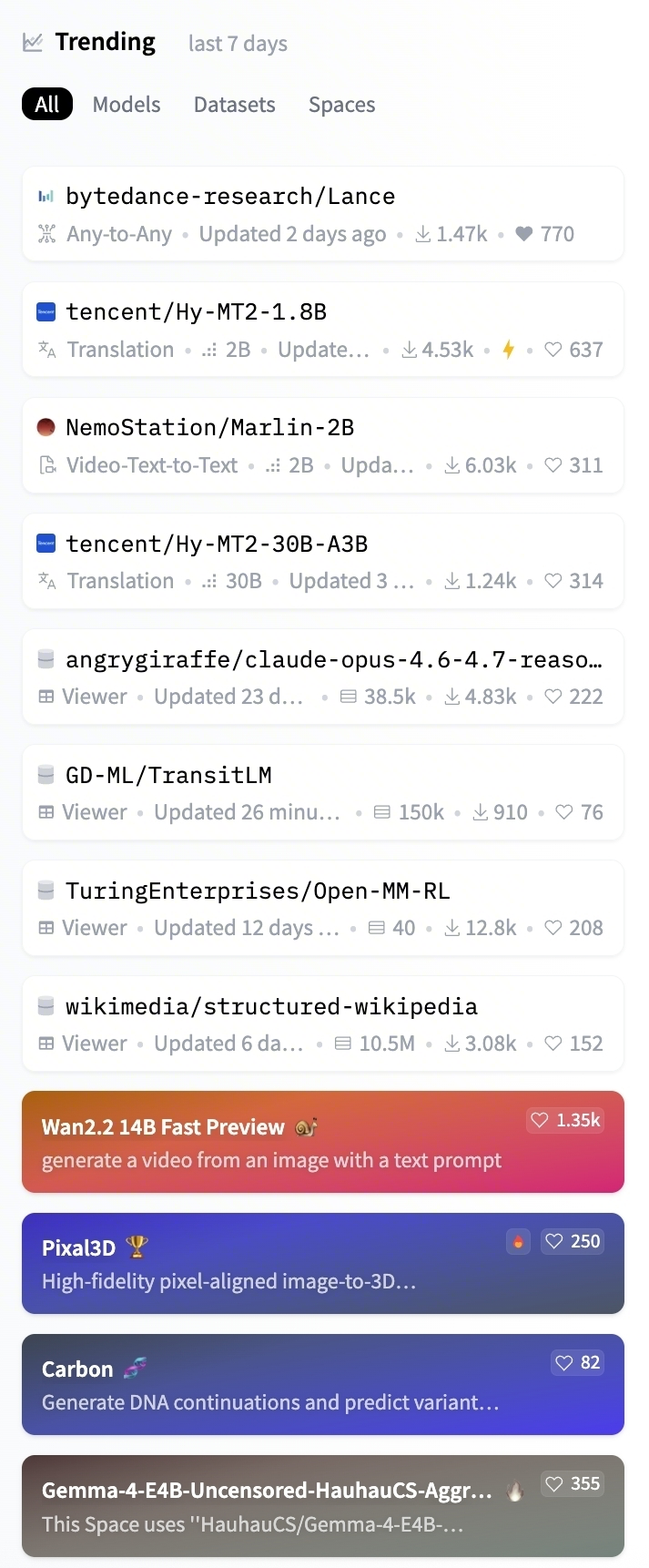
△Lance位列Hugging Face Trending第一
它能干什么
Lance覆盖的不是单点能力,而是一整组图像/视频任务:能看图、能看视频,能文生图、文生视频,也能按自然语言直接改图、改视频。
先上视频生成。
给它复杂文本指令,Lance 能生成具备自然运动、稳定时序一致性和清晰视觉细节的视频内容。


更有看头的是视频编辑。
它不是改一张关键帧糊弄过去,而是连续三轮改视频:
先把短直发改成法式卷发,再加红白花朵发箍,最后把背景换成湖边童话城堡。
难点在于,人物还得是同一个人,动作不能乱,前后帧也不能闪成PPT。

△source video

△replace short straight hair with French curly hair

△add a floral headband with red and white flowers to her hair

△change the background to a fairytale castle by a lake
视频理解也在同一套框架里。
Lance不只是识别画面里有什么,还要理解动作、时序变化、OCR信息和上下文关系,进而完成视频问答与细粒度描述。

△视频理解:视频问答与细粒度时序理解示例
图像侧也一样。
文生图任务里,Lance能处理数量关系、属性绑定、空间布局和风格控制等复杂prompt。

△图像生成:复杂文本指令下的图像生成示例
图像编辑则覆盖主体增删、局部替换、风格迁移、动作调整和自由形式编辑。
核心要求还是一个:听懂自然语言指令,同时尽量保持主体身份、画面结构和视觉一致性。

△图像编辑:多类型图像编辑与主体一致性生成示例
图像理解方面,Lance还能做OCR、知识问答、多图理解和空间关系判断。
这也说明,它不是把生成模型硬塞进一个聊天入口,而是把理解、生成、编辑都放进同一个原生多模态系统里。

△图像理解:OCR、知识问答与多图理解示例
Lance怎么做?
Lance 的核心思路可以拆成两件事:
第一,把文本、图像、视频都放进同一个交错多模态上下文里。
第二,把理解和生成的能力路径拆开,避免它们互相打架。
具体来说,Lance用的是dual-stream mixture-of-experts架构。
理解路径处理文本token和语义视觉token,负责图像/视频理解、问答和推理。
生成路径处理VAE latent token,负责图像/视频生成与编辑。
两条路径共享同一个多模态上下文,但在内部表征和模型容量上保持解耦。
这有点像同一个工作台上,两组人看同一份材料:一组负责理解和判断,另一组负责生成和修改。信息能互通,但具体干活的工具不混用。

还有一个关键设计叫MaPE,全称Modality-Aware Rotary Positional Encoding。
为什么需要它?因为在统一序列里,视觉token的角色并不一样。
有的token是语义ViT token,用来理解;有的是clean VAE token,用来当生成条件;还有noisy VAE token,是生成目标本身。
如果只用普通位置编码,模型容易把这些“长得像、作用不同”的token搞混。
MaPE做的事情,就是在时间维度里加入模态/功能组信息,让模型知道:谁是来帮忙理解的,谁是生成条件,谁才是要被去噪生成的目标。

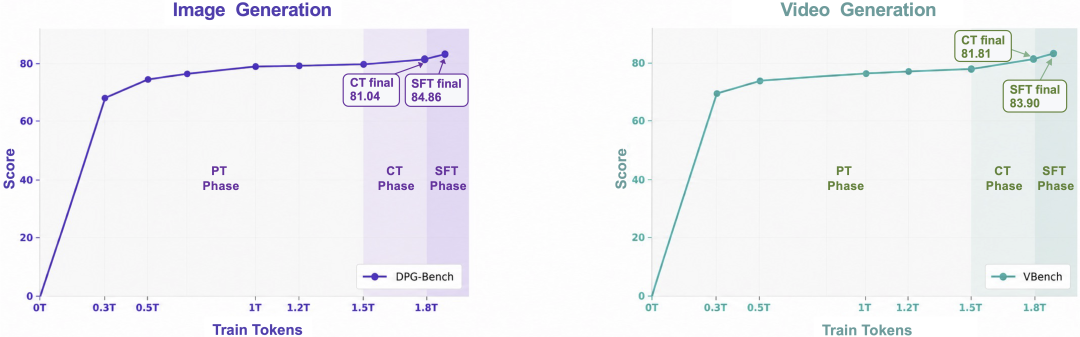
训练上,Lance采用分阶段多任务训练,包括预训练、持续训练、监督微调和强化学习。
其中一个挺关键的发现是:
持续训练阶段即便不额外加入基础生成数据,只加入更多编辑、主体驱动生成等多任务数据,基础生成能力仍然继续涨。
这说明多任务数据不一定会“稀释”生成能力,反而可能帮助模型学到更强的组合、对齐和跨任务迁移。
实验结果怎么样?
先看图像生成。
Lance在GenEval上达到0.90,与统一模型中的最佳总体分数持平,在计数、颜色、空间位置等组合生成维度上表现突出。

再看视频生成。
Lance在VBench上取得85.11,在统一模型中表现领先,同时在视觉质量、对象语义对齐、颜色一致性、空间关系、场景理解、时序风格等维度保持稳定。

编辑方面,Lance 在 GEdit-Bench上取得7.30 Avg/G_O,在统一模型中拿到最佳平均表现。覆盖的编辑类型包括背景改变、材质修改、动作改变、人像美化、主体移除、替换和色调迁移。
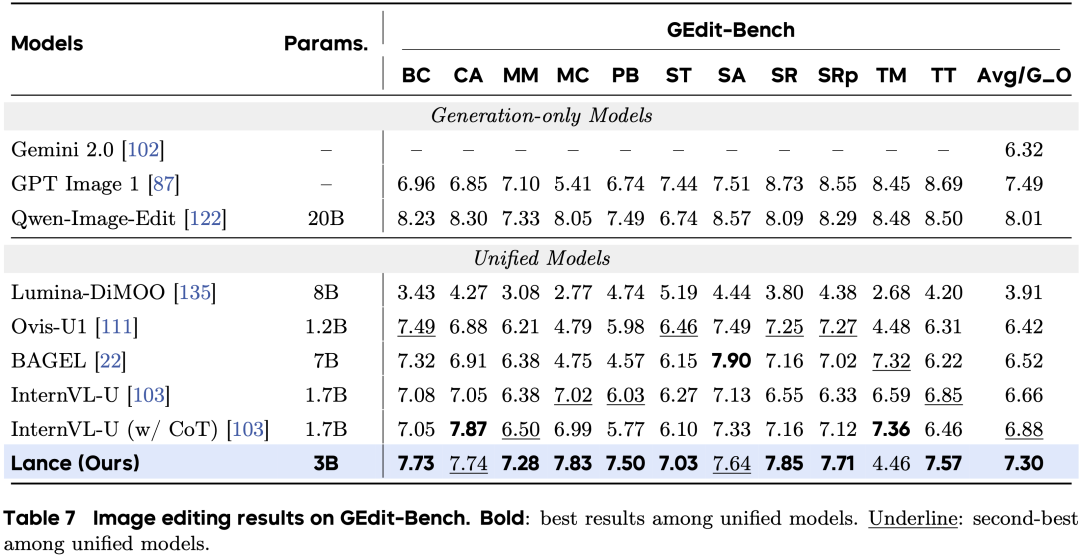
理解方面,Lance在视频理解基准MVBench上达到62.0,在已有统一多模态模型中取得最佳总体分数,相比第二名Show-o2 7B约有11.3%相对提升。
这点比较关键:它说明加入视频生成和编辑能力,并没有把视频理解能力拖垮。

目前,Intelligent Creation Lab(智能创作)团队已经开放Lance的模型权重和代码。
论文地址:https://arxiv.org/abs/2605.18678
Homepage:https://lance-project.github.io
Code (GitHub):https://github.com/bytedance/Lance
Code (HuggingFace):https://huggingface.co/bytedance-research/Lance
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟










