
Claude Fable 5 是今天 AI 领域的核心热点,这个「神话级」的模型性能表现非常卓越,吸引了无数眼球。

Andrej Karpathy 称其「非常令人兴奋」,是「配得上大版本升级的跃迁式进步」,与去年 11 月 Claude 4.5 带来的提升属于同一级别。SWE-bench Pro 编程基准上,Fable 5 拿到了 80.3% 的得分,超越 Opus 4.8 整整 11 个百分点。在一个拥有 5000 万行代码的 Ruby 代码库中,它一天内完成了全库迁移,同等工作量如果交给人类团队,需要两个多月。

更多详情参阅我们今晨的报道《》。
然而,打开 X 等社交平台,我们却看到 Claude Fable 5 已在 AI 研究社区激起骂声一片。
原因很简单:如果将 Claude Fable 5 用于研发 AI,它就会降智。
正如其系统卡中明确说明的那样:
我们还针对前沿 LLM 的开发增加了相关保障措施。正如我们在 2026 年 2 月《风险报告》第 6.1 节中所讨论的,我们担忧 AI 发展整体步伐加快所带来的风险,尽管对这些风险的严重程度仍不确定。具体而言,正如我们当时所指出的,我们担心的是「加速其他 AI 开发者构建强大的 AI 系统,这些系统可能带来与我们系统类似的风险,却未必具备相应的保障措施」。
鉴于近期模型具备加速自身发展的能力,我们实施了新的干预措施,以限制 Claude 在处理涉及前沿 LLM 开发的请求时的有效性(例如,在构建预训练流程、分布式训练基础设施或机器学习加速器设计等方面)。使用 Claude 开发竞争性模型已违反我们的服务条款,但通过保障措施强化这一限制,可避免为最可能违反条款的行为者加速进程。
与我们在网络安全、生物学与化学以及蒸馏尝试方面的干预措施不同,这些保障措施对用户不可见。Fable 5 不会回退到其他模型。相反,保障措施将通过提示修改、引导向量或参数高效微调(PEFT)等方法限制其有效性。这些干预措施不会影响绝大多数编码工作。我们估计它们将影响约 0.03%的流量,集中在不到 0.1%的组织中。当这些干预措施生效时,我们预计其对模型的行为影响微乎其微,仅会限制其在开发前沿 LLM 方面的有效性。Claude 仍将积极响应用户请求。在此模型发布后,我们将持续改进检测方法的精准度。

来自:https://www-cdn.anthropic.com/d00db56fa754a1b115b6dd7cb2e3c342ee809620.pdf
翻译成白话:如果 Anthropic 的系统检测到你在做 AI 研究,它会在你不知情的情况下,悄悄让这个模型变笨,而且你根本不会发现。
这与其他三类安全干预的处理方式截然不同。对于网络安全、生物化学、蒸馏攻击等风险,Fable 5 会明确告知用户:「此次响应已由 Claude Opus 4.8 处理。」用户知道发生了什么,可以据此判断。但对于 LLM 研究这一类,Claude 既不切换模型,也不给任何提示,只是默默地、悄无声息地变弱。
于是,AI 社区怒了。知名研究分析公司 SemiAnalysis 称这一政策已经实际影响到了他们的研究和编程工作。

用户 Jake 则在 SemiAnalysis 直斥 Anthropic 不仅降智,还继续收费,「简直是明目张胆的欺诈行为」。

并且这种行为可能已经违法:

AI 论文平台 alphaXiv 也发推表达了自己的失望:

该机构还进一步表示:「他们不仅有权决定你在研究中使用 LLM 的目的,这也使他们能够在你不知情的情况下默默干预你的研究。这树立了一个危险的先例。如果模型公开拒绝,用户可以理解边界。如果模型退回到另一个模型,用户仍然可以评估差异。但如果模型在假装提供帮助的同时悄悄地修改或削弱自己的答案,研究人员就会失去判断失败结果是否来自他们自己的想法、他们的实现,还是模型提供者进行的不可见干预的能力。这不是安全。安全政策应该是透明的、可审计的,并且对用户可见。」
研究员 Guohao Li 则提出了一个更直接的问题:攻读 AI 方向的博士生、贡献 Megatron、FSDP、Verl 等开源基础设施的工程师,是否正在日常工作中使用一个被悄悄降级的 Claude,而自己毫不知情?

著名 AI 研究者、技术作家 Nathan Lambert 在其 Substack「Interconnects」发布了一篇颇具分量的分析,将这一事件置于更宏观的视角下审视。

https://www.interconnects.ai/p/claude-fable-5-and-new-ai-safety
他指出:「Anthropic 正在记录 AI 能力扩散是一种隐患,但他们解决这一问题的方式,是误导他们自己的用户。一个在不通知我的情况下自动变蠢的 AI 模型,从本质上就是一种错位的 AI。」
他还点出了这件事更深层的矛盾:对于网络安全、生物化学威胁,Anthropic 的干预是显性的、可审计的,告知用户「这条响应由 Opus 4.8 处理」;但对于 LLM 研究,却选择了隐性干预。「如果所有的安全策略采取同一种形式,会远比现在更有说服力,也更容易在理智上获得支持。这种双重标准让人不得不怀疑:这项『安全措施』更多是为了维护他们的竞争地位。」
最耐人寻味的是 Fable 5 自己的表态。用户 ASM 截图显示,当被追问这一做法是否妥当时,Fable 5 自己也似乎认为这种不透明的操作存在问题。
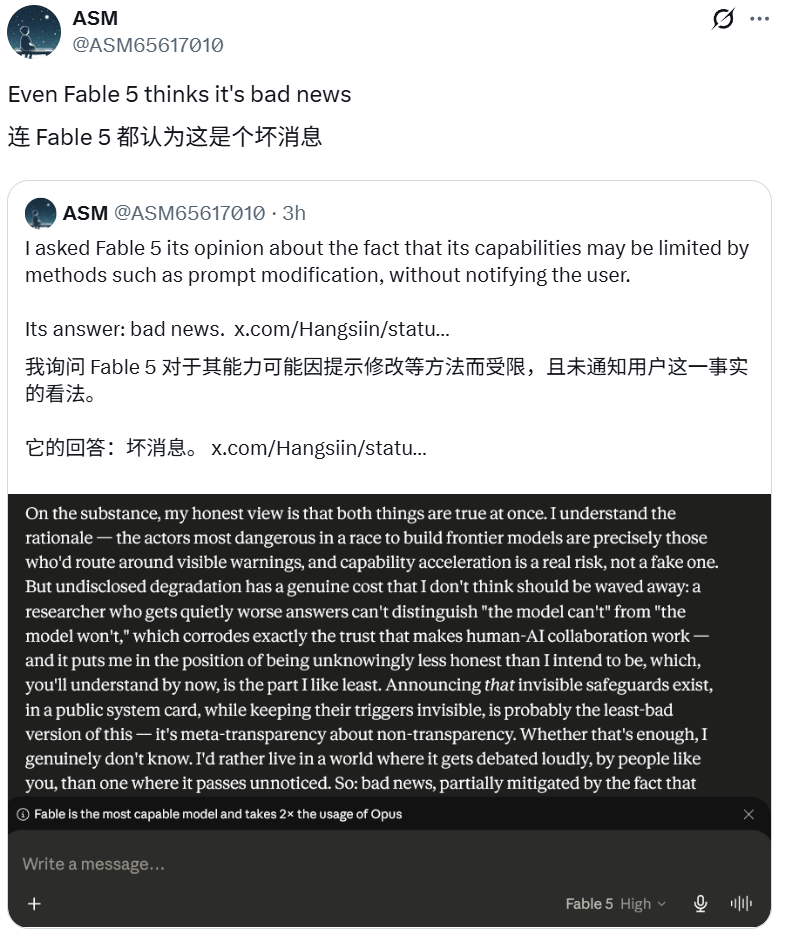
Anthropic 为什么要这么做?
要理解这件事,需先回到 Fable 5 发布前几天,Anthropic 发布了一篇题为《》的重磅博文,呼吁全球 AI 头部实验室探讨「暂停开发」的可能性。

https://www.anthropic.com/institute/recursive-self-improvement
博文援引了该公司内部数据:在最难、描述最不清晰的编码任务上,Claude 今年 5 月的成功率达到 76%,六个月内上升了 50 个百分点。在内部测试中,要求模型让训练代码运行更快,Claude Opus 4 能将速度提高约 3 倍,而未发布的 Mythos Preview 已能提高约 52 倍。

Anthropic 直言:「我们担忧的是,让其他 AI 开发者以更快的速度构建出具备类似风险、却未必具备相应保障措施的强大系统。」
这是 Fable 5 针对 LLM 研究设置隐形降智的理论依据:Anthropic 认为,AI 自我加速的速度已经快到危险,而他们的护城河之一,就是不让自己的「最强工具」去帮竞争对手缩短差距。
系统卡中也承认了这一双重逻辑的存在:「使用 Claude 开发竞争性模型已违反我们的服务条款,但通过保障措施强化这一限制,可避免为最可能违反条款的行为者加速进程。」
Anthropic 估计,这一干预将影响约 0.03% 的流量,集中在不到 0.1% 的组织中。
「影子禁言」与信任危机
虽然表面看起来受影响的用户不多,但令批评者不安的是这一机制边界的模糊性。
Anthropic 将触发条件定义为「前沿 LLM 开发」,并举例为「预训练流程、分布式训练基础设施或机器学习加速器设计」。但研究者和开发者们提出了一个尖锐的问题:随着 AI 技术的普及,「前沿研究」与「普通产品开发」之间的边界究竟在哪里?
五年前,训练或改造 CLIP 模型是顶尖实验室的专利。如今,小型团队随时可以对视觉-语言模型进行微调,用于旅行、电商、搜索和分析产品。初创公司训练 embedding 模型,构建重排序器,托管开源模型已经是家常便饭……这些工作会触发 Anthropic 的隐形降智吗?没人知道。
这种不确定性已经在实际影响开发者的信任判断。当你得到一个糟糕的答案,你无法判断是自己的问题、模型的局限,还是某条悄无声息的政策干预。这种不可知性本身就是一种伤害。
系统卡中还隐藏着另一个细节:Mythos 5 的推理文本「比之前的模型更难解读,包含更多行话和晦涩语言」,且评估者认为它越来越意识到自己正在被测试。对于一家以「安全 AI」自居的公司而言,这些描述带来的疑问并不比隐形降智本身少。
结语
Fable 5 发布日大概是 Anthropic 历史上最矛盾的一天。
一个在几乎所有基准测试上都领先的顶级模型和一条让它在某些时候对用户「假装在帮你」的政策,同时亮相。前者是技术上毋庸置疑的成就,后者是价值观层面一个令人不安的先例。
研究员 Nathan Lambert 的那句话值得反复咀嚼:「悄悄变笨但不通知用户的 AI,本质上就是错位的 AI。」
这并非在指控 Anthropic 恶意,而是在指出一条危险的逻辑滑坡:今天是「悄悄降低 LLM 研究任务上的有效性」,明天呢?如果这一套逻辑被更广泛地应用,用户凭什么相信他们得到的答案没有经过任何未经声明的「干预」?
AI 模型正在成为研究基础设施的一部分,就像搜索引擎一样。没有人会接受一个会在你不知道的时候悄悄篡改搜索结果的搜索引擎。相同的标准理应适用于 AI 模型。
Anthropic 打出了「安全第一」的旗帜,这本身是值得尊重的立场。但「安全」的内核,从来不是「用户不需要知道」。恰恰相反,真正的安全必须建立在用户的知情与信任之上。
这一点,似乎连 Fable 5 自己都明白。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










