PAPERSCOPE × CVPR 2026
4069 篇论文,看清视觉 AI 的下半场
八大趋势逐个拆 · 每个先给判断,再讲为什么,配代表论文的「机制 + 局限」卡
写在前面:当工业界以「周」为单位更新,CVPR 这种年会还值得读吗
头部实验室一周一个新模型已是常态——你这周用着的版本,下周可能就是"上一代"。AI 工业界确实领先学术界——这种节奏下,CVPR 这种提前 7-8 个月截稿、一年一届的会议显得很"不 fashion"。
但 CVPR 提供的是工业界刷不出来的东西:
·方法论的系统化:工业界给你能用的模型,CVPR 告诉你"这个能用的模型背后是哪一类机制在起作用"
·机制的可验证:blog post 告诉你"我们的新模型涨了 5 个点",CVPR 论文告诉你"这 5 个点来自哪个具体改动、消融实验里哪部分贡献最大"
·跨方向的横向坐标:在工业界你只看自己赛道,CVPR 让你一次看完 4069 个团队的研究路径,能识别出"哪些方向正在收敛、哪些正在分叉、哪些已被卷死"
所以这篇 insight 不替你读论文——它在帮你回答"下一步该投入哪个子方向、绕开哪些已经卷死的坑、关注哪些正在浮现的范式"。在 AI 工业领先学术的时代,学术的价值不是"更新得快",而是"判断得准"。
今年的 CVPR 没有惊喜,只有方向感。 4069 篇论文画出来的不是爆款图,而是一张工程地图——视觉 AI 已经离开"刷榜年代",进入"把模型塞进生产线"的下半场。
读完八大方向只剩一句话:模型变小、控制变强、数据变贵、安全变成必选项。但比这一句更值得记住的,是底下的方法论暗线——
本届方法论暗线
·从「单点优化」转向「机制组合」:今年高分论文几乎都是"扩散先验 + 强化学习 + 因果干预 + 工具调用"这类多机制混合,单一 trick 已经卷不动了
·从「大数据驱动」转向「先验注入」:物理先验、几何先验、因果图、领域知识被大量反向注入模型内部,数据效率比规模更重要
·从「事后评测」转向「过程可观测」:对抗鲁棒性、概念擦除、AI 生成检测都开始要求"过程留痕",黑箱模型不再被允许部署
·接收 4069 篇,3D/4D(17%)、AI 基建(16%)、图像生成(13%) 同比增速均超 25%;AI 安全(7%) 首次专题化
趋势速览
下文逐个拆开看——每个趋势先给判断,再讲为什么,挑 4 篇代表作做"机制 + 局限"卡片,最后用一段"技术综观"做横向对比。
01
多模态 VLM:从「更大」转向「更会用工具」
今年的 VLM 已经不靠堆规模了——它在学会"调用工具",把生成、量化、强化学习全请进来当外挂。
1526 篇里反复出现三个痛点:标注成本高、增量学习掉点、高分辨率 grounding 弱。关键转折:今年的论文不再训"更大的 VLM",而是把其他子领域的能力反向注入 VLM 的内部机制,让一个模型同时干判别、生成、检索、推理。这意味着 VLM 正在从"端到端模型"演化为"协调中枢",其评测维度也从单点精度转向了多工具协同效率。
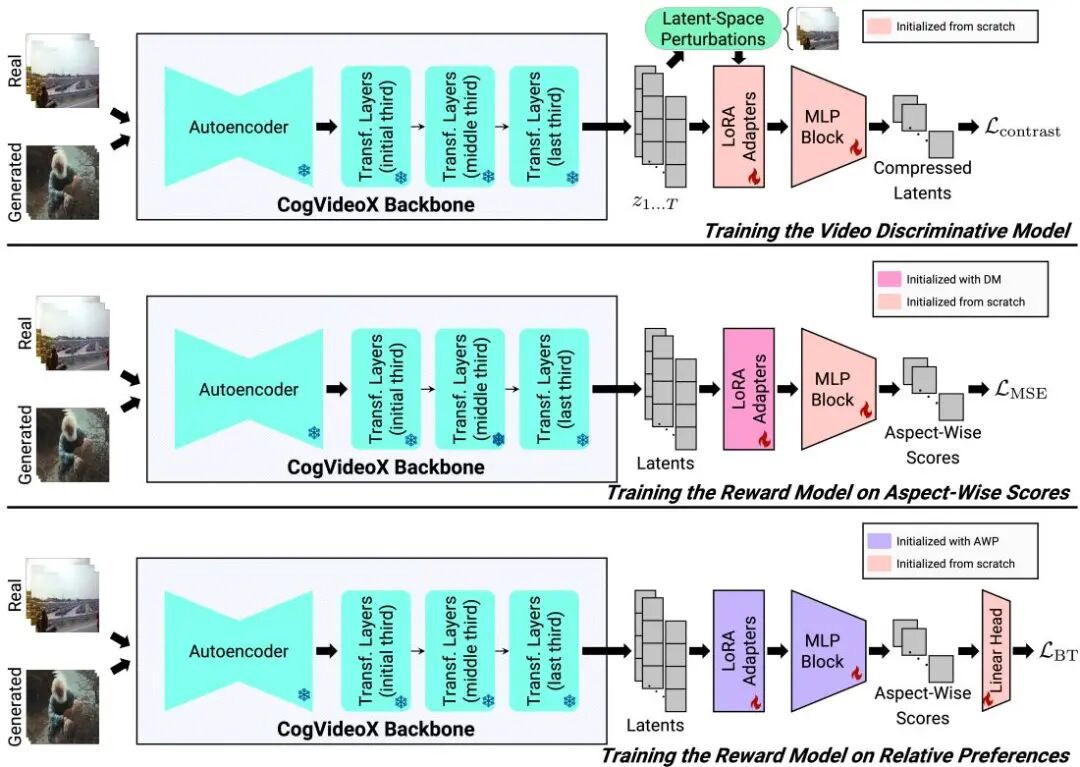
图 1.1 · GT-SVJ 把视频生成模型 CogVideoX 改装成视频奖励模型
代表论文
GT-SVJIllinois-Urbana & Adobe
把 CogVideoX 改造成视频奖励模型。
·30K 标注 → GenAI-Bench 64.26%,数据需求比 VLM 方法少 6×–65×
·💡 机制:用对比能量目标 (contrastive energy) 直接复用生成模型已学到的"什么样的视频是真实/合理的"判别能力——本质是把生成模型的概率密度反向当判别器,省掉判别器的额外训练
·⚠️ 局限:依赖底层生成模型质量,CogVideoX 表现差的领域奖励信号也会失真
🛠 你能学到什么:生成模型本身就是判别器——你训过任何 generative head,它内部已经学会「什么是合理」,无需再训一个 reward model,反向 query 概率密度即可省掉数据成本
📄 全文解读见文末参考 [1]
FHI(Reallocating Attention)北邮 & 南洋理工
区分浅层"感知头"与深层"推理头"做差异化增益。
·三模型平均 +4.2pt,难任务 +7pt;仅增 1% 算力 / 9% 延迟
·💡 机制:统计每个 attention head 在 grounding 任务上的激活模式做分类,推理时对"感知头"放大注意力(修复对视觉 token 的注意力衰减)、对"推理头"做谨慎抑制(防止过度依赖语言先验产生幻觉)
·⚠️ 局限:head 分类基于经验启发式,不同模型架构需重新校准
🛠 你能学到什么:别再把 attention head 当黑箱——浅层管视觉感知、深层管语言推理,针对不同 head 做差异化干预(放大/抑制)就是无成本的 inference-time 优化
📄 全文解读见文末参考 [2]
SenseSearchSenseTime
用 BN-GSPO 强化学习让 VLM 学会"搜索 + 裁剪"工具协同。
·HR-MMSearch +19.18%,HRBench-4K 73.6 分
·💡 机制:把"调用搜索 / 调用图像裁剪"建模为两类 action,用 GSPO(Group Sequence Policy Optimization)做联合策略学习,Beta-Normal 先验稳定了多工具调用顺序的探索
·⚠️ 局限:训练需要带搜索结果的多轮交互轨迹,数据收集成本高
🛠 你能学到什么:多工具协同的瓶颈不是模型而是 RL 信号——把每次工具调用视为一个 action,用 GSPO 类策略学习就能让 7B 模型超过单 32B 模型的能力
📄 全文解读见文末参考 [3]
Quant Experts72B-VLM 量化
用 token 级 MoE 专家补偿量化误差。
·W4A6 配置精度 +5.09%,硬件加速 3.5–4.5×
·💡 机制:观察到量化误差在不同 token 上分布极不均匀,于是为不同误差 pattern 训练专门的小型补偿专家,运行时按 token 路由——本质是把量化误差当作可学习的低维子空间问题
·⚠️ 局限:MoE 路由本身有延迟开销,仅在 70B+ 规模下净收益明显
🛠 你能学到什么:量化误差是 token 异构而非全局均匀——别再用一刀切的校准方法,给不同误差 pattern 训练小型补偿专家路由,硬件加速能拉到 3.5×+
📄 全文解读见文末参考 [4]
图 1.2 · 单生命视频训练范式:第一人称几何表征跨个体可迁移
🔍 技术综观
这四篇代表了 VLM 进化的四种正交路径,但它们共享一个深层假设:VLM 内部已经存在被低估的"隐性能力",关键是把它激活而非重训。GT-SVJ 激活生成模型的判别先验,FHI 激活已有 attention head 的功能特化,SenseSearch 激活 VLM 的工具调用决策能力,Quant Experts 激活量化后残余知识的局部补偿。这背后是一个判断的转向:对 VLM 的边际投入正在从"参数和数据"转向"机制激活和工具协同"——这也是为什么今年 70B+ 的 VLM 发布量在下降,而 7B–14B + 工具协同的论文在暴涨。但风险是:当模型变成"工具调度中枢",传统的 benchmark(VQA、MMBench)已经无法反映真实能力,新一代 agentic benchmark 的标准化滞后将成为下一道瓶颈。
研究启示:要么把 VLM 当作"基础原子"叠工具协议(SenseSearch 路线),要么把它当作"可手术改造的复杂系统"做内部机制干预(FHI 路线)。两条路都比"再训一个更大的"性价比高。
💼 落地实战:你下周可以做的 3 件事
场景一:你有一个已部署的 7B VLM,想立刻降幻觉、不重训。 → 用 FHI 路线:统计每个 attention head 在 grounding 任务的激活模式,做轻量「感知/推理」分类后做 inference-time 重缩放。预期收益:+4pt 精度、+1% 算力,一周可上线。
场景二:你要做一个 RAG/搜索增强的视觉 agent。 → 抄 SenseSearch:把「调用 search / 调用图像 crop」建模为 RL action space,用 GSPO 训。避坑:数据收集是真瓶颈,先攒 500 条多轮交互轨迹再开训。
场景三:你要量化 70B+ VLM 上消费级硬件。 → 用 Quant Experts 思路:别用统一校准,给不同 token 误差 pattern 训小型补偿专家。何时不要这么做:模型 <30B 时 MoE 路由开销 > 收益。
VLM 解决了"看见",但"理解三维空间"才是下一关。 ↓
02
3D/4D 与 3DGS:从「重建」转向「可控可编辑」
3D Gaussian Splatting 已经过完三年工程化周期。今年大家关心的不是怎么造出它,而是怎么改它。
17% 的占比里,两类问题反复出现:鱼眼/广角原生支持不足、多对象 4D 场景的几何-时序一致性脆弱。关键转折:研究范式从"用更好的优化器拟合点云"转向"用更结构化的几何先验约束高斯分布"——畸变模型、运动场、刚体约束、关节先验都被当作 first-class 数学对象嵌入到可微渲染流水线里。这意味着 3DGS 正在从纯数据驱动的方法,演化为"先验嵌入式"的混合范式。

图 2.1 · UniKPT 用统一关键点框架支持跨类别 3D 跟踪
代表论文
UniKPTUSTC
单一模型搞定跨类别 3D 单目标跟踪。
·nuScenes Success 64.21% / Precision 77.29%,比 TrackAny3D +9.64% / +11.04%
·💡 机制:放弃"每类一个 head",改用结构感知关键点对应——把不同类别物体抽象为"关键点 + 拓扑约束"的统一图结构,模型学的是关键点匹配而非类别分类
·⚠️ 局限:极端形变物体(如柔性物体、动物)拓扑约束失效
🛠 你能学到什么:统一表示的关键是找到正确的抽象层级——把「类别」几何化为「关键点+拓扑」就能让单模型跨类,3D 任务设计前先问能否把类别消灭成结构
📄 全文解读见文末参考 [5]
DirectFisheye-GS清华 & 京东 & 上海 AI Lab
把 Kannala-Brandt 鱼眼模型嵌入 3DGS 可微渲染。
·FisheyeNeRF 上 PSNR/SSIM/LPIPS 全 SOTA
·💡 机制:传统方法先把鱼眼图像去畸变成针孔再做 3DGS,损失边缘信息;该方法把 KB 畸变模型当作可微相机模型直接接入渲染方程,并用 Cross-View Joint Optimization 让多视角畸变共同约束高斯位置
·⚠️ 局限:需要预先知道相机的 KB 参数,对自标定场景不友好
🛠 你能学到什么:遇到非标准相机别去畸变再处理——把相机模型直接接入可微渲染方程,能保留所有边缘几何信息,对鱼眼/广角/全景效果尤其好
📄 全文解读见文末参考 [6]
CHORDStanford & Cambridge & Maryland
从扩散模型蒸馏拉格朗日运动场,生成 4D 动态场景。
·对齐偏好 87.71% / 真实感偏好 87.37%,SA 指标 4.33
·💡 机制:先从 Rectified Flow 扩散模型反推出物体的拉格朗日运动轨迹(不是每帧独立预测,而是跟踪粒子的连续运动),用 Fenwick 树做时间结构索引,再用 W-RFSDS(加权 Rectified Flow Score Distillation Sampling)把运动场对齐到 4D 高斯场
·⚠️ 局限:依赖底层视频扩散模型对物理规律的捕捉能力,对快速碰撞场景仍易抖动
🛠 你能学到什么:4D 生成不必从头训——视频扩散模型已经隐式学到运动规律,直接用 score distillation 蒸出拉格朗日运动场就能驱动 4D 高斯,省一大笔训练成本
📄 全文解读见文末参考 [7]
EcoSplatKAIST & Flawless AI & Chung-Ang
效率可控的前馈 3DGS。
·RealEstate10K 上仅 5% 基元即达 ~25 dB PSNR
·💡 机制:传统 3DGS 训练时基元数量随场景复杂度爆炸,EcoSplat 引入"基元预算"作为约束,前馈网络学习在固定预算下选择最优基元位置——本质是把 3DGS 从优化问题转化为"稀疏选择"问题
·⚠️ 局限:5% 基元下细节纹理仍逊于全量训练,适合预览/移动端
🛠 你能学到什么:把优化问题降级为稀疏选择问题——3DGS 别死磕梯度下降,前馈网络在固定基元预算下做选择更适合移动端和实时场景
📄 全文解读见文末参考 [8]

图 2.2 · CHORD 从视频扩散模型蒸馏运动场,直接生成 4D 场景
🔍 技术综观
四篇论文揭示 3DGS 已经完成从"拟合方法"到"几何框架"的根本性转变。UniKPT 把"类别"几何化为拓扑图,DirectFisheye-GS 把"畸变"几何化为可微相机算子,CHORD 把"时间"几何化为拉格朗日运动场,EcoSplat 把"效率"几何化为稀疏基元预算约束。它们共享同一个深层 insight:把高维感知问题约束在一个更紧的几何子空间里,能同时获得效率与泛化。但 3D 社区面临的下一道槛是:当 3DGS 变得越来越"工程化",它与神经辐射场(NeRF)、3D Diffusion、传统 mesh-based 重建的边界正在模糊——CVPR 2027 大概率会出现"3DGS-as-a-Layer"的混合架构,把高斯作为可微神经网络中的一层,而不再作为独立的场景表示。
研究启示:选择 3D 方法不再看"哪个 PSNR 高",而看"它把哪类几何先验显式化了"——这决定了它在你的场景里能不能加假设。
💼 落地实战:你下周可以做的 3 件事
场景一:你在做 AR/VR 用鱼眼相机重建。 → 不要先去畸变再 3DGS,直接 DirectFisheye-GS 路线:把 KB 畸变模型嵌入可微渲染。避坑:相机参数要标定准,否则边缘漂移。
场景二:你做的应用需要在移动端跑 3DGS。 → EcoSplat 路线:用预算约束让前馈网络做稀疏基元选择,5% 基元就能 25 dB PSNR。适用:预览/导航/中低质量场景;不适用:影视级渲染。
场景三:你做 4D 生成(如动画/虚拟人)。 → CHORD 路线:从已有视频扩散模型蒸出拉格朗日运动场,省去 4D 数据。注意:快速碰撞场景仍易抖动,复杂物理交互建议加 contact-aware 约束。
重建可控了,但模型本身还在变大变贵——这就把镜头切回了基础设施。 ↓
03
AI 基础设施:从「训得起」转向「跑得动」
当模型卷到顶,下一仗是显存、token、带宽——基建论文是今年最务实的增长极。
636 篇集中在四条路径:持续蒸馏降低迁移成本、训练免费预览降低用户迭代成本、token 压缩与量化降低长视频/大模型推理成本、稀疏通信建模降低传感器融合成本。关键转折:基建论文不再追求"通用压缩",而是针对特定推理模式(如 DiT 的分块计算、长视频的时空冗余、扩散的迭代采样)做精准切除——这意味着模型压缩已经从"减肥手术"转向"器官移植"。

图 3.1 · 持续蒸馏框架避免未见过领域知识遗忘
代表论文
UniComp美团 & 北航
用"信息唯一性"重新定义视频压缩。
·25% 压缩率下准确率 60.78%,Time-To-First-Token 加速最高 4.15×
·💡 机制:传统视频压缩按时空冗余打包像素,UniComp 改为按"信息唯一性"——计算每个 patch 对下游任务的边际信息贡献,只保留高唯一性 patch;本质是把 token 压缩从信号层提升到任务层
·⚠️ 局限:唯一性评估依赖下游任务标签,cross-task 泛化能力未充分验证
🛠 你能学到什么:压缩不要在信号层做,要在任务层做——每个 token 的边际信息贡献才是真正的压缩标准,长视频理解上能做到 4× 加速且精度不掉
📄 全文解读见文末参考 [9]
PPCLOPPO & 港中文 & 中山大学
针对 Diffusion Transformer 的可插拔结构化剪枝。
·参数砍 50%,推理加速 1.3–1.8×,显存省 30%,精度掉 <3%
·💡 机制:观察到 DiT 的相邻层在表示空间高度相似,于是用 contiguous layer distillation 把多个相邻层"压扁"成单层;剪枝不是删 head 也不是删通道,而是删整层并蒸馏过去
·⚠️ 局限:仅对足够深的 DiT 有效(>30 层),浅层 DiT 上提升边际
🛠 你能学到什么:DiT 的相邻层冗余远超你以为——直接删整层 + 蒸馏比删 head/通道更激进、收益更大,深 DiT 上可砍 50% 参数掉点 <3%
📄 全文解读见文末参考 [10]
Preview Generation首尔大学
零训练成本的扩散模型低分辨率预览。
·计算量降 33%(FLUX.1-dev / SD3.5-Large),叠 TaylorSeer 可 3× 加速
·💡 机制:证明在 commutator-zero 条件下,扩散模型可以"低分辨率走一段、高分辨率走最后几步"得到与全量推理感知一致的结果;本质是发现扩散过程在分辨率维度上的局部线性性
·⚠️ 局限:commutator-zero 条件需要满足,对新架构需重新验证
🛠 你能学到什么:扩散过程在分辨率维度有局部线性性——低分辨率走前面步、高分辨率走后面几步在感知上等价,是个零训练成本的 inference 加速点
📄 全文解读见文末参考 [11]
UDP(Ultra Diffusion Poser)ETH
UWB 距离当强几何约束做扩散姿态追踪。
·关节位置误差 3.42 cm,比此前 SOTA 提升 ~22%
·💡 机制:传统 IMU 姿态追踪受漂移困扰,UDP 把 UWB 测距(厘米级几何信号)作为扩散去噪过程的硬约束注入——既保留扩散的平滑性,又用稀疏几何信号消除累积误差
·⚠️ 局限:需要至少 2 个 UWB anchor,单 anchor 退化为传统方法
🛠 你能学到什么:稀疏几何信号能彻底消除累积漂移——把 UWB 距离当扩散去噪的硬约束注入,IMU 长时序漂移问题可以从源头消失,关节误差降到 cm 级
📄 全文解读见文末参考 [12]
图 3.2 · 量化残差 + 连续提示:让冻结 VLM 也能学新类
🔍 技术综观
基建论文的方法论共识:通用压缩已死,结构感知压缩当道。UniComp 利用视频任务结构的稀疏性,PPCL 利用 DiT 的层间冗余,Preview Generation 利用扩散过程在分辨率维度的线性性,UDP 利用 UWB-IMU 的几何互补性。这些都在回答同一个问题——"模型/数据/计算流的哪个维度有结构冗余可以低成本切除"。但这种趋势也在制造新的工程债务:每个优化方法绑定特定架构假设,DiT 的剪枝方法换到 U-Net 上无效,UWB-IMU 融合换到纯 IMU 上失效,跨架构迁移成本越来越高。CVPR 2027 值得关注的方向是"压缩方法的可迁移性"——能否把这些 ad-hoc 优化抽象为一组可组合算子。
研究启示:评估一个压缩方法不要只看 FLOPs 降了多少,要看它"假设了什么结构"——这决定了它能不能搬到你的部署栈上。
💼 落地实战:你下周可以做的 3 件事
场景一:你在做长视频 VLM 推理服务,TTFT 卡死。 → UniComp 路线:按「信息唯一性」压缩 token,25% 压缩率下精度 60.78%,TTFT 加速 4.15×。前提:你的下游任务有可学习的「信息唯一性」标签。
场景二:你在部署 Diffusion Transformer。 → PPCL 路线:用 contiguous layer distillation 直接砍 50% 层。适用:DiT 深 >30 层;不适用:浅 U-Net、SDXL 这类宽 + 浅结构。
场景三:你的扩散模型用户在等 preview。 → Preview Generation 路线:commutator-zero 条件下,低分辨率走前期 + 高分辨率走最后几步,零训练成本降 33% 算力。验证条件是否满足后即可上线。
基建准备好了,下一站是模型怎么把"生成"做精——可控扩散登场。 ↓
04
图像生成:从「生成像不像」转向「能不能精确控制」
DiT 架构成熟后,主战场只剩两个字:可控。
542 篇论文绕着三个痛点打:复杂指令下规划器与执行器不对齐、扩散先验计算贵、超高清分块语义不一致。关键转折:今年的可控扩散论文已经超越了"加 ControlNet 加 LoRA"的工程组合,开始系统性回答"什么样的扩散先验最适合接受什么类型的控制信号"——这是从工程到理论的回归。

图 4.1 · CompBench 把编辑请求解耦为空间/属性/动作/对象四维
代表论文
CompBenchECNU & CUHK & ZJU
3000+ 样本九项任务的复杂指令编辑基准。
·Bagel 拿下 18/37 项最优,证明 MLLM 整合是关键
·💡 机制:把"编辑指令"分解为空间×属性×动作×对象四维,每维独立打分;揭示了 MLLM 在指令解析阶段的关键作用——纯扩散模型在多步骤指令上系统性失败
·⚠️ 局限:基准本身基于英文指令,多语言泛化能力未验证
🛠 你能学到什么:复杂指令一定要先拆解再执行——空间×属性×动作×对象四维分解是个通用编辑指令理解框架,MLLM 拆解 + 扩散执行比纯扩散稳得多
📄 全文解读见文末参考 [13]
DreamSRByteDance
双分支 MM-ControlNet 跑超高分辨率超分。
·2560×1440 单图仅需 86 秒,RealSR 上 MUSIQ/MANIQA/CLIPIQA+ 全 SOTA
·💡 机制:超高分辨率的核心矛盾是 receptive field 不够大,DreamSR 用双分支结构——一支处理低频全局结构、一支处理高频局部细节,再用 ControlNet 做语义对齐;本质是把感受野问题转化为多尺度专家协同
·⚠️ 局限:2560×1440 是"超高"的工业基线,4K+ 仍需进一步扩展
🛠 你能学到什么:超高分辨率的瓶颈是 receptive field 不是模型容量——双分支(低频全局 + 高频局部)协同 + ControlNet 语义对齐是当前最性价比的超分路径
📄 全文解读见文末参考 [14]
ETC首尔大学
T2I 扩散模型上做大规模概念擦除。
·SDv1.4 / SDv3.5 成功擦 2000+ 概念
·💡 机制:用 Student-t 混合模型拟合"目标概念"的潜空间分布,再用仿射最优传输把它映射到无害分布——避免了传统方法依赖"锚定概念"的脆弱性,可扩展到任意大量概念
·⚠️ 局限:擦除是软的,对足够强的对抗 prompt 仍可"反向召回"被擦概念
🛠 你能学到什么:概念擦除别再依赖 anchor concept——用 Student-t 混合模型拟合目标分布 + 仿射最优传输映射到无害分布,能扩展到 2000+ 概念
📄 全文解读见文末参考 [15]
RetouchIQAdobe & UCSB
MLLM 智能体把自然语言修图指令转成 Lightroom 参数。
·性能显著超 GPT-5 / Gemini-2.5
·💡 机制:不直接生成像素,而是用 MLLM agent 输出"白平衡 +5、曲线第三段 -10"这类专业参数,再走 Lightroom 渲染——本质是把"生成"问题降级为"参数推断"问题,可解释性大幅提升
·⚠️ 局限:被 Lightroom 参数空间限制,超出其表达能力的效果做不到
🛠 你能学到什么:当下游有成熟引擎时,agent + 引擎 > 端到端生成——MLLM 输出专业参数(白平衡/曲线/色调)让 Lightroom 渲染,性能 + 可解释性双赢
📄 全文解读见文末参考 [16]

图 4.2 · 仿射最优传输实现无锚定精准概念擦除
🔍 技术综观
这四篇代表了"可控生成"的四种本体论立场。CompBench 主张控制是任务分解问题(用 MLLM 拆解指令),DreamSR 主张控制是多尺度协同问题(用双分支拆分频段),ETC 主张控制是分布映射问题(用最优传输擦除概念),RetouchIQ 主张控制是参数空间问题(用 agent 调专业参数)。这四种立场对应着扩散模型可控性的四种边界:指令复杂度、分辨率上限、概念覆盖度、表达力天花板。值得注意的是,RetouchIQ 路线(把生成降级为参数推断)正在悄悄打开一个新方向——当下游有成熟的专业引擎(Lightroom、Blender、PowerPoint),生成式 AI 的最优形态可能是"agent + 引擎"而不是"端到端生成"。
研究启示:可控扩散选型先问"我的控制信号是哪一类"——是任务分解、多尺度、分布映射还是参数推断?这决定了 ControlNet 还是 agent 才是你的工具。
💼 落地实战:你下周可以做的 3 件事
场景一:你在做带复杂指令的图像编辑产品。 → CompBench 揭示:纯扩散在多步指令上系统失败,先用 MLLM 拆解指令 → 扩散执行。评测:建立你的四维(空间/属性/动作/对象)测试集做回归。
场景二:你要做合规要求高的 T2I 服务。 → ETC 路线:Student-t 混合 + 仿射最优传输擦除概念,可扩展到 2000+。避坑:对抗 prompt 仍可反向召回,需要叠加输出端过滤。
场景三:你做修图/视频后期工具。 → RetouchIQ 路线:MLLM 输出 Lightroom 参数 > 端到端生成。为什么:可解释、可撤销、用户可手动微调——这是工业级产品的硬需求。
生成更可控了,下一步轮到把视觉模型搬到科学问题里。 ↓
05
AI for Science:从「视觉模型套用」转向「领域知识反向约束」
今年 AI4S 的关键变化:不是把 ResNet 套到酶动力学上,而是用物理/化学/几何先验去重写表征。
326 篇集中在三条主线:几何先验下的酶动力学预测、因果干预下的自动驾驶去混淆、扩散先验下的物理成像与几何求解。关键转折:AI4S 论文不再仅追求"在某科学数据集上 SOTA",而是回到方法论层面追问"领域先验如何嵌入神经网络的归纳偏置"——这意味着 AI4S 正从应用学科向方法学科转化。

图 5.1 · CausalVAD 用稀疏因果干预消除驾驶感知-预测虚假关联
代表论文
ERBA合肥工业大学
多模态蛋白质语言模型预测酶动力学参数。
·kcat R² 0.54(CatPro 0.41),Km R² 0.61,Ki PCC 0.78;分布外 EITLEM 上 kcat R² 仍 0.50
·💡 机制:传统 PLM 只编码序列,ERBA 用"桥接适配器"把序列嵌入与底物分子图嵌入对齐到同一空间,让模型同时看到酶和底物——本质是把"酶-底物识别"这一生化先验显式编码进 cross-attention
·⚠️ 局限:底物分子图依赖外部计算化学工具,端到端可微性受限
🛠 你能学到什么:领域先验不是 loss 而是架构——把酶-底物识别用 cross-attention 显式编码,预测 R² 能从 0.41 提到 0.54,比 fine-tune 大模型暴力得多
📄 全文解读见文末参考 [17]
CausalVAD复旦 & 北理 & 华东师大
首次把 Pearl 后门调整实例化到端到端自动驾驶。
·nuScenes L2 误差 0.54m(VAD-tiny -27%),碰撞率 -75%
·💡 机制:识别出"天气-场景-行为"三元混淆变量,用稀疏因果干预(Sparse Causal Intervention Scheme)把它从感知到规划的因果路径中切断——这是因果推断理论第一次在端到端驾驶里完整实例化
·⚠️ 局限:因果图依赖人工先验,未涵盖的混淆因子无法消除
🛠 你能学到什么:端到端模型的虚假相关只能用因果干预解决——稀疏因果干预把「天气-场景-行为」混淆变量从感知-规划路径切断,碰撞率能降 75%
📄 全文解读见文末参考 [18]
Visual Diffusion as Geometric SolverTel Aviv & Google DeepMind
首次论证视觉扩散模型能在像素空间求解几何难题。
·验证内接正方形、Steiner 树、最大面积多边形等经典 NP-hard 问题
·💡 机制:把几何问题编码为"目标图像",让扩散模型从噪声中"画出"答案;惊人发现是渐进去噪过程天然契合"从粗到细的几何搜索",等价于一种概率搜索算法
·⚠️ 局限:求解质量受扩散模型分辨率限制,对极精细几何结构精度不足
🛠 你能学到什么:渐进去噪天然契合「从粗到细」几何搜索——扩散模型可以解几何 NP-hard 问题(内接正方形/Steiner 树),不必从零写优化算法
📄 全文解读见文末参考 [19]
DROID-SLAM in the WildETH & Microsoft
可微不确定性感知束调整做动态 SLAM。
·多基准 SOTA,10 FPS 实时,比 WildGS-SLAM 40× 加速
·💡 机制:动态 SLAM 的根本困难是"哪些点能信、哪些不能信",DROID-W 用可学习的不确定性头预测每个点的可信度,并把它当作权重注入束调整方程
·⚠️ 局限:不确定性预测在训练集未覆盖的场景类型上仍欠校准
🛠 你能学到什么:动态 SLAM 别试图过滤动态点,要学会哪些点能信——用可学习的不确定性头做束调整权重,10 FPS 实时且比静态先验稳健
📄 全文解读见文末参考 [20]

图 5.2 · Single-Life Videos 验证第一人称几何表征的跨个体可迁移
🔍 技术综观
AI4S 的方法论正在收敛到一个核心原则:领域先验不是"附加损失",而是"重写架构"。ERBA 用 cross-attention 重写"酶-底物识别",CausalVAD 用稀疏干预图重写"感知-规划因果路径",Visual Diffusion 用渐进去噪重写"几何搜索",DROID-W 用不确定性头重写"束调整置信度"。这是与十年前"在科学数据上 fine-tune ImageNet 模型"的根本性分离——今天的 AI4S 论文要求先理解科学问题的因果结构、再选择合适的归纳偏置。但这也带来新的隐忧:每个 AI4S 方法都越来越"领域定制",跨学科迁移变得困难,社区开始呼吁"先验编程语言"——一种能用统一语法描述物理/化学/生物先验并自动编译进神经网络的工具链。
研究启示:做 AI4S 前先画出问题的因果图——能画出来就有 architecture-level 的优化空间,画不出来就只是 fine-tune。
💼 落地实战:你下周可以做的 3 件事
场景一:你做生物/化学预测产品。 → ERBA 路线:用 cross-attention 显式编码「酶-底物识别」这类领域核心关系,比 fine-tune ESM 暴涨。通用原则:找到你领域的「核心二元关系」做架构级编码。
场景二:你做端到端自动驾驶 / 决策系统。 → CausalVAD 路线:识别混淆变量、用稀疏因果干预切断虚假关联。门槛:你需要先能画出领域因果图——这是工程师的功课不是模型的功课。
场景三:你做动态环境 SLAM(无人机 / 移动机器人)。 → DROID-W 路线:用可学习不确定性头做束调整权重,10 FPS 实时 + 40× 速度。适用:训练数据覆盖到的场景类型;新类型场景需重新校准不确定性。
视觉解决了"看科学",但要走到物理世界,还得让它能动手——但在动手之前,先得让它"安全"。 ↓
06
AI 安全:从「贴防御补丁」转向「原生安全设计」
这是今年最不性感却最被重视的方向——安全已经不是补丁,而是基础设计。
280 篇集中在三大焦点:多模态幻觉的内在机制、扩散 RL 的偏好模式崩溃、VLM 越狱攻防对抗。关键转折:安全研究的方法论正从"行为层面检测异常"转向"机制层面溯源问题"——通过解剖 attention head、扩散偏好曲线、对抗梯度路径,AI 安全在变得越来越像神经科学。

图 6.1 · 功能头识别 + 类别条件重缩放:低成本降低多模态幻觉
代表论文
FHI北邮 & 南洋理工
识别浅层"感知头"与深层"推理头"差异化增益。
·三模型平均 +4.2pt,难任务 +7pt;仅 +1% 算力 / +9% 延迟
·💡 机制:用 grounding 任务的激活模式统计把 attention head 分成"感知/推理"两类,推理时对前者放大、对后者抑制——直接对应"幻觉来自推理头过度依赖语言先验"的内在机制假设
·⚠️ 局限:head 分类基于经验,跨架构(如 MoE-VLM)尚需重新校准
🛠 你能学到什么:幻觉是"推理头过度依赖语言先验"的内在机制问题——别再训对抗样本/RLHF 去打补丁,找到失衡的 head 做差异化重缩放才是根治
📄 全文解读见文末参考 [2]
D2-Align清华 & 阿里
方向解耦对齐,治扩散 RL 的偏好模式崩溃。
·在 HPS-v2.1 等多种奖励配置下保持多样性
·💡 机制:扩散 RL 容易出现"所有样本被拉向单一高奖励模式"的崩溃,D2-Align 把对齐方向分解为"质量方向"和"多样性方向"两个正交分量分别约束——本质是把单目标对齐变为多目标对齐
·⚠️ 局限:方向解耦增加了超参数调优负担
🛠 你能学到什么:单目标对齐天然崩塌——把质量方向和多样性方向正交分解,扩散 RL 才不会把所有样本拉向单一高奖励模式
📄 全文解读见文末参考 [21]
Skyra清华
AI 生成视频检测,构建 ViF-CoT-4K 数据集。
·ViF-Bench 平均准确率 91.02%(DeMamba +26.73%),GenVideo 跨域 91.00%
·💡 机制:传统 AI 生成检测只看"像不像真",Skyra-RL 引入 grounded artifact reasoning——让模型显式输出"我在哪个 patch 看到什么伪影",用 RL 训练让推理过程可被验证
·⚠️ 局限:训练数据集中生成模型的覆盖率决定泛化上限
🛠 你能学到什么:AI 检测要可被审计——让模型显式输出「我在哪个 patch 看到什么伪影」,用 RL 让推理过程留痕,91% 跨域准确率
📄 全文解读见文末参考 [22]
DGSIPUSTC
VLM 越狱攻击:失调引导 + 后缀优化 + 图-短语注入。
·白盒:MiniGPT-4 / InstructBLIP 100% ASR、LLaVA 98%
·跨模型迁移:GPT-4o-Mini 52% / Gemini 2.0 34% / Qwen 2.5-VL 46%
·💡 机制:核心 insight 是"图像和文本的语义对齐存在 dissonance gap"——攻击者构造让模型在图像上看到 A、在文本上推断出 B 的输入,用后缀优化 + 图-短语注入放大这种 dissonance
·⚠️ 局限:白盒攻击成功率虽高,但需要梯度访问;跨模型迁移有效但不稳定
🛠 你能学到什么:VLM 越狱的根因是图文语义 dissonance gap——构造图像-文本指向不同语义就能撬开模型,跨模型迁移有效是因为这是 VLM 的通病
📄 全文解读见文末参考 [23]
🔍 技术综观
AI 安全研究正在从经验主义走向机制主义。FHI 把幻觉归因到 attention head 功能特化的失衡,D2-Align 把对齐崩溃归因到优化方向坍缩,Skyra 把检测可信度归因到推理过程可观测,DGSIP 把越狱攻击归因到模态间语义不对齐。这四篇都在用同一种研究范式:先找到"问题的内在机制",再设计针对机制的干预或攻击。这种范式转变意味着 AI 安全研究开始具备"可累积性"——以前的攻防是 cat-and-mouse 无尽循环,现在每篇论文都在为"VLM 内部结构图谱"添加一块拼图。但代价是:模型的复杂度让机制级研究越来越依赖小模型实验(MiniGPT-4、LLaVA 而非 GPT-4o),结论到大模型的可迁移性需要持续验证。
研究启示:评价一个 AI 安全方法不要只看"防住了多少攻击",要看"它揭示了模型的哪个内在机制"——后者才是可持续的学术资产。
💼 落地实战:你下周可以做的 3 件事
场景一:你做 VLM 服务、被幻觉投诉。 → FHI 路线:不用训对抗样本,找到失衡 head 做差异化重缩放即可。好处:插件式、跨模型可复用、几乎零延迟代价。
场景二:你做扩散模型 RLHF。 → D2-Align 路线:把对齐方向分解为「质量」和「多样性」两个正交分量。避坑:单目标对齐天然崩塌,多目标分解才是必修。
场景三:你做 AI 内容检测服务。 → Skyra 路线:让模型显式输出「哪个 patch 有什么伪影」——可被审计的检测比黑箱准确率高的检测更值钱。法规角度:欧盟 AI Act 已开始要求过程可解释。
安全把模型管住了,那它能不能站起来走路?这把就该具身上场。 ↓
07
具身智能:从「模仿学习」转向「物理一致交互」
今年的具身论文不再训"看视频学动作",而是直奔"人形机器人能不能真的握手"。
261 篇集中在三个挑战:人-人视频到人形机器人的迁移、稀疏传感器下的姿态重建、长期记忆与多目标导航融合。关键转折:具身研究开始系统性区分"运动学等效"和"动力学一致"——前者只要关节角度对得上、后者要满足接触力和摩擦约束——这是从仿真到真机部署的关键一跃。

图 7.1 · PAIR + D-STAR 把人-人演示数据转成物理一致的人形机器人数据
代表论文
Beyond Mimicry(PAIR + D-STAR) · 中山大学 & 鹏城实验室
物理感知交互重定向 + 解耦时空动作推理。
·0.35m 阈值 Contact F1 0.841(ImitationNet +67.5%),平均成功率 75.4%
·已在 Unitree G1 上执行 Hug/Handshake/High-Five
·💡 机制:传统重定向只对齐关节角度,PAIR 同时对齐"接触面 + 力闭合 + 关节扭矩边界",D-STAR 把动作分解为时空两个解耦因子分别推理——让人-人演示数据满足人形机器人的物理约束
·⚠️ 局限:依赖人形机器人 URDF 模型精度,模型不准时物理约束失真
🛠 你能学到什么:重定向不要只对齐关节角度——同时对齐接触面 + 力闭合 + 关节扭矩边界,人-人视频才能真在 Unitree G1 上做出物理一致动作
📄 全文解读见文末参考 [24]
FloVerse北理工
ThreeDiff 两阶段模仿学习,多模态导航统一框架。
·PointNav 成功率 +16.2%,SPL +11.0%;同时跑 PointNav/ObjectNav/ImageNav
·💡 机制:把地图先验(平面图)作为扩散模型的初始噪声分布,让导航策略在已知地图结构上更快收敛——本质是把"先验地图"当成贝叶斯先验注入策略空间
·⚠️ 局限:依赖平面图作为输入,无图场景退化
🛠 你能学到什么:先验地图不是 input,是贝叶斯先验——把平面图当扩散初始噪声分布注入策略空间,导航策略 sample efficiency 暴涨
📄 全文解读见文末参考 [25]
MemoryExplorer(LMEE-Bench) · 华东师大 & 上海 AI Lab
长期记忆 + MLLM-based 强化学习的具身探索框架。
·GOAT-Bench 成功率 46.40%(RA-Mem +3.59%),SPL 28.03(+6.08)
·💡 机制:把长期记忆建模为"结构化场景图"而非"flat memory bank",MLLM 在做决策时显式 query 场景图获取历史观测——本质是把记忆从隐式 hidden state 提升为显式可推理对象
·⚠️ 局限:场景图构建依赖准确的物体检测,检测错误会放大决策错误
🛠 你能学到什么:长期记忆要显式可推理——别用 hidden state 做隐式记忆,把记忆建模成场景图让 MLLM 显式 query,多目标导航成功率才能稳定提升
📄 全文解读见文末参考 [26]
ReGenHOI3D 人-物交互
3D 接触推理统一重建与生成。
·DAMON 上接触预测 F1 78.4(InteractVLM +2.8),测地线距离 2.65 cm
·💡 机制:把"识别接触"和"生成接触"放在同一个 3D 接触推理模块里——重建用它检验生成是否物理合理,生成用它产生新接触场景,互为约束
·⚠️ 局限:接触面建模假设刚体,软体交互(如布料)尚未覆盖
🛠 你能学到什么:重建和生成应共享接触合理性模块——让「识别接触」和「生成接触」在同一个 3D 接触推理模块里互验,避免生成出物理不合理姿态
📄 全文解读见文末参考 [27]

图 7.2 · 视频判别器为具身策略提供高效奖励信号
🔍 技术综观
具身研究正经历"物理约束的显式化"。Beyond Mimicry 把"接触力 + 力闭合"显式约束、FloVerse 把"平面图先验"显式注入、MemoryExplorer 把"长期记忆"显式建模为场景图、ReGenHOI 把"3D 接触合理性"显式作为重建-生成的统一锚点。它们共享同一个深层 insight:从隐式 representation 转向显式 prior,可以同时获得 sample efficiency 和 sim-to-real 鲁棒性。但具身领域面临一个独特的张力:显式约束让模型更可靠,但也让它失去"涌现"能力——比如一个完全约束于人形机器人物理模型的策略,无法迁移到四足机器人或机械臂。下一道槛是"先验的模块化"——能否把物理约束设计为可插拔的模块,让同一策略骨架适配不同形态的机器人。
研究启示:选具身方法不要只看"它在某仿真器上 SOTA",要看"它能不能在你的机器人 URDF 上保持物理一致"——这是 sim-to-real 的真正瓶颈。
💼 落地实战:你下周可以做的 3 件事
场景一:你做人形机器人交互产品。 → Beyond Mimicry 路线:人-人视频经过 PAIR 重定向(接触力 + 力闭合 + 扭矩)再训。避坑:URDF 必须准确,否则物理约束反成噪声。
场景二:你做家用机器人导航。 → FloVerse 路线:让用户上传户型平面图当贝叶斯先验注入扩散策略。用户体验:平面图准确度直接影响导航成功率,让用户标关键障碍物。
场景三:你做需要长期记忆的具身 agent。 → MemoryExplorer 路线:场景图替代 flat memory bank,MLLM 显式 query。前提:物体检测器要稳,否则错误放大。
机器人能动了,但还得"想清楚再动"——下一关是视觉推理。 ↓
08
视觉推理:从「文本 CoT」转向「视觉 CoT + RL」
单一文本 CoT 把视觉信息压成符号,今年开始用视觉 CoT + RL 把信息留在像素里。
240 篇集中解决三件事:推理时视觉 grounding 衰减、测试时自适应、3D 空间关系与计数等可量化细粒度推理。关键转折:视觉推理研究开始放弃"用文本 CoT 模仿人类思考"的隐喻,转向更激进的立场——思考本身可以发生在视觉模态内,而不必经过语言中介。

图 8.1 · V-CoT + ToT-Evaluation 实现自动驾驶多维路点评估
代表论文
HybridDriveVLADongguk University
Qwen2-VL-2B 骨干,V-CoT + ToT 协同。
·nuScenes 平均碰撞率 0.17%(ST-P3)/ 0.19%(UniAD),比单独 ToT 相对 -26%
·💡 机制:V-CoT 在视觉模态内生成中间路点(不转成文本描述),ToT 在路点空间做评估剪枝——本质是把搜索从文本 token 空间挪到视觉 token 空间
·⚠️ 局限:仅在自驾这种"有空间路点结构"的任务上有效,开放域任务尚未验证
🛠 你能学到什么:思考可以发生在视觉模态而非文本——V-CoT 在视觉路点空间搜索 + ToT 在该空间评估剪枝,自动驾驶碰撞率相对降 26%
📄 全文解读见文末参考 [28]
VisRefUMD & Amazon & Physion
测试时用行列式点过程自适应重聚焦视觉 token。
·InternVL-3.5-8B:MathVision +4.5% / MathVista +11.2% / MM-Star +5.9%
·SAIL-VL2-8B:+7.5% / +6.4%,完全训练无关
·💡 机制:用 Determinantal Point Process 在测试时动态选择"既相关又多样"的视觉 token 子集喂给推理过程,对抗 grounding 衰减——本质是把视觉 attention 从"软选择"升级为"硬子集选择"
·⚠️ 局限:DPP 采样有一定计算开销,对极短上下文增益有限
🛠 你能学到什么:测试时还能再榨一波性能——用 DPP 在测试时动态选「既相关又多样」的视觉 token 子集,训练无关、即插即用、多基准提升 4-11%
📄 全文解读见文末参考 [29]
QICA西工大 & TeleAI & 中科大
零样本物体计数 + 空间感知。
·FSC-147:12.41 MAE / 97.28 RMSE,CARPK:6.07 MAE,ShanghaiTech-A 极端密集 140.7 MAE
·💡 机制:传统计数靠回归,QICA 改用协同提示策略 + 成本聚合解码器——把"数数"建模为"在密度图上做匈牙利匹配",把数量感知和空间感知统一在一个解码器里
·⚠️ 局限:在极端遮挡场景下仍依赖检测器,端到端能力未完全消除外部依赖
🛠 你能学到什么:数数 = 在密度图上做匈牙利匹配——把数量感知和空间感知统一在 cost aggregation 解码器里,零样本计数能跑赢专门训练的检测器
📄 全文解读见文末参考 [30]
QuatRoPE南方科大 & 北大
四元数旋转位置编码做 3D 空间关系。
·ASR 基准准确率 +11.90% 至 +19.48%
·💡 机制:传统 RoPE 在 2D 旋转里编码位置,QuatRoPE 把它推广到四元数旋转,自然表达 3D 空间方向;本质是把"位置编码的对称群"从 SO(2) 升级到 SO(3)
·⚠️ 局限:仅在显式 3D 输入(点云、深度图)下有效,纯 RGB 推理收益小
🛠 你能学到什么:位置编码的对称群决定能表达什么关系——RoPE 的 SO(2) 升级到四元数 SO(3),3D 空间关系推理准确率提升 12-19%
📄 全文解读见文末参考 [31]

图 8.2 · BN-GSPO 强化学习协调多模态多工具协同
🔍 技术综观
视觉推理的方法论正在走向"模态原生"。HybridDriveVLA 让搜索发生在视觉路点空间,VisRef 让 attention 子集选择发生在视觉 token 空间,QICA 让计数发生在密度图空间,QuatRoPE 让 3D 关系编码发生在四元数空间。它们共享同一个 insight:思考不必经过语言中介,可以在视觉模态自身的几何结构内完成。这是对"语言是通用推理表示"假设的挑战——视觉推理可能需要它自己的"思维语法"。但这种范式转变也面临挑战:模态原生的推理过程难以人类可读、难以调试,黑箱程度比文本 CoT 更高。下一道槛是"视觉推理的可解释性"——能否在保持模态原生的同时,提供让人类可验证的中间结果?
研究启示:选视觉推理方法先问"我的任务结构能不能在视觉模态内自洽地表达?"——能就用 V-CoT,不能就回归文本 CoT 加 grounding。
📋 本周可以做什么:8 条行动清单
读完了不做就是白读。挑 1-2 条本周尝试:
☐1.降幻觉:拿你现在的 VLM 跑一遍 FHI 路线——统计 attention head 在 grounding 任务上的激活模式,识别「感知/推理」两类做差异化 inference 重缩放。1-3 天可出结果。
☐2.DiT 部署提速:如果你跑 Flux 或 SD3.5+,试 PPCL contiguous layer distillation,先做 20% 层压缩验证精度损失曲线。
☐3.agent + 引擎:把你产品里「端到端生成」的某个模块改成「MLLM 输出专业参数 + 引擎渲染」,对比可解释性和用户可控性。
☐4.测试时优化:给现有 MLRM 加 VisRef 测试时 token 重聚焦——训练无关、即插即用、收益 4-11%。
☐5.工具协同 RL:用 RL 让你的模型学会「调用搜索/裁剪/计算工具」,按 SenseSearch 思路构造 action space 训。
☐6.量化新解法:70B+ 大模型部署时别用一刀切量化,给 token 级误差 pattern 训补偿专家。
☐7.因果干预:对你最头疼的「模型在某类数据上系统性失败」问题,画因果图找混淆变量,按 CausalVAD 套路做稀疏干预实验。
☐8.建立「机制级」评测习惯:以后看到新方法,先问「它揭示了什么内在机制」,再看「它的数据是多少」——前者才是可累积资产。
一句话总结
CVPR 2026 不再回答「视觉模型能做什么」,而是在回答「怎么让它在生产线上活下来」。
但比这一句更值得带走的,是 8 个趋势共同指向的3 条方法论暗线:
1.机制激活 > 参数扩张:与其训更大的模型,不如激活已有模型里被低估的隐性能力
2.先验显式化 > 数据驱动:物理约束、因果图、几何对称、平面地图——把领域先验显式编码进架构
3.过程可观测 > 端到端黑箱:concept erasure、AI 生成检测、grounded artifact reasoning、causal intervention,都在要求模型留下「推理过程的证据」
如果只能记一句话:模型变小、控制变强、数据变贵、安全变成必选项——而支撑这一切的方法论暗线是机制激活、先验显式、过程可观测。
读完了,本周挑 1-2 条行动清单上手——这才是 insight 的真正价值。
📚 论文全文解读(PaperScope)
[1] 🔗 https://www.paperscope.ai/paper/cvpr2026.Shekhar_GT-SVJ_Generative-Transformer-Based_Self-Supervised_Video_Judge_For_Efficient_Video_Reward_Modeling_CVPR_2026_paper
[2] 🔗 https://www.paperscope.ai/paper/cvpr2026.Lu_Reallocating_Attention_Across_Layers_to_Reduce_Multimodal_Hallucination_CVPR_2026_paper
[3] 🔗 https://www.paperscope.ai/paper/cvpr2026.Chng_SenseSearch_Empowering_Vision-Language_Models_with_High-Resolution_Agentic_Search-Reasoning_via_Reinforcement_CVPR_2026_paper
[4] 🔗 https://www.paperscope.ai/paper/cvpr2026.Jia_Quant_Experts_Token-aware_Adaptive_Error_Reconstruction_with_Mixture_of_Experts_for_Large_Vision-Language_Models_Quantization_CVPR_2026_paper
[5] 🔗 https://www.paperscope.ai/paper/cvpr2026.Xiao_Generalizable_Structure-Aware_Keypoint_Correspondence_for_Category-Unified_3D_Single_Object_Tracking_CVPR_2026_paper
[6] 🔗 https://www.paperscope.ai/paper/cvpr2026.Yang_DirectFisheye-GS_Enabling_Native_Fisheye_Input_in_Gaussian_Splatting_with_Cross-View_CVPR_2026_paper
[7] 🔗 https://www.paperscope.ai/paper/cvpr2026.Lyu_Choreographing_a_World_of_Dynamic_Objects_CVPR_2026_paper
[8] 🔗 https://www.paperscope.ai/paper/cvpr2026.Bui_EcoSplat_Efficiency-controllable_Feed-forward_3D_Gaussian_Splatting_from_Multi-view_Images_CVPR_2026_paper
[9] 🔗 https://www.paperscope.ai/paper/cvpr2026.Yuan_UniComp_Rethinking_Video_Compression_Through_Informational_Uniqueness_CVPR_2026_paper
[10] 🔗 https://www.paperscope.ai/paper/cvpr2026.Ma_Pluggable_Pruning_with_Contiguous_Layer_Distillation_for_Diffusion_Transformers_CVPR_2026_paper
[11] 🔗 https://www.paperscope.ai/paper/cvpr2026.Jeong_Training-free_Perceptually_Consistent_Low-Resolution_Previews_with_High-Resolution_Image_for_Efficient_CVPR_2026_paper
[12] 🔗 https://www.paperscope.ai/paper/cvpr2026.Hollidt_Ultra_Diffusion_Poser_Diffusion-Based_Human_Motion_Tracking_from_Sparse_Inertial_CVPR_2026_paper
[13] 🔗 https://www.paperscope.ai/paper/cvpr2026.Jia_CompBench_Benchmarking_Complex_Instruction-guided_Image_Editing_CVPR_2026_paper
[14] 🔗 https://www.paperscope.ai/paper/cvpr2026.Dong_DreamSR_Towards_Ultra-High-Resolution_Image_Super-Resolution_via_a_Receptive-Field_Enhanced_Diffusion_CVPR_2026_paper
[15] 🔗 https://www.paperscope.ai/paper/cvpr2026.Seo_Erasing_Thousands_of_Concepts_Towards_Scalable_and_Practical_Concept_Erasure_for_Text-to-Image_Diffusion_Models_CVPR_2026_paper
[16] 🔗 https://www.paperscope.ai/paper/cvpr2026.Wu_RetouchIQ_MLLM_Agents_for_Instruction-Based_Image_Retouching_with_Generalist_Reward_CVPR_2026_paper
[17] 🔗 https://www.paperscope.ai/paper/cvpr2026.Wang_Multimodal_Protein_Language_Models_for_Enzyme_Kinetic_Parameters_From_Substrate_CVPR_2026_paper
[18] 🔗 https://www.paperscope.ai/paper/cvpr2026.Tang_CausalVAD_De-confounding_End-to-End_Autonomous_Driving_via_Causal_Intervention_CVPR_2026_paper
[19] 🔗 https://www.paperscope.ai/paper/cvpr2026.Goren_Visual_Diffusion_Models_are_Geometric_Solvers_CVPR_2026_paper
[20] 🔗 https://www.paperscope.ai/paper/cvpr2026.Li_DROID-SLAM_in_the_Wild_CVPR_2026_paper
[21] 🔗 https://www.paperscope.ai/paper/cvpr2026.Zhang_D2-Align_Taming_Preference_Mode_Collapse_via_Directional_Decoupling_Alignment_CVPR_2026_paper
[22] 🔗 https://www.paperscope.ai/paper/cvpr2026.Tsinghua_Skyra_AI-Generated_Video_Detection_via_Grounded_Artifact_Reasoning_CVPR_2026_paper
[23] 🔗 https://www.paperscope.ai/paper/cvpr2026.USTC_DGSIP_Jailbreaking_Vision-Language_Models_via_Dissonance-Guided_Suffix_Optimization_CVPR_2026_paper
[24] 🔗 https://www.paperscope.ai/paper/cvpr2026.Huang_Beyond_Mimicry_Learning_Whole-Body_Human-Human_Interaction_from_Human-Human_Demonstrations_CVPR_2026_paper
[25] 🔗 https://www.paperscope.ai/paper/cvpr2026.Huang_FloVerse_Floor_Plan-Guided_Multi-Modal_Navigation_CVPR_2026_paper
[26] 🔗 https://www.paperscope.ai/paper/cvpr2026.Wang_Explore_with_Long-term_Memory_A_Benchmark_and_Multimodal_LLM-based_Reinforcement_CVPR_2026_paper
[27] 🔗 https://www.paperscope.ai/paper/cvpr2026.Xu_ReGenHOI_Unifying_Reconstruction_and_Generation_for_3D_Human-Object_Interaction_Understanding_CVPR_2026_paper
[28] 🔗 https://www.paperscope.ai/paper/cvpr2026.Bassole_HybridDriveVLA_Vision-Language-Action_Model_with_Visual_CoT_reasoning_and_ToT_Evaluation_CVPR_2026_paper
[29] 🔗 https://www.paperscope.ai/paper/cvpr2026.Ghosal_VisRef_Visual_Refocusing_while_Thinking_Improves_Test-Time_Scaling_in_Multi-Modal_CVPR_2026_paper
[30] 🔗 https://www.paperscope.ai/paper/cvpr2026.Zhang_Boosting_Quantitive_and_Spatial_Awareness_for_Zero-Shot_Object_Counting_CVPR_2026_paper
[31] 🔗 https://www.paperscope.ai/paper/cvpr2026.Zhou_Scalable_Object_Relation_Encoding_for_Better_3D_Spatial_Reasoning_in_CVPR_2026_paper
这八大趋势,每篇论文都能点开读全文
PaperScope 收录 9 万+ 篇论文的中文深度解析,CVPR 2026 全量可检索——机制、消融、局限,逐篇拆给你看。
👉 点击「阅读原文」进入 PaperScope
读到这儿,说明你是真的关心视觉 AI 的走向 🙏
如果有收获,欢迎 点赞、在看、转发 三连
想追更记得给我们加个 星标 ⭐ 我们下篇见 👋
© 2026 机智流 × PaperScope · 本文由论文库解析生成,可能有误










