Baton团队 投稿
量子位 | 公众号 QbitAI
视频生成,早已不止于视觉。
随着生成式AI发展,联合视频—音频生成正成为重要研究方向。与视频优先、音频后期合成的传统流水线相比,原生同步生成的视听内容跨模态一致性更强,用户体验更沉浸。
但问题在于,现有开源模型面对复杂语义时力不从心。
遇到多阶段动作的组合式指令、涉及人与物体交互的复杂任务时,模型往往无法准确建模场景中的时序逻辑和因果关系——不仅要求长程语义推理能力,还必须在推理中维持视频与音频的时空一致性。
核心矛盾在于:现有方法依赖粗粒度全局文本嵌入指导扩散过程,无法将多阶段动作与多说话人对话分解为具有时间对齐的指导信息,视频和音频去噪轨迹因此各自演化,最终跨模态失配。
为解决这一问题,复旦&腾讯Hunyuan团队提出了Baton——首个基于显式语义蓝图引导的联合视频—音频生成框架:

核心思路,是将语义推理与内容生成显式解耦:先用可学习MLLM完成跨模态语义规划,生成视频和音频各自对应的Planned Tokens作为语义蓝图,再注入扩散模型指导联合生成。两条生成轨迹从一开始便共享同一份预先对齐的语义路线图,从根本上避免跨模态偏移。
在复杂场景基准Sem100上,Baton比LTX-2在提示词遵循准确率(P-Acc)上提升32%,多说话人词错误率(M-WER)提升76%,DeSync提升30%。在复杂指令遵循上,Baton甚至能媲美Seedance 2.0和Wan 2.7。

论文已挂arXiv,代码和项目主页同步开放。
方法简介
如下图所示,Baton通过显式解耦语义推理与内容生成两个阶段,构建了具备模态感知能力的语义蓝图(Blueprint)机制,统一协调视频与音频的扩散去噪过程。
用户输入的文本提示首先送入多模态大语言模型(MLLM)进行语义推理,预测出分别对应视频和音频模态的planned tokens。这些planned tokens充当跨模态共享的语义蓝图,为后续生成提供明确的内容规划和时序指导。
Planned tokens进一步通过cross-attention注入扩散Transformer(DiT)中。这里的DiT延续了Ovi的双分支架构,分别负责视频与音频的生成与去噪。
值得注意的是,planned tokens与扩散模型中的latents分布在不同的时空网格上,天然存在位置对应不一致的问题。为此,Baton提出了Relative Semantic RoPE(RS-RoPE)机制,通过统一的相对位置编码空间,实现planned tokens与diffusion latents之间的精确语义对齐。
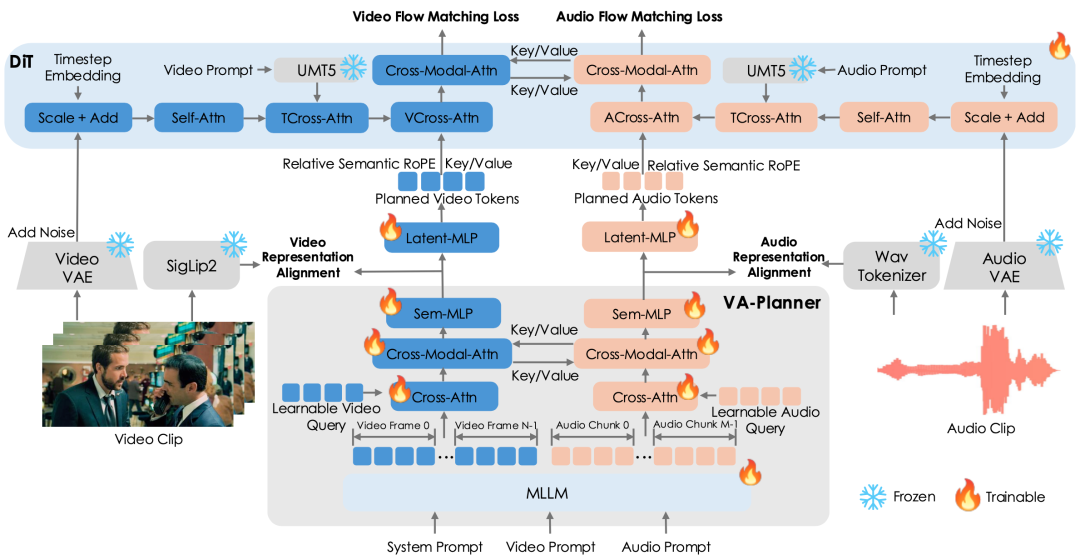
VA-Planner:跨模态语义推理核心
当前联合视频—音频生成模型仅依赖冻结LLM提取的全局文本嵌入来指导生成过程:整个提示词被编码为一个模糊的全局向量,不会分解为模态特定的时序语义,也不会建模视觉事件与听觉线索应如何在每个阶段协同对应。
视频与音频两个去噪分支只能各自独立地解释这一模糊信号,在复杂场景下不可避免地出现语义偏离。
VA-Planner的解法:用一个可训练的MLLM进行语义推理,预测模态特定但相互对齐的planned tokens。每个token编码一个局部语义上下文,描述发生了什么、发生在哪里以及发生在何时。
视频与音频的planned tokens在同一次自回归推理过程中联合生成,保证每个时间点上的跨模态一致性。在进入扩散去噪过程之前,两条生成轨迹都被锚定到同一份共享的语义路线图上,避免两种模态演化为彼此冲突的动态过程。
对于包含N个关键帧(FPS=6采样)和M个音频块(每块对应1秒音频)的生成任务,Baton构造结构化用户Prompt 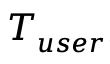 :
:
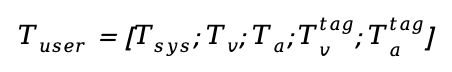
其中 包含视觉语义token占位符,每个关键帧对应
包含视觉语义token占位符,每个关键帧对应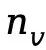 个视觉token,总视频token数
个视觉token,总视频token数 。
。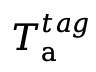 包含音频语义token占位符,每个音频块对应
包含音频语义token占位符,每个音频块对应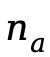 个音频token,总音频token数
个音频token,总音频token数 。由于
。由于 ,对所有音频块预测在计算上可承受。
,对所有音频块预测在计算上可承受。
MLLM对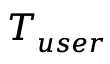 执行自回归推理,从占位符位置提取隐藏状态,获得视频和音频隐藏表示
执行自回归推理,从占位符位置提取隐藏状态,获得视频和音频隐藏表示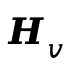 和
和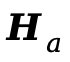 。由于音频规划区域位于视频规划区域之后,
。由于音频规划区域位于视频规划区域之后,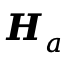 还能进一步关注前面的
还能进一步关注前面的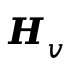 ,在推理阶段自然建立隐式的跨模态依赖关系。
,在推理阶段自然建立隐式的跨模态依赖关系。
双语义对齐塔
Planned tokens的目标是编码具体的感知结构,而不是停留在MLLM以自然语言描述为中心的表示空间中。为此,Baton设计了双语义对齐塔(Dual Semantic Alignment Towers),将planned tokens映射到预训练感知编码器的连续特征空间——视频采用SigLip2,音频采用WavTokenizer。
由于MLLM中的因果依赖是单向的(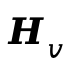 无法访问
无法访问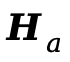 ),视频规划无法感知音频信息。双语义对齐塔通过双向跨模态注意力解决这一问题。
),视频规划无法感知音频信息。双语义对齐塔通过双向跨模态注意力解决这一问题。
每个对齐塔均采用可学习查询向量(learnable queries),从Hv和Ha中灵活提取最相关的语义信息,生成planned tokens。
对于视频塔,可学习查询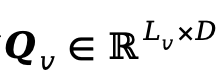 首先对
首先对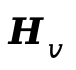 执行跨注意力提取视频特定语义,随后通过跨模态注意力
执行跨注意力提取视频特定语义,随后通过跨模态注意力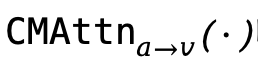 吸收互补的音频信息,最后经由语义MLP(Sem-MLP)映射到目标感知编码器的特征维度:
吸收互补的音频信息,最后经由语义MLP(Sem-MLP)映射到目标感知编码器的特征维度:
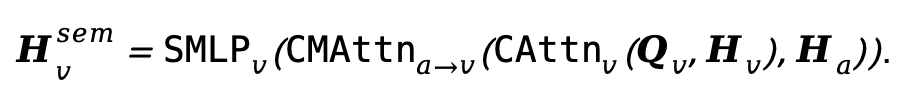
对应地,音频塔生成:

由于 和
和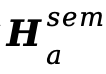 具有不同的时序参考系,在
具有不同的时序参考系,在
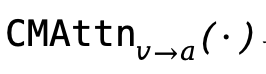 与
与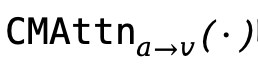 中引入基于时间戳的RoPE(timestamp-based RoPE),将两种模态映射到统一的时间轴上。借助双语义对齐塔,
中引入基于时间戳的RoPE(timestamp-based RoPE),将两种模态映射到统一的时间轴上。借助双语义对齐塔, 与
与 编码的不再是两个独立的规划,而是一份彼此一致、共享的时序语义蓝图。
编码的不再是两个独立的规划,而是一份彼此一致、共享的时序语义蓝图。
值得注意的是,Baton在不同阶段采用两种不同的RoPE设计:
1、时间戳RoPE(Timestamp-based RoPE)。用于双语义对齐塔中的CMAttn,负责规划阶段的跨模态token对齐。
2、相对语义RoPE(Relative Semantic RoPE,RS-RoPE)。用于DiT中的VCAttn和ACAttn,负责在扩散去噪阶段对齐planned tokens与扩散潜变量。具体实现细节和详细公式推导请阅读原论文。
三阶段训练策略
1、VA-Planner预训练(VA-Planner Pretraining)。以Qwen3初始化MLLM,训练整个VA-Planner(即 )。给定真实视频和音频数据,分别从冻结的SigLip2和WavTokenizer的倒数第二层提取目标连续特征
)。给定真实视频和音频数据,分别从冻结的SigLip2和WavTokenizer的倒数第二层提取目标连续特征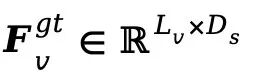 和
和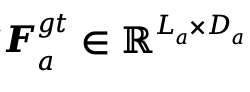 。监督目标为planned tokens与真实感知特征之间的L2损失。与基于离散token的规划方式相比,直接回归连续特征能保留更丰富的语义结构信息。
。监督目标为planned tokens与真实感知特征之间的L2损失。与基于离散token的规划方式相比,直接回归连续特征能保留更丰富的语义结构信息。
2、DiT适配(DiT Adaptation)。为使DiT能够学习语义特征的分布,而不受VA-Planner预测误差干扰,采用Ovi初始化DiT,并将真实特征
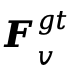 和
和 (经过Latent-MLP投影后)直接输入到VCAttn(·)和ACAttn(·)中作为条件信息。采用Flow Matching损失训练DiT速度场预测器
(经过Latent-MLP投影后)直接输入到VCAttn(·)和ACAttn(·)中作为条件信息。采用Flow Matching损失训练DiT速度场预测器
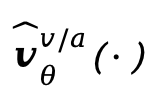 。
。
3、联合微调(Joint Fine-tuning)。VA-Planner与DiT连接为完整系统,VA-Planner参数冻结,DiT继续训练。此时DiT不再使用真实特征 和
和 作为条件,而是接收VA-Planner预测得到的
作为条件,而是接收VA-Planner预测得到的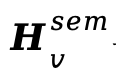 和
和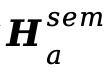 ,训练仍采用Flow Matching损失。该阶段旨在弥合第二阶段使用的理想编码器特征与实际规划器预测结果之间的差距,减轻曝光偏差(exposure bias)问题,保证生成过程的鲁棒性。
,训练仍采用Flow Matching损失。该阶段旨在弥合第二阶段使用的理想编码器特征与实际规划器预测结果之间的差距,减轻曝光偏差(exposure bias)问题,保证生成过程的鲁棒性。
实验结果
Baton与开源模型在Verse-Bench和Sem100两个测试集上进行对比。
Verse-Bench为开源的音画一致生成测试集;Sem100为内部收集的100条测试样例,text prompt包含人物与周围环境的多次连续性交互动作、多人复杂交互、多个连续指定性质的复杂组合动作描述,语义复杂度远高于现有开源测试集。
评估维度包括:视频质量(AQ、IQ、DD、ID),音频质量及音视频同步性(PQ、CU、M-WER、Sync-C、Sync-D、DeSync),以及提示词遵循准确率(P-Acc)。

与领先方法LTX-2相比,Baton在Verse-Bench上取得相当结果(该集合提示主要描述简单单事件场景,不需要深层语义推理)。在Sem100上优势则更加明显:
- P-Acc:比LTX-2提升32%
- M-WER:比LTX-2提升76%
- DeSync:比LTX-2提升30%
M-WER差距尤为显著。多说话人场景要求模型明确推理哪个角色在何时说了什么内容,这正是planned tokens所提供的局部、时间对齐语义能力——而传统全局文本嵌入无法有效拆解。
P-Acc和M-WER的显著差距进一步验证:在复杂提示场景中,显式语义规划是必要的。
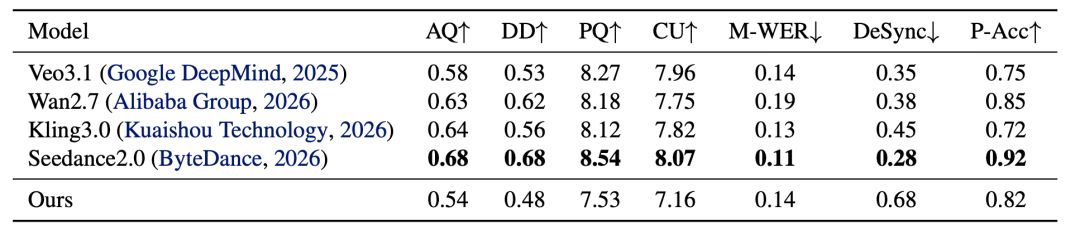
与闭源商业模型的对比同样有力:尽管Baton在视觉质量和音频美感方面仍落后于商业模型,但在提示词遵循能力方面表现出相当的性能。在Sem100复杂指令遵循上,Baton的性能超越了Kling 3.0,并能媲美Seedance 2.0和Wan 2.7。
生成结果展示
Video Prompt: On a vast barren beach under a pale overcast sky with haze obscuring the flat horizon, a young man with dark messy hair lies face down on the sand…
Audio Prompt: On a windswept open beach, continuous artillery explosions rumble and crash, growing progressively louder and closer…
Video Prompt: In a indoor martial arts gym with yellow padded bars along the wall, two bald men of Middle Eastern descent stand facing each other…
Audio Prompt: In a gym with faint ambient echo, a mature man [Speaker A] speaks in a steady, instructional tone: “Think about the idea of short distance power…”
Video Prompt: At dusk in a desolate clearing beside a rustic log cabin, a bearded white man squats before a small crackling campfire…
Audio Prompt: A quiet outdoor dusk atmosphere with faint wind rustling dry grass. A small campfire crackles and pops…
Video Prompt: In a dimly lit interior, a close-up shows hands using a knife and fork to slice through a medium-rare steak on a white square plate…
Audio Prompt: A knife sawing through steak with a soft, wet slicing sound against the plate. A fork scrapes briefly. Quiet, slow chewing follows…
Video Prompt: Inside an old car, a girl wearing a grey-white t-shirt first looks down, then smiles slightly while steering along a rural road…
Audio Prompt: A dramatic orchestral score with sweeping strings. The music is layered with the sounds of a vehicle engine starting and revving…
Video Prompt: On a sunny suburban backyard, a woman in a ribbed sweater and black skirt rallies a shuttlecock with a boy across a badminton net…
Audio Prompt: A fast-paced electronic dance music track plays throughout. A boy [Speaker A] shouts: “Oh no! Ten points! I’m scared!” A girl [Speaker B]: “We’re the winners!”
Video Prompt: On a residential street corner, a young Asian boy in bright blue shorts stands holding a brown Spalding basketball in one hand and a yellow-orange ball in the other…
Audio Prompt: A young boy [Speaker A] speaks: “This is two ball basketball drill.” Immediately after, the rhythmic sound of a basketball being dribbled begins…
Video Prompt: A young Caucasian man stands at an outdoor shooting range, holding a scoped AR-15 rifle, he fires several shots at a nearby pine tree, then reloads.
Audio Prompt: In a quiet, open outdoor environment, a sharp gunshot rings out, followed by a male voice [Speaker A] saying “Ah”. After a brief pause, a mechanical click is heard, as if a weapon is being reloaded.
Video Prompt: On a sunlit outdoor asphalt basketball court, a young man dribbles the ball between his legs, takes a jump shot; the ball arcs over the rim and drops through the net.
Audio Prompt: A young man [Speaker A] speaks: “Easy peasy, baby.” The sound of a ball being dribbled on a hard surface is heard, followed by a sharp impact as it hits a backboard.
论文地址:https://arxiv.org/pdf/2605.25195
项目主页:https://francis-rings.github.io/Baton/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟