
IB-Robot是OpenAtom openEuler(简称“openEuler”或“开源欧拉”)社区孵化的具身智能OS全栈技术,为开发者、行业伙伴提供从底层硬件到上层算法的全链路端到端解决方案。
在前一篇《》中关于 Action Dispatcher 的深度解析中,聚焦了”如何将单一模型输出的离散动作块平滑转译为连续的物理执行”。本文将视角向上推一层,讨论系统中的另一个关键组件:Inference Scheduler。它负责在多个异构模型之间做选择,让推理链路既跟得上控制节奏,也不会把有限算力浪费在不合适的模型上。
当前以 LeRobot 为代表的具身智能框架,普遍采用”单模型 per Launch”的设计:系统启动时选定唯一的推理模型,整个运行周期内不切换。这在单一任务、固定场景的 Demo 阶段够用。
但进入真实环境后,问题会明显变复杂:
1.任务多样性:一个真实的机器人工作场景中,“抓取放置”、“精细插孔”、“柔性操作”等子任务往往需要不同的策略模型。期望一个通用模型覆盖所有场景,成本高,效果也未必稳定。
2. 算力异构性:云端大参数量模型擅长复杂语义理解,但延迟高;端侧轻量化模型响应快,但能力边界更窄。调度器要做的不是固定选择某一类模型,而是在当前约束下选更合适的一类。
3. 场景实时性:机器人执行任务时经常会被打断。正在抓取时收到新的语音指令、导航途中遇到障碍、精密操作中检测到物体滑落,这些都可能触发模型管线切换。系统中同时存在多个不同实时性要求的模型,它们各自有独立的截止时间(deadline)和帧率要求。这类系统更接近实时多模型(RTMM, Real-Time Multi-Model)负载,而不是传统的单模型推理服务。
4.负载动态性:真实部署中的推理负载并不恒定。任务切换、环境变化、算力波动都会改变系统负载,静态调度很难长期保持稳定。
多模型调度要解决的问题可以概括为一句话:让对的模型,在对的时刻,跑在对的设备上。
IB-Robot 的多模型调度从 Layer 0 到 Layer 4 逐层展开。Layer 0 是系统优化底座,负责提供真实资源状态和高效数据通路;上面四层是调度平面,负责”选哪个模型、什么时候跑、跑在哪里”。这样底层系统资源、模型实例、模型生命周期、推理调度和任务路由不会混在一起。

▲IB-Robot 四层多模型调度架构
图中从 Layer 0 到 Layer 4 表示完整链路。Layer 0 不直接做模型选择,但会持续向 Inference Scheduler 提供资源状态和数据通路状态,影响后续评分和路由结果。
Layer 0:系统优化底座
Layer 0 承接操作系统和 ROS 通信层。openEuler 侧提供 CPU、NPU、内存带宽等运行时状态,并结合历史数据做短期负载判断;ROS 异构加速侧负责优化节点间数据传递,减少图像、状态和张量在节点间流转时的复制和带宽开销。
这一层不直接参与模型选择,但会持续给 Inference Scheduler 提供底层事实:CPU 是否紧张、NPU 是否排队、内存带宽是否接近瓶颈、节点间传输是否变慢。这里特别保留内存带宽和 ROS 数据通路两个指标,是因为模型推理不只消耗算力,也会消耗大量数据搬运能力;如果忽略这部分,调度结果很容易和真实延迟脱节。
Layer 1:PolicyWrapper 实例池
最底层是系统的统一模型接口 PolicyWrapper。每个模型在系统中对应一个 PolicyWrapper 实例。多模型管理的基础是把单个 wrapper 变成 wrapper 池:系统维护已加载实例,支持线程安全的按需加载与驱逐。高频模型常驻内存,低频模型按需换入。
在这个抽象下面,系统适配了多种后端:
LeRobotPolicyWrapper:支持 ACT、Diffusion、TDMPC、VQBeT、Pi0、Pi0.5、SmolVLA 等策略类型。
CompiledPolicyWrapper:支持 Ascend OM、RKNN 等硬件加速后端,内置 ADAPTER_REGISTRY 实现策略类型到适配器类的映射。
Layer 2:Model Pool(模型注册表与生命周期)
这一层管理模型的生命周期:注册、加载、驻留、驱逐。每个模型在注册表中记录必要元数据,包括路径、策略类型、目标设备、加载策略、调度优先级、任务标签、内存占用、历史延迟、契约文件路径和可选的轻量变体列表。
Model Pool 提供三种加载策略:
eager:启动时即加载,适合高频核心模型
lazy:按需加载,适合低频大模型、
preload:在任务切换前提前预加载,消除冷启动延迟
当显存或内存压力过高时,Model Pool 会按 LRU 策略驱逐低频模型,为新模型腾出空间。
IB-Robot 的契约系统为每个模型定义输入输出规格。不同模型可能需要不同尺寸的图像、不同的状态向量或不同的动作空间。每模型一契约的映射关系,让调度器可以判断候选模型是否兼容当前观测和执行端。
Layer 3:Inference Scheduler(调度器)
这一层负责做调度判断。调度器从系统优化底座读取资源状态,再对候选模型打分、过滤明显无效的请求,并在负载变化时调整策略。
面对多个候选模型,调度器需要一套稳定的打分规则。InferScore 关注四个维度:
评分维度 | 含义 | 作用 |
紧迫性 | 预估推理延迟 / 距截止时间的余量 | 队列即将耗尽时,延迟低的模型得分更高 |
设备亲和度 | 所有设备平均延迟 / 目标设备延迟 | 模型在最擅长的设备上得分最高 |
公平性 | 等待时间 / 平均推理延迟 | 长时间未被调度的模型获得补偿 |
资源开销 | 综合显存占用、加载延迟和驻留状态 | 已驻留的模型得分更高,减少换入换出 |
紧迫性和设备亲和度绑定得最紧:如果某个请求很急,但候选模型在当前设备上很慢,它不会被轻易选中;反过来,一个模型即使跑得快,如果当前任务并不紧迫,也不应该长期挤占资源。公平性和资源开销作为调节项,用来避免某些模型长期饥饿,也减少不必要的模型换入换出。
当系统判断某个推理请求已经不可能在截止时间前完成时,会主动丢弃该请求,让 Action Dispatcher 继续持有上一帧动作。这比”发了请求但最终超时”更稳妥:后者既浪费算力,也可能阻塞后续更紧迫的请求。
过滤需同时满足四个条件:注定违规(即使最优模型也来不及)、不唯一依赖(无其他模型等这个结果)、丢弃率约束(滑动窗口内不超过阈值,防止过度丢弃)、有降级替代(存在轻量备选)。
InferScore 的公平性权重和资源权重不是固定值,而是在线调整。调度器会观察截止违规率和资源浪费率,在小范围内调整参数。这个过程在后台进行,不阻塞推理执行。
每个模型可以声明一组轻量变体。系统负载升高时,调度器可以切到轻量变体;负载恢复后,再切回标准模型:
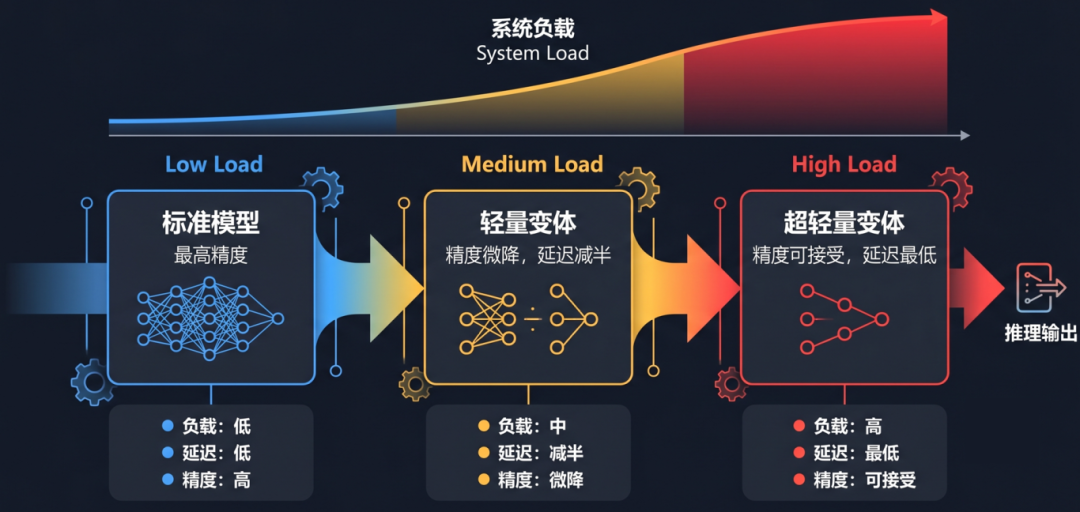
▲模型变体在线切换示意图
变体切换的关键约束是动作流不能断裂。切换时复用 Action Dispatcher 的跨帧平滑机制,在过渡区对新旧模型输出做平滑混合。
Layer 4:Task Router(任务路由)
最上层负责把外部输入(语音指令、视觉感知结果、任务状态机输出)映射为候选模型集。候选模型通常有两类来源:
1. 异构模型:不同任务对应不同专精模型。比如”抓取”对应操作策略模型,“导航”对应路径规划模型,“语义理解”对应多模态大模型。架构、参数量、输入输出规格各不相同。
2. 同源变体:同一个模型经过不同级别的蒸馏或量化,产生精度递减但推理速度递增的多个版本。比如一个操作策略模型可能同时有全精度版、量化版和蒸馏轻量版。这些变体共享相同的输入输出规格(同一契约),但在延迟、精度和资源占用上形成梯度,适配不同负载。
Task Router 的映射关系在配置中声明式定义:

▲Task Router 路由示例
Task Router 只提供候选集,最终选哪个由 Inference Scheduler 根据实时系统状态决定。这样路由规则保持可配置,模型选择又能跟随运行时负载变化。
Action Dispatcher 负责把模型输出变成连续动作流,Inference Scheduler 负责决定下一次推理该交给哪个模型。二者通过水位线机制连接:当动作队列低于阈值时,Dispatcher 触发一次调度和推理。
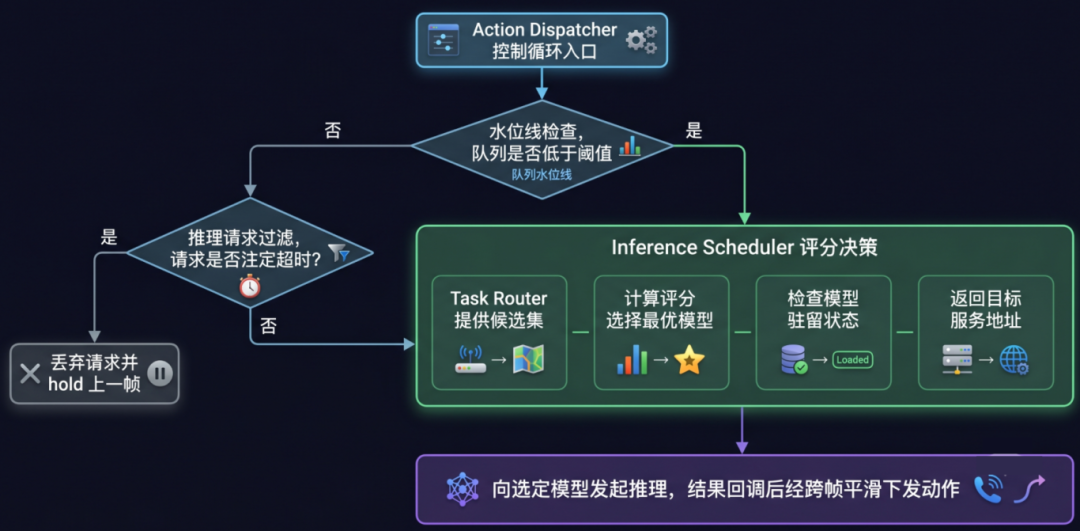
▲Action Dispatcher 与 Inference Scheduler 协作流程
Action Dispatcher 不绑定唯一推理服务。每次推理前,它先向 Inference Scheduler 查询目标服务地址,再发送推理请求。
从单模型到多模型,不是多加载几个模型那么简单。真正麻烦的地方,往往在系统资源和数据流上。
资源竞争:端侧设备的内存有限,同时驻留多个大型模型不现实。Model Pool 通过换入换出机制处理:高频模型尽量常驻,低频模型按需换入,压力过高时按 LRU 驱逐。
模型切换约束:模型 A 和模型 B 可能输出不同维度的动作向量、不同的 chunk_size、不同的归一化方式。这里不能简单替换队列,否则机器人会在切换点产生明显顿挫。因此调度器在选择候选模型时,需要优先考虑契约兼容性和切换成本。
冷启动延迟:模型从磁盘加载到设备需要时间。Model Pool 通过 eager、lazy、preload 三种策略覆盖不同场景。对已知即将发生的任务切换,可以提前 preload,避免控制流等模型加载。
内存带宽与数据通路:这部分由 Layer 0 持续提供状态输入。Inference Scheduler 不只看 CPU/NPU 负载,也会参考内存带宽和节点间传输状态,避免调度结果在真实链路里失准。
多模型调度放到云边端场景里,会形成多级拓扑:

▲云边端协同多模型拓扑
设备亲和度不仅看模型适合跑在哪类设备上,也看它适合放在哪个网络层级:
本地命中:端侧模型直接推理,链路最短,最适合高频闭环。
边缘卸载:端侧模型能力不足时,将预处理张量发送到边缘服务器推理。
云端请求:复杂语义理解任务卸载到云端,同时端侧模型继续维持控制流。
推理请求过滤在这里很关键:云端路径被选中时,系统先评估动作队列是否能覆盖这段链路延迟。如果覆盖不了,请求会被过滤或降级到端侧模型。
Action Dispatcher 的动态水位线也会参与进来。选择高延迟模型时,系统提前触发推理预取,用更长的动作队列吸收推理延迟。
整条架构延续了 Action Dispatcher 的思路:模型只管推理,调度器管编排。
PolicyWrapper 不需要知道自己跑在单模型还是多模型环境下,调度决策在系统层完成。
模型之间的动作空间差异由契约系统管理,调度器只调度契约兼容的模型。
调度基于可量化的多维评分,不依赖人工写死的规则。
PolicyWrapper、ModelPool、InferenceScheduler 都是纯 Python 组件,不依赖 ROS,可以独立单测。
一句话总结:IB-Robot 的多模型调度把模型推理和系统调度分开处理。InferScore 负责选模型,请求过滤避免无效推理,变体切换应对负载变化,Action Dispatcher 负责把切换后的动作流接顺。这样系统才能在算力、延迟和任务需求之间做稳定取舍。

开源代码仓库:
https://gitcode.com/openeuler/IB_Robot.git
文档与教程:
https://pages.openeuler.openatom.cn/embedded/docs/build/html/master/features/embodied_ai/introduction/ib-robot_overview.html

-END-
供稿 | 吴小强
编辑 | 丘云
校审 | 郑振宇、刘彦飞
关注我们,了解更多
▼











