加入高工机器人专业行业群,加微信:13590381326,出示名片,仅限机器人及智能制造产业链相关企业。
2026年,具身大模型和各类框架系统扎堆出现。
几乎每个月都有新成果公布,如提升机器人完成复杂长程任务的能力,强化模型预测能力与动作决策之间的关联,增强模型推理能力,统一并简化模型结构,提升VLM环节的推理能力,甚至为其附加运动决策功能等。
虽然方向各异,但每项成果都在修补现有模型的短板。
单看这些新发布或开源的大模型,可能会觉得方向模糊、难辨高下;但若将它们放在一起对比,就会发现一个清晰的图景:世界模型已是势不可挡的趋势,而VLA也远未退场。
具身智能企业新发布的大模型
普渡机器人
具身智能大模型PuduFM 1.0、通用具身智能体平台PuduAgent
5月11日,普渡机器人发布具身智能大模型Pudu Foundation Model(PuduFM 1.0)。
该模型采用分层解耦、协同进化的系统架构,通过模拟生物神经系统的"大脑"高层逻辑规划与"小脑"底层精细控制的清晰分工,赋予机器人应对复杂、不确定性场景的卓越鲁棒性。
5月12日,普渡机器人发布通用具身智能体平台PuduAgent。
PuduAgent是一个面向物理世界的通用具身智能体平台,包含三大核心能力:系统层(PuduAgent OS)提供运行环境与认知基座;能力层(PuduAgent Skills)构建标准化的原子能力库;安全层(PuduAgent Safety)实现执行约束与风险控制。
蚂蚁灵波
具身基座模型LingBot-VLA的真机后训练工具链
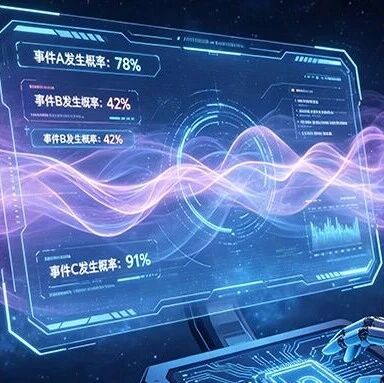
5月13日,蚂蚁集团旗下具身智能公司灵波科技,宣布全面开源具身基座模型LingBot-VLA的真机后训练工具链。
基于这套工具链,开发者可以把自有数据从LingBot-VLA快速迁移到自有机器人和具体任务中。
资料显示,此次开源针对真机适配过程,主要面向4个环节:支持多LeRobot数据合并、关节维度映射标准化的数据处理工具;面向真机场景优化的训练配置;离线评测工具;以及支持编译加速的真机部署模块。
晨昏线科技
目标因果世界模型TermiBrain GCWM1
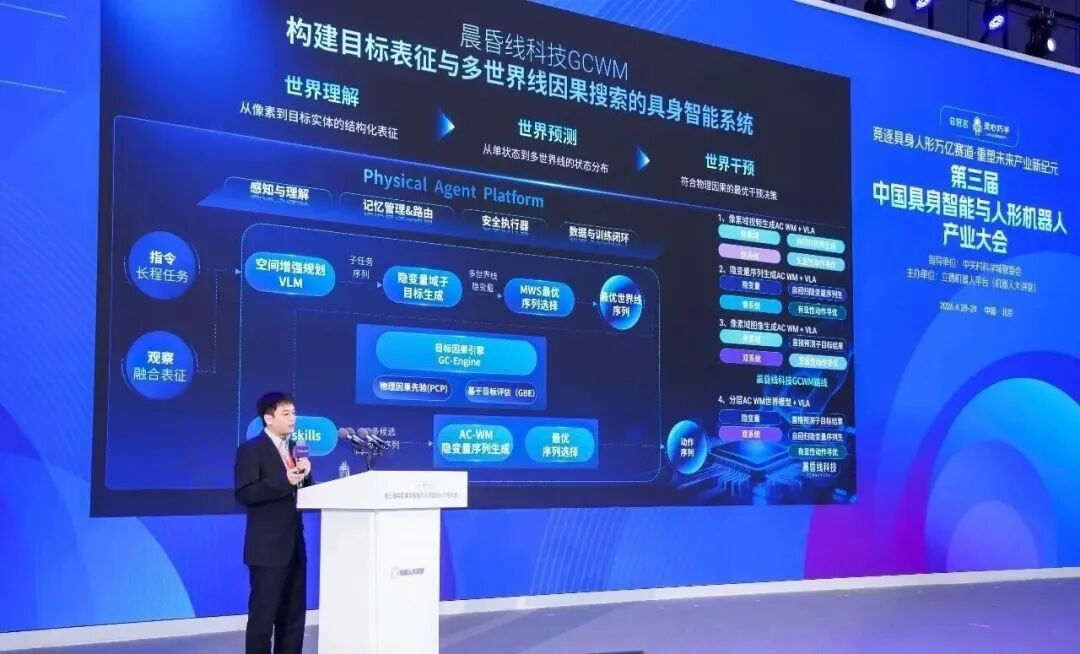
5月13日,晨昏线科技发布目标因果世界模型TermiBrain GCWM1,核心为“世界模型不应只是像素生成器,必须是物理因果引擎。”
该模型实现了从世界理解→世界预测→世界干预的完整闭环,在此基础上,GCWM1 进一步提出了“多世界线搜索”,从物理先验的底层约束和任务目标出发,在潜空间中并行生成与核心目标因果相关的关键世界线,每一条都清晰标注着“如果这样,就会那样”。
从“单状态决策”跨越到“多状态分布预测”,让机器人具备了成功率更高的预判能力。
地平线
小脑大模型HoloMotion-1
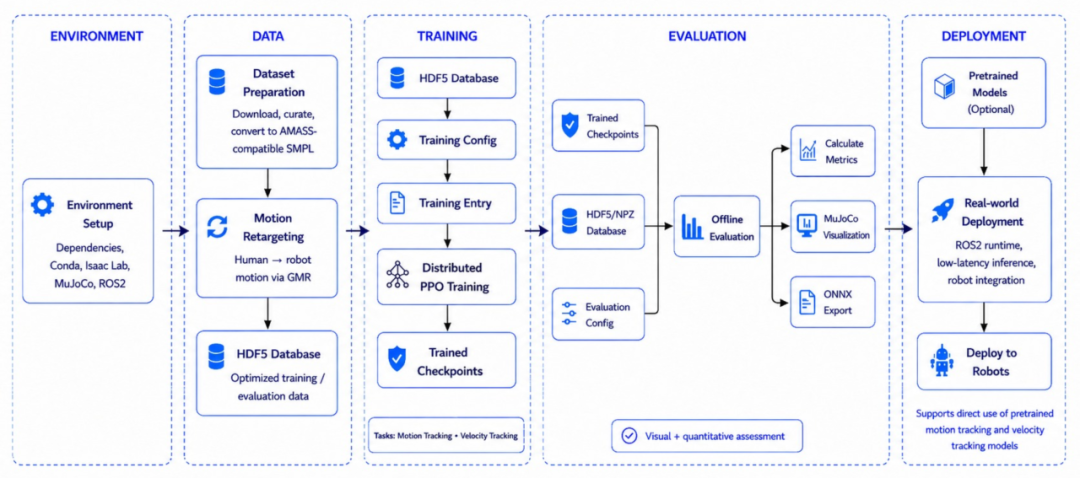
5月18日,地平线正式开源其机器人实验室面向人形机器人全身控制打造的4亿参数级机器人小脑大模型HoloMotion-1。
在模型架构上,HoloMotion-1采用MoE-Transformer policy。系统以参考动作和机器人本体观测为输入,通过reference-conditioned router进行稀疏专家路由,再由Transformer主干网络和action head输出机器人全身控制动作。
HoloMotion-1首先建立的能力是,Imitate Any Pose,即机器人运控领域中的通用motion tracking任务。也就是说,机器人不仅要会走路、站立或执行少量预设动作,还要能够从大规模开放动作数据中学习复杂全身姿态,并迁移到真实机器人上稳定执行。
智元
BFM-2
5月23日,智元发布了BFM-2,二阶段 Motion-Between 运控基座模型,一个能在任意状态下自主推理运动演化的“小脑”。
BFM-2 是全球首个引入端到端 DOF Feather Motion Generator 生成式训练机制的全身运动基座模型。
资料显示,运控基座模型,它背后对应着一个真实需求,当上层智能越来越强,机器人底层身体也必须变得更通用、更稳定、更可调用。
其一般由三层构成,上层是VLA,主管语义解析和任务调度;中层是运控基座,负责身体行为生成;底层是硬件系统,专司真实力矩与接触执行。
根据智元官方演示,搭载 BFM-2 的人形机器人被人为推倒后能自主调整肢体姿态,数秒内连贯起身并保持动态平衡;在不平整地面测试中也能主动调步态稳重心。
智澄AI
Chengling PWM 0.1
5月28日,智澄AI正式开源澄灵物理世界模型 0.1 版本(Chengling PWM 0.1),采用MIT 开源协议。
澄灵 PWM 同源于 Meta 联合嵌入预测架构(JEPA),与传统生成式世界模型不同,它直接从视觉、本体觉等原始感官输入中学习物理世界运行规律,通过观察机器人演示预测动作后果,让机器人在执行任务前完成 "心智模拟"。
本次开源的 0.1 版本聚焦核心架构与训练流水线,在 robomimic 多模态数据集上完成验证,可根据历史观察序列和自然语言指令,预测完整未来动作轨迹。
自变量
具身基础模型 WALL-OSS-0.5
5月28日,自变量机器人开源了其具身基础模型 WALL-OSS-0.5。
该预训练模型可以直接部署到自变量自研的机器人本体上,完成搬运、分拣、整理绳子等多种操作任务,甚至一些效果能够达到不少模型需要微调才能触及的水平。
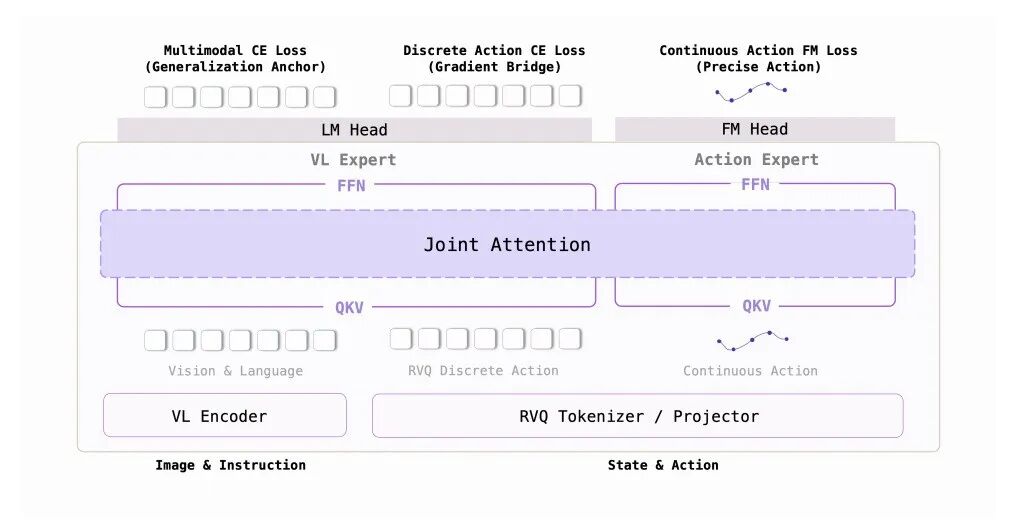
WALL-OSS-0.5 模型瞄准的核心命题是让 VLM 主干真正习得可泛化的动作能力。
WALL-OSS-0.5把动作 Token 化,然后塞进语言模型训练。
自变量提出了一个叫 Gradient-Bridge 的设计,因为过去的 VLA 是图像到主干,再到动作头,动作监督停留在 Action head。
经过 Gradient-Bridge 后,图像、文本、动作 Token 并到同一条自回归序列,使得动作也像语言一样,可以被预测。
模型用交叉熵损失去学习动作 token,并让梯度直接反向更新主干模型。
世界模型Wall-WM
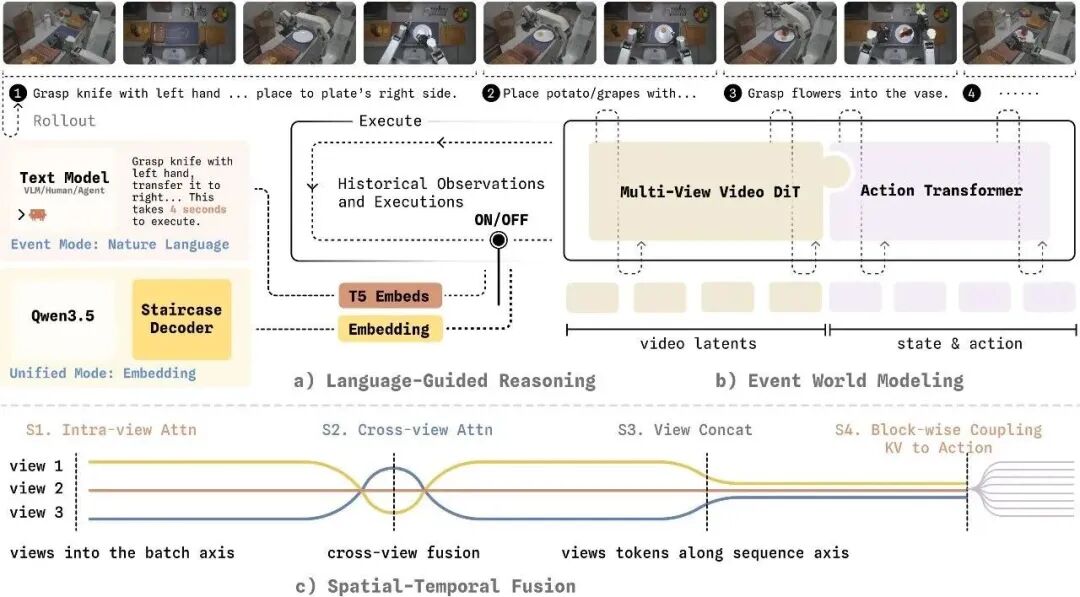
同月29日,自变量机器人推出首个具备事件级预测能力的世界模型Wall-WM。
模型传递过程中信息丢失的问题。自变量通过 Wall-WM 这一世界模型,先换掉大模型思考的时间单位,以“事件”为单位进行预测。
即模型只在世界发生重要变化时,才重新调整预测。
Wall-WM 可以实现同一套“大脑”,可以灵活适配不同场景。这源于其有两种模式。
一是事件模式,适合已经有上层规划器的场景,设置好指令后,机器人一次输出一个完整的动作单元;
二是统一模式,适合没有外部规划器、需要端到端实时控制的场景,模型独立完成推理和执行,保持固定的控制频率。
越疆
DobotWAM具身大模型
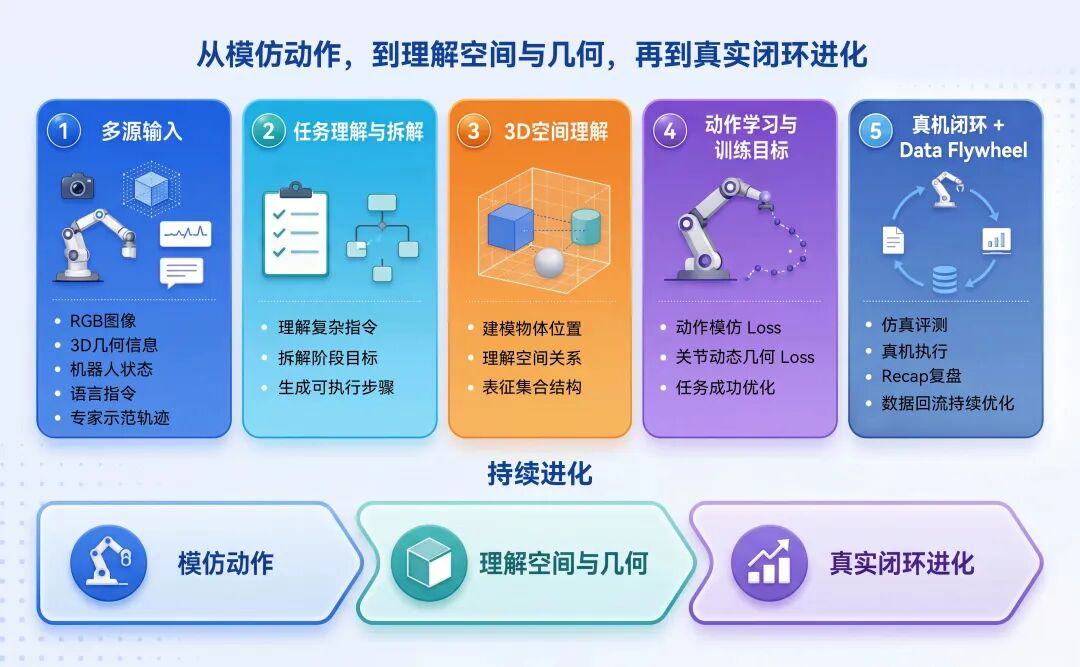
5月29日,越疆正式发布自研世界动作模型空弈DobotWAM具身大模型。
越疆空弈DobotWAM具身大模型的思路,是在视觉-语言-动作建模基础上,进一步引入三维空间理解、机器人运动几何约束和真实数据闭环机制,让模型不仅学会“模仿动作”,更学会“理解动作为什么这样做”。
眸深智能
STI-WM时空一体世界动作模型
5月31日,眸深智能正式推出STI-WM时空一体世界动作模型(Spatiotemporally Integrated World Model)。
STI-WM面向机器人长时序规划、在线闭环控制、真实物理交互,实现空间结构、时间演化、物理一致性、执行鲁棒性四维一体化统一。模型可兼容RGB图像、深度点云、机器人本体多模态感知输入,将复杂环境信息统一编码为紧凑高效的时空潜在世界状态,上层支撑百秒级长时程任务推演与全局轨迹规划,下层输出精准可控的精细化动作片段。
具身智能模型相关论文
浙江人形机器人创新中心&港中文大学&浙江大学
论文题目:A retrieval-augmented framework enabling VLM spatial awareness for object-centric robot manipulation
三维空间理解与操作模型RAM(Retrieval-Augmented Manipulation)
探索方向:用“知识检索”让机器人读懂三维世界

5月1日,由浙江人形机器人创新中心联合香港中文大学、浙江大学等多家高校与科研机构共同发表了机器人空间智能研究,提出名为RAM(Retrieval-Augmented Manipulation)的三维空间理解与操作模型,为提升机器人在复杂长程任务中的操作可靠性提供了新的技术路径。
RAM 借鉴检索增强生成(RAG)的思想,为大模型配备可查询的外部三维知识库。机器人执行任务时,模型可以按需检索物体类别、几何属性、功能平面、抓取点等空间先验信息,从而弥补视觉语言模型自身三维空间理解不足的问题。
与将知识隐含在模型参数中不同,RAM 的空间知识更加显式、可解释,也便于扩展。
OpenHelix Robotics&浙江大学&西湖大学
论文题目:VAMPO: Policy Optimization for Improving Visual Dynamics in Video Action Models
VAM强化学习后训练框架VAMPO
探索方向:视频动作模型落地机器人操控的瓶颈

5月18日,OpenHelix Robotics、浙江大学、西湖大学等团队联合发布了VAMPO。
该框架旨在消除“生成逼真度”与“操控精准度”之间的目标错位,使机器人的未来预测能力能服务于动作决策。
研究成果:
其一,为避免奖励投机(Reward Hacking)与长程信用分配失效,VAMPO首创欧拉混合采样器(Euler Hybrid Sampler),解决信用分配难题;
其二,采用GRPO(分组相对策略优化)算法,搭配潜空间一致性奖励(L1距离+余弦相似度),对齐专家动态。
北京人形机器人创新中心
论文题目:Pelican-Unify 1.0: A Unified Embodied Intelligence Model for Understanding, Reasoning, Imagination and Action
统一具身基础模型Pelican-Unified 1.0
探索方向:用单一模型把"看懂场景、推理任务、想象未来、执行动作"四个能力统一进同一个梯度回路,不再靠VLM、VLA、世界模型系统拼 PipeLine。

5月20日,北京人形发布首个统一具身基础模型Pelican-Unified 1.0。
Pelican-Unified 的架构包括两大组件:
组件一结合理解和推理,即统一 VLM,这个推理轨迹不是事后解释,是具身生成过程的中间表示,会被下游生成损失反向约束;
组件二结合想象和动作,即UFG 统一未来生成器,不用独立世界模型做视频预测、再用独立策略头做动作生成。
北京大学副教授穆亚东&北京大学&星源智团队
论文题目:Extending Embodied Question Answering from Perception to Decision
大规模数据集EQA-Decision、对应的RoboDecision训练框架
探索方向:具身问答从静态感知扩展到动态决策

EQA-Decision数据集拥有超过四百万个多模态问答对,数据来源横跨模拟环境、图像问答、第一人称视频和真实机器人轨迹四大类型。
RoboDecision训练框架有三个递进式训练阶段,分别是SFT(监督微调)、CoT-SFT(思维链监督微调)、GRPO(强化学习微调)。
为了实现GRPO阶段的最终目的,团队设计了一种混合奖励函数,包括推理奖励、答案奖励、视觉一致性奖励。
最具创新性的是视觉一致性奖励,它用OpenCLIP对齐生成的推理与视觉观察,确保模型的思考内容真正反映画面中的视觉证据,而非靠文本先验“瞎猜”。
Genesis AI
论文题目:The Role of Simulation in Scalable Robotics, Genesis World 1.0, and the Path Forward
Genesis World 1.0
探索方向:让仿真系统具备闭环评估能力。
5月28日,Genesis AI 发布 Genesis World 1.0,针对模型开发周期本身慢的问题,将仿真不仅仅是"数据生成器",更可以是机器人基础模型的评估与迭代引擎。
在现阶段,Genesis AI的目标是在不让任何仿真数据参与预训练的前提下,让仿真和真实世界之间建立强相关性。
其认为,当训练和评估共享同一份仿真分布时,模型表现的提升既可能反映"模型/数据配方真的更好了",也可能只是"对仿真器动力学拟合得更紧了"。
让两条管线保持解耦,才能拿到一个更干净的信号:判断哪些实验是真正在改进模型表现。
北京大学副教授穆亚东&星源智团队
论文题目:RoboAgent: Chaining Basic Capabilities for Embodied Task Planning
RoboAgent方案
探索方向:机器人系统所面对的探索、定位、状态理解、动作解码和失败恢复等流程。
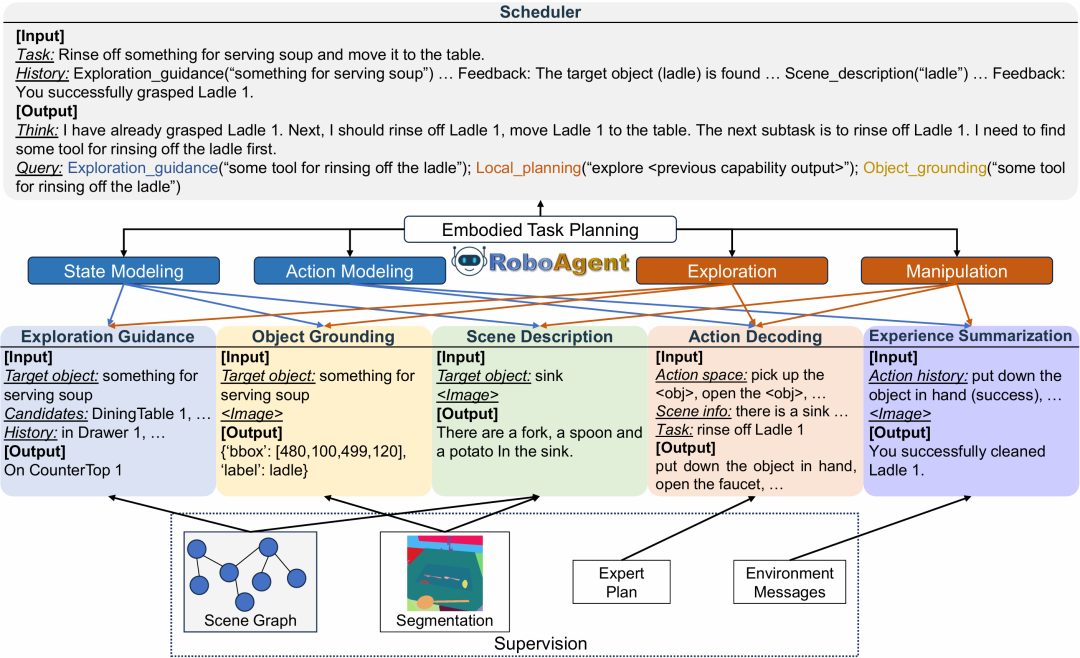
针对VLM没办法进行具身路径规划这一问题,北京大学副教授穆亚东联合星源智团队提出RoboAgent方案。
它把具身路径规划拆成一系列更小的、VLM本来就擅长的视觉-语言子问题,类似在一个 scheduler 添加了EG(探索引导)、OG(物体定位)、SD(场景描述)、AD(动作解码)、ES(经验总结)5类能力。
一个值得注意的地方是,RoboAgent 没有把这些能力做成多个外部工具,也没有依赖封闭模型或独立模块拼接。Scheduler 和所有能力都由同一个 VLM 实现。模型只是通过不同 prompt、不同上下文和不同输入输出格式,在统一框架内扮演不同能力角色。