点击下方卡片,关注【Xbotics具身智能实验室】公众号
更多具身干货,欢迎加入(戳我)
👉具身智能学习资料汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-Guide
👉具身智能求职/实习信息汇总:https://github.com/Xbotics-Embodied-AI-club/Xbotics-Embodied-AI-Job
你想要的这里都有~~
过去一年,圈子里最热闹的是模型。OpenVLA、π0、GR00T,每隔一段时间就有人放出新结果,大家追着问成功率、泛化能力、真机视频。
但跟一线做训练的朋友聊久了,会发现一个更朴素的问题卡在所有人喉咙里:
模型再强,数据从哪里来?
任务怎么批量生成?环境怎么系统变化?双臂协作怎么评?厨房、桌面、柔性物体这些真实世界的麻烦,怎么被放进训练和评测体系?
这才是具身智能现在真正开始卷 Infra 的原因。
如果说 VLA 是机器人的大脑,那数据生成和任务评测 Infra 就是机器人训练的健身房。没有足够丰富的训练场,再聪明的大脑也只能在几个精心布置的 demo 里转圈。一旦换物体、换光照、换桌面高度、换任务顺序,系统马上露馅。
这篇文章选三个同类型项目:RoboTwin 2.0、RoboCasa365 和 MimicGen 系列。它们不是模型,它们在回答同一个问题:机器人学习到底怎么规模化?
为什么机器人数据比图文数据难太多?
先讲一个很基础的对比。
大语言模型成功,很大程度上靠互联网文本。视觉语言模型可以继续吃图文对、视频、网页。但机器人不一样。
机器人数据不是“图片加文字”。它是多相机图像、深度、关节角、末端位姿、夹爪状态、力觉触觉、动作序列、语言指令、时间戳,有时还要环境状态和成功标记。
更关键的是,机器人数据不能只看,必须能做。一张猫的图片不需要猫真的回应你。但一条机器人轨迹,必须对应一个可执行的动作过程。抓杯子就是抓杯子,插积木就是插积木。动作偏一点,任务失败;环境变一点,旧数据可能就废了。
所以机器人学习有一个天然死结:真实数据贵,仿真数据容易假,评测标准难统一。
RoboTwin 2.0、RoboCasa365 和 MimicGen 系列,正是在这个死结上发力。它们不追求“提出一个更大的模型”,而是把数据、任务、环境和评测变成可规模化生产的系统。
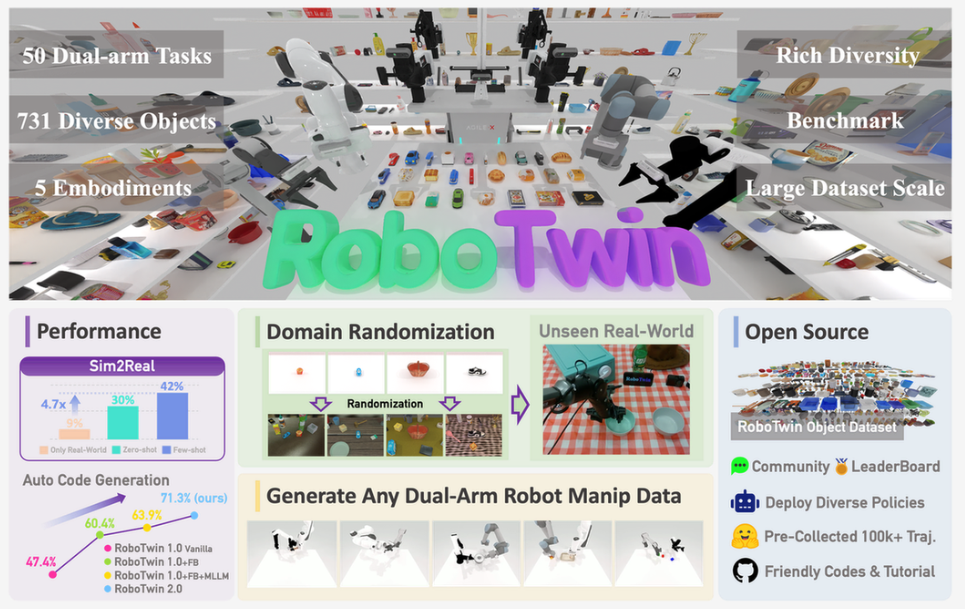
RoboTwin 2.0:双臂机器人的“标准化训练场”
先看 RoboTwin 2.0。这个项目最鲜明的标签是双臂操作。
今天很多 VLA demo 还是单臂机械臂:抓一个物体,移动到目标,放下。这类任务当然重要,但离真实的人形和双臂机器人还有一大段距离。人在做家务、装配、整理时,大量动作不是单手完成的。一只手固定,一只手操作;一只手递送,一只手接收;两只手同时拉、推、撑、拧。
双臂操作的难点在哪?在协调。单臂只需要管一个末端和物体的关系,双臂还要管两只手之间的时序、相对位置、角色分工和碰撞约束。一只手拿住盒子,另一只手放东西进去;一只手扶住容器,另一只手倒东西。关键不是“会抓”,而是“会配合”。
RoboTwin 2.0 的价值,就是把双臂操作做成一个可生成、可评测、可扩展的基础设施。它不是只给几个任务,而是围绕双臂 manipulation 搭了一个完整框架:物体库、任务生成、专家数据合成、domain randomization、统一评测协议。
里面很值得注意的一点,是它开始把 MLLM 放进任务生成流程。过去机器人任务要人工写代码、写脚本、写 reward、写专家策略。RoboTwin 2.0 试图让多模态语言模型自动生成任务级执行代码,再通过 simulation-in-the-loop 做修正。
这件事的含义很深。因为未来具身智能不可能靠人工一个个写任务。如果每个新任务都要工程师手动建模、写脚本、调参数,规模永远上不去。真正可扩展的路线,是让系统自己提出任务、生成数据、检查结果、纳入评测体系。机器人数据生成正在从“人工搭任务”走向“模型辅助造任务”。
还有一个很工程化的设计:domain randomization。它不是只随机换个物体,而是从杂乱程度、光照、背景、桌面高度、语言指令等多个维度去做环境扰动。
这点太现实了。机器人在实验室失败,很多时候不是完全不会任务,而是环境稍微变了:桌子高一点、灯暗一点、背景乱一点、指令换种说法、物体摆偏一点。人类觉得没区别,但对策略来说,这就是分布外。
所以 RoboTwin 2.0 代表的趋势是:机器人 benchmark 不能只问“会不会做这个任务”,还得问“环境变了之后还能不能做”。
对人形和双臂机器人来说,这类系统尤其重要。未来人形上肢训练,不可能只靠少量真机采集,也不可能只在固定桌面任务上刷分。双臂协作需要更大规模、更强随机性、更接近真实的训练和评测环境。RoboTwin 2.0 在尝试把双臂操作从“少数 demo”推进到“系统化训练场”。
RoboCasa365:家庭机器人需要的不是抓取,是日常生活
如果说 RoboTwin 2.0 更偏双臂操作,那 RoboCasa365 更偏家庭场景。这个方向很容易被低估。
很多人讲机器人操作喜欢从桌面抓取开始,因为任务清楚、物体有限、评测简单。但真正的家庭服务机器人不会只站在一张干净桌子前抓积木。家庭场景里有柜子、抽屉、冰箱、台面、水槽、微波炉、杯子、盘子、锅、瓶子、垃圾。任务也不是简单 pick-and-place,而是“从柜子里拿杯子”“放进微波炉”“整理台面”“准备咖啡”“清理餐具”这类长程、组合、多步骤操作。
这就是 RoboCasa365 的意义。 它把家庭厨房作为核心场景,扩展到 365 个日常任务和 2500 个厨房环境。这个规模的意义不是数字大,而是让家庭机器人有机会在更丰富的布局、风格、物体和任务组合里接受训练和评测。
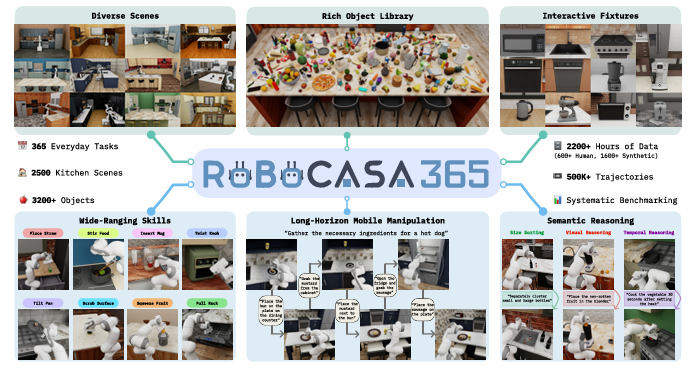
家庭任务最大的难点是变化太多。不同家庭的厨房布局不一样,柜子位置不一样,电器不一样,摆放习惯不一样。机器人如果只在一个固定厨房里训练,很容易学到场景偏见。一换厨房,视觉先崩,路径再崩,任务顺序跟着崩。
RoboCasa365 的核心价值,就是把这种“家庭差异”系统性地放进仿真环境里。它不是做一个漂亮厨房,而是提供大量不同布局、风格、家具和物体组合的厨房场景,让模型不再只适应一个标准实验室。
这对 foundation model training 非常关键。过去很多机器人策略是任务专用的:训一个任务,评一个任务。但家庭机器人需要多任务能力和持续学习能力。RoboCasa365 这类 benchmark 把“日常任务”变成了可以系统训练和比较的集合。
它还让一个问题更清楚地暴露出来:家庭机器人离真正可用还差什么?
短任务不错、长程崩盘,说明缺任务规划。一个厨房成功、换布局失败,说明场景泛化不够。基础技能能完成、组合不起来,说明没有稳定的多步骤执行能力。物体轻微变化就失败,说明视觉和动作绑定不够鲁棒。
这些问题,只有在大规模、多场景、多任务的评测系统里才会被逼出来。从这个意义上说,RoboCasa365 不只是一个仿真环境,而是一个家庭机器人能力的“压力测试系统”。
MimicGen:少量示范,变成海量训练数据
第三个项目是 MimicGen 系列。它解决的是更核心的问题:机器人示范太贵了。
模仿学习需要 demonstration。问题是,高质量人类示范并不好采。要设备、要遥操作系统、要任务设计、要采集人员,还要保证轨迹质量。单臂已经不便宜,到了双臂、灵巧手、人形,成本只会更高。
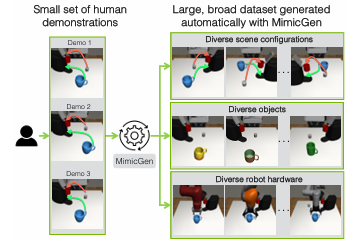
MimicGen 的思路很直接:能不能从少量人类示范出发,自动合成更多?
原版 MimicGen 证明了一件事:少量人工示范不一定只能一条条拿来训练。它们可以被系统拆解、迁移、重组,生成大量新场景下的轨迹。项目中从约 200 条人类示范生成五万多条 demonstrations,覆盖多个任务、场景配置、物体实例和机器人本体。
这背后的思想很朴素,但很有力量:人类只提供“种子”,系统负责扩增。
过去要更多数据,就继续找人采。MimicGen 把人类示范变成可复用资产:一条示范不只是一个样本,而是一个可以迁移到新初始状态、新物体、新布局的动作模板。它特别适合长程、高精度但结构相对清楚的 manipulation 任务,比如装配、咖啡制作、多步骤操作。人类先给少量成功轨迹,系统再在不同场景里自动生成大量变体。
更重要的是,MimicGen 后面形成了一个系列。
DexMimicGen 把这个思路扩展到双臂灵巧操作。双臂加灵巧手的数据采集难度更高,因为控制自由度多、同步要求高、失败点多。它从少量源示范出发,生成双臂灵巧机器人的大规模 demonstrations。
SoftMimicGen 进一步推进到柔性物体操作。毛巾、绳子、纸巾、布料,这些物体形变复杂、状态难表示、仿真更难。过去合成数据更集中在刚体任务,因为刚体好模拟、好检测、好评估。SoftMimicGen 的出现说明,数据生成 Infra 正在进入更真实也更麻烦的操作场景。
从原版到 DexMimicGen 再到 SoftMimicGen,一条很清楚的演化线:先解决单臂刚体扩增,再解决双臂灵巧扩增,最后进入柔性物体和更复杂本体。
这条线非常值得关注。因为真实世界不是刚体积木世界。机器人未来要整理衣物、处理包装、拿软袋、操作线缆,就必须面对柔性物体、多接触和复杂形变。MimicGen 系列不取代真实数据,但能极大提高真实示范的利用率。
结语:Infra 不是在后台,是在定义前台能力
很多人一听 Infra,觉得是后台工程,不如模型和算法性感。但在具身智能里,Infra 往往直接决定模型的上限。
没有 RoboTwin 这样的双臂训练场,人形上肢很难系统学习协作操作。没有 RoboCasa365 这样的家庭场景 benchmark,家庭机器人很难知道自己离真实日常任务还有多远。没有 MimicGen 这样的数据生成系统,机器人示范数据的规模化会长期被成本卡住。
这些项目看起来是在做数据、任务、环境和 benchmark,实际上是在定义未来机器人模型可以学什么、比较什么、改进什么。
VLA 让机器人看到一条通向通用操作的路。但要把这条路走通,光有模型还不够。还需要足够大的训练场,足够真实的任务集,足够高效的数据生成系统。
具身智能的下一场竞争,可能不会发生在一个更大的模型名字里,而会发生在这些看似基础、却决定一切的训练基础设施里。
-END-
Ask Me Anything|提问箱
❝对文章有疑惑,或想聊更深?欢迎把你的问题丢给我们:技术方案、实操踩坑、课程与资料、项目合作、职业发展,都可以问。
怎么问:在评论区留言,或私信公众号
我们会做什么:每周集中整理高质量问题并公开回复,重点问题邀请作者或嘉宾深度解答;典型问题会加入知识库并持续更新。
提问小提示:尽量说明「你的目标—当前做法—期望产出」,附上必要信息(硬件/软件版本、数据规模等),能更快获得有用答案。
一起把问题变成知识,推动社区进步 🚀