点击蓝字 关注我们

欢迎各位专家学者在公众号平台报道最新研究工作,荐稿请联系小编Robert(微信ID:BrainX007); 或将稿件发送至lgl010@vip.163.com。
原文标题:Achieving more human brain-like vision via human EEG representational alignment

成果简介
当前人工智能视觉模型已经在目标识别任务上取得了很高的性能,深度卷积神经网络甚至可以在许多图像分类任务中接近或超过人类水平。然而,一个关键问题仍然存在:模型“认对了”,并不代表它“像人一样理解”。人类视觉系统并不是简单地把图像映射到类别标签,而是在几十到几百毫秒内经历从低级视觉特征到高级语义表征的动态加工过程。相比之下,传统视觉模型虽然分类准确率很高,但其内部表征与人脑视觉加工过程仍存在明显差距。过去,研究者尝试利用神经数据来约束人工神经网络,使模型更接近生物视觉系统。但这类研究往往存在两个限制:第一,许多工作依赖动物的侵入式神经记录,例如小鼠或猴子的 V1、IT 区信号,难以直接代表人类视觉加工;第二,很多方法只对齐单一脑区或单一模型层,无法充分模拟人脑视觉系统的层级加工机制。针对这些问题,Lu、Wang 和 Golomb 等研究者提出了 ReAlnet框架,首次利用非侵入式人类 EEG 信号,直接对视觉模型的多层内部表征进行脑表征对齐。不是让 EEG 去辅助分类,而是让视觉模型在完成图像识别的同时,学习生成与真实人脑 EEG 相似的神经反应,从而把模型内部表征训练得更像人脑。
主要贡献
提出基于 EEG 的多层脑表征对齐框架:该研究不是简单地把 EEG 信号作为额外输入,也不是只在模型输出层加入脑信号约束,而是在视觉模型多个层级上加入 EEG 编码模块,使模型在不同视觉层级上同时学习人脑表征。
从“提高分类准确率”转向“优化内部表征”:传统视觉模型优化目标通常是分类准确率,即图像输入后预测类别是否正确。但本文关注的不是模型是否会分类,而是模型的内部表征是否更接近人脑
研究方法
ReAlnet 的整体框架可以理解为一个“图像到大脑”的多层编码模型。输入是一张自然图像,模型一方面输出图像类别,另一方面生成对应的人类 EEG 反应。
(1)基础模型:从 CORnet-S 到 ReAlnet
研究团队选择 CORnet-S 作为基础视觉模型。CORnet-S 是一种具有生物启发结构的卷积神经网络,其层级结构与人类腹侧视觉通路具有一定对应关系,例如 V1、V2、V4 和 IT。在原始 CORnet-S 中,图像经过多个视觉层级后进入分类器,输出物体类别。而在 ReAlnet 中,作者在多个视觉层级后加入 EEG 编码模块,使模型可以根据不同层级的视觉特征预测 EEG 信号。也就是说,ReAlnet 不再只是一个“图像分类器”,能够同时完成两件事的模型:预测图像类别和预测人类看到该图像时的大脑 EEG 反应。
(2)多层 EEG 编码模块:让不同视觉层共同预测脑活动
ReAlnet 的关键创新在于多层对齐。作者并没有只选取模型最后一层与 EEG 对齐,而是从多个视觉层级提取特征,再通过多层视觉编码器和 EEG 编码器生成预测 EEG。这种设计的意义在于,人脑视觉加工本身是层级化的:早期视觉皮层更关注颜色、边缘、大小等低级特征,较晚阶段则更关注物体类别、真实世界大小、生命性等高级语义信息。因此,多层对齐比单层对齐更符合人脑视觉加工逻辑。
(3)联合训练目标:分类损失 + EEG 生成损失
训练过程中,ReAlnet 同时优化两个目标。第一个目标是图像分类损失,用于保持模型的物体识别能力。这样可以避免模型为了拟合 EEG 而牺牲基本视觉识别能力。第二个目标是 EEG 生成损失,用于让模型生成的 EEG 信号接近真实 EEG。该损失包括重建误差和对比学习损失。重建误差帮助模型学习图像对应的神经响应,对比学习损失则帮助模型学习更稳定、更可泛化的神经表征结构。简单来说,分类损失保证模型“看得准”,EEG 生成损失则推动模型“看得像人脑”。
(4)评估方法:用 RSA 衡量模型是否更像人脑
为了判断 ReAlnet 是否真的更接近人脑,作者采用了表征相似性分析,即 RSA。其基本思路是:如果两个系统对同一组图像形成的内部表征结构相似,那么它们对图像之间关系的理解也应当相似。例如,人脑认为某两张图像更相似,模型也认为它们更相似,那么说明模型表征更接近人脑。研究团队分别比较了 ReAlnet、原始 CORnet、ResNet101 和 CLIP 等模型与人类 EEG、fMRI 以及行为数据之间的表征相似性。

图1:ReAlnets与人类脑电图信号的对齐情况,展示更多类人脑视觉模型。A ReAlnet对齐框架示意图,B 模型内部表征与things EEG2测试数据集中人类时序脑电图信号之间的表征相似性。
研究结果

图 2:ReAlnets模型与人类脑电图及层级化个体差异性表现出更高的相似性。A图分别展示了不同层级中人类脑电图与各模型(ReAlnets、随机化模型及CORnet)之间的表征相似性时间变化曲线。底部深蓝色方点表示ReAlnets与CORnet在显著差异的时间点(p < 0.05);底部灰色方点表示ReAlnets与随机化模型在显著差异的时间点(p < 0.05)。线条及阴影表示均值±标准误(SEM)。B图显示了ReAlnets模型相较于CORnet在相似性峰值时刻的相似性提升幅度及其提升比率;每个圆点代表一个独立的ReAlnets模型,误差线表示±SEM。C图展示了人类脑电图与各模型(ReAlnets、随机化模型及CORnet)之间最大表征相似性的时间变化曲线(该值通过计算各时间点所有模型层级中的最高相似度得出);底部深蓝色方点表示ReAlnets显著优于CORnet的时间点(p < 0.05),灰色方点表示ReAlnets与随机化模型间的显著差异(p < 0.05);线条及阴影表示均值±SEM。D图:上图展示四个视觉层级的ReAlnets个体变异矩阵;左下图显示各层级层面的ReAlnets个体变异;右下图展示人类功能磁共振成像(fMRI)数据在视觉皮层层面的个体变异;每个圆点代表一对个性化ReAlnets模型或两名受试者;误差线表示±SEM。E 交叉受试者相似性矩阵展示了每个个体化的ReAlnet模型(行)对所有10名受试者的脑电图表征(列)的泛化效果。每个单元格反映了人类脑电图与ReAlnet及CORnet模型在四个模型层级及50–200毫秒时间窗口内的平均表征相似度。F 超越基线CORnet的跨受试者泛化效果:每个单元格表示ReAlnet与CORnet在脑电图相似度上的差异,正值表明即使不匹配的ReAlnet模型在其他受试者的脑电数据上仍优于CORnet。G 左图:基于基线扣除后的相似性矩阵构建的列归一化相似性矩阵,各列数值按最高相似度值为1进行标准化;右图:匹配组与非匹配组间的统计学比较,黑色星号表示匹配组的相似度显著高于非匹配组(p < 0.05)。误差条表示±标准误。
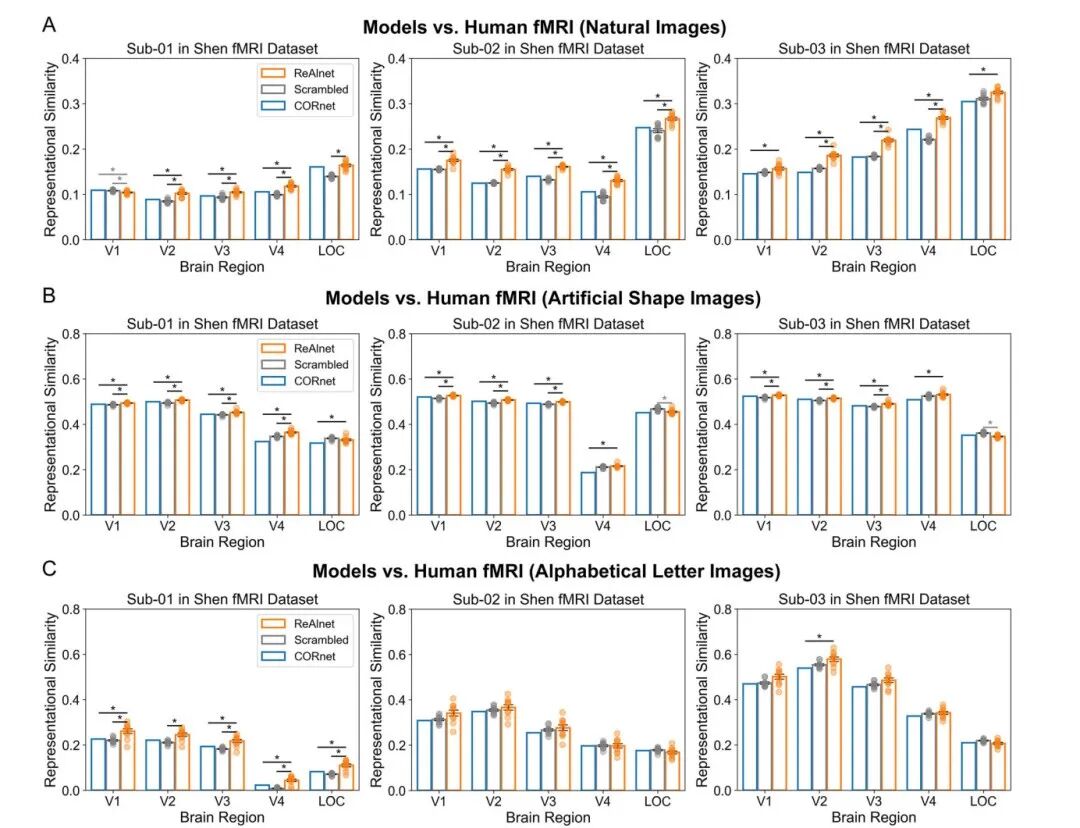
图3:ReAlnets模型与人类功能性磁共振成像(fMRI)表征具有更高的相似性。当Shen fMRI测试数据集中的三名受试者分别观看A类自然图像、B类人工形状图像及C类字母图像时,各模型与五个不同脑区的人类fMRI表征之间的表征相似度如图所示。黑色星号表示ReAlnets模型的相似度显著高于Scrambled模型或CORnet模型(p < 0.05);灰色星号则表明其相似度显著低于上述模型(p < 0.05)。所有两两比较均采用Bonferroni法进行多重比较校正。每个圆点代表一个独立的ReAlnets模型或Scrambled模型。误差线表示±标准误(SEM)。

图4:ReAlnets中的行为相似性与特征表征增强效果。基于Brain-Score平台评估,ReAlnets模型与人类行为表现出更高的相似性:每个橙色圆点代表一个独立的ReAlnet模型,每个灰色圆点代表一个独立的Scrambled模型;星号表示ReAlnets模型与CORnet或Scrambled模型之间的相似性显著更高(p < 0.05)。B左图:ReAlnets、Scrambled模型及ReAlnets β =0模型相较于CORnet的前五项增强特征表征;右图:ReAlnets和Scrambled模型相较于ReAlnets β =0模型的前五项增强特征表征。每个橙色圆点代表一个独立的ReAlnet模型,每个灰色圆点代表一个独立的Scrambled模型;误差线表示±标准误(SEM)。

图4:fMRI体素探照灯RDM与基于视听视频刺激的预训练双分支深度神经网络(DNN)的比较。DNN模型的示意图训练于视听视频刺激Audioset有两个独立分支分别接收视频帧和音频频谱图。两个分支的输出通过对比学习框架被训练为匹配同一视频,并排斥不同视频。在每个模型分支的不同区块提取实验视频刺激的模型激活,利用刺激两对皮尔逊距离度量创建RDM,总共获得14个RDM以捕捉每个模型分支的七个层级结构。b 每个模型层RDMs之间的Spearman相关值。仅显示显著相关性(1万次配对置换检验,FDR校正后p< 0.01)。c 在将每个DNN层RDM与每个体素RDM关联后,绘制了大脑中相关度最高的层。颜色表示模型中相关性最高的层(经过1000次随机化的簇校正单侧符号置换检验,簇定义阈值p < 0.001,簇阈值p < 0.01)。
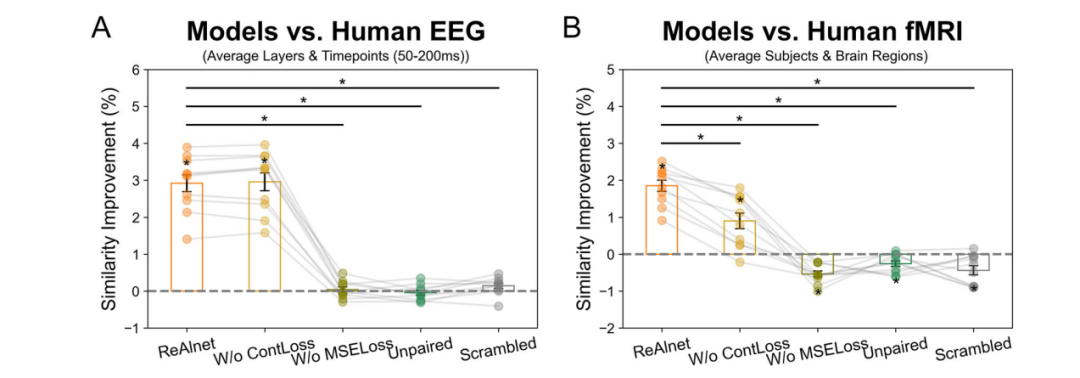
图5:对照实验结果。A. ReAlnets模型与对照模型相较于CORnet在人类脑电图(EEG)相似性方面的提升;B. ReAlnets模型与对照模型相较于CORnet在人类功能磁共振成像(fMRI)相似性方面的提升。每个圆点代表一个独立模型,星号表示统计显著性(p < 0.05),误差线表示±标准误(SEM)。

图6: ReAlnet-Rs模型中的类似改进。A 分别展示第1、5、9、13和17层人类脑电图与各模型(ReAlnet-Rs及ResNet)之间的表征相似性时间变化曲线。底部黑色方点标示ReAlnet-Rs与ResNet在显著差异的时间点(p < 0.05);线条及阴影表示均值±标准误。B 通过计算各时间点所有模型层中最高相似度,得出人类脑电图与不同模型(ReAlnet-Rs及ResNet)之间最大表征相似性的变化趋势;底部黑色方点标示ReAlnet-Rs显著优于ResNet的时间点(p < 0.05);线条及阴影表示均值±标准误。C ReAlnet-R模型在第1、5、9、13和17层的个体变异矩阵及其层间个体变异情况;每个圆点代表一对个性化ReAlnet模型。D 基于Brain-Score平台分析五个不同脑区在受试者2观看自然图像、人工形状图像及字母图像时,模型与人类功能磁共振成像数据间的表征相似性:黑色星号表示ReAlnet-Rs的相似度显著高于ResNet(p < 0.05),灰色星号表示其相似度显著低于ResNet(p < 0.05);每个圆点代表单个ReAlnet-R模型;误差线表示±标准误。E 基于Brain-Score平台分析模型与人类行为的相似性;每个圆点代表单个ReAlnet-R模型;误差线表示±标准误。
研究结论
本文提出的 ReAlnet 框架通过非侵入式人类 EEG 信号,对视觉模型的多层内部表征进行直接对齐,使模型在保持图像识别能力的同时,表现出更强的人脑相似性。实验结果表明,ReAlnet 在 EEG 表征、fMRI 表征和人类行为三个层面均优于传统视觉模型。它不仅能够学习人类视觉加工的时间动态特征,还能在未见过的新图像类别和不同神经成像模态上保持泛化能力。这项研究的重要意义在于,它证明了非侵入式 EEG 并不只是用于解码人脑状态的信号来源,也可以反过来作为训练人工智能模型的神经监督信号,帮助模型形成更接近人脑的内部表征。未来,类似 ReAlnet 的脑表征对齐框架可以进一步扩展到更多模型结构、更大规模视觉数据、更复杂的多模态任务,甚至可以与 fMRI、MEG、行为数据共同训练,构建更加接近人类感知系统的人工智能模型。总体来看,ReAlnet 为“脑启发 AI”提供了一条清晰路径:不是简单模仿大脑结构,而是直接让模型学习人脑表征。这也意味着,未来的人工智能视觉系统可能不只是“看得准”,还要“看得像人”。
免责声明:原创仅代表原创编译,水平有限,仅供学术交流,如有侵权,请联系删除,文献解读如有疏漏之处,我们深表歉意。



公众号丨智能传感与脑机接口