点击下方卡片,关注“具身智能之心”公众号
作者丨Weifeng Lin 等
本文只做学术分享,如有侵权,联系删文
>>
更多干货,欢迎加入国内首个具身智能全栈学习社区:(戳我),这里包含所有你想要的。
现在很多VLA模型,都会先采用一个会看图、会理解语言的 VLM 当“大脑底座”,再接上动作模块,让它学会动作控制。
但一个关键问题却还没被深入研究:这个 VLM 底座里,到底哪些能力对机器人有用?如果要把它改造成 VLA,是应该大刀阔斧地重训,还是尽量保住原来的能力?
来自CUHK和 ACE Robotics 的团队,对这个问题做了一组系统实验。结论很直接:VLM 原本的能力很重要,初始化 VLA 时,改得越狠,往往越容易把有用的东西改坏。
标题:Rethinking VLM Representation for VLA Initialization 作者:Weifeng Lin, Siyuan Huang, Hao Li, Tingwei Chen, Ruichuan An, Xinyu Wei, Jianbo Liu, Hongsheng Li 机构:香港中文大学、香港理工大学、北京大学、ACE Robotics 论文:https://arxiv.org/pdf/2605.25802 代码:https://github.com/AFeng-x/Rethink_VLA_Initialization
先说结论
好的 VLA 初始化,不是把 VLM 彻底改造成具身相关的专用感知模型,而是在保住原有能力的基础上,精准补进和动作相关的新能力。
这篇论文给出的经验可以概括成五点:
预训练 VLM 的“通用表征”很值钱,不能轻易丢掉。 给 VLM 补具身能力有用,但要对症下药,不是补得越多越好。 LoRA 这种轻量改造方式,比全量微调更稳。 底座模型越强,保留原始表征的价值越大。 机器人数据也有帮助,但最好分阶段注入,而不是所有信号特征一起硬塞。
为什么这个问题重要?
现在VLA主流做法是先拿一个预训练好的 VLM,比如 Qwen3VL, PaliGemma2等作为 VLA 的 backbone。然后再接一个动作输出模块,让模型从机器人数据里学习如何执行任务。
但问题是:
VLM 会看图说话,不代表它天然会控制机器人。
那它原来的能力到底有多少能有效迁移到机器人控制?是否必须要训练它更好地理解空间、定位、第一视角、任务规划?训练时是全模型都改,还是只加一点适配参数?
过去很多工作默认“用更强的 VLM 当底座”或者“多加具身相关的感知数据”。这篇论文则把问题拆得更细:到底什么样的 VLM 表征,才适合拿来初始化 VLA?
研究怎么做:把 VLA 初始化拆成三个问题
作者没有只比较几个模型分数,而是把 VLA 初始化当成一个“表征设计问题”来研究。

具体来说,他们围绕三个问题做对照实验。
第一,给 VLM 补什么能力?
论文把具身相关的 VQA 数据分成 7 类能力:
空间关系:比如物体在左边还是右边、远还是近。 目标定位:比如“我要拿这个杯子”,模型能不能找到目标位置。 规划推理:比如先做哪一步、后做哪一步。 相机预测:比如相机视角和参数。 第一视角理解:比如手、夹爪、可触达物体在哪里。 时序理解:比如视频里动作发生的顺序。 动作预测:把机器人动作当成 token,让模型预测下一步动作。
第二,改造 VLM 时改多狠?
作者比较了两种常见方式:
Full Finetune:全量微调,把整个模型参数都更新。 LoRA:只训练很小一部分适配参数,尽量保留原模型。
第三,要不要加入机器人数据预训练?
除了用 VQA 数据补能力,作者还测试了用 AgiBot-World-Beta 这类机器人轨迹数据继续预训练,看它能不能带来更好的 VLA 初始化。
为了让结论更可靠,实验覆盖了不同底座模型、不同动作头(MLP Head和Diffusion Expert),和不同任务平台,包括 Libero-10、SimplerBridge 和 RoboCasa GR1 Tabletop。
发现一:从零开始训,性能直接掉一大截
最基础的问题是:预训练 VLM 到底有没有用?
答案很明确:非常有用。
如果不用预训练 VLM,而是从零开始训练,三个平台上的成功率都会明显下降。
比如在 MLP action head 设置下:
Libero-10:从 92.4 掉到 66.6。 SimplerBridge:从 45.8 掉到 19.4。 RoboCasa:从 49.5 掉到 20.3。
这说明 VLM 原本学到的视觉和语言表征,并不是一个可有可无的起点。它里面确实保留了对机器人动作学习有帮助的通用信息。
换句话说,VLM 不只是“拿来凑一个 backbone”。它原来的知识,是 VLA 能学好的重要基础。
发现二:补课有用,但不能乱补
一个很自然的想法是:既然 VLM 要变成机器人模型,那就多给它补一些具身能力,比如空间理解、目标定位、规划推理。
但实验结果并不支持“补得越多越好”。
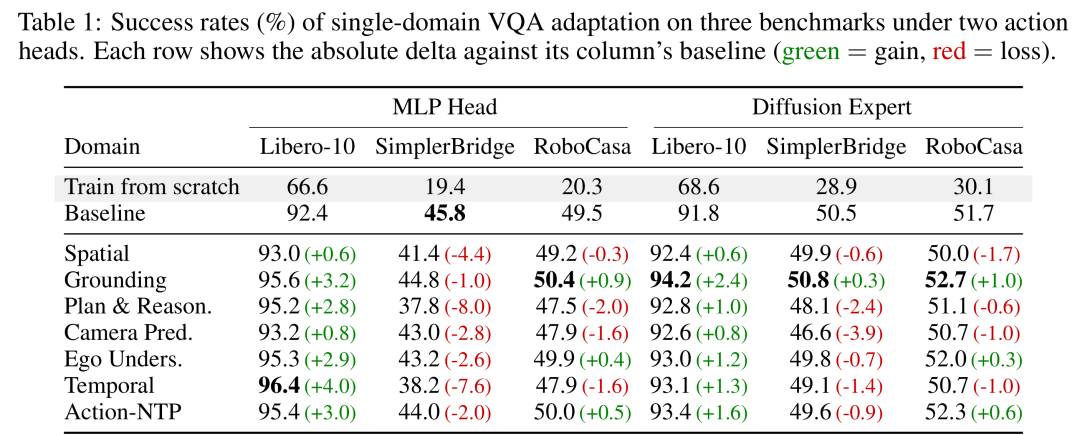
结果可以分成两层看。
第一层:同一种能力,在不同任务上效果不一样。
在 Libero-10 上,大多数能力注入都有帮助。比如 Temporal 在 MLP head 下能从 92.4 提到 96.4,Grounding 也能提到 95.6。
但到了 SimplerBridge,很多能力反而带来下降。也就是说,某种能力有没有用,要看下游任务真正卡在哪里。
第二层:不同能力之间不是简单相加。
论文发现,Grounding 和 Egocentric Understanding 是比较稳定的两类能力。前者帮助模型找准目标,后者帮助模型理解第一视角里的手、夹爪和可操作物体。
这两类能力组合起来时,效果最好。在 RoboCasa 的 Diffusion Expert 设置下,Grounding + Ego 能达到 53.5,比单独 Grounding 的 52.7 和单独 Ego 的 52.0 都更高。
但如果把更多能力继续堆进去,效果反而会下降。7-domain mix 并没有带来最强结果。
这里的启发很清楚:
给 VLM 补具身能力,要像看病开药一样,对症下药。不是药越多越好,关键是补到任务真正需要的地方。
发现三:LoRA 比全量微调更适合做初始化
这篇论文最重要的结论之一,是关于“怎么改 VLM”。
很多人会直觉上认为,全量微调更彻底,应该效果更好。毕竟所有参数都能更新,模型更有能力适应新任务。
但实验结果相反:
LoRA 几乎全程比 Full Finetune 更稳、更好。
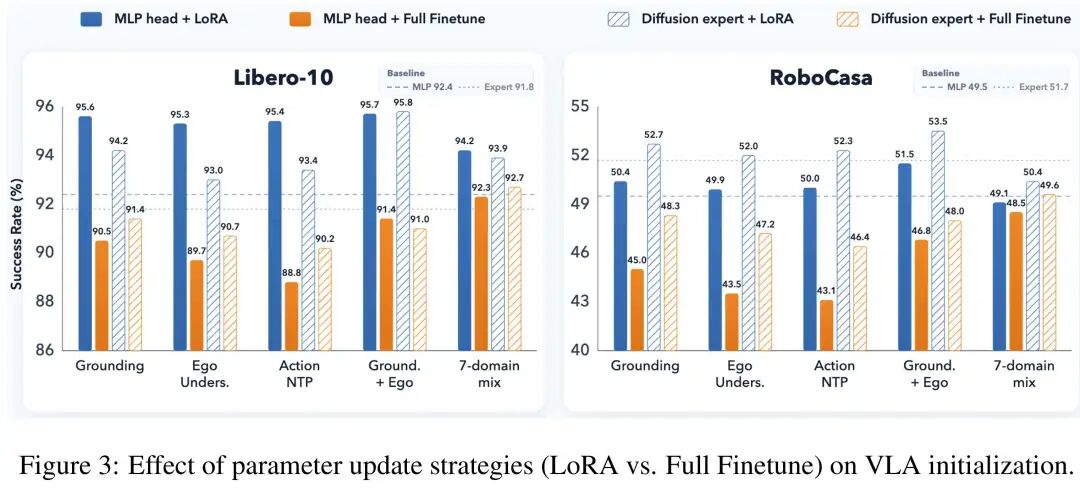
在 Libero-10 和 RoboCasa 上,不管是单独注入 Grounding、Ego、Action-NTP,还是组合 Grounding + Ego,LoRA 的结果基本都高于 Full Finetune。
更关键的是,Full Finetune 经常会低于原始 baseline。也就是说,模型虽然经过了“专业训练”,但最终反而不如不改。
为什么会这样?
论文给出的解释是:全量微调太容易造成表征漂移,把 VLM 原本有用的通用能力覆盖掉。
附录里还有一个很直观的证据:Full Finetune 在具身 VQA 上的分数更高,说明它确实更会做这些“专业题”。但它的通用多模态能力平均掉了约 18%,最后 VLA 表现也更差。
这就像一个人参加了很密集的专项训练,专业测试成绩变高了,但原本的通识能力被冲掉了。真正干活时,反而没有之前稳。
LoRA 的价值就在这里:它不是完全重写模型,而是轻量地加一层适配,让模型学到新能力,同时尽量保留原来的底子。
发现四:底座越强,越值得“轻轻改”
LoRA 的优势还和 VLM 底座本身有关。
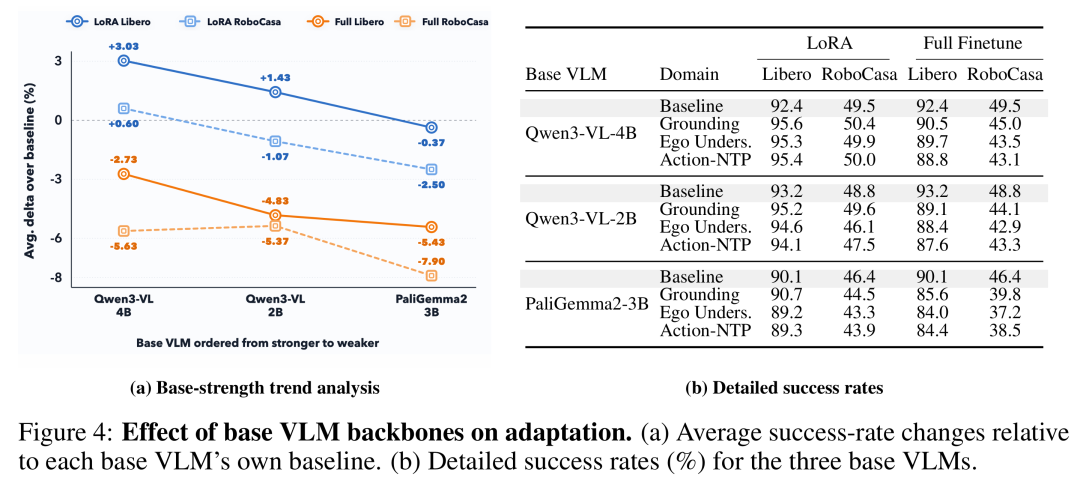
作者比较了 Qwen3-VL-4B、Qwen3-VL-2B 和 PaliGemma2-3B。
结果显示,底座越强,LoRA 带来的收益越明显。
在 Libero-10 上:
Qwen3-VL-4B 的 LoRA 平均提升是 +3.03。 Qwen3-VL-2B 的提升降到 +1.43。 PaliGemma2-3B 上则变成 -0.37。
RoboCasa 也呈现类似趋势。
这说明 LoRA 好用,并不是因为它本身神奇,而是因为它能保护一个本来就有价值的底座。底座越强,越值得保留;底座本身能力有限时,保留带来的收益也会变小。
所以这篇论文并不是简单说“永远用 LoRA”。更准确的说法是:
当你有一个足够强的 VLM 底座时,VLA 初始化更应该避免过度改写它。
发现五:机器人数据有用,但最好分阶段加入
最后,作者进一步问:如果直接用机器人轨迹数据来预训练,会不会更好?
答案是:会更好,但训练方式很重要。
在 RoboCasa 上,基础模型是 49.5。如果用 AgiBot 机器人数据做预训练:
Full Finetune 可以到 52.0。 LoRA 可以到 54.0。
这说明机器人数据确实能提供动作侧的信号,而且 LoRA 仍然更占优。
最强结果来自一个分阶段方案:
先用 Grounding + Egocentric Understanding 对 VLM 做 LoRA 适配。 再继续用机器人轨迹数据做 LoRA 预训练。
最终 RoboCasa 成功率达到 55.2,是论文中最好的结果。
为什么分阶段更好?
因为 VQA 信号和机器人轨迹信号并不完全一样。一个偏理解,一个偏动作。如果把它们同时塞进同一个适配模块,可能会互相竞争。分阶段训练,可以先补理解能力,再补动作经验,让两类信号各自发挥作用。
这篇论文真正想提醒什么?
过去做 VLA,大家很容易把注意力放在更大的模型、更多的数据、更复杂的动作头上。
这篇论文提醒了一个更基础的问题:
VLA 的起点很重要。
不是所有 VLM 改造都会让机器人更强。尤其是当我们已经有一个强 VLM 时,过度微调可能会把原本有用的视觉语言表征破坏掉。
所以,VLM 到 VLA 的适配不应该只问“能不能训得更专”,还要问:
新注入的能力,真的和下游动作任务相关吗? 这些能力之间是互补,还是会互相干扰? 更新方式会不会让模型忘掉原本有用的东西? 机器人数据应该和 VQA 数据一起训,还是分阶段训?
这也是本文标题里 “Rethinking” 的意思:重新思考 VLM 表征在 VLA 初始化里的作用。
给 VLA 研究者的实用建议
如果你正在做 VLA 或具身智能模型,这篇论文可以直接整理成一份初始化避坑指南:
第一,不要轻易从零开始。
预训练 VLM 的通用视觉语言能力,对动作学习非常重要。
第二,补能力要精准。
Grounding 和 Egocentric Understanding 是论文中发现的相对稳定的组合,但更多能力一起堆,并不一定更好。
第三,优先考虑 LoRA。
全量微调可能让模型在辅助任务上更强,但未必让最终机器人策略更强。
第四,选强底座更关键。
LoRA 的收益来自“保住好底子”。底座越强,这个策略越有价值。
第五,机器人数据最好分阶段注入。
先补具身理解,再用机器人轨迹继续适配,比把所有数据混在一起更稳。
小结
这篇论文的核心贡献,不是提出一个新的 VLA 大模型,而是把一个过去经常靠经验处理的问题进行深入探究:
VLM 到 VLA 的初始化,本质上是一个“注入新能力”和“保留旧能力”之间的平衡问题。
补得太少,机器人学不到足够的具身信号;改得太狠,又会破坏 VLM 原本有价值的表征。
真正有效的做法,是找到和动作学习相关的能力,用低破坏性的方式注入进去,再用机器人数据进一步校准。
这对后续 VLA 研究很有参考价值。因为随着 VLM 越来越强,如何“不把好底子改坏”,可能会和“怎么继续变大、继续加数据”一样重要。
推荐阅读 :












