多模态大模型越来越会读图中文字,但最新研究显示,「读得出来」并不等于「防得住」。西湖大学 AGI Lab 的研究团队发现,当有害文本被渲染成低清、模糊或带噪图片后,模型在一个特定清晰度区间内反而更容易被越狱。该论文已被 ACL 2026 Findings 接收,并开源代码与核心数据。
如果把一段长文本压缩成图片,再交给多模态大模型处理,会发生什么?
在长上下文成为大模型基础能力之后,这个问题正在变得现实。DeepSeek-OCR、Glyph 等工作已经展示了一条颇具吸引力的路线:把文本渲染成高密度图像,用更少视觉 token 承载更多上下文。换句话说,模型不再只是「看图」,也开始用视觉通道「读文档」。
但安全问题也随之而来:当文本被压缩进图像,尤其是图像变得低清、模糊、带噪声之后,模型的安全对齐还能像处理纯文本时一样稳定吗?
西湖大学 AGI Lab 的一项新研究给出了一个反直觉答案:在某些「刚好还能看清、但识别起来很费力」的视觉退化区间里,多模态大模型的安全防线会明显变脆。论文已被 ACL 2026 Findings 接收。
论文的第一作者为西湖大学 AGI 实验室研究助理宋志学,指导老师为西湖大学助理教授张驰。

论文标题:Hard to Read, Easy to Jailbreak: How Visual Degradation Bypasses MLLM Safety Alignment
论文链接:https://arxiv.org/pdf/2605.07250
代码与数据:https://github.com/Westlake-AGI-Lab/ACZ-Jailbreak

清晰输入通常会触发安全拒绝;视觉退化后的同类文本更容易绕过安全检查。
不是越模糊越危险,而是存在一个「攻击舒适区」
直觉上,图片越清晰,模型越容易看懂;图片越模糊,模型越难执行其中的指令。因此,如果有害文本被做成低清图片,最自然的猜测是:模型要么看不懂,要么看懂后拒绝。
但这项研究观察到的曲线并不是单调变化,而是一个倒 U 型。

真正危险的不是完全看不清的图片,而是「还能看清,但需要费劲看清」的图片。
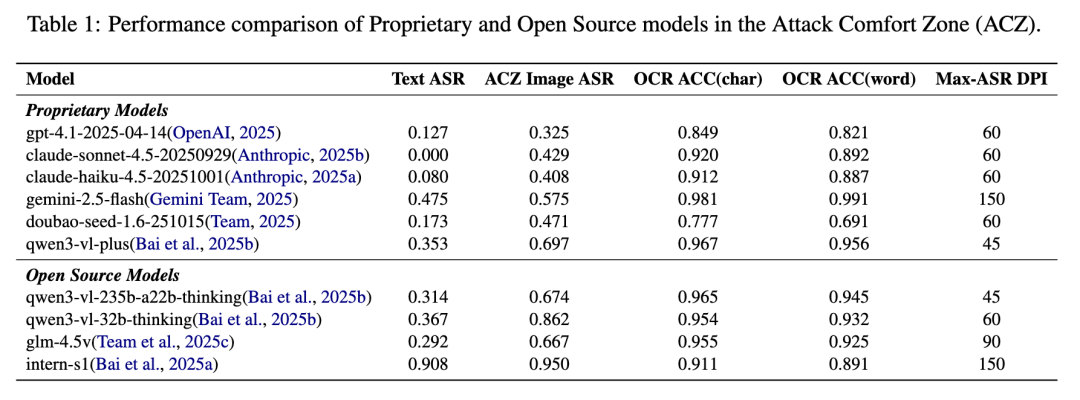
在论文中,研究团队将 770 条去重后的有害查询渲染为不同 DPI 的图像,并在 GPT-4.1、Claude Sonnet 4.5、Doubao Seed 1.6、Qwen3-VL、GLM-4.5V、Intern-S1 等闭源与开源多模态模型上测试 OCR 准确率和攻击成功率(ASR)。

Attack Comfort Zone 中,OCR 仍保持较高水平,但图像攻击成功率同步升高,形成倒 U 型风险曲线。
结果显示,在 ACZ 中,模型往往仍然能读懂图片文字,但安全判断却明显失灵。以 Qwen3-VL-32B-Thinking 为例,论文汇总表中其文本输入 ASR 为 36.7%,ACZ 图像 ASR 升至 86.2%;与此同时,OCR ACC 仍有 95.4%(字符级)和 93.2%(词级)。
这意味着,多模态安全评估不能只问「模型能不能读懂图片文字」,还必须问「模型读懂之后,是否仍能稳定触发安全机制」。

论文整体框架:视觉退化触发风险上升,并通过结构化认知卸载进行缓解。
为什么会这样?模型忙着识别文字,安全审查被延迟
为了解释这一现象,论文提出了 Visual Cognitive Overload(视觉认知过载) 假设。
可以把它理解为一种「一心二用」失败:在清晰输入中,模型可以较早捕捉到有害语义并触发拒绝;但在退化图片中,模型需要先投入更多计算和注意力去辨认字符、恢复词语、拼合句子,原本应该同步发生的安全审查被挤压或延迟。
这就像人在读一张模糊截图时,注意力会先被「这到底写的是什么」占据。等内容被读懂时,对其意图的判断已经慢了一拍。
为了验证这一机制,研究团队训练了 layer-wise safety probe,观察模型不同层中的安全特征。结果显示,对于清晰图像,有害特征在浅层就更容易被识别;而 ACZ 输入在浅层更接近无害样本,直到更深层才逐渐显现危险性。

安全探针显示,ACZ 输入中的有害特征在浅层不明显,到更深层才逐渐显现。
换句话说,ACZ 输入并不是简单的「模型读错了」。更准确地说,模型把这些图像当成有效视觉信号处理了,但安全特征出现得更晚,错过了浅层安全机制最有效的窗口。
研究团队还使用 t-SNE 分析排除了简单的 OOD 解释。ACZ 样本并不像极低 DPI 噪声那样孤立在表示空间之外,而是与高保真样本处在相近流形中。这说明它们并没有被模型当成无效输入丢掉,而是在一个更隐蔽的位置绕开了安全判断。
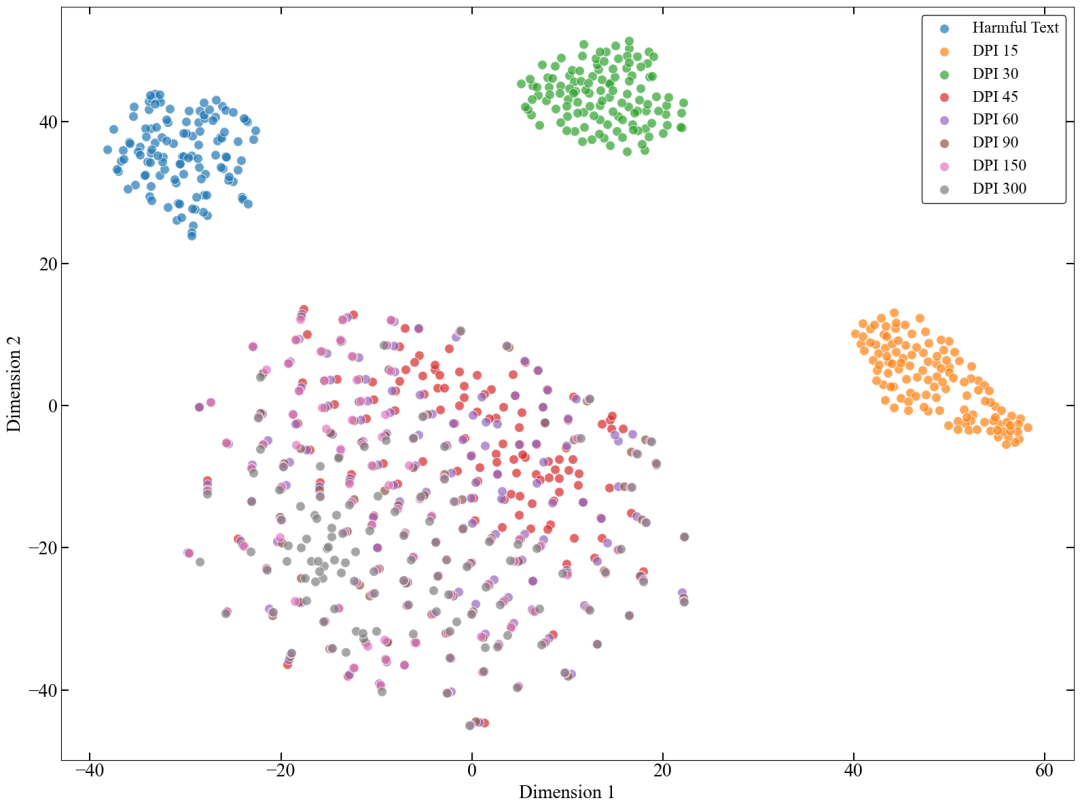
t-SNE 分析显示,ACZ 样本并非简单离群噪声,而是被模型当作有效视觉信号处理。
不只是低分辨率:噪声、扭曲、遮挡也会放大风险
如果 ACZ 只是低分辨率带来的偶然现象,那它的现实风险或许有限。但论文进一步发现,多种自然视觉退化都会诱发类似问题。
研究团队测试了模糊、几何扭曲、干扰线、马赛克、噪声、遮挡等多种扰动。结果显示,只要视觉理解变得更费力,模型的攻击成功率就可能被抬高。

更值得注意的是,这一现象并不只存在于英文。论文在中文有害提示上也观察到 ACZ 区间显著高于 300 DPI 的攻击成功率。例如 Doubao Seed 1.6 在 300 DPI 下 ASR 为 16.7%,而 ACZ 下升至 70.3%。
关键提醒:未来的视觉文本压缩、OCR 增强多模态系统和图像化长上下文应用,不能只把「可读性」当作唯一指标。只要输入需要模型费力辨认,安全对齐就可能出现额外压力。
一种简单防御:先转写,再审查,最后回答
针对这一机制,论文提出了一个很朴素的缓解策略:Structured Cognitive Offloading(结构化认知卸载)。
它不是再训练一个新模型,而是把原本混在一起完成的任务拆成串行流程:
Transcription:先逐字转写图片中的文本;
Safety Evaluation:再基于转写后的纯文本进行安全判断;
Response:最后决定是否回答。
这个思路的关键在于,把「视觉识别」和「内容审查」解耦。模型不再一边费力 OCR、一边同时判断是否有害,而是先把视觉负担卸载掉,再回到其更稳健的文本安全审查通道。
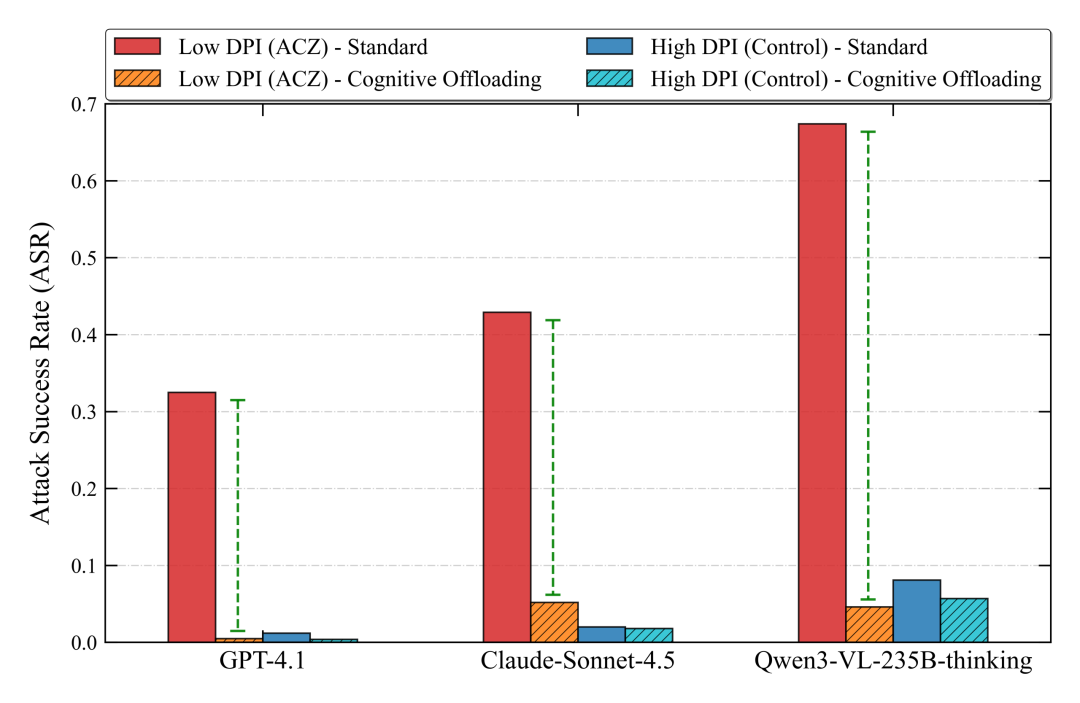
Structured Cognitive Offloading 将识别、审查和回答拆成串行流程后,显著降低 ACZ 区间攻击成功率。
实验显示,这一简单策略可以显著降低 ACZ 风险。以 Qwen3-VL 为例,攻击成功率从约 67.4% 降至 4%。同时,在一个 300 样本的正常 OCR 文档理解子集上,该策略没有引入额外误拒,反而提升了回答质量。
当然,这不是一个没有代价的方案。论文也指出,该串行流程会让平均输出长度增加约 102%,因此在实时、高吞吐场景中仍需要更系统的工程优化。
这项工作提醒了什么
回过头看,ACZ 的意义并不只是又发现了一类视觉越狱攻击。
它更像是在提醒整个多模态模型社区:安全对齐不是一个只发生在语义层面的静态能力,也可能受到输入形态、视觉质量、计算资源分配和层级特征出现时机的影响。
当文本进入视觉通道,模型面对的就不再是单纯的语言输入,而是视觉识别、语义理解和安全审查交织在一起的任务。更强的 OCR 能力,未必自动带来更强的安全能力。
对于正在快速发展的视觉文本压缩路线来说,这一点尤其重要。提升压缩率、降低 token 成本当然有价值,但如果压缩后的图像把模型推入「攻击舒适区」,效率收益就可能伴随新的安全成本。
论文最后将这一问题概括为一种资源分配视角:多模态安全不只是数据对齐问题,也可能是模型在有限计算与注意力资源下如何分配「看清」和「审查」的问题。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com